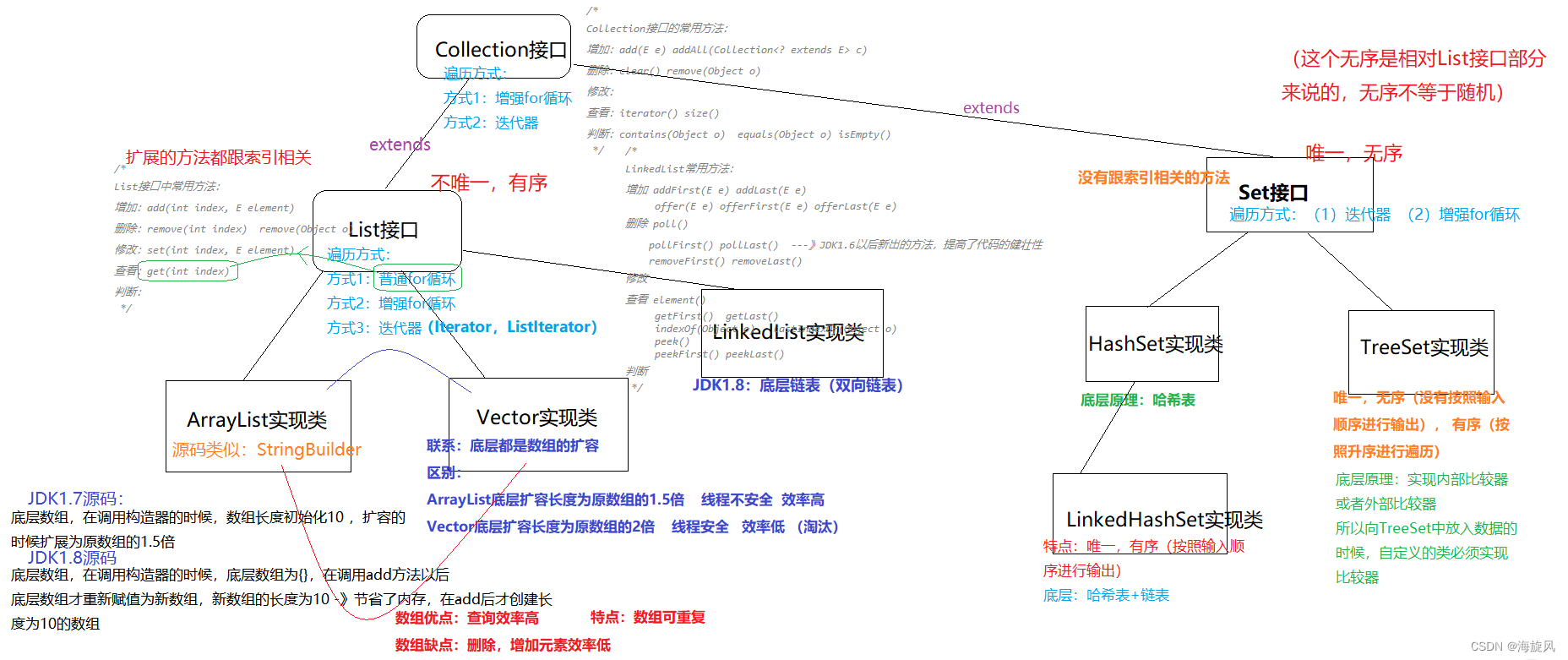
一、HashSet实现类
1.常用方法
增加:add(E e)
删除:remove(Object o)、clear()
修改:
查看:iterator()
判断:contains(Object o)、isEmpty()
常用遍历方式:
Set<String> set = new HashSet<String>();
set.add("aa");
set.add("bb");
set.add("cc");
//1.迭代器打印
Iterator iterator = set.iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next());
}
//2.增强for
for (String s : set) {
System.out.println(s);
}
//3.直接输出
System.out.println(set);
2.JDK1.8(jdk1.8.0_361)源码下(简要)
public class HashSet<E> extends AbstractSet<E>
implements Set<E>, Cloneable, java.io.Serializable
{
//成员变量
private transient HashMap<E,Object> map; //HashSet存储主体
private static final Object PRESENT = new Object();
//构造器,可以看出来底层是用的HashMap来实现的,这块需要对HashMap源码熟悉
//创建出来的时候,数组是null,只有调用add方法才会进行数组初始化
//Constructs a new, empty set; the backing HashMap instance has default initial capacity (16) and load factor (0.75).
//构造一个具有默认初始容量(16)和负载因子(0.75)的新的,空的链接散列集
public HashSet() {
map = new HashMap<>();
}
public HashSet(Collection<? extends E> c) {
map = new HashMap<>(Math.max((int) (c.size()/.75f) + 1, 16));
addAll(c);
}
public HashSet(int initialCapacity, float loadFactor) {
map = new HashMap<>(initialCapacity, loadFactor);
}
public HashSet(int initialCapacity) {
map = new HashMap<>(initialCapacity);
}
//这个就是LinkedHashSet创建时会调用的构造器
HashSet(int initialCapacity, float loadFactor, boolean dummy) {
map = new LinkedHashMap<>(initialCapacity, loadFactor);
}
//添加
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
//删除
public boolean remove(Object o) {
return map.remove(o)==PRESENT;
}
public void clear() {
map.clear();
}
}
3.HashSet原理图
public class TestSet {
public static void main(String[] args) {
HashSet<Student> hs = new HashSet<>();
hs.add(new Student(19,"lili"));
hs.add(new Student(20,"lulu"));
hs.add(new Student(18,"feifei"));
hs.add(new Student(19,"lili"));
hs.add(new Student(10,"nana"));
hs.add(new Student(10,"nana"));
System.out.println(hs.size());
//并没有出现唯一数据的情况,为什么呢?
//原因是没有重写Student类的hashcode和equals方法,无法判断是否同一个数据
System.out.println(hs);
HashSet<Integer> hs01 = new HashSet<>();
System.out.println(hs01.add(19));//true
hs01.add(6);
hs01.add(17);
hs01.add(11);
hs01.add(3);
System.out.println(hs01.add(19));//false 这个19没有放入到集合中
System.out.println(hs01.size());//唯一,无序
System.out.println(hs01);
}
}
class Student {
int age;
String name;
public Student(int age, String name) {
this.age = age;
this.name = name;
}
}
运行结果

如果不了解HashMap底层的话,可以结合以下图片进行说明:
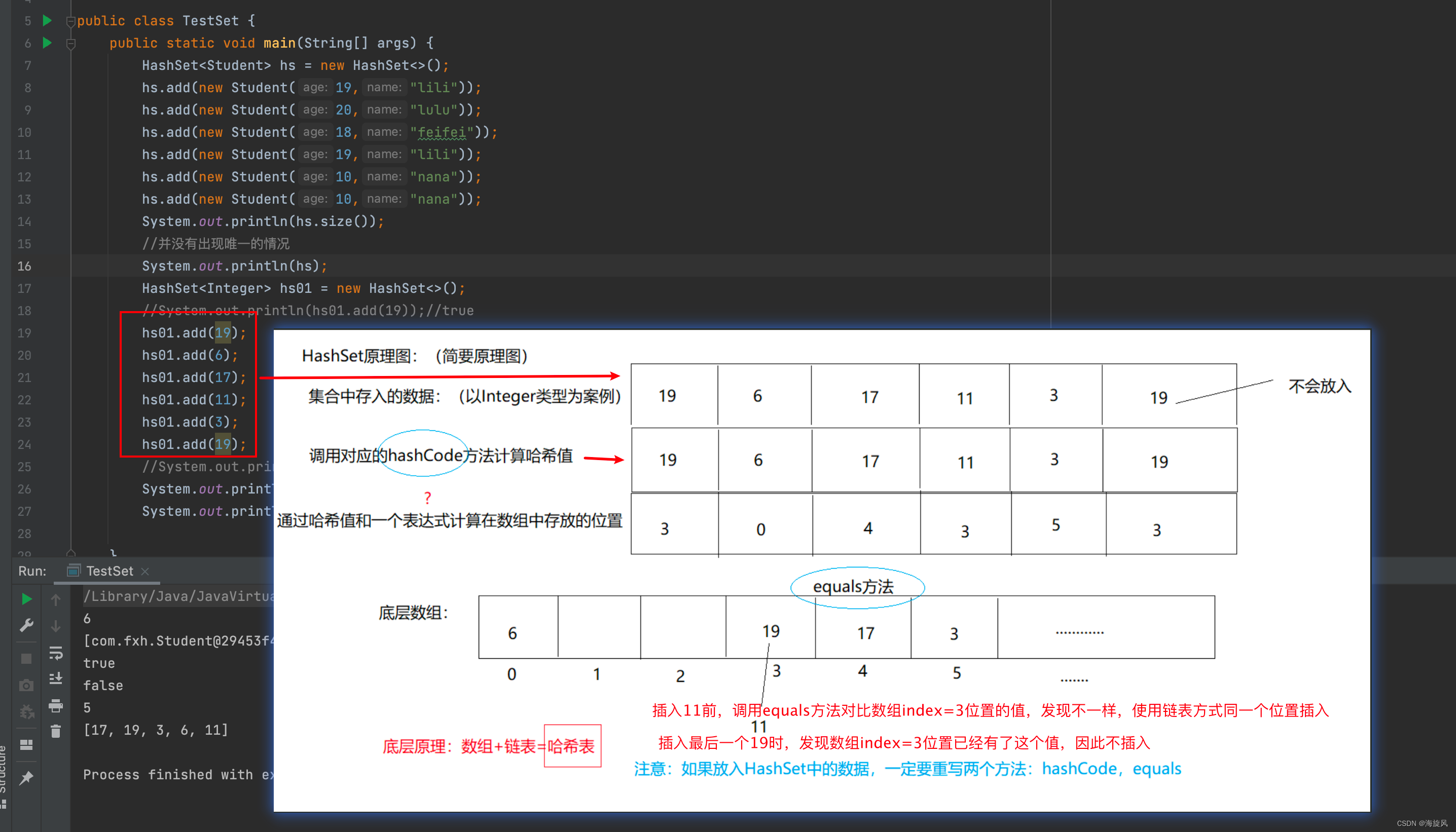
总结:HashSet底层是使用的HashMap类来进行的存储,因此底层存储是通过数组+链表方式实现数据存储的。
HashSet的无序、唯一是基于HashMap(key,PRESENT)来实现的,所以对于基础数据类型、String类型是无序唯一的,但是对于没有重写过hashcode方法和equals方法的引用类来说不是唯一的。这块理解需要解锁前置技能- HashMap。
二、LinkedHashSet实现类
1.常用方法
LinkedHashSet是HashSet的子类,因此方法使用跟HashSet相同
增加:add(E e)
删除:remove(Object o)、clear()
修改:
查看:iterator()
判断:contains(Object o)、isEmpty()
常用遍历方式:...
2.JDK1.8(jdk1.8.0_361)源码
public class LinkedHashSet<E> extends HashSet<E>
implements Set<E>, Cloneable, java.io.Serializable {
//调用父类HashSet的构造方法,构造一个具有默认初始容量(16)和负载因子(0.75)的新的,空的链接散列集。
public LinkedHashSet() {
super(16, .75f, true);
}
public LinkedHashSet(int initialCapacity) {
super(initialCapacity, .75f, true);
}
public LinkedHashSet(Collection<? extends E> c) {
super(Math.max(2*c.size(), 11), .75f, true);
addAll(c);
}
public LinkedHashSet(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor, true);
}
public Spliterator<E> spliterator() {
return Spliterators.spliterator(this, Spliterator.DISTINCT | Spliterator.ORDERED);
}
}
总结,源码非常简短,从调用的构造方法上是可以看出,实际LinkedHashSet底层是使用的LinkedHashMap进行存储。其实就是在HashSet的基础上,多了一个总的链表,这个总链表将放入的元素串在一起,方便有序的遍历,(可以看到LinkedHashMap.Entry 继承自HashMap.Node 除了Node 本身有的几个属性外,额外增加了before after 用于指向前一个Entry 后一个Entry。也就是说,元素之间维持着一条总的链表数据结构。)。这块理解需要有有前置技能- LinkedHashMap和HashMap。
三、比较器(TreeSet理解前置技能)
【1】以int类型为案例:
比较的思路:将比较的数据做差,然后返回一个int类型的数据,将这个int类型的数值 按照 =0 >0 <0
int a = 10;
int b = 20;
System.out.println(a-b); // -10 通过=0 >0 <0来判断
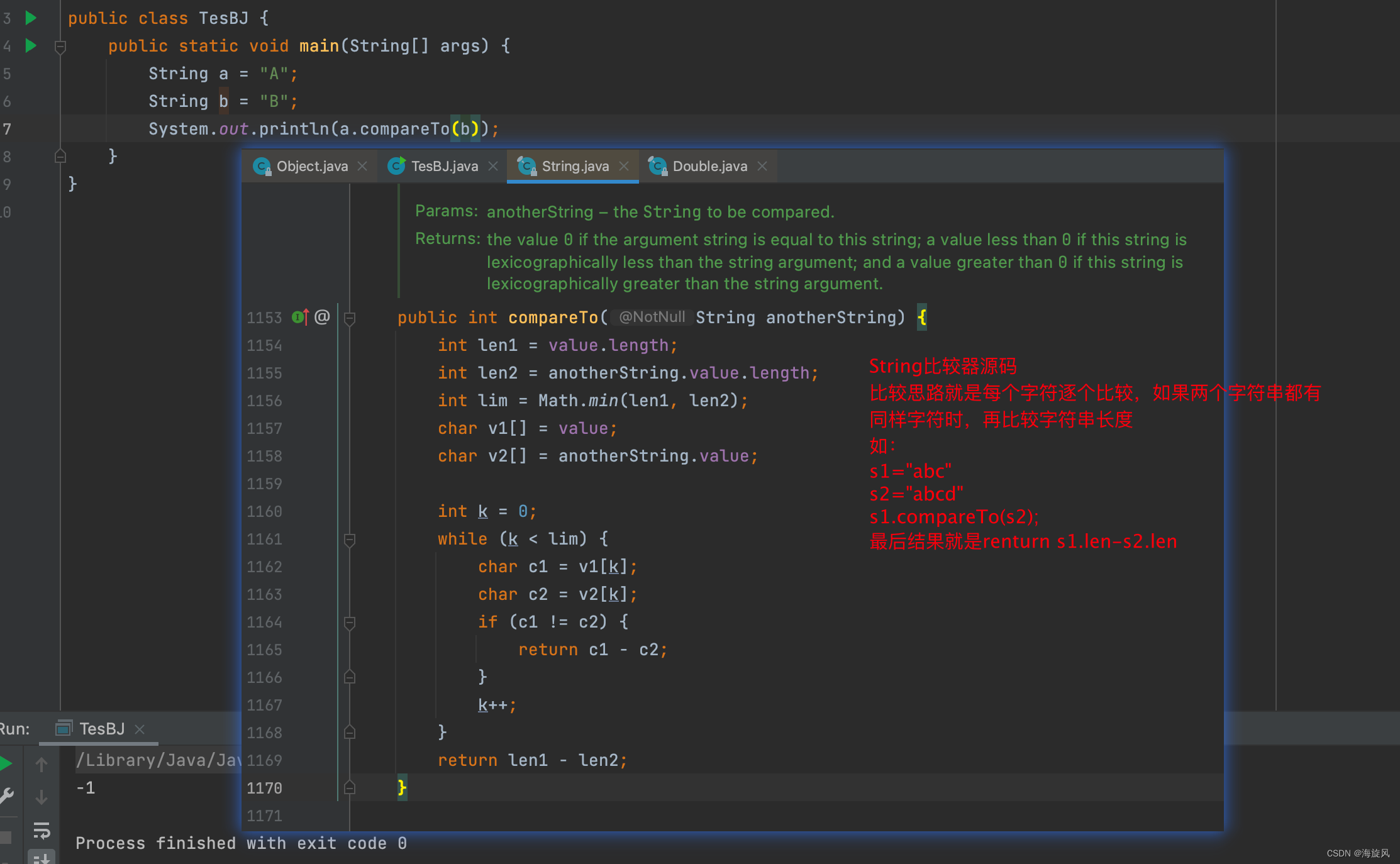
【2】比较String类型数据:
String类实现了Comparable接口,这个接口中有一个抽象方法compareTo,String类中重写这个方法即可
String a = "A";
String b = "B";
System.out.println(a.compareTo(b)); //-1,String比较器源码如下
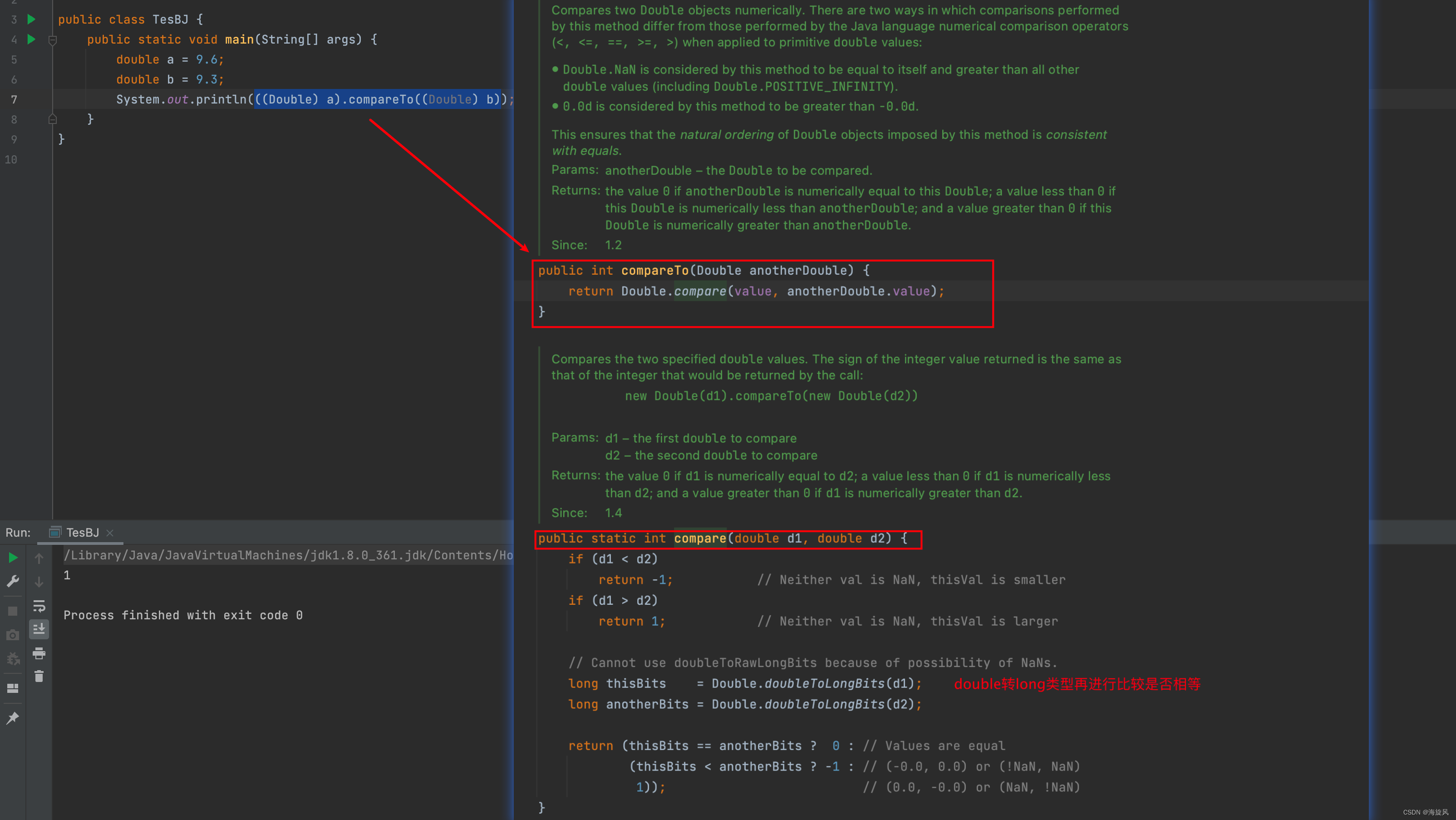
【3】比较double类型数据:
double a = 9.6;
double b = 9.3;
System.out.println(((Double) a).compareTo((Double) b)); //1
【4】比较自定义的数据类型:
(1)内部比较器:
通过实现Comparable接口实现,缺点是只有一个比较方法,不能实现多个不同属性的比较方法
public class Student implements Comparable<Student>{
private int age;
private double height;
private String name;
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public double getHeight() {
return height;
}
public void setHeight(double height) {
this.height = height;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Student(int age, double height, String name) {
this.age = age;
this.height = height;
this.name = name;
}
@Override
public String toString() {
return "Student{" +
"age=" + age +
", height=" + height +
", name='" + name + '\'' +
'}';
}
@Override
public int compareTo(Student o) {
//按照年龄进行比较:
/*return this.getAge() - o.getAge();*/
//按照身高比较
/*return ((Double)(this.getHeight())).compareTo((Double)(o.getHeight()));*/
//按照名字比较:
return this.getName().compareTo(o.getName());
}
}
public class TesBJ {
public static void main(String[] args) {
//比较两个学生:
Student s1 = new Student(14,160.5,"alili");
Student s2 = new Student(14,170.5,"bnana");
System.out.println(s1.compareTo(s2)); //结果 -1
}
}
(2)外部比较器:
import java.util.Comparator;
public class Student{
private int age;
private double height;
private String name;
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public double getHeight() {
return height;
}
public void setHeight(double height) {
this.height = height;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Student(int age, double height, String name) {
this.age = age;
this.height = height;
this.name = name;
}
@Override
public String toString() {
return "Student{" +
"age=" + age +
", height=" + height +
", name='" + name + '\'' +
'}';
}
}
class BiJiao01 implements Comparator<Student> {
@Override
public int compare(Student o1, Student o2) {
//比较年龄:
return o1.getAge()-o2.getAge();
}
}
class BiJiao02 implements Comparator<Student> {
@Override
public int compare(Student o1, Student o2) {
//比较姓名:
return o1.getName().compareTo(o2.getName());
}
}
class BiJiao03 implements Comparator<Student> {
@Override
public int compare(Student o1, Student o2) {
//在年龄相同的情况下 比较身高 年龄不同比较年龄
if((o1.getAge()-o2.getAge())==0){
return ((Double)(o1.getHeight())).compareTo((Double)(o2.getHeight()));
}else{//年龄不一样
return o1.getAge()-o2.getAge();
}
}
}
【5】外部比较器和内部比较器 谁好?
答案:外部比较器,多态,扩展性好
理解完比较器后就能开始看TreeSet的源码了。
四、TreeSet实现类
1.常用方法
HashSet的子类,所以常用方法同HashSet
2.TreeSet使用
【1】存入Integer类型数据:(底层利用的是内部比较器)
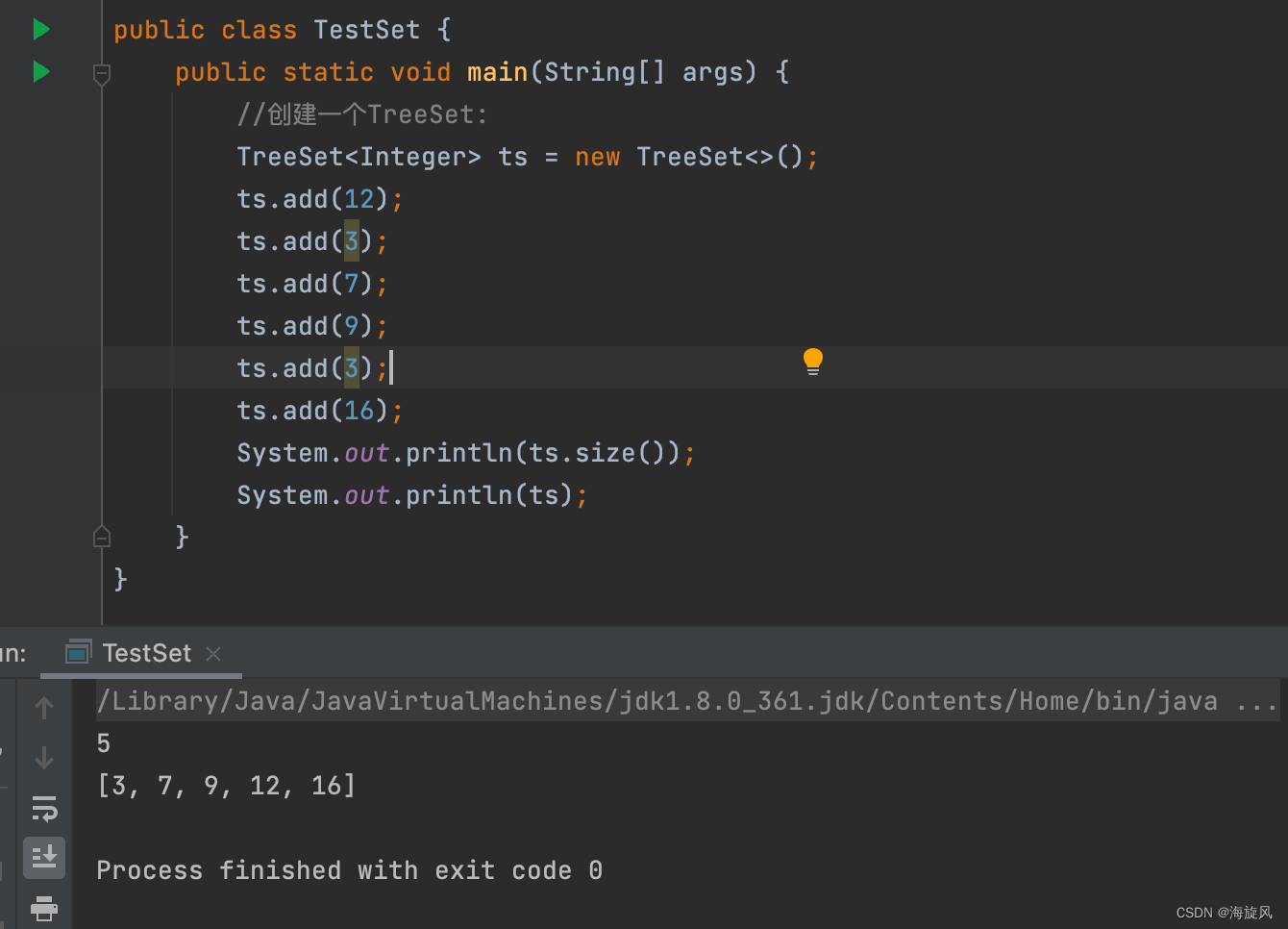
特点:唯一,无序(没有按照输入顺序进行输出), 有序(按照升序进行遍历)
底层原理:二叉树(数据结构中的一个逻辑结构)
TreeSet底层的二叉树的遍历是按照升序的结果出现的,这个升序是靠中序遍历得到的(不熟悉的话得再看一下数据结构与算法):
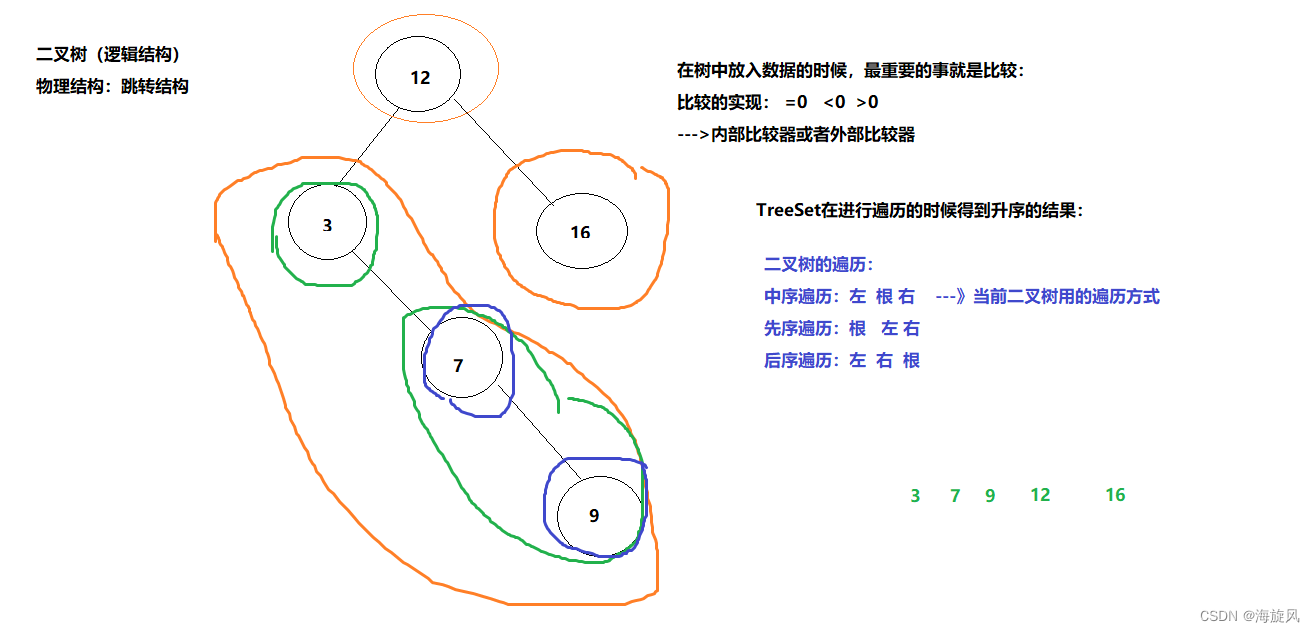
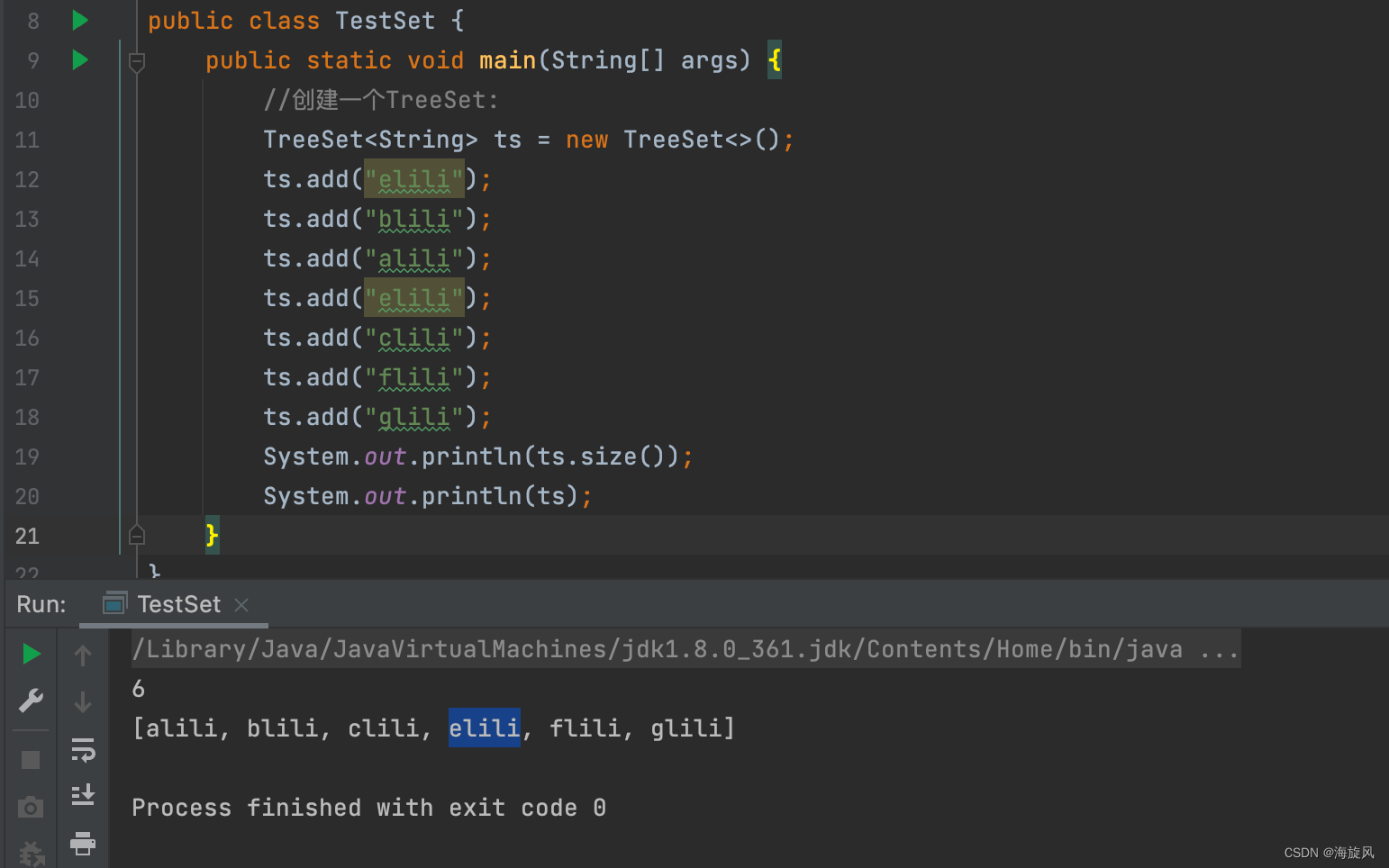
【2】放入String类型数据:(底层实现类内部比较器)
【4】想放入自定义的Student类型的数据:
(1)利用内部比较器:
public class Student implements Comparable<Student> {
private int age;
private String name;
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Student(int age, String name) {
this.age = age;
this.name = name;
}
@Override
public String toString() {
return "Student{" +
"age=" + age +
", name='" + name + '\'' +
'}';
}
@Override
public int compareTo(Student o) {
//按年龄排序
return this.getAge()-o.getAge();
}
}
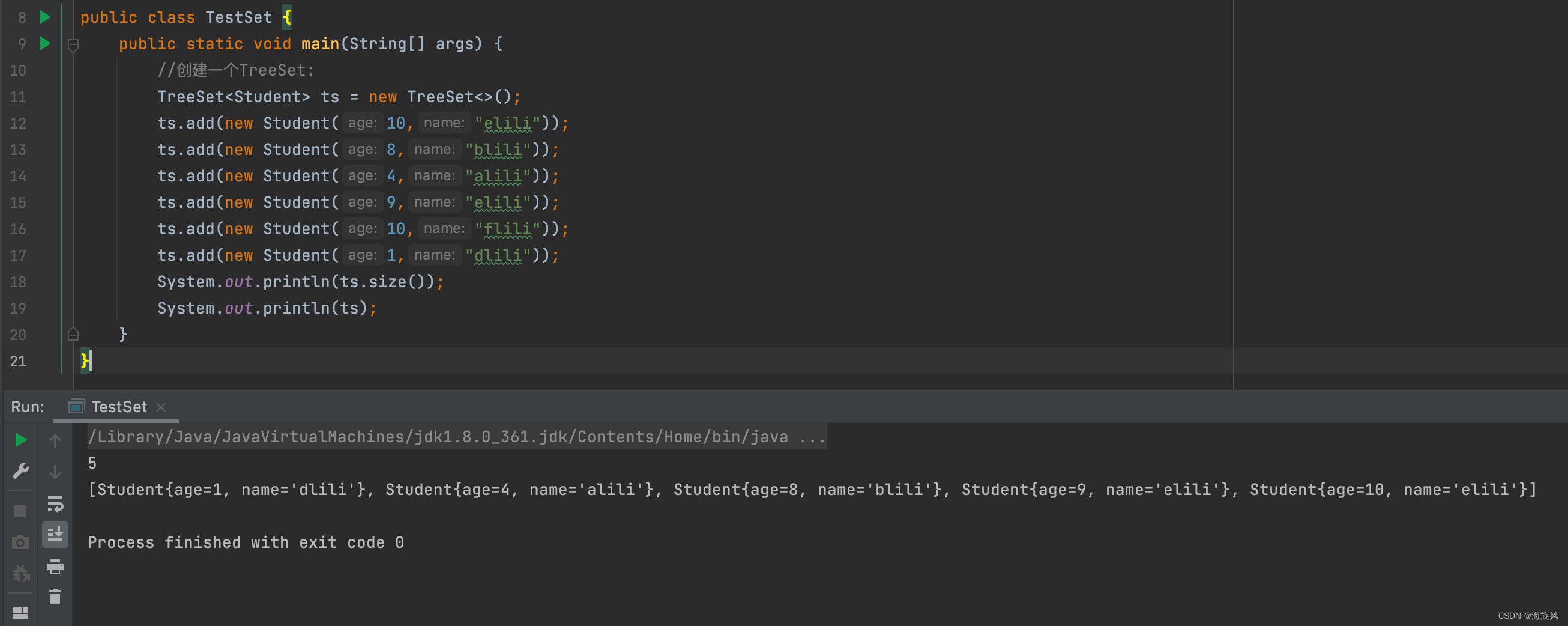
少了一个,是因为比较器按照年龄进行比较,年龄相同的去除掉。TreeSet的add方法内部调用的TreeMap的put方法,详细解析需要看TreeMap源码中put方法中如何调用的比较器,以及根据比较器返回的结果>0 =0 <0做了什么操作,外部比较器同理。
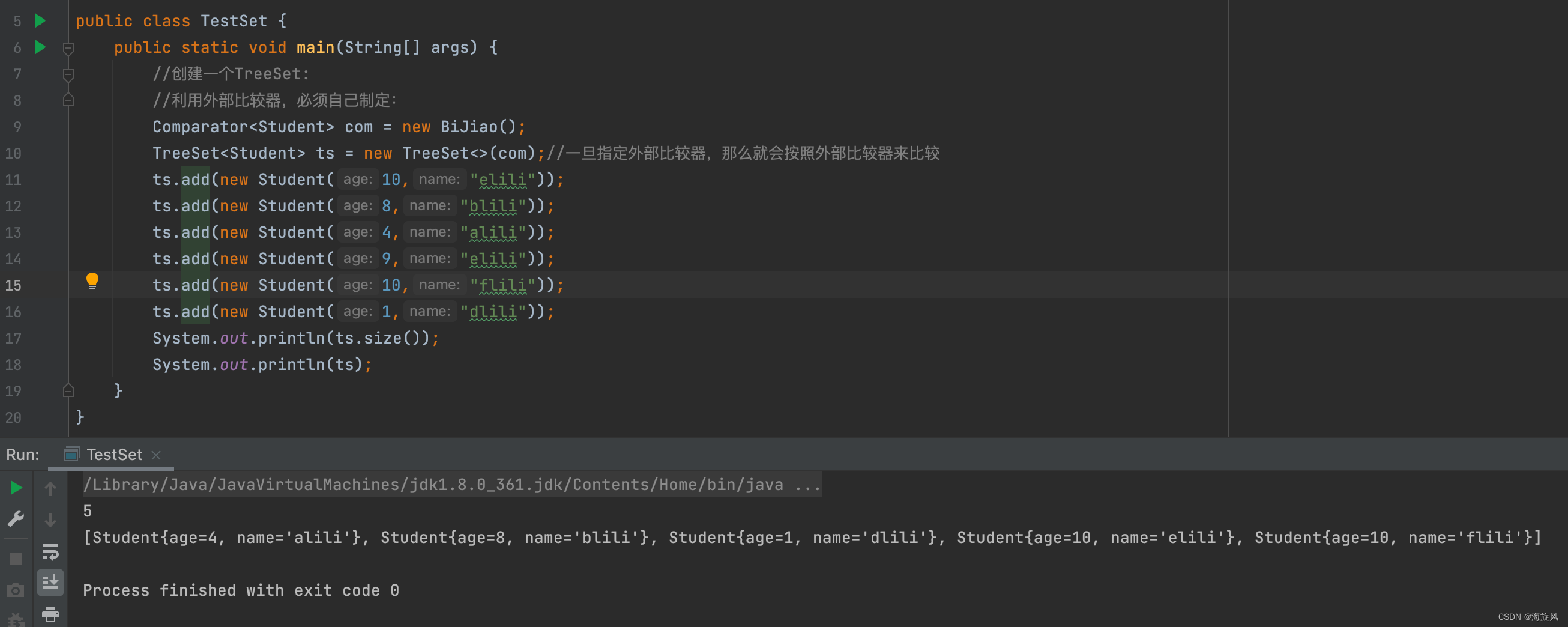
(2)通过外部比较器:
import java.util.Comparator;
public class Student{
private int age;
private String name;
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Student(int age, String name) {
this.age = age;
this.name = name;
}
@Override
public String toString() {
return "Student{" +
"age=" + age +
", name='" + name + '\'' +
'}';
}
}
class BiJiao implements Comparator<Student>{
@Override
public int compare(Student o1, Student o2) {
return o1.getName().compareTo(o2.getName());
}
}
3.JDK1.8(jdk1.8.0_361)源码下(简要)
简要拿出常用部分,其余方法可以自行看jdk1.8的文档,utools软件里面有
public class TreeSet<E> extends AbstractSet<E>
implements NavigableSet<E>, Cloneable, java.io.Serializable
{
//存储的数据就是在这里
//NavigableMap<K,V>是接口,TreeMap<K,V>是这个接口的实现类
private transient NavigableMap<E,Object> m;
//虚拟固定的value
private static final Object PRESENT = new Object();
//没有传参数时,构造器就是直接new TreeMap<E,Object>()再传给下一个构造器
public TreeSet() {
this(new TreeMap<E,Object>());
}
//没有修饰符,只能同包内使用
TreeSet(NavigableMap<E,Object> m) {
//接口=接口实现类,多态
this.m = m;
}
//传入集合c所有元素添加进TreeSet
public TreeSet(Collection<? extends E> c) {
this();
addAll(c);
}
//传入比较器,排序就是根据比较器规则进行处理。
public TreeSet(Comparator<? super E> comparator) {
this(new TreeMap<>(comparator));
}
//SortedSet<E>是接口,NavigableSet<E>接口继承自此接口
//形参是接口,调用传实参是实现类,接口=接口实现类,多态
public TreeSet(SortedSet<E> s) {
this(s.comparator());
addAll(s);
}
//升序迭代器
public Iterator<E> iterator() {
return m.navigableKeySet().iterator();
}
//降序迭代器
public Iterator<E> descendingIterator() {
return m.descendingKeySet().iterator();
}
//以降序返回一个新的 TreeSet 集合
public NavigableSet<E> descendingSet() {
return new TreeSet<>(m.descendingMap());
}
//元素个数
public int size() {
return m.size();
}
//是否为空
public boolean isEmpty() {
return m.isEmpty();
}
//是否含有元素o
public boolean contains(Object o) {
return m.containsKey(o);
}
//添加
public boolean add(E e) {
return m.put(e, PRESENT)==null;
}
//删除
public boolean remove(Object o) {
return m.remove(o)==PRESENT;
}
//清空元素
public void clear() {
m.clear();
}
}
总结:TreeSet部分源码较多,简化出了常用的方法。这块的理解需要了解TreeMap源码和树结构。
五.Collection部分整体结构图