一、使用的库
import requests
from lxml import etree
import time
import random
import re
import openpyxl
import openpyxl
from pyecharts.charts import Bar, Pie
from pyecharts import options as opts
from multiprocessing.dummy import Pool二、数据爬取思路
1.网站地址分析
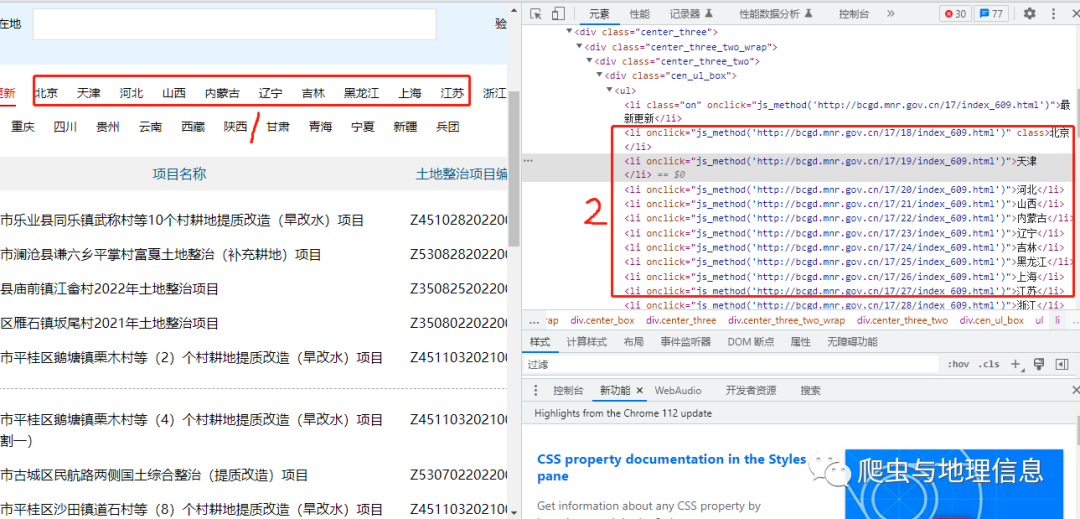
自然资源部官方网站上【补充耕地项目与地块信息公开】模块里面有全国补充耕地项目信息,主页地址为:http://bcgd.mnr.gov.cn/。点击不同的省份按钮,会自动跳转到对应省份项目清单。
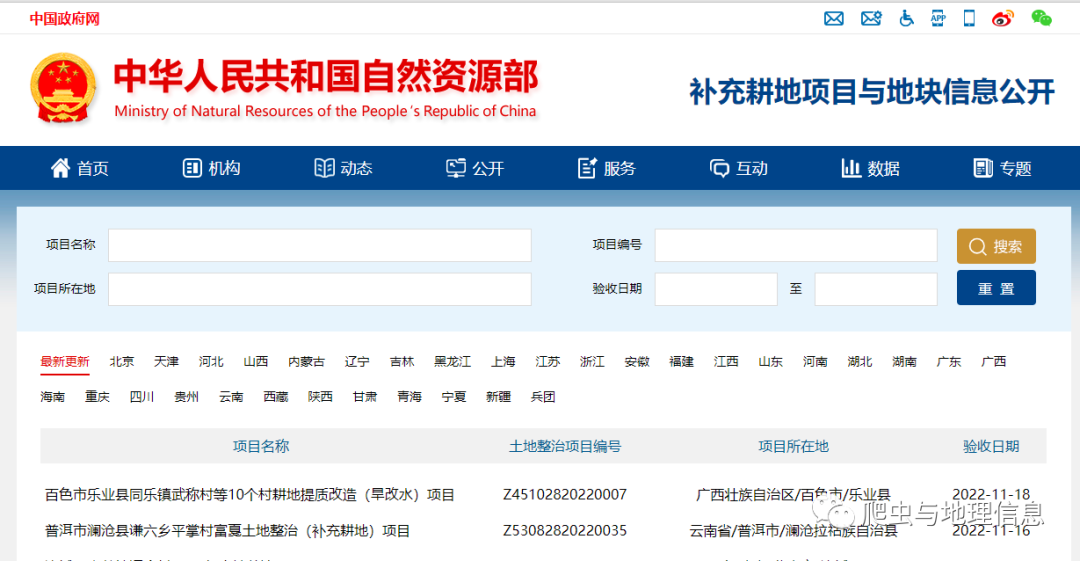
在浏览器中右击检查,分析网站结构发现,省份信息包含在一个无序列表ul标签中,里面每个省份的链接地址与名称信息包含在一个li标签中,基于XPath语法很容易即可得到每个省份对应url地址。需要注意的是,第一个li标签是最新项目信息,爬取时可进行跳过。
以北京为例,从下图发现每页最多显示20条项目信息