pandas之DataFrame基础
- 1. DataFrame定义
- 2. DataFrame的创建形式
- 3. DataFrame的属性
- 4. DataFrame的运算
- 5. pandas访问相关操作
- 5.1 使用 loc[]显示访问
- 5.2 iloc[] 隐式访问
- 5.3 总结
- 6. 单层索引和多层级索引
- 6.1 索引种类与使用
- 6.2 索引相关设置
- 6.3 索引构造
- 6.4 索引访问
- 6.5 索引变换
1. DataFrame定义
DataFrame是一个二维的表格型数据结构,可以看做是由Series组成的字典(共用同一个索引)DataFrame由按一定顺序排列的【多列】数据组成,每一列的数据类型可能不同- 设计初衷是将
Series的使用场景从一维拓展到多维,DataFrame即有行索引,也有列索引
2. DataFrame的创建形式
-
使用列表创建,并设置行索引与列索引
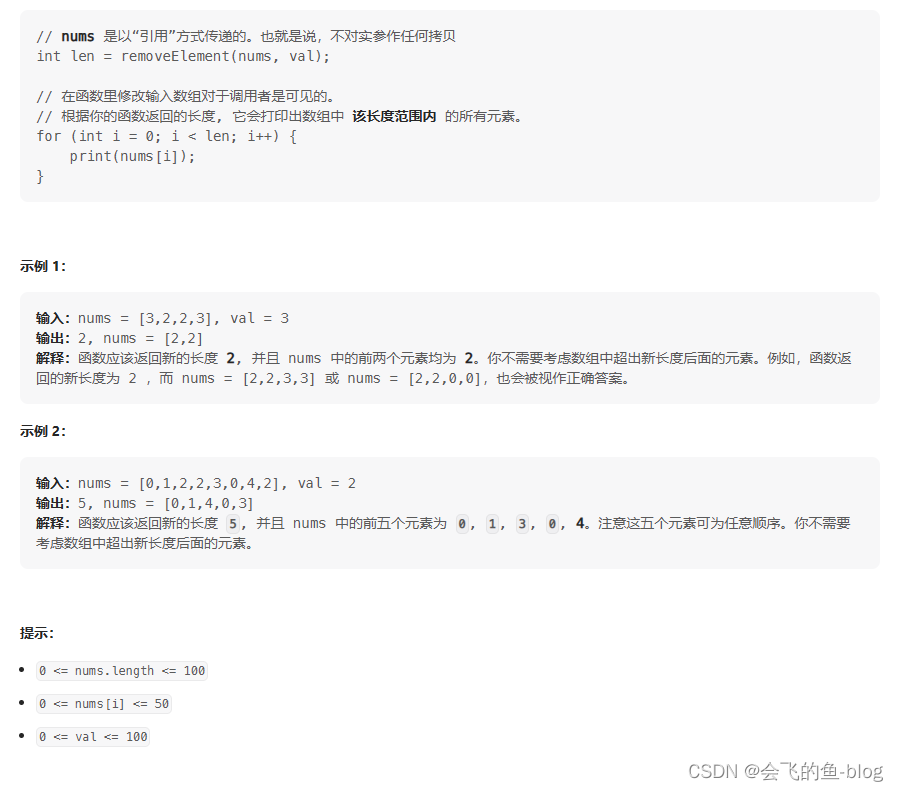
#data:构造DataFrame的数据 pd.DataFrame(data=data, index=index, columns=columns) data=np.random.randint(0,100,size=(3,4)) index=['tom','lucy','alex'] columns=['语文','数学','物理','化学'] df1=pd.DataFrame(data=data,index=index,columns=columns) -
from dict of Series or dicts使用一个由Series构造的字典或一个字典构造#通过字典套Series方式创造DataFrame names=pd.Series(data=['lucy','mery','tom'],index=list('ABC')) scores=pd.Series(data=np.random.randint(0,100,size=3),index=list('ABC')) df2=pd.DataFrame(data={ "names":names, "scores":scores }) -
from dict of ndarrays/lists使用一个由列表或ndarray构造的字典构造,ndarrays必须长度保持一致#通过字典套列表创建DataFrame dic={ 'name':['user1','user2'], 'score':[90,80] } df3=pd.DataFrame(data=dic) -
from a list of dicts使用一个由字典构成的列表构造#列表套字典创建DataFrame dic1={ 'name':'lucy', 'score':90 } dic2={ 'name':'user', 'score':80 } lis=[dic1,dic2] df4=pd.DataFrame(data=lis) -
DataFrame.from_dict()函数构造#字典套ndarry构造 names=['lucy','tom'] yuwen=np.random.randint(0,100,size=2) shuxue=np.random.randint(0,100,size=2) dic={ "name":names, "语文":yuwen, '数学':shuxue } df5=pd.DataFrame(data=dic)
3. DataFrame的属性
| 属性 | 含义 |
|---|---|
index | 行索引 |
columns | 列索引 |
values | 值 |
dtype | 列数据类型 |
score=pd.DataFrame(data={
"name":pd.Series(data=['lucy','mery','tom'],index=list('ABC')),
"score":pd.Series(data=np.random.randint(0,100,size=3),index=list('ABC'))
})
score.dtypes #列数据类型
# name object
# score int32
# dtype: object
score.values #获取所有值 array([['lucy', 66], ['mery', 88],['tom', 71]], dtype=object)
score.index #列索引 Index(['A', 'B', 'C'], dtype='object')
score.columns #行索引 Index(['name', 'score'], dtype='object')
4. DataFrame的运算
-
与非
pandas对象的运算 【服从广播机制】运算方式 运算含义 相关代码 与数值相加 各个位置都会加上这个数值 【广播机制】 
列相同 对应列位置相加 
行列不同 不可加,DataFrame是根据索引匹配,不匹配报错 
df=pd.DataFrame(data=np.random.randint(0,100,size=(3,4)),columns=list('ABCD'))
df+10
arr1=np.array([1,2,3,4])
df + arr1
arr2=np.random.randint(0,20,size=(2,2))
df + arr2
-
与
Series对象运算-
DateFrame和Series运算,默认是列索引对齐原则,不匹配,补NaN -
用
add函数指定轴向index为行,不匹配补NaNs=pd.Series(data=[1,2,3],index=[1,2,3]) df=pd.DataFrame(data=np.random.randint(0,100,size=(3,4)),columns=list('ABCD')) s+df df.add(s,axis='index')
-
-
与
DataFrame对象运算对齐方式 方法 索引对齐原则 (row/columns)对不齐补空值 使用 add/sub/mul/div函数处理空值 -
python操作符与pandas操作函数的对应表- 根据索引匹配,不匹配补NaN,匹配进行运算
- 填充方式:根据索引匹配,不匹配适用fill_value填充,匹配进行运算
- 注意:DataFrame与Series运算,不支持fill_value属性
字符 函数 +add()-sub(),subtract()*mul(),multiply()/truediv(),div(),divide()//floordiv()%mod()**pow()df1=pd.DataFrame(data=np.random.randint(0,10,size=(3,3)),columns=list('ABC')) df2=pd.DataFrame(data=np.random.randint(0,10,size=(2,2)),columns=list('BA')) df1+df2 df1.add(df2,fill_value=0)
-
numpy functionsarr = np.random.randint(-10, 10, size=(3,3)) df=pd.DataFrame(data=arr) #求每个数的绝对值 np.abs(df)
-
转置运算
df=pd.DataFrame(data=np.random.randint(-10,10,size=(3,3))) #对角线翻转 df.T
5. pandas访问相关操作
ndarray(ndim_index,ndim_index2…)
ndim_index支持:索引,索引列表,bool列表,切片,条件表达式
- 注意:使用索引切片都是左闭右开,使用标签切片的都是闭合区间
| 访问形式 | 含义 |
|---|---|
loc[] | 显示访问:在pandas对象中,可以使用标签的形式访问数据 |
iloc[] | 隐式访问,在pandas对象中,也可以使用index的形式访问数据 |
5.1 使用 loc[]显示访问
s.loc[index]
s.loc[row_index,col_index]
index支持:索引(index),索引列表(index_list),布尔列表(bool_list),条件表达式,切片(左闭右开)
| 显示索引访问形式 | 相关代码 |
|---|---|
df.loc[0,'A'] | 取指定位置的数,第0行,第A列 |
df.loc[0] | 获取指定行,默认取行索引 |
df.loc[:,['A','B']] | 取AB列,但是不能跳过行索引直接取列索引,所以前面用切片取所有 |
df.loc[[1,2],['B','C']] | 取前两行,AB列 |
df.loc[np.array([True,False,False,False,False])] | 通过bool列表获取列,bool长度要与行一致 |
bool_list=pd.Series(data=np.array([True,True,False,False,False,True]),index=[0,4,1,2,3,5]) df.loc[bool_list] | 创建Series,将行0,4,5行设为True,其他为False,取所要的行 |
bool_list=pd.Series(data=np.array([True,True,False,False,False,True]),index=[0,4,1,2,3,5]) df.loc[:,bool_list.values] | 获取所有行,将bool_list的bool值赋值给列 |
s.loc['b':'c'] | 切片访问,显示索引闭合区间,左闭右闭 |
s.loc[['b','c']] | 索引访问 |
s.loc[[False,True,True,False,False]] | 布尔值访问 |
s.loc[s>6] | 条件语句访问 |
df = pd.DataFrame(data=np.random.randint(0,10,size=(5,6)), columns=list('ABCDEF'))
df.loc[0,'A']
df.loc[0]
df.loc[:,['A','B']]
df.loc[[1,2],['B','C']]
df.loc[np.array([True,False,False,False,False])]
bool_list=pd.Series(data=np.array([True,True,False,False,False,True]),index=[0,4,1,2,3,5])
df.loc[bool_list]
df.loc[:,bool_list.values]
s=pd.Series(data=np.random.randint(0,10,size=5),index=list('abcde'))
s.loc['b':'c']
s.loc[['b','c']]
s.loc[[False,True,True,False,False]]
s.loc[s>6]
5.2 iloc[] 隐式访问
s.iloc[index]
s.iloc[row_index,col_index]
index支持:索引(index),索引列表(index_list),布尔列表(bool_list),条件表达式,切片(左闭右开)
| 隐示索引访问形式 | 相关代码 |
|---|---|
df.iloc[:,0] | 获取所有行,第一列 |
df.iloc[0:3] | 获取所有行,0,1,2列 【切片获取,左闭右开】 |
df.iloc[[True,False,True,False,False]] | bool列表获取索引 |
df = pd.DataFrame(data=np.random.randint(0,10,size=(5,6)), columns=list('ABCDEF'))
df.iloc[:,0]
df.iloc[[True,False,True,False,False]]
df.iloc[0:3]
-
间接访问
df = pd.DataFrame(data=np.random.randint(0,10,size=(5,6)), columns=list('ABCDEF')) #间接访问,不提倡,赋值时会分不清到底修改了谁 df.loc[0].loc['B']=10 #标签访问列 df[['A','B']] #切片访问行 df[0:2]
5.3 总结
- 注意:直接用中括号访问
- 标签访问的是列,标签切片访问的是行
6. 单层索引和多层级索引
6.1 索引种类与使用
-
怎么使用索引?
pd.Index是pandas提供的专门用于构造索引的类,它有很多类,CategoricalIndex,RangeIndex- 所有的子类都具备
Index类的特点,比如可以使用索引访问元素 - 通常如果需要对索引定制
(name),可以使用pd.Index系列方法来构造索引 - 如果没有特殊需求,使用普通的列表完全没有问题
-
索引种类【不是很知道区别,实际好像没有用到过】
| 种类 | 含义 |
|---|---|
| RangeIndex | 实现单调整数范围的索引. |
| CategoricalIndex | 索引类分类 |
| MultiIndex | 多级索引 |
| IntervalIndex | 类间隔索引 |
| DatetimeIndex, TimedeltaIndex, PeriodIndex,Int64Index, UInt64Index, Float64Index | 其他种类 |
6.2 索引相关设置
| 索引相关设置 | 代码 |
|---|---|
重新设置index索引 | df.index=list('abcde') |
重新设置columns索引 | df.columns = [1,2,3] |
设置索引名称为index | pd.RangeIndex(start=0,stop=5,step=1,name='index') |
其他pd对象索引赋值给另一个pd对象 | df.index=m_index |
df=pd.DataFrame(data=np.random.randint(0,10,size=(5,3)),columns=list('ABC'))
df.index=list('abcde')
df.columns = [1,2,3]
m_index=pd.RangeIndex(start=0,stop=5,step=1,name='index')
df.index=m_index
6.3 索引构造
-
单层索引,使用
pd.index() -
多层索引构造
- 使用
arrays MultiIndex.from_arrays()
columns=pd.MultiIndex.from_arrays([['第一学期','第一学期','第一学期','第二学期','第二学期','第二学期'], ['lucy','tom','hello','lucy','tom','hello']]) index=list('ABC') data=np.random.randint(0,100,size=(3,6)) df=pd.DataFrame(data=data,index=index,columns=columns) #可以直接作为多层索引使用,不需要构造MutiIndex对象 #pd.MutiIndex.from_arrays([必须是一个额为数组结构]) #模范,不采用,理解即可-
使用
tuple pd.MulitiIndex.from_tuplestuples=pd.MultiIndex.from_tuples([ ('第一期','lucy'), ('第一期','tom'), ('第一期','hello'), ('第二期','lucy'), ('第二期','tom'), ('第二期','hello'), ]) index=list('ABC') data=np.random.randint(0,100,size=(3,6)) df=pd.DataFrame(data=data,index=index,columns=columns) -
使用
product pd.MultiIndex.from_productlevel1=['第一期','第二期'] level2=['A','B','C'] #level1与level2自动匹配 #列索引为期数与产品 data=np.random.randint(0,100,size=(3,6)) columns=pd.MultiIndex.from_product([level1,level2],names=['期数','产品']) index=pd.Index(data=['lucy','tom','hello'],name='销售员') df=pd.DataFrame(data=data,index=index,columns=columns) level1=['第一期','第二期'] level2=['A','B','C'] #行索引为期数与销售员 index=pd.MultiIndex.from_product([['第一期','第二期'],['lucy','tom','hello']],names=['期数','销售员']) columns=pd.Index(data=['A','B','C'],name='产品') data = np.random.randint(0, 100, size=(6,3)) df=pd.DataFrame(data=data,index=index,columns=columns)
- 使用
6.4 索引访问
- 多层索引访问逻辑
- 多层索引的访问逻辑,与单层索引的访问逻辑完全一致
- 但是:多层索引的索引表达形式是以元组的方式处理的
- 多层索引创建
level1,level2=['第一期','第二期'],['lucy','tom','hello'] #行索引为期数与销售员 index=pd.MultiIndex.from_product([level1,level2],names=['期数','销售员']) columns=pd.Index(data=['A','B','C'],name='产品') data = np.random.randint(0, 100, size=(6,3)) df=pd.DataFrame(data=data,index=index,columns=columns)
- 多层索引访问【元祖形式访问】
#显示索引 df.loc[('第一期','hello')] df.loc[[('第一期','lucy'),('第二期','lucy')]] df.loc['第一期'].loc['tom'] df.sort_index(inplace=True) #使用babels df.loc[('第一期','lucy'):('第二期','lucy')]

6.5 索引变换
-
unstack把行索引向列索引变换level1,level2=['第一期','第二期'],['lucy','tom','hello'] #行索引为期数与销售员 index=pd.MultiIndex.from_product([level1,level2],names=['期数','销售员']) columns=pd.Index(data=['A','B','C'],name='产品') data = np.random.randint(0, 100, size=(6,3)) df=pd.DataFrame(data=data,index=index,columns=columns) display(df,df.unstack())

-
stcak把列索引向行索引变换df.stack()