- 自动求导
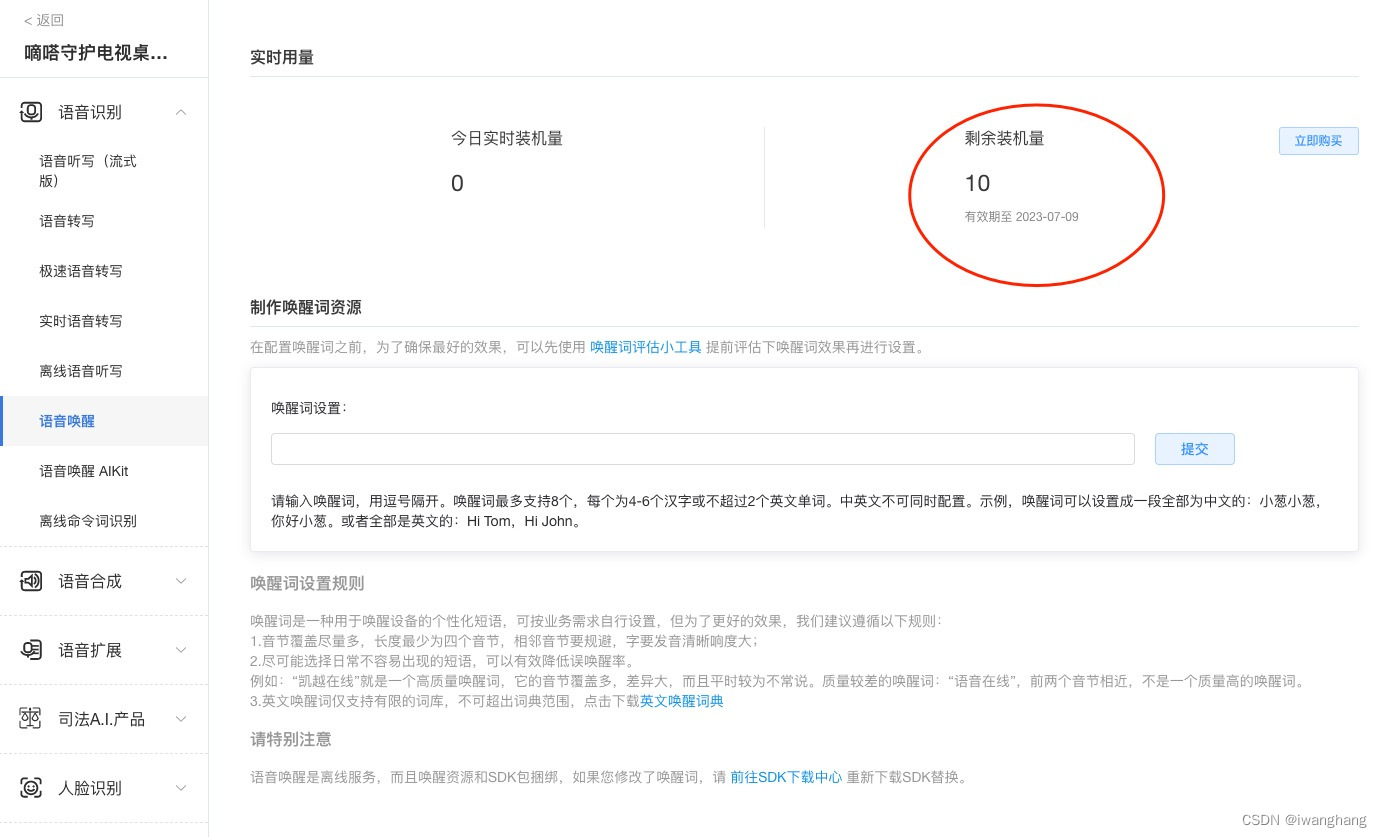
两种方式:正向,反向
内存复杂度:O(n)
计算复杂度:O(n)
- 线性回归
梯度下降通过不断沿着反梯度方向更新参数求解
两个重要的超参数是批量大小和学习率
小批量随机梯度下降是深度学习默认的求解算法
- 训练误差和泛化误差
训练误差:模型在训练数据上的误差
泛化误差:模型在新数据上的误差
验证数据集:一个用来评估模型好坏的数据集
测试数据集:只用一次的数据集
K则交叉验证 常用K=5或者10
- 过拟合和欠拟合

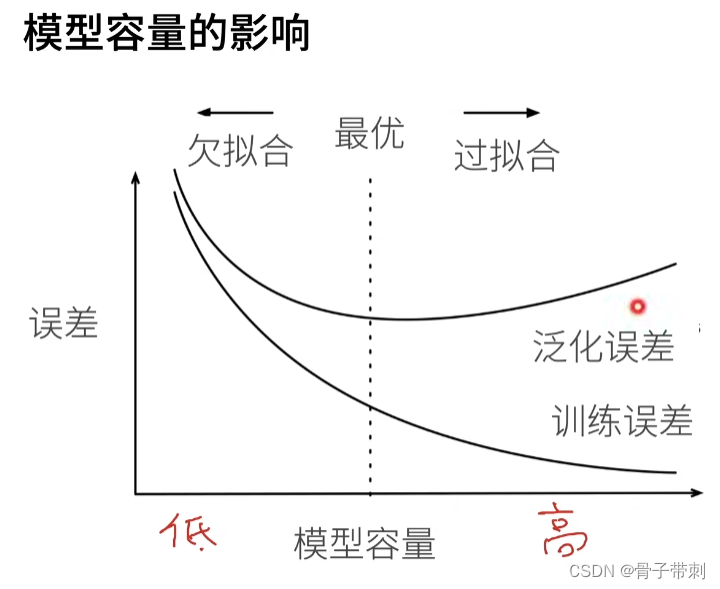
- 权重衰退weight decay
这是一种处理过拟合的方法
权重衰退(weight
decay)是一种用于机器学习的正则化技术。在训练神经网络时,我们通常使用优化算法来调整模型中的权重参数,以使其最小化损失函数。然而,为了防止过拟合,我们需要对这些权重进行约束,以使它们不会变得过大。权重衰退通过在损失函数中增加一个正则化项来实现这一点,该正则化项惩罚过大的权重。具体地说,它将模型参数的 L2
范数(即每个权重值的平方和)添加到损失函数中,并乘以一个称为权重衰减系数的超参数 λ,从而使得较大的权重值被约束到更小的范围内。在训练过程中,权重衰减可以帮助我们避免过拟合,提高模型的泛化能力。同时,它也可以作为一种正则化技术,有助于改善模型的鲁棒性和可解释性。





![[MAUI 项目实战] 手势控制音乐播放器(四):圆形进度条](https://img-blog.csdnimg.cn/eaecf39b83074eb79c774b56c21145ea.gif)