SSM版本的个人博客系统
文章目录
- SSM版本的个人博客系统
- 统一的数据返回处理
- 关于前端的一些问题
- 实现注册功能
- 实现登录的功能
- 存储session
- 获取用户的信息
- 获取左侧的个人信息
- 获取右侧的博客列表
- 时间格式化
- 删除操作
- 注销功能(退出登录)
- 查看文章的详情页
- 排查问题
- 实现阅读量累计
- 新增文章
- 小优化
- 修改文章
- 加盐算法
- 实现文章的分页功能
- Session持久化
在正式写后端程序之前,我已经将博客系统的前端页面写好,详情可以见我的gitee
项目源码
实现步骤:
-
创建一个SSM项目
-
准备项目
a.删除项目中用不到的文件
b.在resources下面的static包下引入起前端页面
c.添加数据库中常用的配置(properties文件)
spring.datasource.url=jdbc:mysql://localhost:3306/mycnblog?characterEncoding=utf8&useSSL=false spring.datasource.username=root spring.datasource.password= 1111 spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver #在resources下面建一个"mapper"的文件夹,里面放的就是xml文件,就使用下面的路径 mybatis.mapper-locations=classpath:mapper/*.xml mybatis.configuration.log-impl=org.apache.ibatis.logging.stdout.StdOutImpl logging.level.com.example.demo=debug -
使用SQL语句来初始化数据库
-- 创建数据库 drop database if exists mycnblog; create database mycnblog DEFAULT CHARACTER SET utf8mb4; -- 使用数据数据 use mycnblog; -- 创建表[用户表] drop table if exists userinfo; create table userinfo( id int primary key auto_increment, username varchar(100) not null unique, password varchar(100) not null , photo varchar(500) default '', createtime datetime, updatetime datetime, `state` int default 1 ) default charset 'utf8mb4'; -- 创建文章表 drop table if exists articleinfo; create table articleinfo( id int primary key auto_increment, title varchar(100) not null, content text not null, createtime datetime, updatetime datetime, uid int not null, rcount int not null default 1, `state` int default 1 )default charset 'utf8mb4'; -- 创建视频表 drop table if exists videoinfo; create table videoinfo( vid int primary key, `title` varchar(250), `url` varchar(1000), createtime datetime, updatetime datetime, uid int )default charset 'utf8mb4'; -- 添加一个用户信息 INSERT INTO `mycnblog`.`userinfo` (`id`, `username`, `password`, `photo`, `createtime`, `updatetime`, `state`) VALUES (1, 'admin', 'admin', '', '2021-12-06 17:10:48', '2021-12-06 17:10:48', 1); -- 文章添加测试数据 insert into articleinfo(title,content,uid) values('Java','Java正文',1); -- 添加视频 insert into videoinfo(vid,title,url,uid) values(1,'java title','http://www.baidu.com',1);-- -
创建出合适的分层
统一的数据返回处理
对于一个项目来说,统一的数据返回是前后端交互很重要
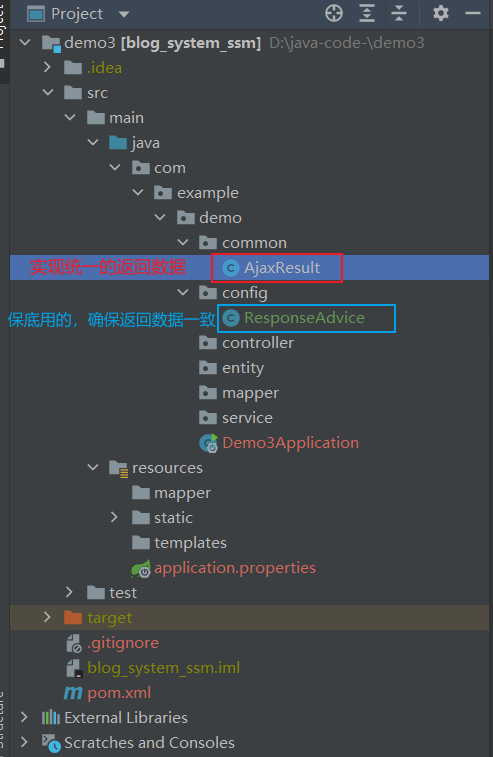
AjaxResult类:
package com.example.demo.common;
import lombok.Data;
import java.io.Serializable;
/*
统一的数据格式返回
最终以JSON的形式来返回
*/
@Data
public class AjaxResult implements Serializable {
//实现Serializable序列化
//状态码
private Integer code;
//状态码描述信息
private String msg;
//返回的数据(不知道具体是什么类型,所以采用Object)
private Object data;
/*
操作成功的结果
*/
public static AjaxResult success(Object data) {
AjaxResult ajaxResult = new AjaxResult();
ajaxResult.setCode(200);
ajaxResult.setMsg("");//成功了就不返回信息了
ajaxResult.setData(data);
return ajaxResult;
}
//像上面写,数据是定死的,所以可以使用方法的重载来实现,一共就是3中重载的方法
public static AjaxResult success(Integer code,Object data) {
AjaxResult ajaxResult = new AjaxResult();
ajaxResult.setCode(code);
ajaxResult.setMsg("");//成功了就不返回信息了
ajaxResult.setData(data);
return ajaxResult;
}
public static AjaxResult success(Integer code,String msg,Object data) {
AjaxResult ajaxResult = new AjaxResult();
ajaxResult.setCode(code);
ajaxResult.setMsg("msg");//成功了就不返回信息了
ajaxResult.setData(data);
return ajaxResult;
}
/**
* 返回失败的结果,也是重载
*/
public static AjaxResult fail(Integer code,String msg) {
AjaxResult ajaxResult = new AjaxResult();
ajaxResult.setCode(code);
ajaxResult.setMsg("msg");
ajaxResult.setData(null);
return ajaxResult;
}
public static AjaxResult fail(Integer code,String msg,Object data) {
AjaxResult ajaxResult = new AjaxResult();
ajaxResult.setCode(code);
ajaxResult.setMsg("msg");
ajaxResult.setData(data);
return ajaxResult;
}
}
ResponseAdvice类:
package com.example.demo.config;
import com.example.demo.common.AjaxResult;
import com.fasterxml.jackson.databind.ObjectMapper;
import lombok.SneakyThrows;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.core.MethodParameter;
import org.springframework.http.MediaType;
import org.springframework.http.server.ServerHttpRequest;
import org.springframework.http.server.ServerHttpResponse;
import org.springframework.web.bind.annotation.ControllerAdvice;
import org.springframework.web.bind.annotation.ResponseBody;
import org.springframework.web.servlet.mvc.method.annotation.ResponseBodyAdvice;
import javax.annotation.Resource;
/**
* 这个类就是一个保底的类,要是忘记调用AjaxResult类,就只能依靠这个类在返回之前确保返回的是JSON格式的数据
*/
@ControllerAdvice
public class ResponseAdvice implements ResponseBodyAdvice {
//Jackson对象注入,用于将String类型转换成JSON
@Resource
private ObjectMapper objectMapper;
//这个方法就是一个开关,返回的是true时,才会执行beforeBodyWrite方法
@Override
public boolean supports(MethodParameter returnType, Class converterType) {
return true;
}
@SneakyThrows //异常
@Override
public Object beforeBodyWrite(Object body, MethodParameter returnType, MediaType selectedContentType, Class selectedConverterType, ServerHttpRequest request, ServerHttpResponse response) {
//body是Object格式的,所以要先检验一下数据类型
if (body instanceof AjaxResult) {
//说明body已经是AjaxResult的JSON类型了,所以没事
return body;
}
if (body instanceof String) {
//要是body是String,要想转换成JSON格式,就要用到Jackson来转换
return objectMapper.writeValueAsString(AjaxResult.success(body));
}
//body是正常的数据类型
return AjaxResult.success(body);
}
}
关于前端的一些问题
有一个注意点:在修改前端代码的时候,前端页面可以没有生效,此时极大的概率是缓存问题
几种解决方案:
- 首先可以试试重启一下IDEA中的项目
- 不行的话,就删除目录下的target文件夹,之后再重启IDEA来重新生成target文件夹
- 使用强制刷新来刷新浏览器(CTRL + F5),之后打开F12看看源代码有没有改变
- 要是还是不行的话,就尝试在url后面添加一个?参数,来让浏览器重新加载
在进行前后端的交互的时候,使用的基本上都是jQuery的ajax,所以对于ajax要很熟悉
jQuery.ajax({
url:"",//请求的地址
type:"",//请求类型是GET/POST....
data:{},//请求的参数,也就是要传递给后端的参数
success: function(){//用于接收后端的返回值
//........
}
})
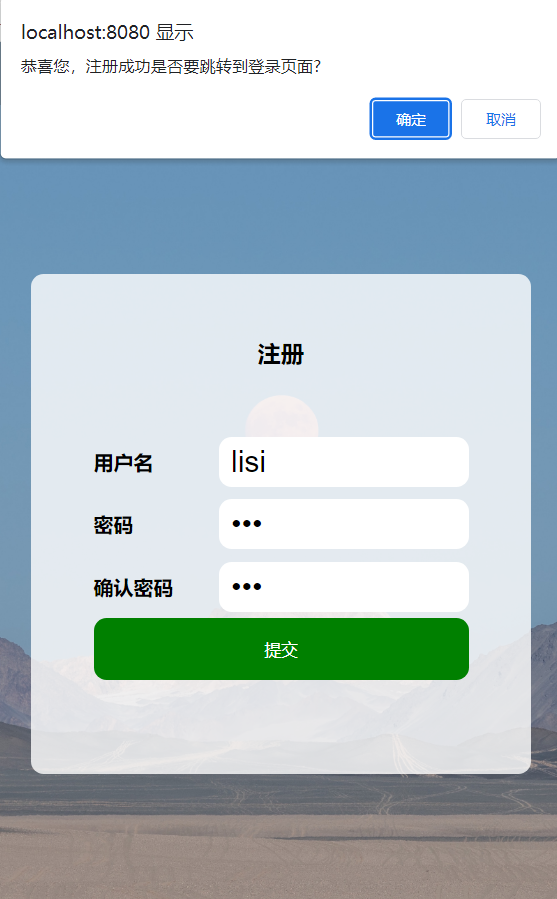
一个实现注册请求的ajax示例:
jQuery.ajax({
url:"/user/reg",
type:"POST",
data:{"username":username.val(),"password":password.val()},
success:function(result){
//这里的data是受影响的行数
if(result != null && result.code == 200 && result.data == 1){
//后端返回响应且成功了
if(confirm("恭喜您,注册成功是否要跳转到登录页面?")){
location.href = "/login.html";
}
}else{
alert("抱歉,注册失败,请稍后再试");
}
}
})
实现注册功能
在后端实现注册功能的时候,其实本质上就是向数据库中的userinfo表中添加一行
逻辑调用关系:由于存在controller调用service,service调用mapper接口,所以可以先实现mapper接口,之后再向上传递,会比较好
注意:在创建出一个类的时候,应该首先考虑要不要加上注解,应该加上什么注解
创建出一个userinfo的实体类
package com.example.demo.entity;
import lombok.Data;
import java.time.LocalDateTime;
//使用@Data省的写很多的getter setter toString hashcode方法
@Data
public class Userinfo {
//使用Integer比int更好,因为Integer的兼容性更好,传null时,int接收会报错,Integer接收不会报错
private Integer id;
private String username;
private String password;
private String photo;
private LocalDateTime createtime;
private LocalDateTime updatetime;
private Integer state;
}
UserMapper:
package com.example.demo.mapper;
import com.example.demo.entity.Userinfo;
import org.apache.ibatis.annotations.Mapper;
@Mapper
public interface UserMapper {
int reg(Userinfo userinfo);
}
UserMapper.xml :
有一个很重要的点:在xml中写SQL语句的时候,只有select语句要写resultType,其他的语句都不用写返回值
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<!--命名空间要根据目录结构依次写到接口-->
<mapper namespace="com.example.demo.mapper.UserMapper">
<insert id="reg">
insert into userinfo(username,password)
values (#{username},#{password})
</insert>
</mapper>
<!--这个xml的名字要和上面的mapper包里面的接口名是一致的,这样子就能建立映射关系-->
UserService:
package com.example.demo.service;
import com.example.demo.entity.Userinfo;
import com.example.demo.mapper.UserMapper;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import javax.annotation.Resource;
@Service
public class UserService {
@Resource
private UserMapper userMapper;
public int reg(Userinfo userinfo) {
return userMapper.reg(userinfo);
}
}
UserController :
package com.example.demo.controller;
import com.example.demo.common.AjaxResult;
import com.example.demo.entity.Userinfo;
import com.example.demo.mapper.UserMapper;
import com.example.demo.service.UserService;
import org.apache.coyote.http11.upgrade.UpgradeInfo;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.util.StringUtils;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.ResponseBody;
import org.springframework.web.bind.annotation.RestController;
@RestController
@RequestMapping("/user") //使用@RequestMapping可以接收GET和POST请求
//RequestMapping是要根据前端在ajax中的url中的参数来确定的,所以前端的ajax很重要
public class UserController {
@Autowired
private UserService userService;
@RequestMapping("/reg")
public AjaxResult reg(Userinfo userinfo) {
//非空判断
//虽然前端已经进行了非空检查,但是用户可能会通过别的方式直接访问url绕过前端的非空校验,所以作为后端,应该要考虑到这一点
//所以在后端也是要写非空校验的
if (userinfo == null || !StringUtils.hasLength(userinfo.getUsername()) ||
!StringUtils.hasLength(userinfo.getPassword())){
return AjaxResult.fail(-1,"非法参数");
}
//不是空的话,就直接返回成功的响应就行了
//这里响应的是1,所以前端在进行成功判断的时候才有result.data == 1 这一条
return AjaxResult.success(userService.reg(userinfo));
}
}
以上就是所有的注册功能的实现,点击“确定”就会跳转到登录的页面
实现登录的功能
前端中的部分代码(重点是ajax的前后端交互)
<script>
function mysub(){
//1.非空校验
var username = jQuery("#username");
var password = jQuery("#password");
if(username.val() == ""){
alert("请先输入账号");
username.focus();
return;
}
if(password.val() == ""){
alert("请先输入密码");
password.focus();
return;
}
//2.ajax请求登录接口
jQuery.ajax({
url:"/user/login",
tpye:"POST",
data:{"username":username.val(),"password":password.val()},
success: function(result){
//xiugaide
if(result != null && result.code == 200 && result.data == 1){
//登录成功
location.href = "myblog_list.html";
}else{
alert("用户名或者密码错误,请重新输入");
}
}
})
}
</script>
业务上的登录在数据库层面就是查询
这里有一个问题:要保证数据库中没有相同的用户名,可是在创建数据库的时候并没有考虑用户名的唯一性(unique),所以只能现在改一下
alter table 表名 add unqiue(列名)
alter table userinfo add unique(username);
UserMapper :
//登录
//这里只传入一个用户名,在后面的controller中进行密码判断就行了,主要是为了保护密码的安全,所以只传一个用户名
Userinfo getUserByName(@Param("username") String username);
UserMapper.xml:
<!--登录-->
<select id="getUserByName" resultType="com.example.demo.entity.Userinfo">
select * from userinfo where username = #{username};
</select>
UserService:
public Userinfo getUserByName(String username) {
return userMapper.getUserByName(username);
}
UserController:
//登录操作
@RequestMapping("/login")
public AjaxResult login(String username,String password) {
//1.进行非空判断
if (!StringUtils.hasLength(username) || !StringUtils.hasLength(password)){
//说明没有传入任何参数
return AjaxResult.fail(-1,"非法请求");
}
//2.查询数据库
Userinfo userinfo = userService.getUserByName(username);
if (userinfo != null && userinfo.getId() > 0) {
//能获得id就说明用户名一定是在数据库中,说明是有效用户
if (password.equals(userinfo.getPassword())){
//要是密码正确,在将数据返回之前,考虑到隐私,隐藏密码
userinfo.setPassword("");
return AjaxResult.success(userinfo);
}
}
return AjaxResult.fail(0,null);
}
最后的效果就是输入正确的账号密码登录,然后跳转到博客详情页
存储session
首先要知道为什么要存储session?
session就是会话的意思,一般都是用在服务端记录用户信息,可以用来标识当前的用户
session是键值对的形式,可以定义一个全局变量作为key
ApplicationVariable 类:
package com.example.demo.common;
//关于全局变量的类
public class ApplicationVariable {
//用户的session的key值
public static final String USER_SESSION_KEY = "USER_SESSION_KEY";
}
在登录操作的时候就要创建session
UserController:
//登录操作
@RequestMapping("/login")
public AjaxResult login(HttpServletRequest request, String username, String password) {
//1.进行非空判断
if (!StringUtils.hasLength(username) || !StringUtils.hasLength(password)){
//说明没有传入任何参数
return AjaxResult.fail(-1,"非法请求");
}
//2.查询数据库
Userinfo userinfo = userService.getUserByName(username);
if (userinfo != null && userinfo.getId() > 0) {
//能获得id就说明用户名一定是在数据库中,说明是有效用户
if (password.equals(userinfo.getPassword())){
//将用户的session存储下来
//参数为true:要是没有session就创建一个会话
HttpSession session = request.getSession(true);
//设置session的key和value
session.setAttribute(ApplicationVariable.USER_SESSION_KEY,userinfo);
//要是密码正确,在将数据返回之前,考虑到隐私,隐藏密码
userinfo.setPassword("");
return AjaxResult.success(userinfo);
}
}
return AjaxResult.fail(0,null);
}
此时要考虑一下:是不是所有的页面都能给未登录的用户看呢?
之前的方法是每次进入一个页面之前都要做很多的session判断,来判断能不能进入当前的页面,但是现在可以实现一个拦截器,统一地进行拦截,有效地解决了代码的重复
哪些页面是不能拦截的–>不登录的用户也是可以看的?
- 注册页面 && 接口
- 登录页面 && 接口
- 博客列表页
- 博客详情页
blog_list是展示所有用户写的博客,不拦截
myblog_list是展示登录用户写的博客,要拦截(登录之后才能看到)
像博客编辑页、myblog_list 肯定是要先登录的,所以要对未登录的用户进行拦截
实现拦截器就是两个步骤:
- 实现一个普通的拦截器
- 设置拦截规则
LoginInterceptor :
package com.example.demo.config;
import com.example.demo.common.ApplicationVariable;
import org.springframework.web.servlet.HandlerInterceptor;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import javax.servlet.http.HttpSession;
//1.实现一个普通的拦截器
//a.实现HandlerInterceptor
//b.重写preHandle,要是返回值时true,说明可以继续流程,返回值是false说明被拦截了,不能继续了
public class LoginInterceptor implements HandlerInterceptor {
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
//登录拦截器本来就是拦截没有登录的用户,所以没有session会话也不会创建
HttpSession session = request.getSession(false);
if (session != null && session.getAttribute(ApplicationVariable.USER_SESSION_KEY) != null) {
//说明存在session且session的值不为空
return true;
}
//要是不存在session,就直接跳转到登录页面
response.sendRedirect("/login.html");
return false;
}
}
AppConfig:
package com.example.demo.config;
import org.springframework.context.annotation.Configuration;
import org.springframework.web.servlet.config.annotation.InterceptorRegistry;
import org.springframework.web.servlet.config.annotation.WebMvcConfigurer;
//2.设置拦截规则
@Configuration
public class AppConfig implements WebMvcConfigurer {
@Override
public void addInterceptors(InterceptorRegistry registry) {
registry.addInterceptor(new LoginInterceptor())
.addPathPatterns("/**")
//下面都是不要拦截的
.excludePathPatterns("/css/**")
.excludePathPatterns("/editor.md/**")
.excludePathPatterns("/img/**")
.excludePathPatterns("/js/**")
.excludePathPatterns("/login.html")
.excludePathPatterns("/reg.html")
.excludePathPatterns("/blog_list.html")
.excludePathPatterns("/blog_content.html")
.excludePathPatterns("/art/detail")
.excludePathPatterns("/art/incr-rcount")
.excludePathPatterns("/user/getuserbyid")
.excludePathPatterns("/art/listbypage")
.excludePathPatterns("/user/login")
.excludePathPatterns("/user/reg");
}
}
以后都只要输入一遍用户名 + 密码就能自由访问了,要是没有登录,有些页面就不能访问并且会跳转到登录页面
获取用户的信息
在登录之后,展示博客列表时,需要前端给后端发送请求,获取用户的信息(用户名、文章数量、写的博客)
信息可以分为左右两侧的信息
获取左侧的个人信息
首先是获取左侧的信息:主要是登录的用户名 和 写的博客数量
前端的主要代码:
<script>
function showInfo(){
jQuery.ajax({
url:"/user/showinfo",
type:"POST",
data: "", //前端请求的时候并不需要任何参数
success : function (result){
if(result != null && result.code == 200){
//说明后端已经返回了个人信息
jQuery("#username").text(result.data.username);
//artTotal在原本数据库中是没有的,所以后端要新建一个artTotal属性
jQuery("#artTotal").text(result.data.artTotal);
}else{
alert("个人信息加载失败,请刷新重新尝试!");
}
}
})
}
//执行方法
showInfo();
</script>
由于原本的Userinfo并没有artTotal属性,所以创建出一个新的实体类,继承了Userinfo
package com.example.demo.entity.vo;
import com.example.demo.entity.Userinfo;
import lombok.Data;
import java.net.InetAddress;
@Data
public class UserinfoVO extends Userinfo {
public Integer artTotal;//用户发表的博客总数
}
由于要拿到博客的数量,所以要查询 articleinfo 表,查询一个表,就要创建出一个对应的实体类、Mapper、Service、Controller
ArticleMapper:
package com.example.demo.mapper;
import org.apache.ibatis.annotations.Mapper;
import org.apache.ibatis.annotations.Param;
@Mapper
public interface ArticleMapper {
//根据用户的id来查询博客数量
int getArtTotalByUid(@Param("uid") int uid);
}
对应的ArticleMapper.xml文件:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<!--命名空间要根据目录结构依次写到接口-->
<mapper namespace="com.example.demo.mapper.ArticleMapper">
<select id="getArtTotalByUid" resultType="Integer">
-- 注意:uid代表作者的身份,id表示博客的数量,注意这里要使用count(*)计算出行数
select count(*) from articleinfo where uid = #{uid};
</select>
</mapper>
<!--这个xml的名字要和上面的mapper包里面的接口名是一致的,这样子就能建立映射关系-->
此时可以自动生成一个单元测试,来测试一下这个接口到底是不是正确的,免得后面写完了Service和Controller出错,更重要的是可以增加自己编码的信心
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dFmMngUJ-1681609448499)(…/…/…/AppData/Roaming/Typora/typora-user-images/image-20230408210107671.png)]
在写完了mapper之后,就可以写service和controller了
ArticleService:
package com.example.demo.service;
import com.example.demo.mapper.ArticleMapper;
import org.apache.coyote.http11.upgrade.UpgradeInfo;
import org.apache.ibatis.annotations.Mapper;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
@Service
public class ArticleService {
@Autowired
private ArticleMapper articleMapper;
public Integer getArtTotalByUid(Integer uid){
return articleMapper.getArtTotalByUid(uid);
}
}
要获得用户的博客数量,就要先获得session会话,之后才能进行操作,获取session这个动作在后面也会进程用到,所以将它变成一个common包下面的类中的一个方法应该是更好的选择
common包下面的UserSessionUtils:
package com.example.demo.common;
import com.example.demo.entity.Userinfo;
import org.apache.coyote.http11.upgrade.UpgradeInfo;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpSession;
//这个类是用来存放登录用户的session操作的
public class UserSessionUtils {
//获取登录用户的session
public static Userinfo getUser(HttpServletRequest request){
HttpSession session = request.getSession();
if (session != null && session.getAttribute(ApplicationVariable.USER_SESSION_KEY) != null) {
return (Userinfo) session.getAttribute(ApplicationVariable.USER_SESSION_KEY);
}
return null;
}
}
开始写UserController:(首先要在前面将articleService对象注入)
@Autowired
private ArticleService articleService;
@RequestMapping("/showinfo")//这个路径是根据前端ajax中的url规定好的
public AjaxResult showInfo(HttpServletRequest request){
//定义包含artTotal属性的对象
UserinfoVO userinfoVO = new UserinfoVO();
//调用common包中的获取session方法
Userinfo userinfo = UserSessionUtils.getUser(request);
if (userinfo == null) {
AjaxResult.fail(-1,"非法请求");
}
//Spring提供的深拷贝的方式,将userinfo深拷贝给userinfoVO
BeanUtils.copyProperties(userinfo,userinfoVO);
//通过userinfo的id来查找userinfoVO的博客数量
userinfoVO.setArtTotal(articleService.getArtTotalByUid(userinfo.getId()));
//前端最后要的是username和artTotal,这两个属性都在userinfoVO对象中,所以直接返回就行了
return AjaxResult.success(userinfoVO);
}
这样子每次刷新就会去读取数据库,并且在左侧显示用户名和博客数量
获取右侧的博客列表
查询不同的表就要有对应的实体类、Mapper、Service、Controller
首先要创建出一个ArticleInto实体类,将数据库中的字段进行对应的实体化
package com.example.demo.entity;
import lombok.Data;
import java.time.LocalDateTime;
//创建出一个文章的实体类
@Data
public class ArticleInfo {
private Integer id;
private String title;
private String content;
private LocalDateTime createtime;
private LocalDateTime updatetime;
private String uid;
private String rcount;
private String state;
}
在ArticleMapper中:
//根据uid获取用户的博客列表(uid指的是用户的id,数据库中的id指的是文章对用的id)
//返回的是ArticleInfo类型的list
List<ArticleInfo> getMyList(@Param("uid") int uid);
ArticleMapper.xml :
<!--返回的是ArticleInfo实体类-->
<select id="getMyList" resultType="com.example.demo.entity.ArticleInfo">
select * from articleinfo where uid = #{uid};
</select>
ArticleService:
@Autowired
private ArticleMapper articleMapper;
public List<ArticleInfo> getMyList(Integer uid){
return articleMapper.getMyList(uid);
}
ArticleController:
package com.example.demo.controller;
import com.example.demo.common.AjaxResult;
import com.example.demo.common.UserSessionUtils;
import com.example.demo.entity.ArticleInfo;
import com.example.demo.entity.UserInfo;
import com.example.demo.service.ArticleService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpSession;
import java.util.List;
@RestController
//所有的@RequestMapping后面的参数都是在前端代码中指定的
@RequestMapping("/art")
public class ArticleController {
@Autowired
private ArticleService articleService;
@RequestMapping("/getlist")
public AjaxResult getMyList(HttpServletRequest request) {
//首先先获取到对应的用户信息
UserInfo userInfo = UserSessionUtils.getUser(request);
if (userInfo == null) {
//说明当前不存在session,也就是没有登录(虽然存在拦截器,但是还是要进行判断一下是否是真的登录了)
return AjaxResult.fail(-1, "非法请求");
}
//说明已经正常登录了
List<ArticleInfo> list = articleService.getMyList(userInfo.getId());
return AjaxResult.success(list);
//问题:在xml中传入的是uid,为什么这里传入的是userInfo.getId()????
//这里涉及到了userinfo和articleinfo两张表的关系了
//在articleinfo表中id表示每篇文章对应的id,uid表示写文章的用户
//在userinfo中id表示当前登录用户的信息,所以userinfo中id对应着articleinfo表中uid,所以这里使用的是userInfo.getId()
}
}
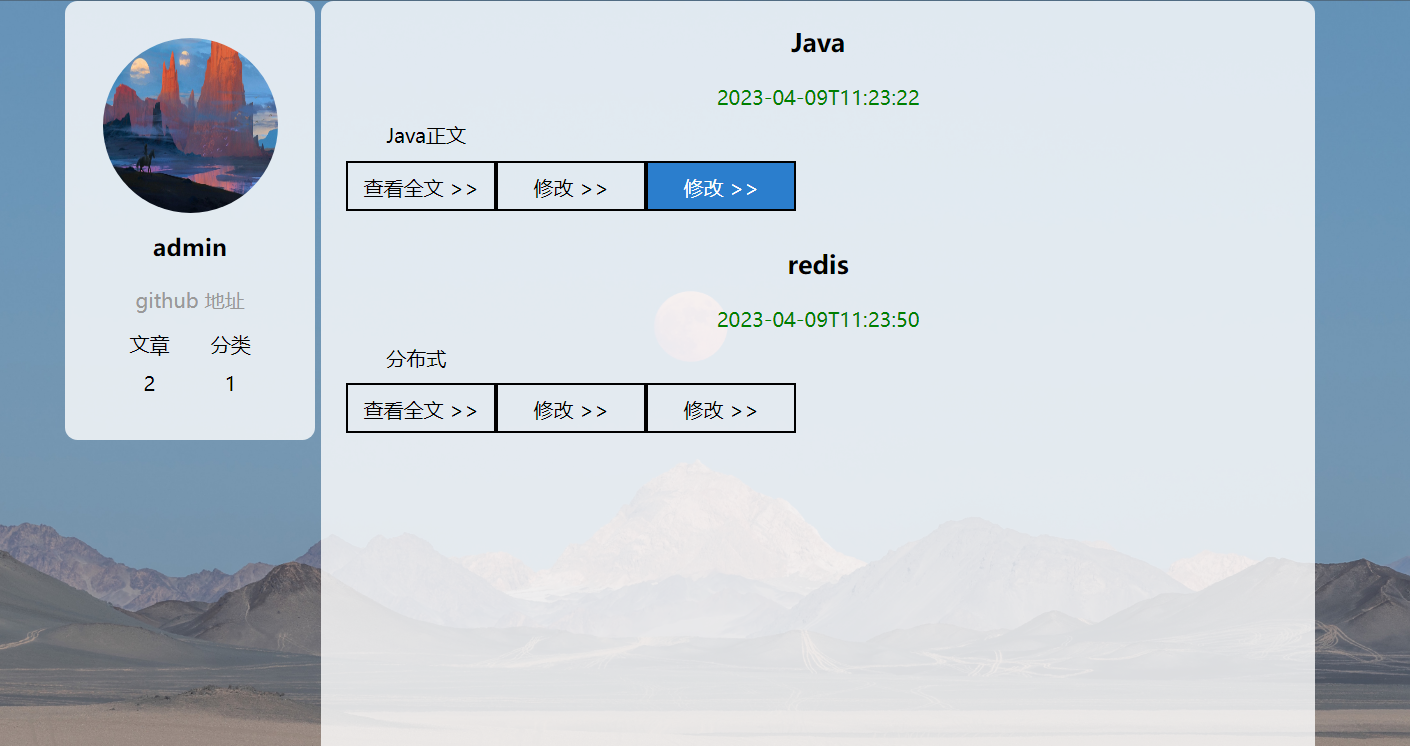
但是,时间的格式并不是很对,所以需要进行时间的格式化调整
时间格式化
-
使用全局配置方法
在properties文件中,使用
spring.jackson.date-format=yyyy-MM-dd HH:mm:ss spring.jackson.time-zone= GMT +8
这个GMT默认是格林尼治时间,由于我们是在东八区,所以时间要加8
但是这种全局配置的方法只能针对Date类型,对LocalDateTime类型是不生效的
- 由于上面的全局配置方式对LocalDateTime没有效果,所以可以使用@JsonFormat注解
@JsonFormat(pattern = "yyyy-MM-dd HH:mm:ss",timezone = "GMT +8")
private LocalDateTime createtime;
@JsonFormat(pattern = "yyyy-MM-dd HH:mm:ss",timezone = "GMT +8")
private LocalDateTime updatetime;
对每个时间变量单独进行时间的格式化
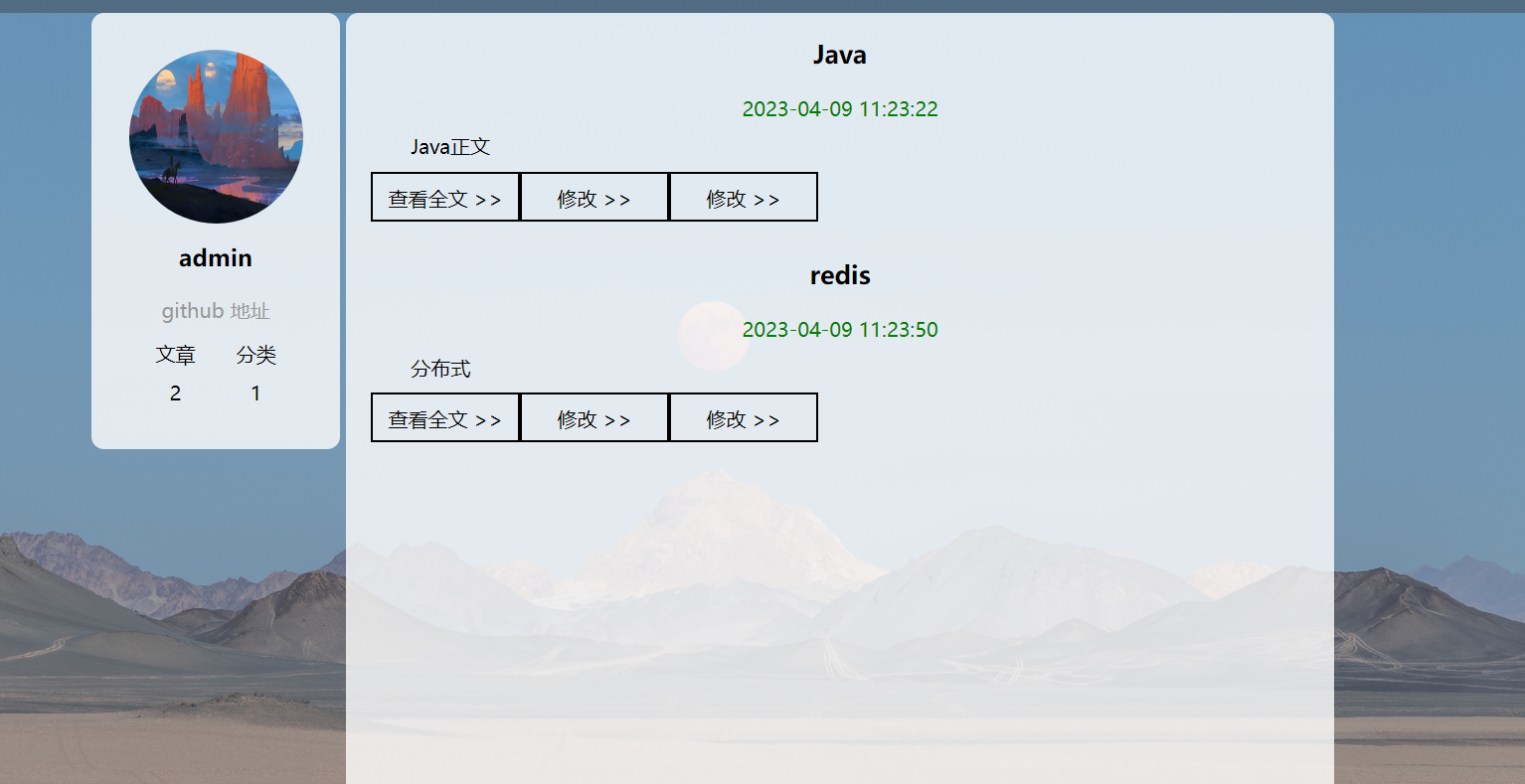
时间格式化后显示效果:
删除操作
前端的部分代码:
//删除方法
function myDel(id){
if(confirm("确定要删除文章吗?")){
jQuery.ajax({
url:"art/del",
type:"POST",
data:{"id":id},//将要删除的文章的id传给后端
success: function(result){
if(result != null && result.code == 200 && result.data == 1){
alert("删除成功!");
//删除之后,刷新页面
location.href = location.href;
}else{
alert("抱歉,删除失败,请重试!");
}
}
})
}
}
ArticleMapper:
//删除文章
//在删除文章的时候必须要验证当前登录的用户是不是文章的作者
//在articleinfo中的id表示文章的id,uid表示写这篇文章的用户的id,在controller中只要判断一下uid与当前登录的用户的id是不是一样就也可以了
int del(@Param("id") Integer id,@Param("uid") Integer uid);
ArticleMapper.xml :
<delete id="del">
delete from articleinfo where id = #{id} and uid = #{uid};
</delete>
ArticleService:
public Integer del(Integer id,Integer uid){
return articleMapper.del(id,uid);
}
ArticleController:
@RequestMapping("/del")
//前端传过来的id是文章的id
public AjaxResult del(HttpServletRequest request, Integer id) {
if (id == null || id <= 0) {
//根本就不存在这个文章
AjaxResult.fail(-1,"非法请求");
}
UserInfo userInfo = UserSessionUtils.getUser(request);
if(userInfo == null){
AjaxResult.fail(-2,"用户未登录");
}
//userinfo中的id就是articleinfo中的uid,都表示用户的id
return AjaxResult.success(articleService.del(id,userInfo.getId()));
}
注意:
return AjaxResult.success(articleService.del(id,userInfo.getId()));
并不一定能删除文章
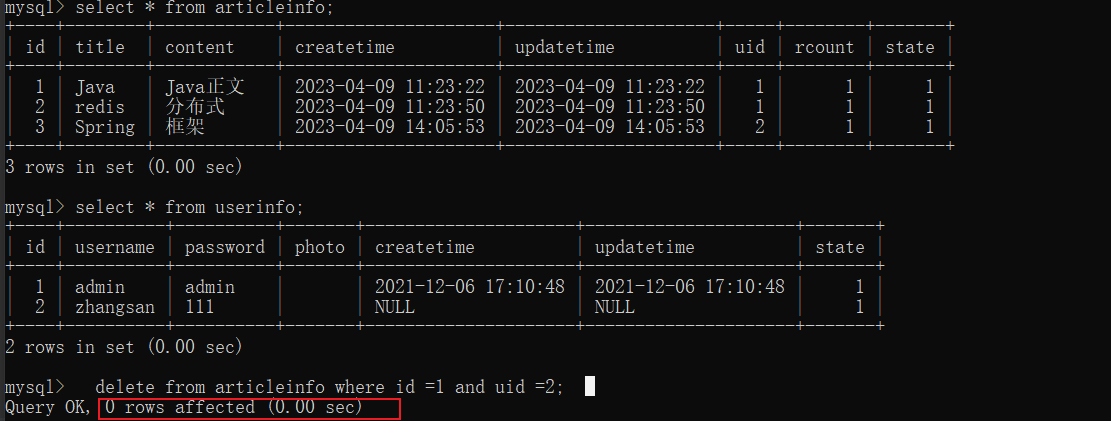
登录uid为2的用户去删除文章id为1时,最后并没有删除,
对应到前端中的
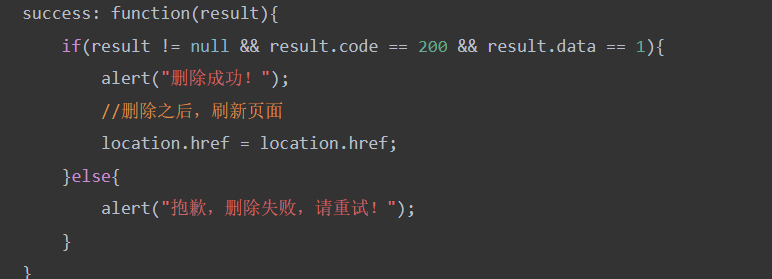
result。data = 0,所以最后还是没有删除,满足了业务的需求。
注销功能(退出登录)
前端部分代码:
<a href="javascript:loginout()">注销</a>
//实现注销方法
function logout(){
if(confirm("确认退出吗?")){
jQuery.ajax({
url:"/user/logout",
type:"POST",
data:{},
success: function(result){
if(result != null && result.code == 200){
//返回到登录页面
location.href = "/login.html";
}
}
})
}
}
退出登录不需要查询数据库,所以直接在controller写就行了
//实行注销功能
@RequestMapping("/logout")
public AjaxResult logout(HttpSession session){
//将session中key的值删除了,那session也就没了
session.removeAttribute(ApplicationVariable.USER_SESSION_KEY);
return AjaxResult.success(1);
}
查看文章的详情页
- 从url中得到文章 id的值(前端代码中体现)
- 从后端articleinfo表查询出当前文章的详细信息(已经uid)
- 根据查询到的uid来查询用户的信息
- 实现阅读量+1
前端的部分代码:
function getArtDetail(id){ if(id == ""){ alert("非法参数"); return; } jQuery.ajax({ url:"/art/detail", type:"POST", data:{"id":id}, success: function(result){ if(result != null && result.code == 200){ //说明请求成功了 jQuery("#title").html(result.data.title); jQuery("#updatetime").html(result.data.updatetime); jQuery("#rcount").html(result.data.rcount); initEdit(result.data.content); showUser(result.data.uid); }else{ alert("请求失败,请重试!"); } } }); }
从后端中查询当前文章的信息:
ArticleMapper:
//获取文章的详情
ArticleInfo getDetail(@Param("id") Integer id);
ArticleService:
public ArticleInfo getDetail(Integer id){
return articleMapper.getDetail(id);
}
ArticleController:
@RequestMapping("/detail")
public AjaxResult getDetail(Integer id){
if(id == null || id <= 0){
return AjaxResult.fail(-1,"非法请求");
}
return AjaxResult.success(articleService.getDetail(id));
}
左侧的作者信息要去数据库中拿:
前端中的部分代码:
//查询用户的详细信息
function showUser(id){
jQuery.ajax({
url:"/user/getuserbyid",
type:"POST",
data:{"id":id},
success:function(result){
if(result != null && result.code ==200 && result.data.id > 0){
jQuery("#username").text(result.data.username),
jQuery("#artCount").text(result.data.artCount)
}else{
alert("抱歉,查询用户信息失败,请重试!");
}
}
})
}
UserMapper:
//在文章详情中获取左侧的作者信息
UserInfo getUserById(@Param("id") Integer id);
UserMapper.xml :
<select id="getUserById" resultType="com.example.demo.entity.UserInfo">
select * from userinfo where id = #{id};
</select>
UserService:
public UserInfo getUserById(Integer id){
return userMapper.getUserById(id);
}
UserController :
//在文章详情页获取左侧的博客作者的信息
//url中一定不要使用大写字母,windows对于大小写不敏感,但是Linux对大小写敏感,所以可能会出现错误
@RequestMapping("getuserbyid")
public AjaxResult getUserById(Integer id){
if(id == null || id <= 0){
return AjaxResult.fail(-1,"非法参数");
}
UserInfo userInfo = userService.getUserById(id);
if(userInfo == null || userInfo.getId() <= 0){
//用户不存在
return AjaxResult.fail(-2,"非法参数");
}
//去除敏感的信息
userInfo.setPassword("");
UserInfoVO userInfoVO = new UserInfoVO();
//深拷贝,将userInfo拷贝给userInfoVO
BeanUtils.copyProperties(userInfo,userInfoVO);
//查询当前用户发布过多少篇文章
userInfoVO.setArtTotal(articleService.getArtTotalByUid(id));
return AjaxResult.success(userInfoVO);
}
之所以要引入userInfoVO,是因为userInfoVO中有artTotal,可以统计文章数
在启动项目之后,却发现了错误
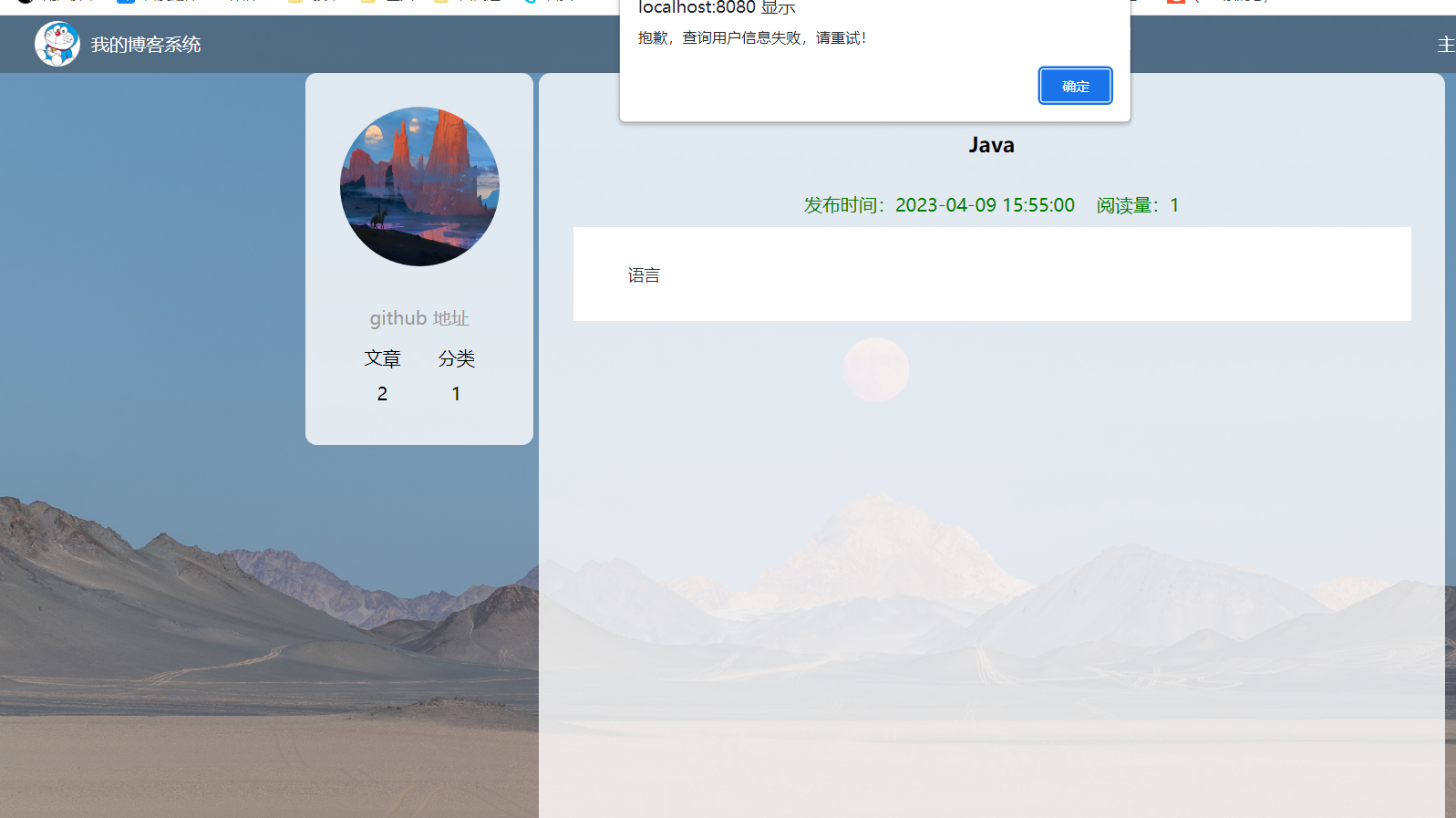
排查问题
遇到错误其实是很常见的,最重要的就是找到哪里除了问题
首先打开开发者工具,找到network栏,再刷新一下网页,就会看到具体的网络请求了
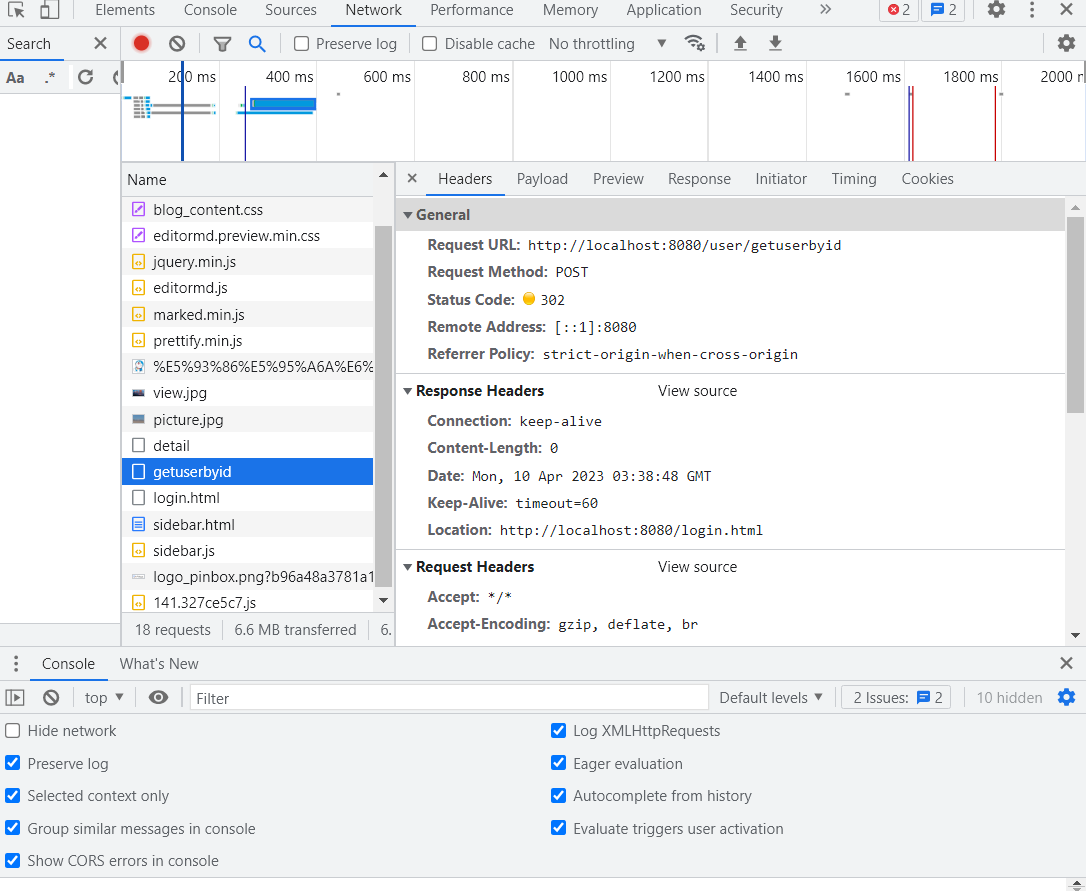
找到对应的方法之后,发现是302错误,也就是重定向错误,此时就可以确认是拦截器的问题了
之前在拦截器中设置了blog_content.html是可以访问的,现在添加了一个/user/getuserbyid接口,会被拦截,所以就会跳转到登录页面
使用fiddler抓包也可以看出来
所以只要在拦截器中添加一条排除/user/getuserbyid接口的规则就行了
实现阅读量累计
要想实现阅读量累加,可以有两种方式
方式一:首先在数据库中查询当前的阅读量,之后再加一
但是,这种方式是很有问题的,要是A和B同时去访问一篇博客,A拿到了阅读量为x,同时B也拿到了阅读量x,在A之后阅读量就会变成x+1,但是B之后,阅读量还是x+1,可实际上应该是x+2才对,所以这个方式的问题在于并发,不能保证操作的原子性
所以采用第二种方式:直接就在数据库中+1,只进行这一步操作就能有效避免非原子性
ArticleMapper:
//将阅读量+1
int updateRcount(@Param("id") Integer id);
ArticleMapper.xml :
<update id="updateRcount">
update articleinfo set rcount = rcount+1 where id = #{id};
</update>
ArticleService :
public int updateRcount(Integer id){
return articleMapper.updateRcount(id);
}
ArticleController :
//实现阅读量+1
@RequestMapping("addrount")
public AjaxResult updateRcount(Integer id){
if(id == null || id <= 0){
return AjaxResult.fail(-1,"非法请求");
}
return AjaxResult.success(articleService.updateRcount(id));
}
和上面的问题一样,要让拦截器不要拦截 /art/addrcount 接口
代码运行之后就可以实现阅读量的累加
新增文章
前端的部分代码:
function mysub(){
if(confirm("确认提交吗?")){
//1.首先进行非空校验
var title = jQuery("#title");
if(title.val() == ""){
alert("请先输入标题!");
title.focus();
return;
}
if(editor.getValue()== ""){
alert("请先输入文章内容");
return;
}
//2.请求后端进行博客的添加操作
jQuery.ajax({
url:"art/add",
type:"POST",
data:{"title":title.val(),"content":editor.getValue()},
success:function(result){
if(result != null && result.code == 200 && result.data==1){
if(confirm("添加文章成功!是否继续添加?")){
//继续添加文章就刷新写博客页面
location.href = location.href;
}else{
//不再添加文章就返回到列表页
location.href = "/myblog_list.html";
}
}else{
alert("抱歉,添加文章失败,请重试!");
}
}
})
}
}
ArticleMapper :
//添加文章
//这里最好还是传articleinfo对象,后续要是改需求也会比较灵活
int add(ArticleInfo articleInfo);
ArticleMapper.xml :
<insert id="add">
insert into articleinfo(title,content,uid,createtime) values(#{title},#{content},#{uid},now());
</insert>
ArticleService :
public int add(ArticleInfo articleInfo){
return articleMapper.add(articleInfo);
}
ArticleController:
//增加新的文章
@RequestMapping("/add")
public AjaxResult add(HttpServletRequest request , ArticleInfo articleInfo) {
//1.进行非空校验,要是articleinfo对象或者标题或者内容为空,那就是非法访问
if(articleInfo == null || !StringUtils.hasLength(articleInfo.getTitle())
|| !StringUtils.hasLength(articleInfo.getContent())){
return AjaxResult.fail(-1,"非法请求");
}
//2.在数据库中新增
//新增文章的前提是要知道当前登录的用户的uid
UserInfo userInfo = UserSessionUtils.getUser(request);//先得到当前登录用户
if(userInfo == null || userInfo.getId()<=0){
return AjaxResult.fail(-2,"无效的登录用户");
}
articleInfo.setUid(userInfo.getId());
return AjaxResult.success(articleService.add(articleInfo));
}
这个时候就实现了博客的创建
小优化
有时候文章会很长,在博客列表页中应该显示前一小段的内容,所以要进行截取
在ArticleController文件中:
使用一个foreach来让每篇比较长的博客都显示前100个字
@RequestMapping("/getlist")
public AjaxResult getMyList(HttpServletRequest request) {
UserInfo userInfo = UserSessionUtils.getUser(request);
if (userInfo == null) {
//说明当前不存在session,也就是没有登录(虽然存在拦截器,但是还是要进行判断一下是否是真的登录了)
return AjaxResult.fail(-1, "非法请求");
}
//说明已经正常登录了
//这里涉及到了userinfo和articleinfo两张表的关系了
//在articleinfo表中id表示每篇文章对应的id,uid表示用户信息
//在userinfo中id表示用户的信息,所以userinfo中id对应着articleinfo表中uid,所以这里使用的是userInfo.getId()
List<ArticleInfo> list = articleService.getMyList(userInfo.getId());
for (ArticleInfo listArr : list) {
if(listArr.getContent().length() > 200){
listArr.setContent(listArr.getContent().substring(0,100));
}
}
return AjaxResult.success(list);
}
在博客列表页面中,markdown还是以文本的形式来显示的
所以要将markdown渲染成html的形式
首先引入两个依赖:
<dependency>
<groupId>com.vladsch.flexmark</groupId>
<artifactId>flexmark-all</artifactId>
<version>0.36.8</version>
</dependency>
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.13.1</version>
</dependency>
在common包下面建一个MarkdownToHTML类:
package com.example.demo.common;
import com.vladsch.flexmark.html.HtmlRenderer;
import com.vladsch.flexmark.parser.Parser;
import org.jsoup.Jsoup;
public class MarkdownToHTML {
public static String MtoH(String markdown) {
// 1: Convert Markdown to HTML
Parser parser = Parser.builder().build();
HtmlRenderer renderer = HtmlRenderer.builder().build();
String html = renderer.render(parser.parse(markdown));
// 2: Remove Image tags from HTML
html = html.replaceAll("<img[^>]*>", "");
// 3: Extract plain text from HTML
String text = Jsoup.parse(html).text();
// 4: Output the results
System.out.println(text);
return text;
}
}
最后在上面的ArticleController类中的 foreach中加入一个调用
@RequestMapping("/getlist")
public AjaxResult getMyList(HttpServletRequest request) {
UserInfo userInfo = UserSessionUtils.getUser(request);
if (userInfo == null) {
//说明当前不存在session,也就是没有登录(虽然存在拦截器,但是还是要进行判断一下是否是真的登录了)
return AjaxResult.fail(-1, "非法请求");
}
//说明已经正常登录了
//这里涉及到了userinfo和articleinfo两张表的关系了
//在articleinfo表中id表示每篇文章对应的id,uid表示用户信息
//在userinfo中id表示用户的信息,所以userinfo中id对应着articleinfo表中uid,所以这里使用的是userInfo.getId()
List<ArticleInfo> list = articleService.getMyList(userInfo.getId());
for (ArticleInfo listArr : list) {
//进行调用
listArr.setContent(MarkdownToHTML.MtoH(listArr.getContent()));
if(listArr.getContent().length() > 200){
listArr.setContent(listArr.getContent().substring(0,100) + "......");
}
}
return AjaxResult.success(list);
}
修改文章
ArticleMapper:
//修改文章
int update(ArticleInfo articleInfo);
ArticleMapper.xml :
<update id="update">
update articleinfo set title = #{title},content = #{content}, updatetime = #{updatetime}
where id = #{id} and uid = #{uid};
</update>
ArticleService :
public int update(ArticleInfo articleInfo){
return articleMapper.update(articleInfo);
}
ArticleController :
//修改文章
@RequestMapping("update")
public AjaxResult update(HttpServletRequest request, ArticleInfo articleInfo) {
//首先要进行非空校验
//注意:这里还有多判断一个id是否为空,修改文章就要确保传过来的文章id不是空的
if(articleInfo == null || !StringUtils.hasLength(articleInfo.getTitle())
|| !StringUtils.hasLength(articleInfo.getContent())
||articleInfo.getId() == null ) {
return AjaxResult.fail(-1,"非法请求");
}
//得到当前登录用户的id
UserInfo userInfo = UserSessionUtils.getUser(request);
if(userInfo == null || userInfo.getId() <= 0){
return AjaxResult.fail(-2,"无效用户");
}
//修改文章的核心代码!将登录用户的id赋值给articleinfo的uid中,这样执行SQL的时候就会使用登录用户的id了
//要是执行SQL的时候,发现数据库中文章与uid对不上,就不会执行修改操作了
articleInfo.setUid(userInfo.getId());
//添加修改时间
articleInfo.setUpdatetime(LocalDateTime.now());
return AjaxResult.success(articleService.update(articleInfo));
}
加盐算法
关于加盐算法,可以看看我的另一篇文章
加盐算法的实现思路和具体代码
实现文章的分页功能
最终要实现的四个小功能(首页、上一页、下一页、末页)能分页显示所有的用户写的文章
分页的关键分析:
前端要获取:当前的页数【此时固定每页显示2条文章】
后端要获取:当前的页数、每页中显示最大的条数
显示第一页: select * from articleinfo limit 2;
显示第二页: select * from articleinfo limit 2 offset 2;
显示第三页: select * from articleinfo limit 2 offset 4;
显示第四页: select * from articleinfo limit 2 offset 6;
在写SQL分页语句的时候:offset后面的数字就是跳过多少条文章,在显示第二页的时候就要跳过前两篇文章,显示第三页的时候就要跳过前4篇文章
所以关于分页的规律也就出来了: offest x , 这个x = (页码-1)* 每页显示的最大文章数
在搞定了offset的公式之后,就要考虑一下怎么计算出一共有多少页数
- 拿到所有的文章数
- 文章总数 / 每页显示的最大的文章数(涉及到精度丢失的问题)
- 面对小数怎么应对?
//获取当前一共要有多少页
//首先求出总共有多少条数据
int Count = articleService.getCount();
double temp = Count/(psize * 1.0);//变成double,避免使用int造成精度丢失
int pages = (int) Math.ceil(temp);//ceil的方法的作用就是将小数向上提成整数,eg:2.2-->3,要是已经是整数的话就不会改变
开始写后端的代码:
ArticleMapper:
//分页显示文章
//这里的psize是每页显示的最大条数,offsize就是offset后面的数字,由于offset是关键字所以不方便直接使用
List<ArticleInfo> getListByPage(@Param("psize") Integer psize,@Param("offsize") Integer offsize);
//查询一共有多少篇文章
int getCount();
ArticleMapper.xml :
<select id="getListByPage" resultType="com.example.demo.entity.ArticleInfo">
select * from articleinfo limit #{psize} offset #{offsize};
</select>
<select id="getCount" resultType="Integer">
select count(*) from articleinfo;
</select>
ArticleService:
public List<ArticleInfo> getListByPage(Integer psize,Integer offsize){
return articleMapper.getListByPage(psize,offsize);
}
public int getCount(){
return articleMapper.getCount();
}
ArticleController:
/**
* 根据分页查询列表
* @param pindex 当前要显示的页码(从1开始,至少为1)
* @param psize 每页最大显示的文章数(至少为1)
* @return
*/
@RequestMapping("/listbypage")
public AjaxResult getListByPage(Integer pindex,Integer psize){
//参数校正,在首页的时候不传参数的话,我要自己手动设置
if(pindex == null || pindex < 1){
pindex = 1;//页码至少是1
}
if(psize == null || psize < 1){
psize = 2;//要是不传每页最大显示数,那就设置成2
}
//分页的公式: offset = (页码-1)*每页最大的显示数
int offset = (pindex -1 )* psize;
List<ArticleInfo> list = articleService.getListByPage(psize,offset);
//获取当前一共要有多少页
//首先求出总共有多少条数据
int Count = articleService.getCount();
double temp = Count/(psize * 1.0);//变成double,避免使用int造成精度丢失
int pages = (int) Math.ceil(temp);//ceil的方法的作用就是将小数向上提成整数,eg:2.2-->3,要是已经是整数的话就不会改变
HashMap<String,Object> hashMap = new HashMap<>();//键值对的形式传进去
hashMap.put("list",list);
hashMap.put("pages",pages);
return AjaxResult.success(hashMap);
}
这就是后端的代码实现,其实分页功能最难的就是找出offset 每页显示的最大文章数 当前的页码 三者之间的关系
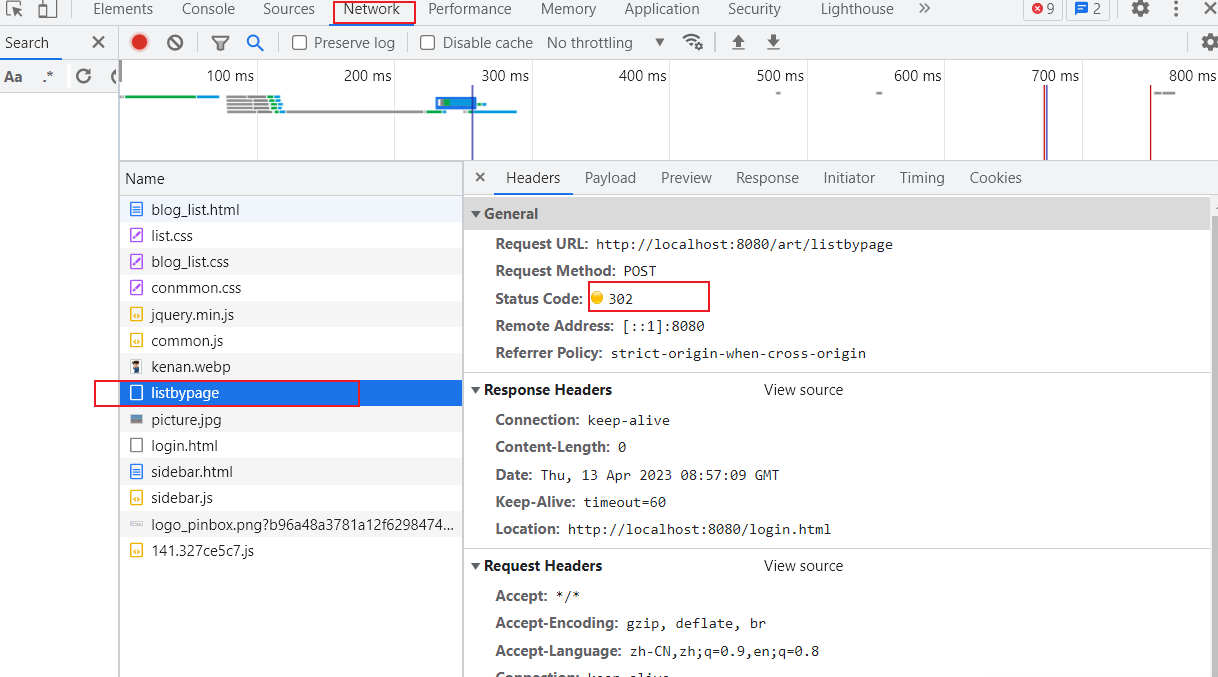
代码运行的时候发现报错了,使用network抓包之后才发现是一个已经很常见的问题: 被拦截器拦截了,所以只要在AppConfig中添加.excludePathPatterns(“/art/listbypage”),不要拦截listbypage接口就行了
Session持久化
现在已经将主要的功能实现了,但是每次重启服务器都要重新输入账号和密码,也就是说session并不能持久保存,可以使用Redis来持久化保存session
首先要引入redis和session对应的依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.session</groupId>
<artifactId>spring-session-data-redis</artifactId>
</dependency>
之后在properties:
spring.session.store-type=redis
spring.redis.host=47.96.166.241
spring.redis.port=6379
#spring.redis.password= 要是Redis没有密码可以不写
server.servlet.session.timeout=1800
spring.session.redis.flush-mode=on_save
spring.session.redis.namespace=spring:session
这样子就完成了将session存储到Redis中,以后重启服务器也不会丢失session
以上就是我的SSM版本的博客系统的所有功能的实现。