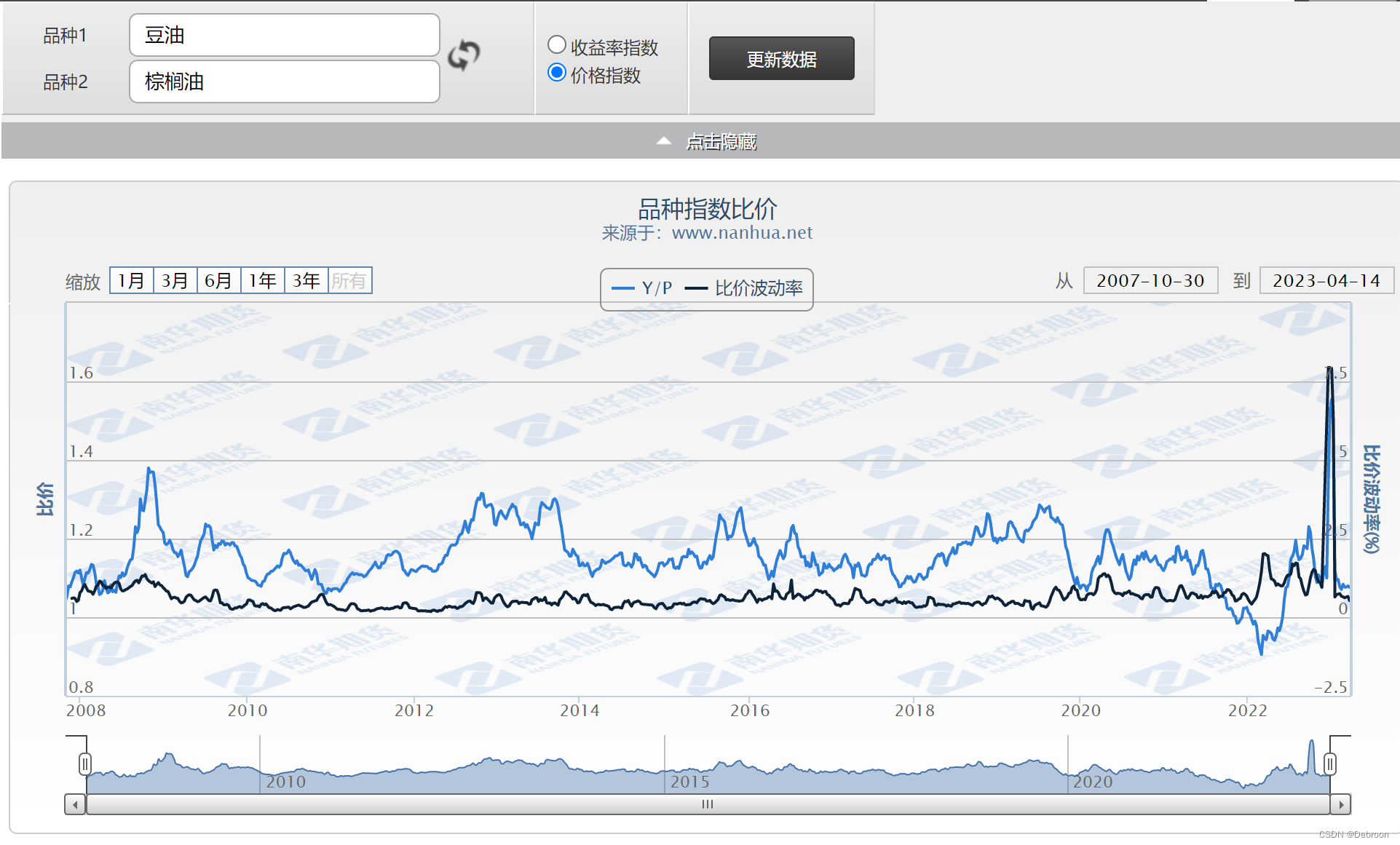
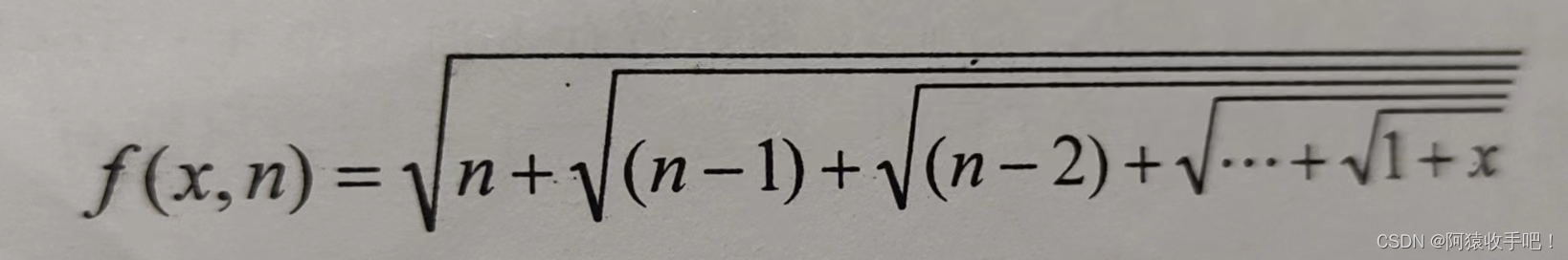Spark 官网:Apache Spark™ - Unified Engine for large-scale data analytics
Spark RDD介绍官网:https://spark.apache.org/docs/2.2.0/api/scala/index.html#org.apache.spark.rdd.RDD
下载好spark解压mv到软件目录
linux>mv spark-xxx-xxx /opt/install/spark修改配置文件进入spark/conf
linux>vi spark-env.sh
#添加如下配置
export JAVA_HOME=/opt/install/jdk
export SPARK_MASTER_IP=192.168.58.200
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
linux>vi slaves
192.168.58.201
192.168.58.202启动spark服务
linux>sbin/start-all.sh
linux>jps #查看服务进程
192.168.58.200 启动spark jps 后有Master
192.168.58.201 启动spark jps 后有Worker
192.168.58.202 启动spark jps 后有Worker
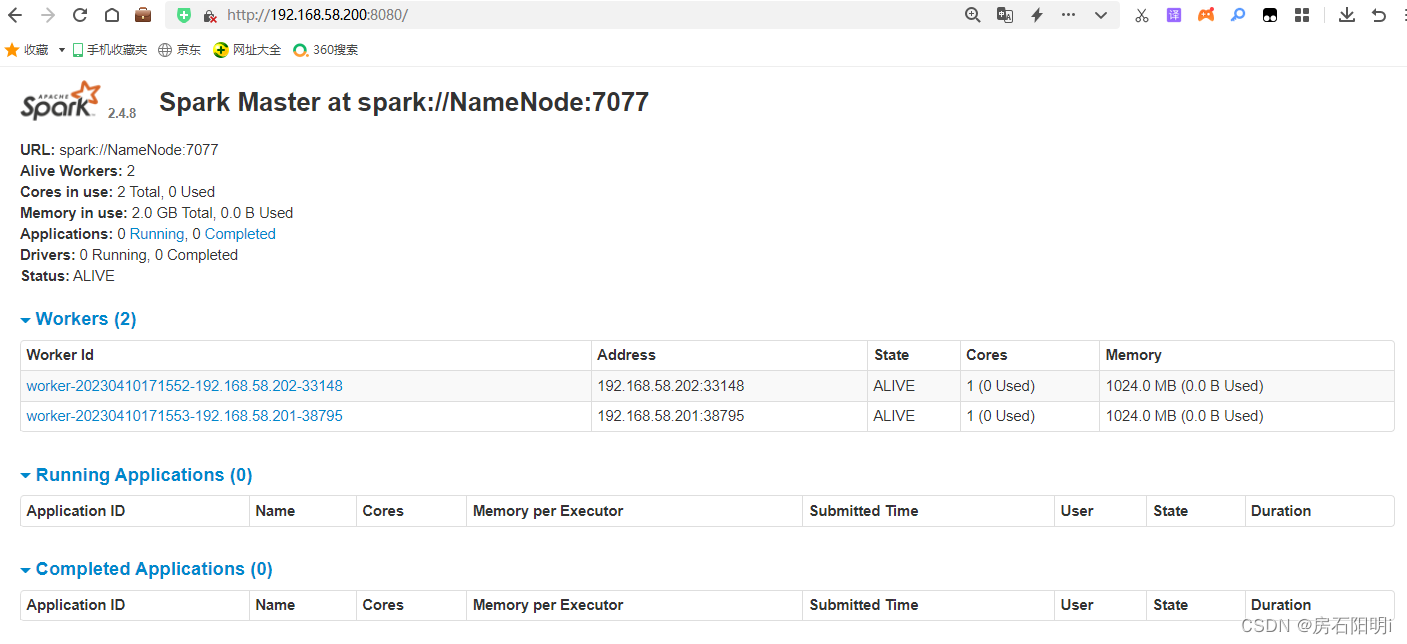
访问Spark Web UI 用浏览器输入IP:8080 即可
spark Shell 用于测试
Linux>bin/spark-shell 用于测试
或bin/spark-shell --master spark://IP:7070 (会启用stanlang集器 )测试数据:(将数据上传到hdfs上 例:hdfs dfs -put testdata.txt /mycluster/tmp_data/sparkdata)
linux>testdata.txt
hello zhangsan hello lisi hello wangwu hello xiaohong
hello lisi2 hello xiaoming hello zhangsan
hello zhangsan2 hello lisi3 hello wangwu2
zhang san li siSpark Shell WordCount
spark(scala)>val lines=sc.textFile("/root/tmp_data/sparkdata/testdata.txt") (创建RDD,指定hdfs上的文件)
spark(scala)>val lines=sc.textFile("file:///root/tmp_data/sparkdata/testdata.txt") (创建RDD,指定本地上的文件)
spark(scala)>lines
spark(scala)>lines.take(5) (查看指定范围)
spark(scala)>lines.collect (收集查看全部)
spark(scala)>lines.flatMap(x=>x.split(" ")).take(10)
spark(scala)>lines.flatMap(x=>x.split(" ")).map(x=>(x,1)).take(10)
spark(scala)>lines.flatMap(x=>x.split(" ")).map(x=>(x,1)).reduceByKey((x,y)=>x+y).take(10)
spark(scala)>lines.flatMap(x=>x.split(" ")).map(x=>(x,1)).reduceByKey((x,y)=>x+y).sortBy(_._2,false).take(5) (查看指定范围的WordCount)
spark(scala)>lines.flatMap(x=>x.split(" ")).map(x=>(x,1)).reduceByKey((x,y)=>x+y).sortBy(_._2,false).saveAsTextFile("file:///root/tmp_data/sparkdata/output") (WordCount 后将结果保存到本地)
spark(scala)>lines.flatMap(x=>x.split(" ")).map(x=>(x,1)).reduceByKey((x,y)=>x+y).sortBy(_._2,false).saveAsTextFile("/root/tmp_data/sparkdata/output") (WordCount 后将结果保存到hdfs)
linux>hdfs dfs -cat /xxx/xxx 查看数据IDEA pom.xml配置:
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>2.11.8</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.2.0</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.2</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.4.3</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>SparkWordCount
package SparkTest
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object SparkWordCount {
/* 1.创建Sparkcontext
2.创建RDD
3.调用transformation算子
4.调用action算子
5.释放资源*/
def main(args:Array[String]):Unit={
/* val conf =new SparkConf().setAppName("SparkWrodCount")
val sc = new SparkContext(conf)
val lines: RDD[String]=sc.textFile("/mycluster/tmp_data/sparkdata")
val wordes: RDD[String]=lines.flatMap(_.split(" "))
val wordAndOne: RDD[(String,Int)] = wordes.map((_,1))
val reduced: RDD[(String,Int)]=wordAndOne.reduceByKey(_+_)
val result: RDD[(String,Int)]=reduced.sortBy(_._2,false)
result.saveAsTextFile("/mycluster/tmp_data/output")
sc.stop()*/
val conf =new SparkConf().setAppName("SparkWrodCount")
val sc = new SparkContext(conf)
val lines:RDD[String]=sc.textFile(args(0))
val wordes:RDD[String]=lines.flatMap(_.split(" "))
val wordAndOne:RDD[(String,Int)] = wordes.map((_,1))
val reduced:RDD[(String,Int)]=wordAndOne.reduceByKey(_+_)
val result:RDD[(String,Int)]=reduced.sortBy(_._2,false)
result.saveAsTextFile(args(1))
sc.stop()
}
}
打好包后运行
linux>bin/spark-submit --master spark://192.168.58.200:7077 --class SparkTest.SparkWordCount /root/tmp_data/sparkdata/SparkDemo-1.0-SNAPSHOT.jar /mycluster/tmp_data/sparkdata /mycluster/tmp_data/outputJavaLamdaWordCount
package WordCount;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import scala.Tuple2;
import java.util.Arrays;
public class JavaLamdaWordCount {
public static void main(String[] args) {
final SparkConf conf = new SparkConf().setAppName("JavaLamdaWordCount");
final JavaSparkContext jsc = new JavaSparkContext(conf);
final JavaRDD<String> lines = jsc.textFile(args[0]);
final JavaRDD<String> words=lines.flatMap(line -> Arrays.asList(line.split(" ")).iterator());
final JavaPairRDD<String,Integer> wordAndOne = words.mapToPair(Word -> new Tuple2<>(Word,1));
final JavaPairRDD<String,Integer> reduced = wordAndOne.reduceByKey((x,y) -> x + y);
final JavaPairRDD<Integer,String> swaped = reduced.mapToPair(tuple -> tuple.swap());
final JavaPairRDD<Integer,String> sorted = swaped.sortByKey(false);
final JavaPairRDD<String,Integer> result = sorted.mapToPair(tuple -> tuple.swap());
result.saveAsTextFile(args[1]);
jsc.stop();
}
}
打好包后运行
linux>bin/spark-submit --master spark://192.168.58.200:7077 --class WordCount.JavaLamdaWordCount /root/tmp_data/sparkdata/SparkDemo-1.0-SNAPSHOT.jar /mycluster/tmp_data/sparkdata /mycluster/tmp_data/outputJavaWordCount
package WordCount;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import scala.Tuple2;
import java.util.Arrays;
import java.util.Iterator;
public class JavaWordCount {
public static void main(String[] args) {
final SparkConf conf = new SparkConf().setAppName("JavaWordCount");
final JavaSparkContext jsc = new JavaSparkContext(conf);
// final JavaRDD<String> lines=jsc.textFile("/mycluster/tmp_data/sparkdata");
final JavaRDD<String> lines=jsc.textFile(args[0]);
final JavaRDD<String> words=lines.flatMap(new FlatMapFunction<String,String>() {
@Override
public Iterator<String> call(String line) throws Exception{
// final String[] words=line.split(" ");
// final List<String> lists= Arrays.asList(words);
// return lists.iterator();
return Arrays.asList(line.split(" ")).iterator();
}
});
final JavaPairRDD<String,Integer> wordAndOne = words.mapToPair(new PairFunction<String,String,Integer>(){
@Override
public Tuple2<String,Integer> call(String word) throws Exception{
return new Tuple2<>(word,1);
}
});
final JavaPairRDD<String,Integer> reduced = wordAndOne.reduceByKey(new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer v1, Integer v2) throws Exception {
return v1 + v2;
}
});
final JavaPairRDD<Integer,String> swaped=reduced.mapToPair(new PairFunction<Tuple2<String, Integer>, Integer, String>() {
@Override
public Tuple2<Integer, String> call(Tuple2<String, Integer> Tuple2) throws Exception {
return Tuple2.swap();
}
});
final JavaPairRDD<Integer,String> sorted = swaped.sortByKey(false);
final JavaPairRDD<String,Integer> reuslt = sorted.mapToPair(new PairFunction<Tuple2<Integer, String>, String, Integer>() {
@Override
public Tuple2<String, Integer> call(Tuple2<Integer, String> Tuple2) throws Exception {
return Tuple2.swap();
}
});
//integerString
// reuslt.saveAsTextFile("/mycluster/tmp_data/output");
reuslt.saveAsTextFile(args[1]);
jsc.stop();
}
}
打好后包后运行
linux>bin/spark-submit --master spark://192.168.58.200:7077 --class WordCount.JavaWordCount /root/tmp_data/sparkdata/SparkDemo-1.0-SNAPSHOT.jar /mycluster/tmp_data/sparkdata /mycluster/tmp_data/output