rocketmq环境搭建
在docket环境下安装部署rocketmq的方法记录在上一篇文章中。
(31条消息) docker环境下搭建rocketmq集群_haohulala的博客-CSDN博客
这种方式不一定是最好的,但是我用这种方式可以成功搭建rocketmq开发环境。
项目架构
我们需要在springboot中创建两个module,分别是生产者和消费者。
项目的架构非常简单
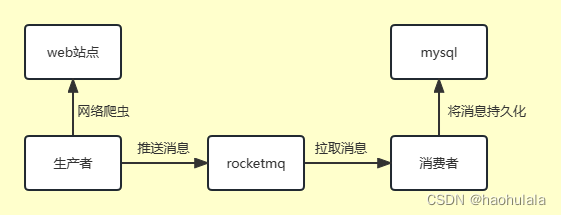
生产者使用web爬虫从网络中获取信息,然后将信息推送给rocketmq,消费者从rocketmq中获取消息,然后再存储到mysql数据库中。
在这样的案例中,消息队列起到了一个同步生产者和消费者的作用,因为我们的生产者可以有非常多的线程一起进行web爬虫,然后可能会生产非常多的消息,如果没有rocketmq的话,消费者可能会消费不过来,有了rocketmq,生产者和消费者就可以按照自己的节奏放心工作了。
下面我们来创建springboot项目。
首先创建一个空的springboot项目,框中文件都可以删除。
将上面的文件删除后,我们需要建两个module

建立的module还是springboot项目
 选择使用maven构建项目,我使用的java版本是jdk1.8
选择使用maven构建项目,我使用的java版本是jdk1.8
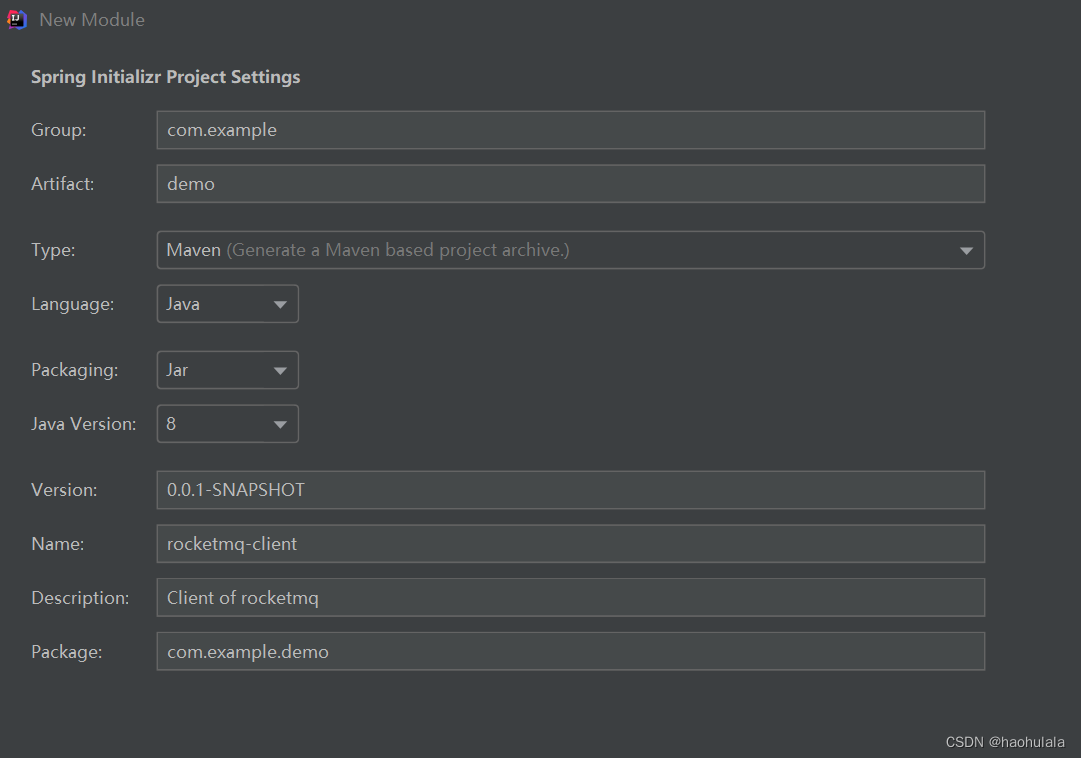 然后可以选择需要用到的start包,这里由于我使用的是jdk1.8,所以对应的springboot版本应该是2开头的
然后可以选择需要用到的start包,这里由于我使用的是jdk1.8,所以对应的springboot版本应该是2开头的
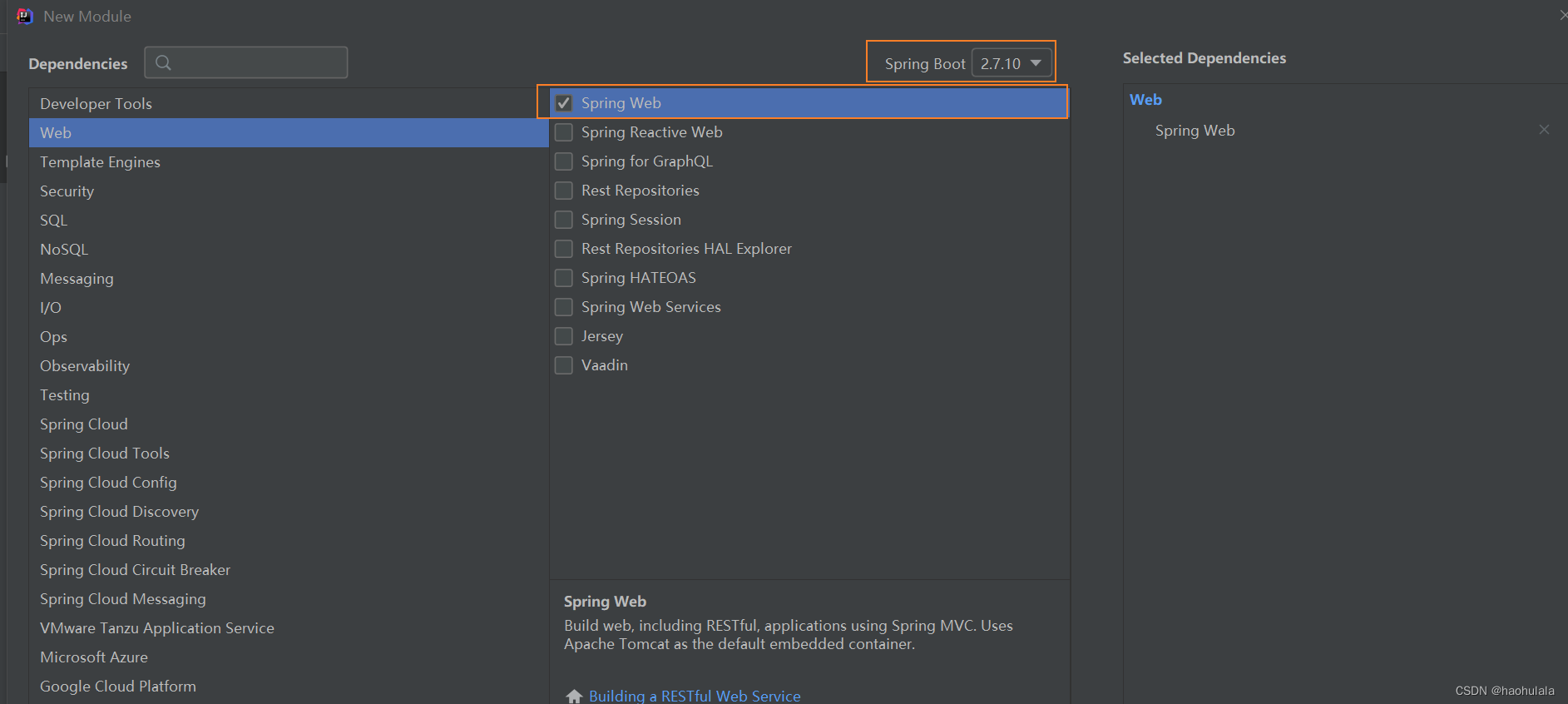
修改pom.xml的内容
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.7.10</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.example</groupId>
<artifactId>demo</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>rocketmq-client</name>
<description>Client of rocketmq</description>
<properties>
<java.version>1.8</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.rocketmq</groupId>
<artifactId>rocketmq-spring-boot-starter</artifactId>
<version>2.0.4</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
<!-- 爬虫相关的包 -->
<dependency>
<groupId>com.squareup.okhttp3</groupId>
<artifactId>okhttp</artifactId>
<version>3.10.0</version>
</dependency>
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.11.3</version>
</dependency>
<dependency>
<!-- fastjson -->
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.47</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-resources-plugin</artifactId>
<version>2.4.3</version>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.22.2</version>
<configuration>
<skipTests>true</skipTests>
</configuration>
</plugin>
</plugins>
</build>
</project>
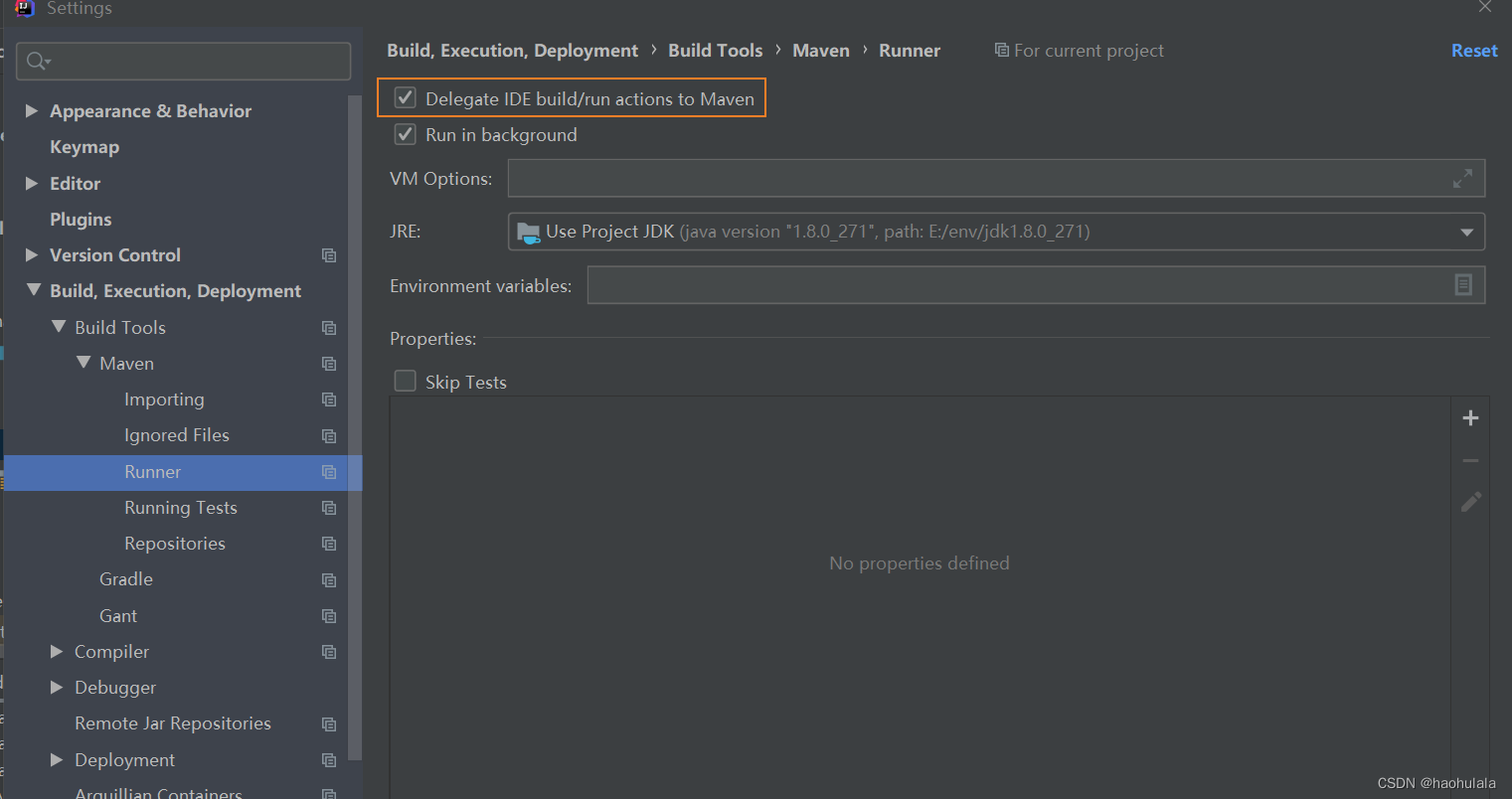
如果在启动项目的时候报错,别忘了在maven中将下面这个选项勾上
可以写一个简单的接口测试一下项目是否启动成功
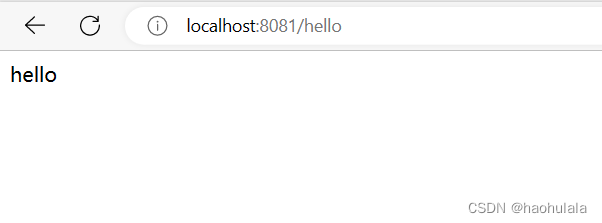
如果接口调通了,那么就证明项目已经启动成功,接着就是使用同样的方法构建消费者
消费者的pom.xml的内容和生产者稍微有点不同,主要是添加了mysql和mybaits的支持
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.7.10</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.example</groupId>
<artifactId>demo</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>consumer</name>
<description>a consumer of rocketmq</description>
<properties>
<java.version>1.8</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.rocketmq</groupId>
<artifactId>rocketmq-spring-boot-starter</artifactId>
<version>2.0.4</version>
</dependency>
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>2.1.0</version>
</dependency>
<dependency>
<groupId>com.mysql</groupId>
<artifactId>mysql-connector-j</artifactId>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
<dependency>
<!-- fastjson -->
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.47</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-resources-plugin</artifactId>
<version>2.4.3</version>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.22.2</version>
<configuration>
<skipTests>true</skipTests>
</configuration>
</plugin>
</plugins>
</build>
</project>
这样一来开发环境就搭建好了,项目结构如下所示
生产者
生产者主要就是使用web爬虫爬取csdn中的文章和作者信息,然后将消息推送到rocketmq中。
首先是配置文件
server.port=8081
rocketmq.name-server=192.168.232.129:9876
rocketmq.producer.group=CSDN_group使用两个实体类来存储文章信息和作者信息
@Data
@AllArgsConstructor
@NoArgsConstructor
public class CSDNArticleEntity {
private Long u_id;
private String title;
private String url;
private String author_name;
private String nick_name;
private String up_time;
private Integer read_volum;
private Integer collection_volum;
private String tag;
private Double score;
}@Data
@AllArgsConstructor
@NoArgsConstructor
public class CSDNAuthorEntity {
private Long u_id;
private String author_name;
private String nick_name;
private Integer num_fans;
private Integer num_like;
private Integer num_comment;
private Integer num_collect;
private Double author_score;
}
接着就是写爬虫,我们采用广度优先搜索的策略,以csdn的主页为源节点,加载文章url
(31条消息) CSDN博客-专业IT技术发表平台
加载的文章url都会存放到一个阻塞队列中。
然后再从阻塞队列中逐个将url取出,加载文章和作者信息,并且将页面中的推荐文章的url再放到阻塞队列中,这样就可以不停的爬文章信息了。
@Slf4j
@Service
public class CSDNSpiderServiceImpl implements CSDNSpiderService {
@Autowired
private RocketMQTemplate rocketMQTemplate;
// 指定一个主题,两个TAG,分别对应文章消息和作者消息
private final String TOPIC = "TOPIC_CSDN";
private final String TAG1 = "ARTICLE";
private final String TAG2 = "AUTHOR";
private final String start_url = "https://blog.csdn.net/";
// 定义一个线程池
private ThreadPoolExecutor pool = new ThreadPoolExecutor(
1,
1,
10,
TimeUnit.SECONDS,
new ArrayBlockingQueue<>(2048)
);
@Override
public void startSpider() {
new Thread(()->{
// 首先从首页拿到初始的文章url
Request request = new Request.Builder()
.url(start_url)
.get() //默认就是GET请求,可以不写
.addHeader("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.122 Safari/537.36")
.build();
try {
Response response = CSDNSpiderUtils.client.newCall(request).execute();
Document dom = Jsoup.parse(response.body().string());
// 找到文章
Elements as = dom.getElementsByClass("blog");
for(Element e : as) {
String url = e.attr("href");
if(url!=null && !url.equals("")) {
CSDNSpiderUtils.queue.offer(url);
log.debug("成功添加url:{}", url);
}
}
// 之后就是不断从队列中拿到url,然后解析顺便拿到更多的url
while(true) {
// 如果队列为空就持续等待
while(CSDNSpiderUtils.queue.isEmpty()){}
String url = CSDNSpiderUtils.queue.poll();
pool.execute(new ArticleParser(url));
log.debug("成功消费url:{}", url);
Thread.sleep(500);
}
} catch (IOException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
}).start();
}
// 解析每个页面的代码
private class ArticleParser extends Thread {
private String url = null;
public ArticleParser(String url) {
this.url = url;
}
@Override
public void run() {
super.run();
// 判断一下url是否为空
if(url==null || url.equals("")) {
return;
}
// 先判断一下url是否是文章的url
if(!url.contains("article")) {
return;
}
// 然后再加载html页面然后解析
// 建立连接
Request request = new Request.Builder()
.url(url)
.get() //默认就是GET请求,可以不写
.addHeader("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.122 Safari/537.36")
.build();
try {
Response response = CSDNSpiderUtils.client.newCall(request).execute();
Document dom = Jsoup.parse(response.body().string());
// 获取作者信息
CSDNAuthorEntity authorEntity = assembleAuthorEntity(dom, url);
if(authorEntity == null) {
return;
}
// 获取文章信息
CSDNArticleEntity articleEntity = assembleArticleEntity(dom, url, authorEntity.getAuthor_name(), authorEntity.getNick_name(), authorEntity.getAuthor_score());
if(!CSDNSpiderUtils.scoreFilter(articleEntity, authorEntity)){
return;
}
/*
* 向消息队列中推送消息
* */
if(articleEntity!=null) {
// 写入到消息队列
rocketMQTemplate.send(TOPIC + ":" + TAG1, MessageBuilder.withPayload(articleEntity).build());
log.info("获取文章信息:{}", JSON.toJSONString(articleEntity));
}
if(authorEntity != null) {
// 写入到消息队列
rocketMQTemplate.send(TOPIC + ":" + TAG2, MessageBuilder.withPayload(authorEntity).build());
log.info("获取作者信息:{}", JSON.toJSONString(authorEntity));
}
// 找到文章底部推荐的文章url
Elements elementsByClass = dom.getElementsByClass("recommend-item-box type_blog clearfix");
for(Element el : elementsByClass) {
String data_url = el.attr("data-url");
if(data_url!=null && !data_url.equals("")) {
CSDNSpiderUtils.queue.offer(data_url);
log.debug("成功添加url:{}", data_url);
}
}
elementsByClass = dom.getElementsByClass("recommend-item-box baiduSearch clearfix");
for(Element el : elementsByClass) {
String data_url = el.attr("data-url");
if(data_url!=null && !data_url.equals("")) {
CSDNSpiderUtils.queue.offer(data_url);
log.debug("成功添加url:{}", data_url);
}
}
return;
} catch (IOException e) {
e.printStackTrace();
}
return;
}
}
// 获取文章信息
private CSDNArticleEntity assembleArticleEntity(Document dom, String url, String username, String nickname, double score) {
// 找到文章标题
String title = dom.getElementsByClass("title-article").text();
// 如果title过长就截取
if(title.length() >= 150) {
title = title.substring(0, 150);
}
// 找到发表时间
String up_time = "";
if(dom.getElementsByClass("time").text().split(" ").length>=2) {
up_time = dom.getElementsByClass("time").text().split(" ")[1];
}
else {
return null;
}
// 找到文章阅读量
if(dom.getElementsByClass("read-count").text()==null || dom.getElementsByClass("read-count").text().equals("")){
return null;
}
Integer read_volum = Integer.parseInt(dom.getElementsByClass("read-count").text());
// 找到文章收藏量
if(dom.getElementsByClass("get-collection").text()==null || dom.getElementsByClass("get-collection").text().equals("")){
return null;
}
Integer collection_volum = Integer.parseInt(dom.getElementsByClass("get-collection").text().split(" ")[0]);
// 查找文章标签
StringBuilder sb = new StringBuilder();
Element element = dom.getElementsByClass("tags-box artic-tag-box").first();
// 找到所有的a标签
// 第一个标签是文章分类的,所以忽略掉
// 第二个是个span,内容是“文章标签”,也忽略掉
Elements tag_as = element.getElementsByTag("a").next().next();
for(Element tag_a : tag_as) {
sb.append(tag_a.text());
sb.append(" ");
}
String str_tag = sb.toString();
CSDNArticleEntity articleEntity = new CSDNArticleEntity();
articleEntity.setTitle(title);
articleEntity.setUp_time(up_time);
articleEntity.setAuthor_name(username);
articleEntity.setNick_name(nickname);
articleEntity.setRead_volum(read_volum);
articleEntity.setCollection_volum(collection_volum);
articleEntity.setTag(str_tag);
articleEntity.setUrl(url);
articleEntity.setScore(CSDNSpiderUtils.getScore(read_volum, collection_volum, up_time, score));
return articleEntity;
}
// 获取作者信息
private CSDNAuthorEntity assembleAuthorEntity(Document dom, String url) {
CSDNAuthorEntity authorEntity = new CSDNAuthorEntity();
// 从url中获取作者username
String username = url.split("/article")[0].split("https://blog.csdn.net/")[1];
authorEntity.setAuthor_name(username);
// 获取作者的昵称
Element name_el = dom.getElementsByClass("profile-intro-name-boxTop").first();
String nick_name = name_el.getElementsByTag("a").first().getElementsByTag("span").text();
authorEntity.setNick_name(nick_name);
Element element = dom.getElementsByClass("data-info d-flex item-tiling").get(1);
Elements elements = element.getElementsByTag("dl");
try {
Integer num_fans = Integer.parseInt(elements.get(1).attr("title"));
Integer num_like = Integer.parseInt(elements.get(2).attr("title"));
Integer num_comment = Integer.parseInt(elements.get(3).attr("title"));
Integer num_collect = Integer.parseInt(elements.get(4).attr("title"));
authorEntity.setNum_fans(num_fans);
authorEntity.setNum_like(num_like);
authorEntity.setNum_comment(num_comment);
authorEntity.setNum_collect(num_collect);
authorEntity.setAuthor_score(CSDNSpiderUtils.getAuthorScore(num_fans, num_like, num_comment, num_collect));
} catch (Exception e) {
log.debug(elements.get(1).attr("title"));
log.debug("出错的url:{}", url);
}
return authorEntity;
}
}
从上述代码中可以看出来,我们定义了一个TOPIC和两个TAG,分别用来存放文章信息和作者信息,我们启动服务可以发现消息队列中已经有消息了。

可以在web控制台中看到生产者信息

消费者
消费者负责从rocketmq中取出消息,并且将数据存到mysql数据库中。
首先是配置信息,分别是mysql的配置,mybatis的配置和rocketmq的配置,具体的配置信息你需要根据实际情况来填写
server.port=8082
# mysql
spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver
spring.datasource.url=jdbc:mysql://192.168.232.129:3306/rocketmq_demo?serverTimezone=UTC&&characterEncoding=UTF-8
spring.datasource.username=root
spring.datasource.password=123456
# mybatis
mybatis.type-aliases-package=com.example.demo.entity
mybatis.mapper-locations=classpath:/mapper/*Mapper.xml
# rocketmq
rocketmq.name-server=192.168.232.129:9876然后是建库建表,我建的数据库名称是rocketmq_demo,你也可以用其他名称,建表sql如下所示
USE rocketmq_demo;
-- ----------------------------
-- Table structure for csdn_article
-- ----------------------------
DROP TABLE IF EXISTS `csdn_article`;
CREATE TABLE `csdn_article` (
`u_id` bigint(20) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '文章id',
`title` varchar(150) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '文章标题',
`url` varchar(200) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '文章url',
`author_name` varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '文章作者',
`nick_name` varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '作者昵称',
`up_time` varchar(10) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '文章发表时间 yyyy-mm-dd',
`read_volum` int(11) NOT NULL COMMENT '文章阅读量',
`collection_volum` int(11) NOT NULL COMMENT '文章收藏量',
`tag` varchar(100) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '文章标签',
`article_score` double NOT NULL COMMENT '文章得分',
PRIMARY KEY (`u_id`) USING BTREE,
UNIQUE INDEX `url_index`(`url`) USING BTREE,
INDEX `title_index`(`title`) USING BTREE,
INDEX `tag_index`(`tag`) USING BTREE,
INDEX `score_index`(`article_score`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 2615 CHARACTER SET = utf8 COLLATE = utf8_general_ci COMMENT = '文章信息表' ROW_FORMAT = Dynamic;
-- ----------------------------
-- Table structure for csdn_author
-- ----------------------------
DROP TABLE IF EXISTS `csdn_author`;
CREATE TABLE `csdn_author` (
`u_id` bigint(20) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '作者id',
`author_name` varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '文章作者',
`nick_name` varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '作者昵称',
`num_fans` int(11) NOT NULL COMMENT '粉丝数量',
`num_like` int(11) NOT NULL COMMENT '获赞数量',
`num_comment` int(11) NOT NULL COMMENT '评论数量',
`num_collect` int(11) NOT NULL COMMENT '收藏数量',
`author_score` double NOT NULL COMMENT '作者得分',
PRIMARY KEY (`u_id`) USING BTREE,
UNIQUE INDEX `author_name_index`(`author_name`) USING BTREE,
INDEX `author_socre_index`(`author_score`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 2306 CHARACTER SET = utf8 COLLATE = utf8_general_ci COMMENT = '作者信息表' ROW_FORMAT = Dynamic;
SET FOREIGN_KEY_CHECKS = 1;我们需要监听同一个TOPIC的两个TAG,这边需要注意一下,不同TAG的消费组需要不同,不然会报错。这个问题我真的找了好久好久,最后才发现是消费组相同造成的,-_-||
@Slf4j
@Service
@RocketMQMessageListener(topic = "TOPIC_CSDN", selectorExpression = "ARTICLE", consumerGroup = "CSDN_ARTICLE")
public class ArticleListener implements RocketMQListener<CSDNArticleEntity> {
@Autowired
private CSDNMapper csdnMapper;
@Override
public void onMessage(CSDNArticleEntity csdnArticleEntity) {
log.info("消费文章信息:{}", csdnArticleEntity);
if(csdnMapper.checkArticle(csdnArticleEntity)==0) {
csdnMapper.insertOneArticle(csdnArticleEntity);
}
else {
csdnMapper.updateOneArticle(csdnArticleEntity);
}
}
}@Slf4j
@Service
@RocketMQMessageListener(topic = "TOPIC_CSDN", selectorExpression = "AUTHOR", consumerGroup = "CSDN_AUTHOR")
public class AuthorListener implements RocketMQListener<CSDNAuthorEntity> {
@Autowired
private CSDNMapper csdnMapper;
@Override
public void onMessage(CSDNAuthorEntity csdnAuthorEntity) {
log.info("消费作者信息:{}", csdnAuthorEntity);
if(csdnMapper.checkAuthor(csdnAuthorEntity)==0) {
csdnMapper.insertOneAuthor(csdnAuthorEntity);
}
else {
csdnMapper.updateOneAuthor(csdnAuthorEntity);
}
}
}可以看到这其中有数据库操作,对应的数据库mapper如下
@Mapper
public interface CSDNMapper {
// 清空数据库
public void clearArticle();
public void clearAuthor();
// 检查是否有某篇文章
public int checkArticle(CSDNArticleEntity articleEntity);
// 检查是否有某个作者
public int checkAuthor(CSDNAuthorEntity authorEntity);
// 插入一条数据
public void insertOneArticle(CSDNArticleEntity articleEntity);
// 插入一条作者数据
public void insertOneAuthor(CSDNAuthorEntity authorEntity);
// 更新一条数据
public void updateOneArticle(CSDNArticleEntity articleEntity);
public void updateOneAuthor(CSDNAuthorEntity authorEntity);
// 从文章表中查询数据
public List<CSDNArticleEntity> selectFromArticle(@Param("keyword") String keyword,
@Param("offset") Integer offset,
@Param("pagesize") Integer pagesize);
// 查询一共有多少条数据
public Integer selectCount(@Param("keyword") String keyword);
}
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.example.demo.mapper.CSDNMapper">
<delete id="clearArticle">
delete from csdn_article where 1=1
</delete>
<delete id="clearAuthor">
delete from csdn_author where 1=1
</delete>
<select id="checkArticle" parameterType="CSDNArticleEntity" resultType="Integer">
select count(url) from csdn_article
where url=#{url}
</select>
<select id="checkAuthor" parameterType="CSDNAuthorEntity" resultType="Integer">
select count(author_name) from csdn_author
where author_name=#{author_name}
</select>
<insert id="insertOneArticle" parameterType="CSDNArticleEntity">
insert into csdn_article
(title, url, up_time, author_name, nick_name, read_volum, collection_volum, tag, article_score) values
(#{title}, #{url}, #{up_time}, #{author_name}, #{nick_name}, #{read_volum}, #{collection_volum}, #{tag}, #{score})
</insert>
<insert id="insertOneAuthor" parameterType="CSDNAuthorEntity">
insert into csdn_author
(author_name, nick_name, num_fans, num_like, num_comment, num_collect, author_score) values
(#{author_name}, #{nick_name}, #{num_fans}, #{num_like}, #{num_comment}, #{num_collect}, #{author_score})
</insert>
<update id="updateOneArticle" parameterType="CSDNArticleEntity">
update csdn_article
set
read_volum = #{read_volum},
collection_volum = #{collection_volum},
article_score = #{score}
where url=#{url}
</update>
<update id="updateOneAuthor" parameterType="CSDNAuthorEntity">
update csdn_author
set
num_fans=#{num_fans},
num_like=#{num_like},
num_comment=#{num_comment},
num_collect=#{num_collect},
author_score=#{author_score}
where author_name=#{author_name}
</update>
<select id="selectFromArticle" resultType="CSDNArticleEntity">
select * from csdn_article
where
title like CONCAT('%',#{keyword},'%') or
tag like CONCAT('%',#{keyword},'%')
order by article_score DESC
limit #{offset}, #{pagesize}
</select>
<select id="selectCount" parameterType="String" resultType="Integer">
select count(u_id) from csdn_article
where
title like CONCAT('%',#{keyword},'%') or
tag like CONCAT('%',#{keyword},'%')
</select>
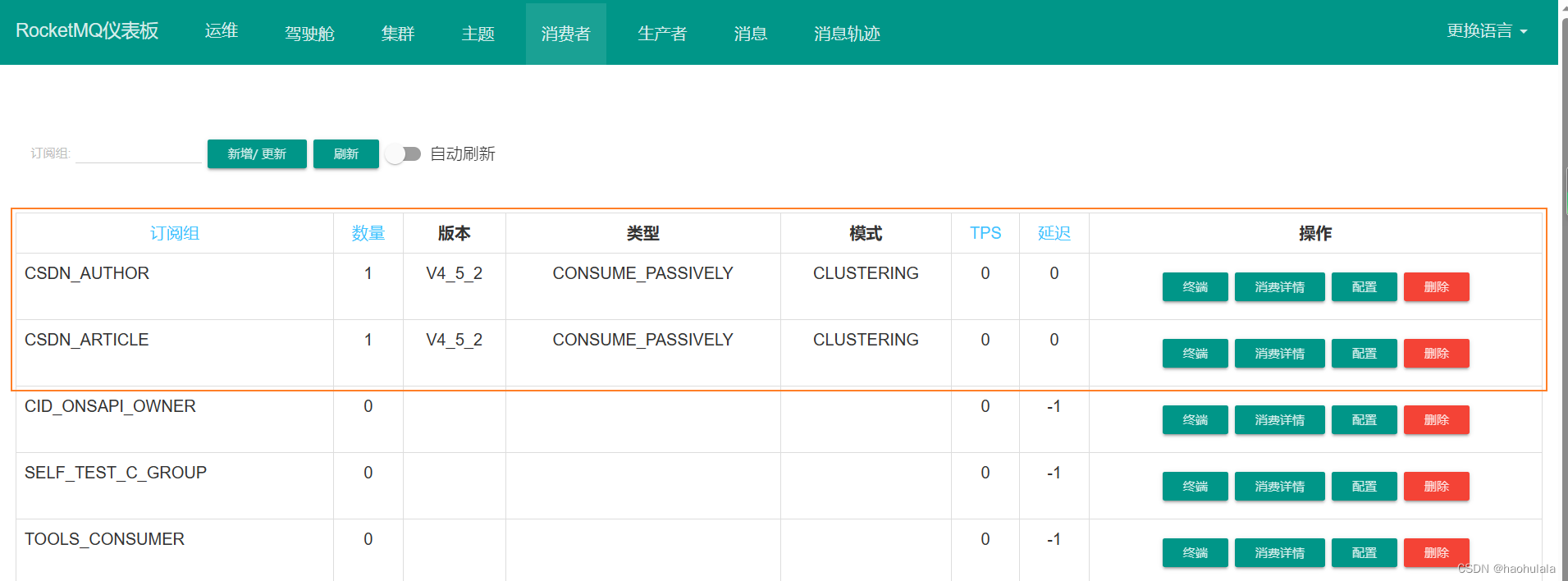
</mapper>将消费者启动起来,可以在web控制台中查看到消费者信息
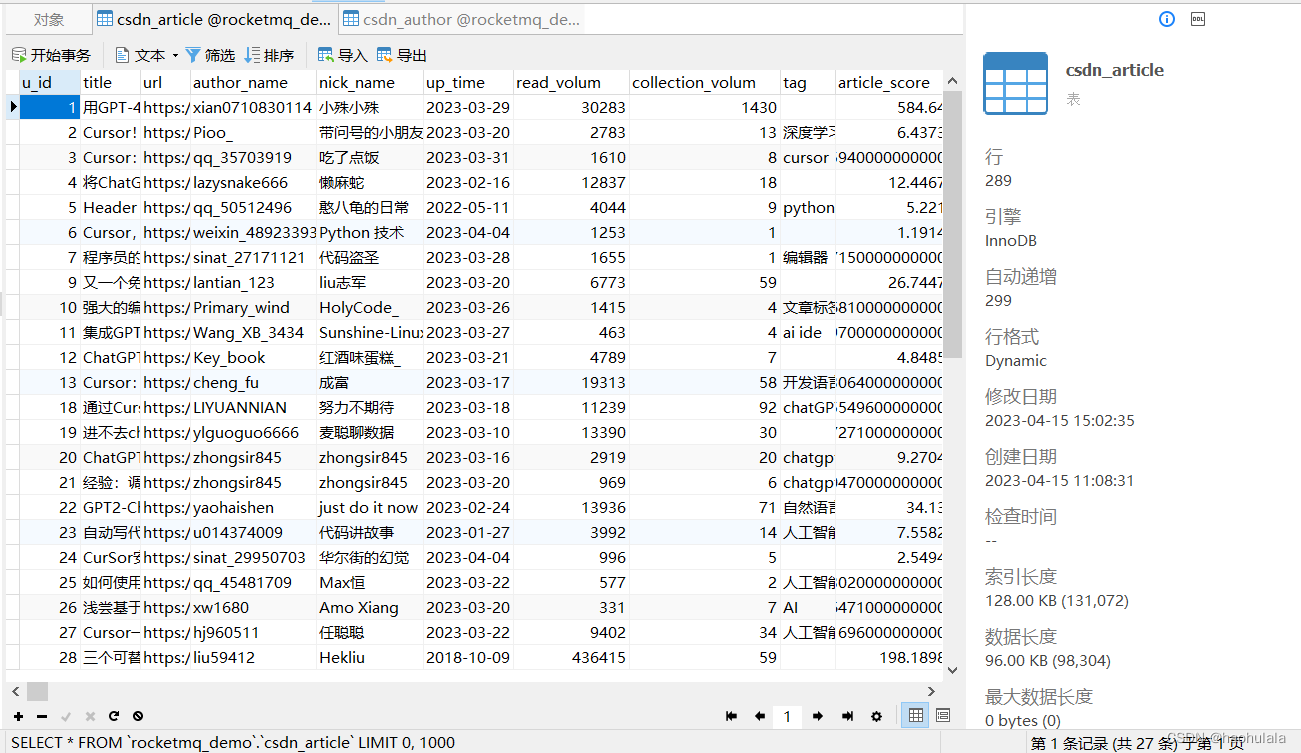
查看数据库,发现有数据了,消费成功
总结
这个项目虽然看上去不难,但是真的做起来还是花了不少精力的。
我将代码都放到gitee上了,有需要可以自取。
rocketmq-demo: springboot整合rocketmq的一个demo (gitee.com)