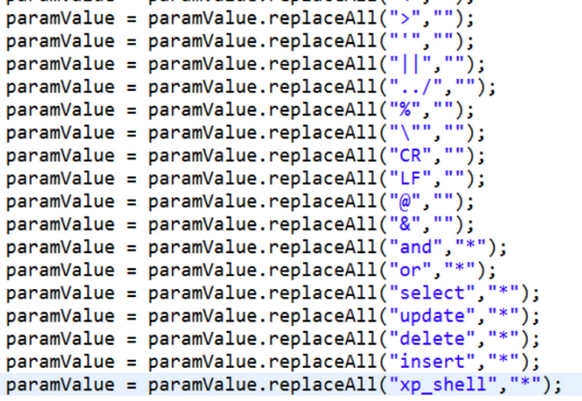
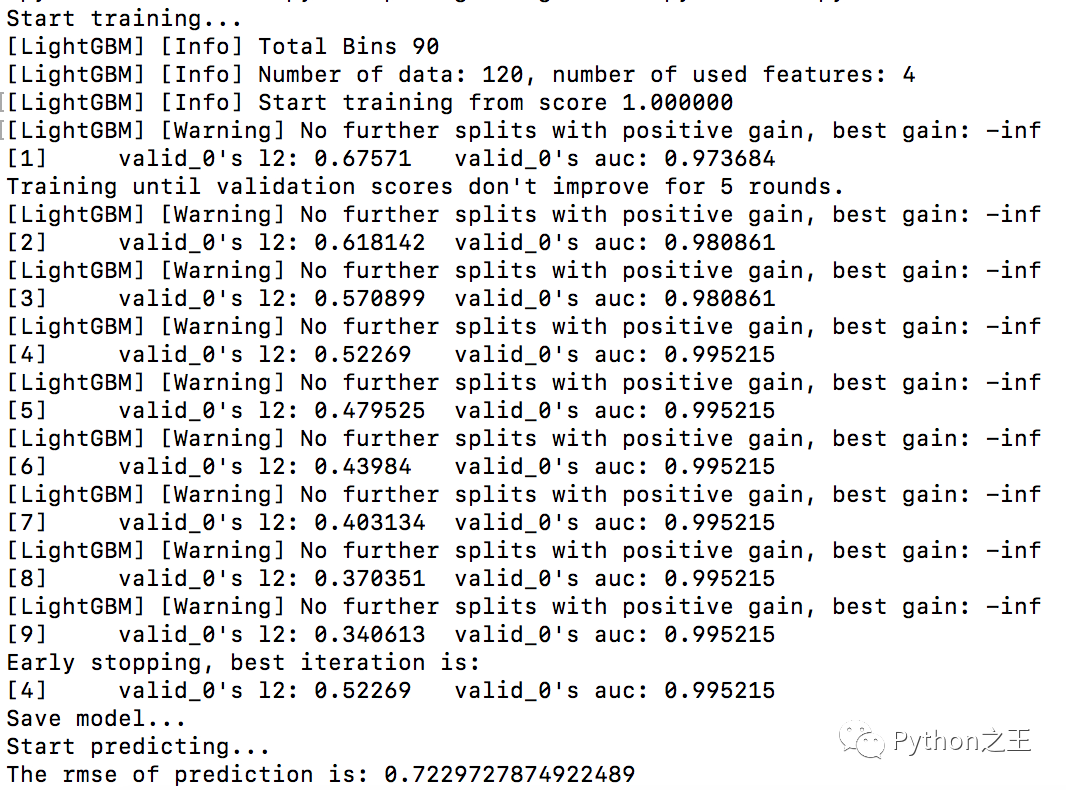
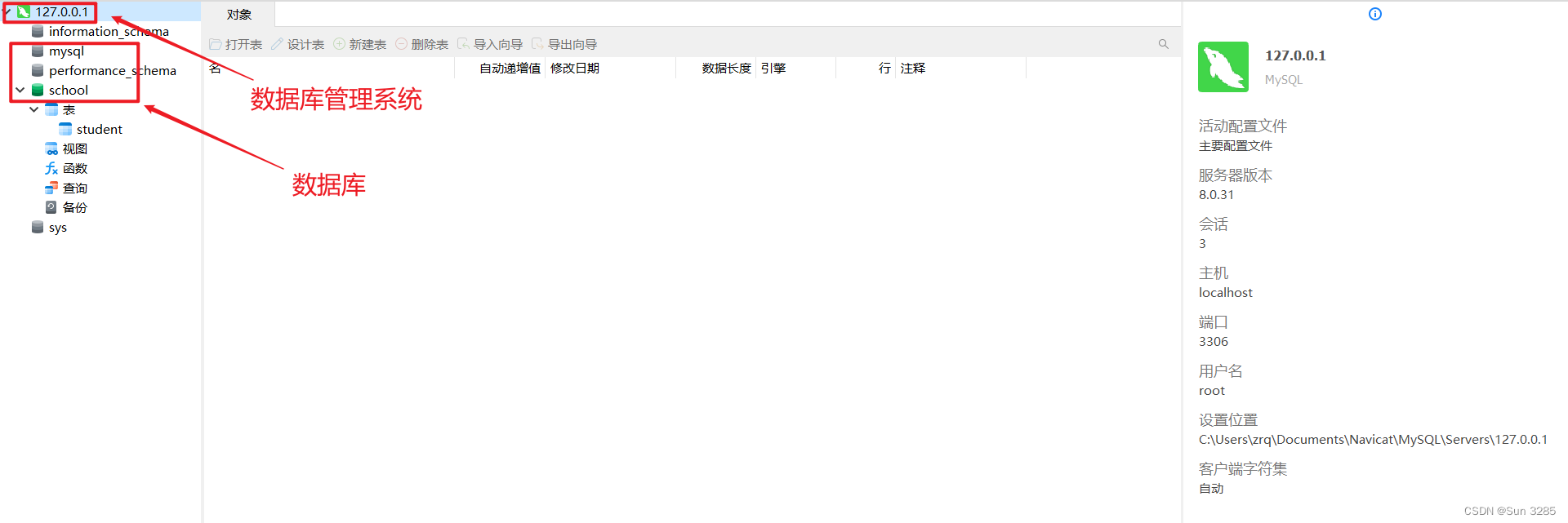
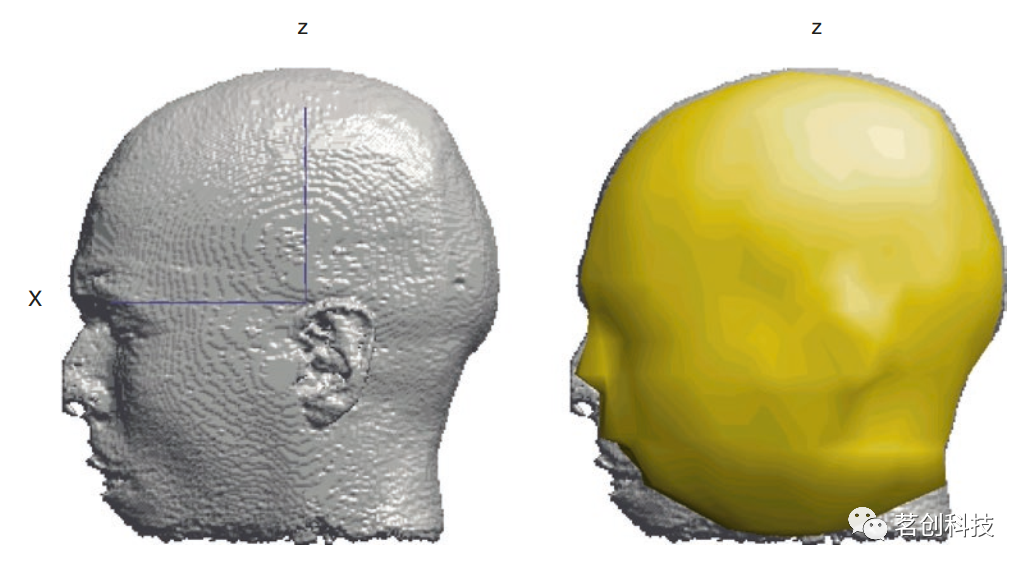
向量:
有y=w*x,取w、x分别如下且y得:
x1 = tc.tensor([[5],[6]], dtype=tc.float32, requires_grad=True)
w = tc.tensor([[10,20],[30,40]], dtype=tc.float32, requires_grad=True)
y1 = tc.mm(w, x1)y1: tensor([[170.],
[390.]], grad_fn=<MmBackward0>)经过backward后取x1.grad为:
y1.backward(tc.tensor([[4],[5]]))x1_Grad: tensor([[190.],
[280.]])这是由于,将得到的
乘以backward中的参数张量[[4],[5]]得此结果。
矩阵
只需把m*n维的矩阵x看成m个向量分别作为输入即可。
例如:
x = tc.tensor([[1,2],[3,4]], dtype=tc.float32, requires_grad=True)
w = tc.tensor([[10,20],[30,40]], dtype=tc.float32, requires_grad=True)
y = tc.mm(w, x)y: tensor([[ 70., 100.],
[150., 220.]], grad_fn=<MmBackward0>)backward一下
y.backward(tc.tensor([[1,2],[2,3]]))结果是和backward中的参数张量[[1,2],[2,3]]相乘得到的
x_Grad: tensor([[ 70., 110.],
[100., 160.]])注意
矩阵A和矩阵B相乘后对A求偏导得B,对B求偏导得。并且y的backward中的参数要和y的维数相同,并且某个变量的梯度是要和自身维数相同的。