嗨咯,好几天没更新了,你以为我不知道吗?
这几天主要还是学习,学习如何再学习!
简述以下这几天都学习了什么~
-
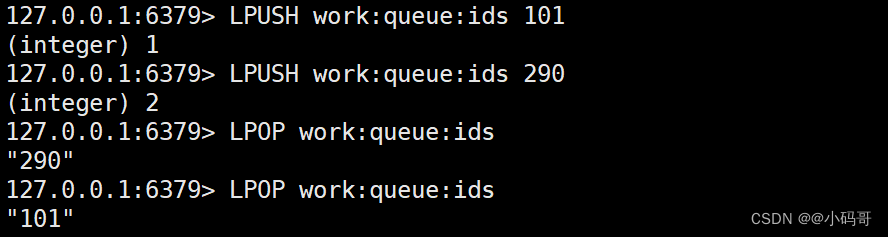
MongoDB的命令
-
GaussDB(for Mongo)集群架构与社区版架构的对比
社区版(副本集架构):
mongos(路由) config(记录元数据) shard(负责计算和存储)
GaussDB(for Mongo)存算分离架构:
mongos config shard + 底层存储 ,这里shard只负责计算 -
GaussDB怎么保证一致性的(2PC协议)
-
GaussDB内存满了怎么办?
-
Oplog就是一个中间人,类似于Mysql的binlog记录增删改的记录
-
巴拉巴拉巴拉

Hive的安装
下载Hive
这里选了最新的版本~3.1.3
下载结束后该配置环境了;
解压信息可以看到解压后的hive中有很多jar包
进入解压后的文件:

配置hive
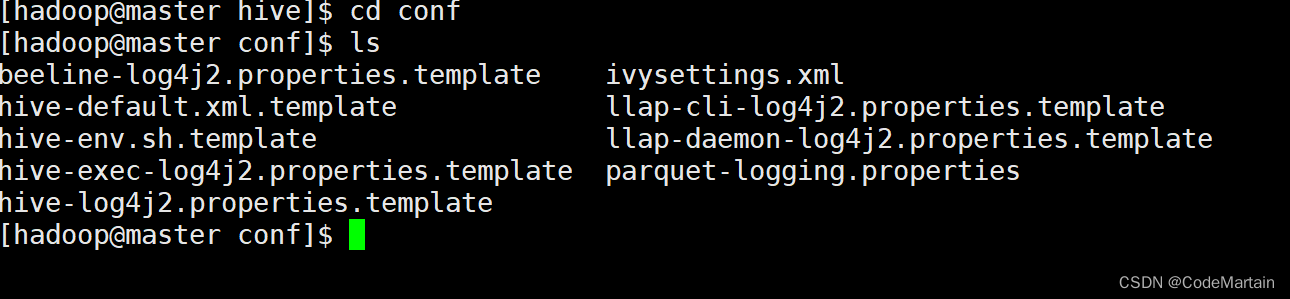
根据提供的模板文件开始配置我们的hive
配置hive-env.sh
cp hive-env.sh.template ./hive-env.sh
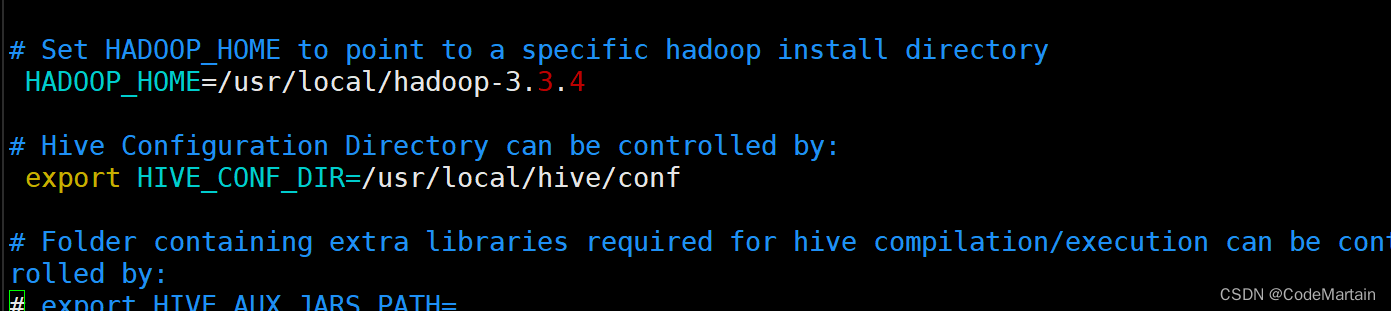
配置 hive-default.xml
cp hive-default.xml.template hive-default.xml
复制完毕后,暂且不需要修改,就放在这里就可以了;
配置hive-site.xml
#新建一个文件 hive-site.xml
vi hive-site.xml
在文件中添加仓库的配置~即数据库的连接要素
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<!--这里要注意5.0和8.0驱动的区别 -->
<value>com.mysql.cj.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
<description>username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>hive</value>
<description>password to use against metastore database</description>
</property>
</configuration>
配置hive环境
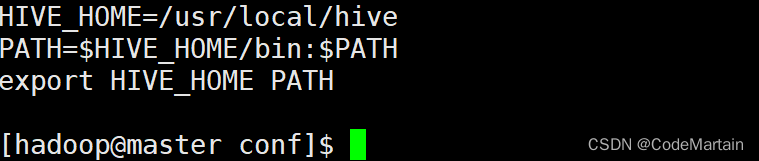
检查hive配置是否成功
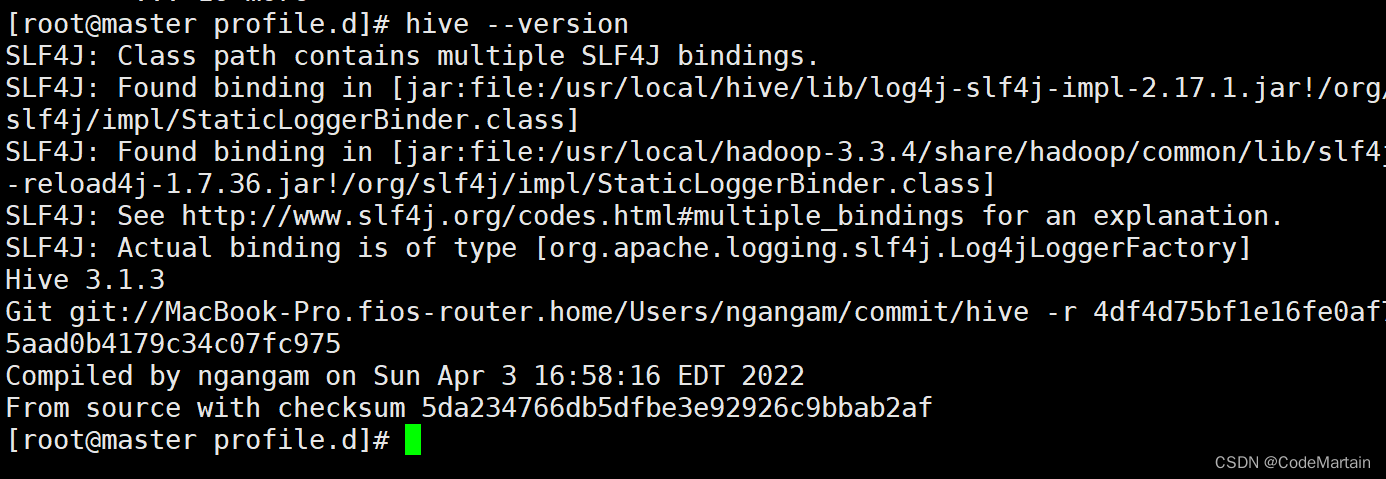
Hive通常是被数据仓库的一个组件出现的~Apache Hive是一个分布式,容错的数据仓库系统,可实现大规模和 便于使用 SQL 读取、写入和管理驻留在分布式存储中的 PB 级数据。
所以需要搭配数据库使用
检查一下在自己机器上有什么数据库,比如mysql ,postgresql,sqlserver and so on;
正好机器上有mysql社区版~8.0.27

下面就以mysql为例搭建一个数据仓库
下载mysql8.0.27的驱动jar包到hive 的lib目录下
去maven仓库搞一个~

然而该版本的驱动有漏洞,应该使用高版本无漏洞的吧(应该可以兼容的),不行咱再换对应版本的;
点击下载jar包~8.0.30
点击下载jar包~8.0.27
然后去hive-site.xml中配置数据库的连接要素:
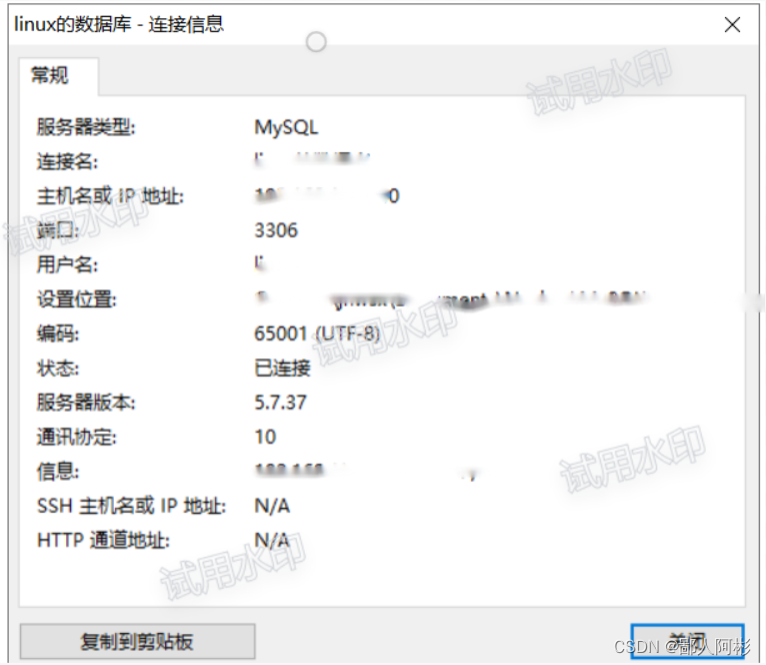
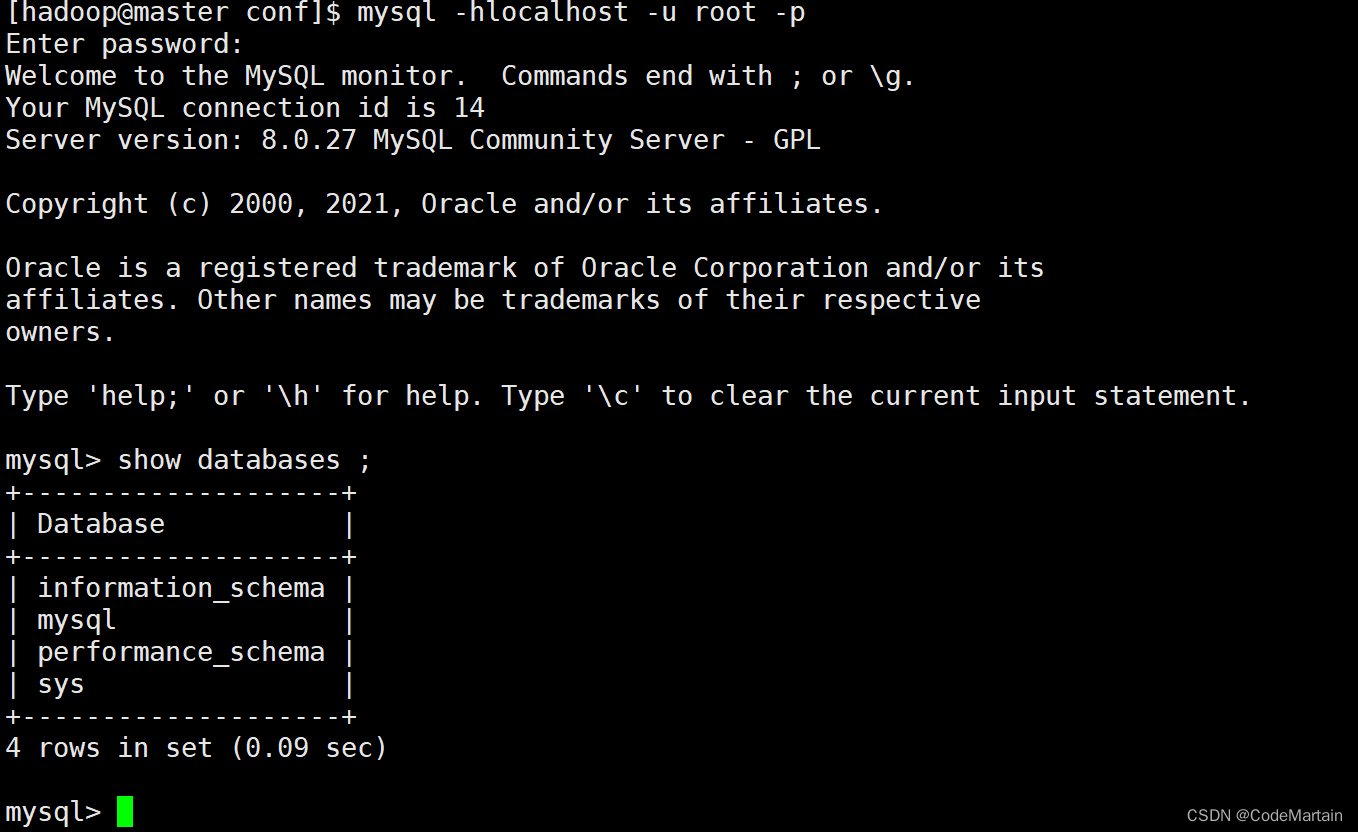
登录mysql数据库查看数据库信息:
新开一个会话启动hive
在这之前要先启动hadoop)因为hive依赖于MapReduce作业
启动hadoop后,
启动hive
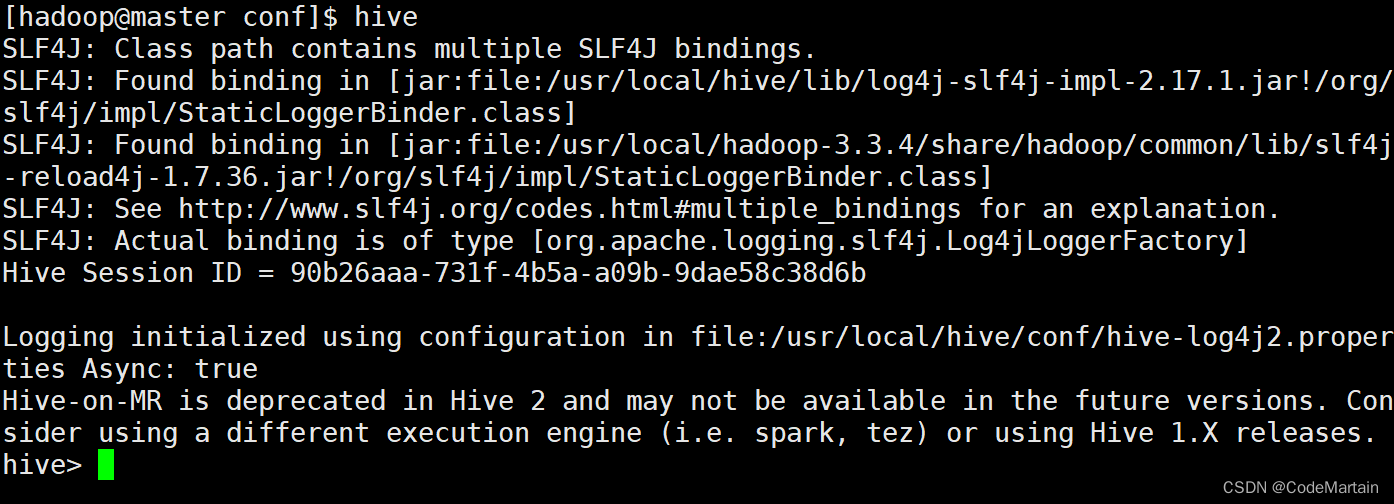
上图表示hive启动成功了,检查一下能否正常运行,那就先小试一下:
show databases ;
不出意外的话,意外出现了–报错了

大体意思就是不能够实例化元数据客户端
出错原因:以前曾经安装了Hive或MySQL,重新安装Hive和MySQL以后,导致版本、配置不一致。解决方法是,使用schematool工具。Hive现在包含一个用于 Hive Metastore 架构操控的脱机工具,名为 schematool.此工具可用于初始化当前 Hive 版本的 Metastore 架构。此外,其还可处理从较旧版本到新版本的架构升级。所以,解决上述错误,你可以在终端执行如下命令:
schematool -dbType mysql -initSchema
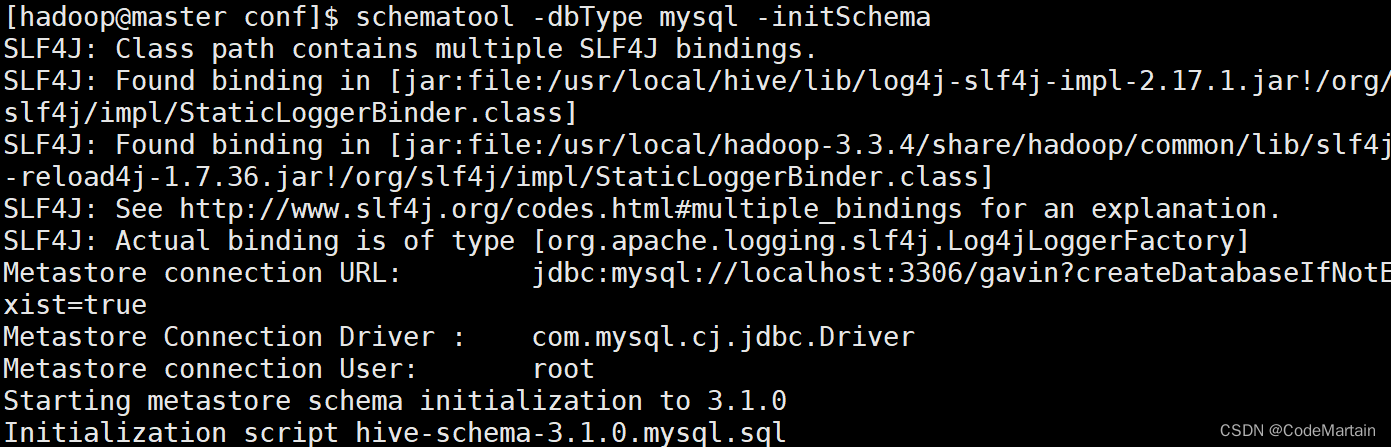
重新启动hive后重新测试:
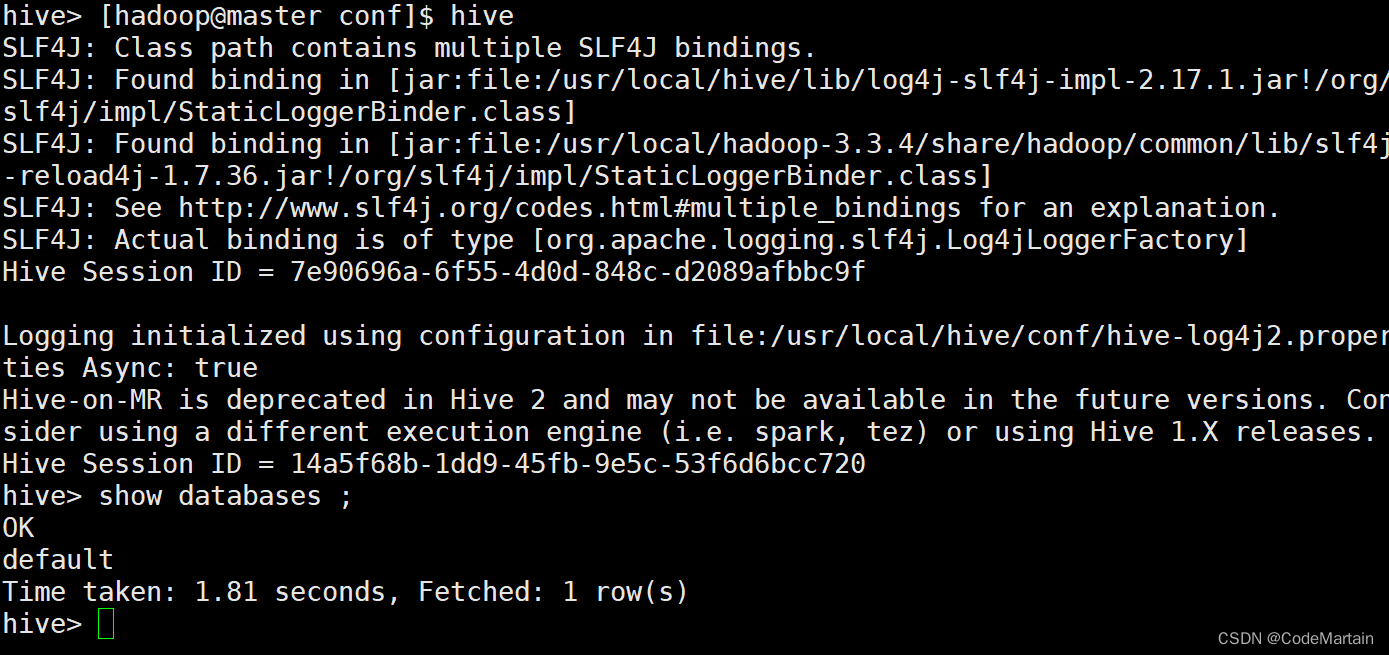
这次正常了;
我们查看mysql数据库中标的信息:
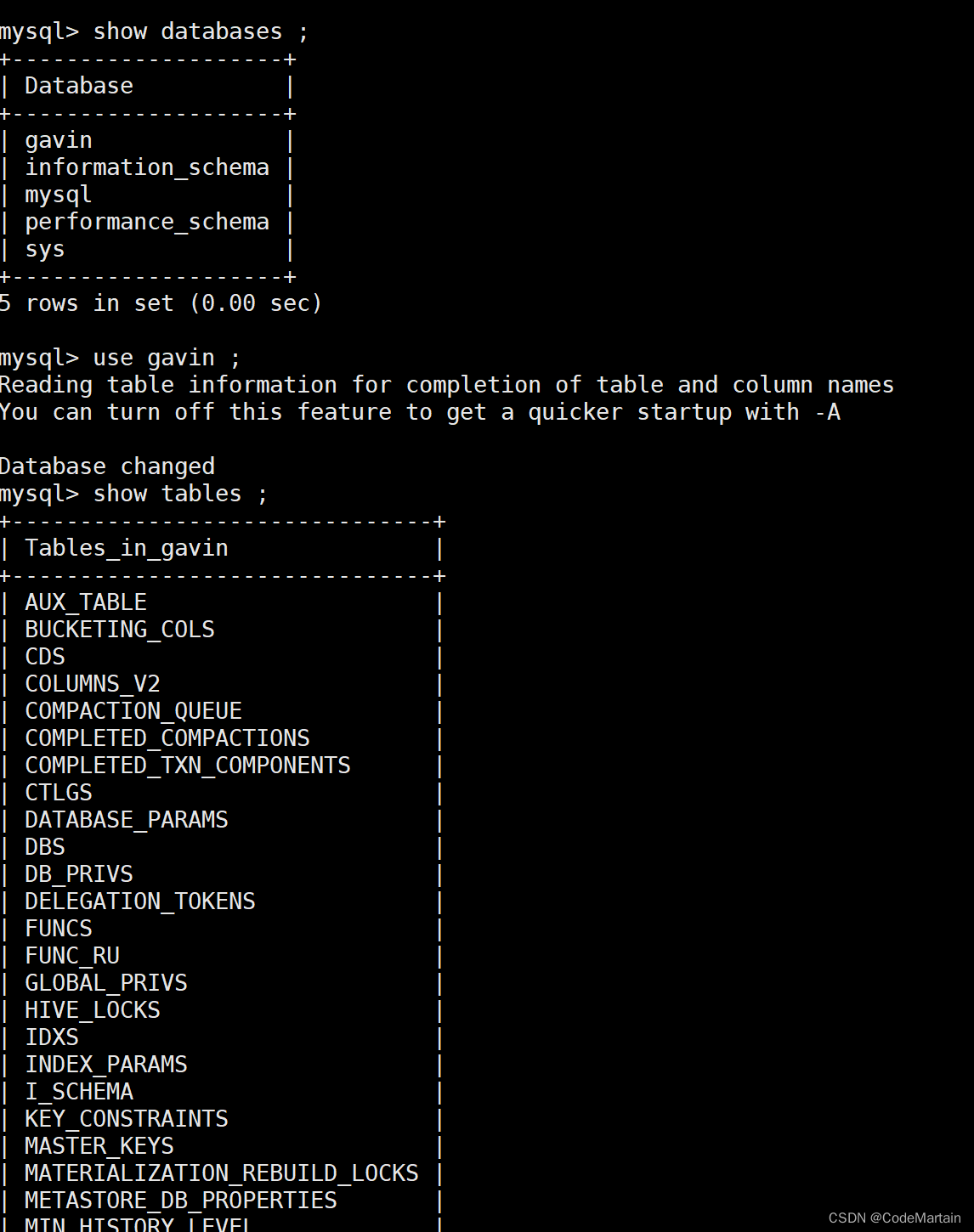
可以看到库中多了多表的信息;
查看要准备导入数据的表结构:
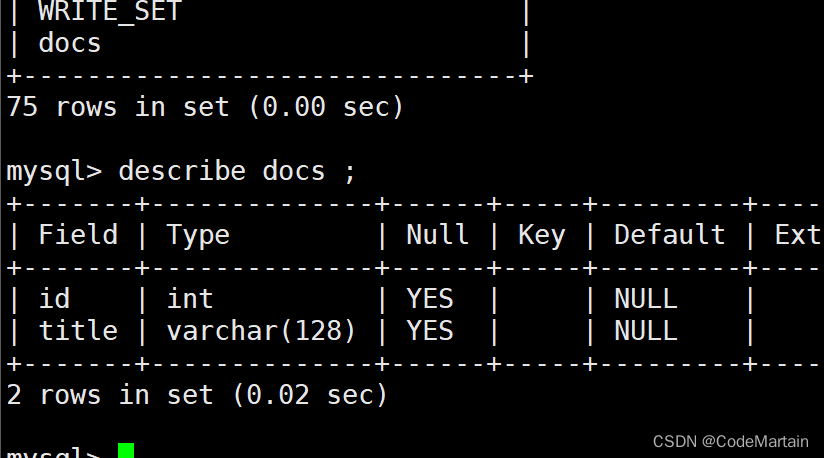
下面该学习一下hive一些命令了:
hive常用命令
在使用常用命令前,先看其数据类型吧:
hive中数据类型:
Hive支持基本数据类型和复杂类型, 基本数据类型主要有数值类型(INT、FLOAT、DOUBLE ) 、布尔型和字符串, 复杂类型有三种:ARRAY、MAP 和 STRUCT。
- a.基本数据类型
TINYINT: 1个字节
SMALLINT: 2个字节
INT: 4个字节
BIGINT: 8个字节
BOOLEAN: TRUE/FALSE
FLOAT: 4个字节,单精度浮点型
DOUBLE: 8个字节,双精度浮点型
STRING 字符串
- b.复杂数据类型
ARRAY: 有序字段
MAP: 无序字段
STRUCT: 一组命名的字段
hive基本命令
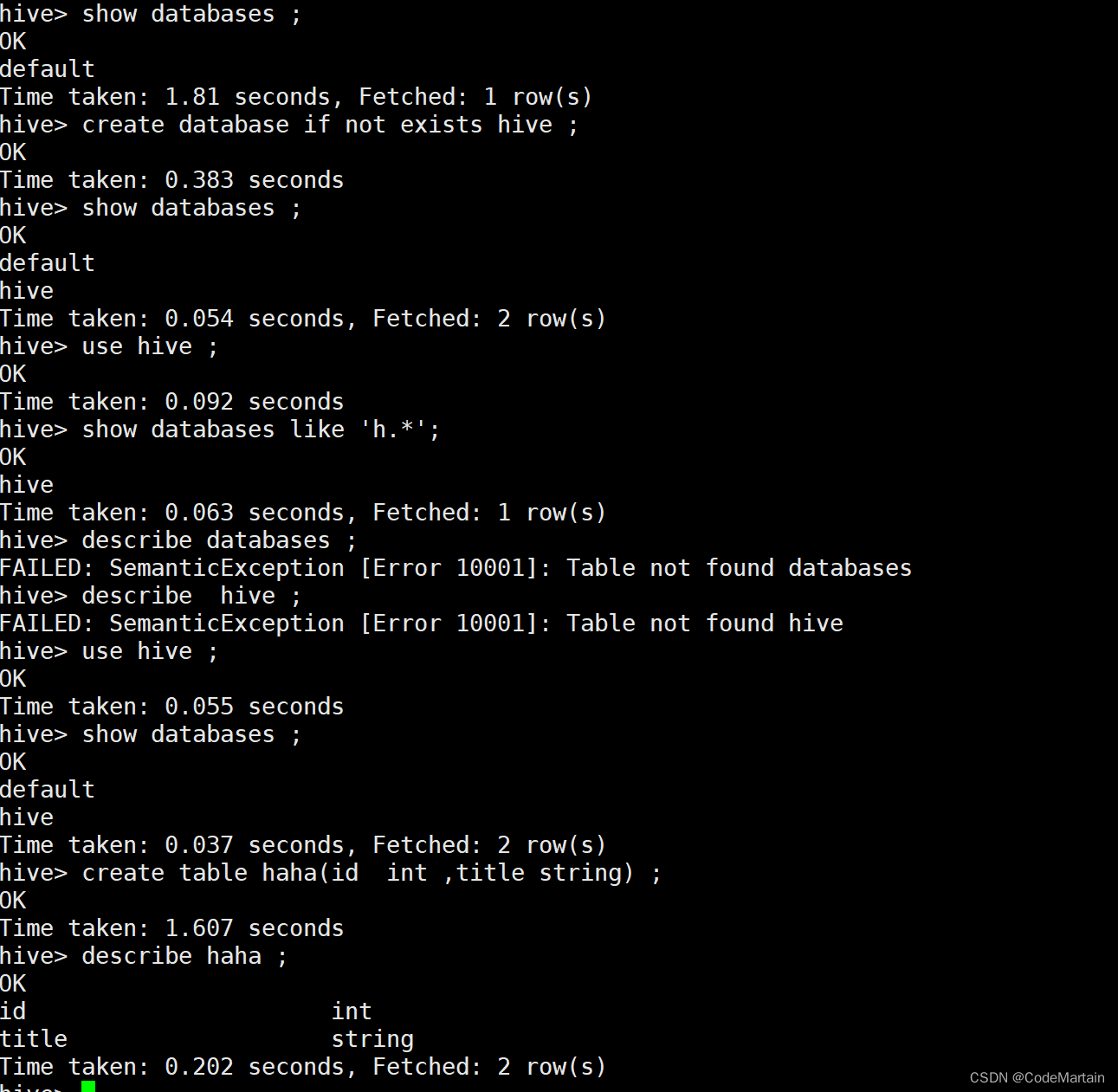
可以看到hivesql的命令跟sql92很像(简直一毛一样呀)
hivesql的一些其他命令不在演示,网上有很多教程,这里不再做搬运工了;
捡几个重点的搞一下:
向表中导入数据
首先准备数据,没有现成的,只能自己造了:
1 java
2 c++
3 html
4 golang
5 erlang
创建数据表用来存数据:
use hive;
create table book(id int ,name string) ;
导入本地数据
load data local inpath '/usr/local/bigdata/apache-hive-3.1.2-bin/loaddata/book' overwrite into table book ;
出了些问题~导入的数据全是null
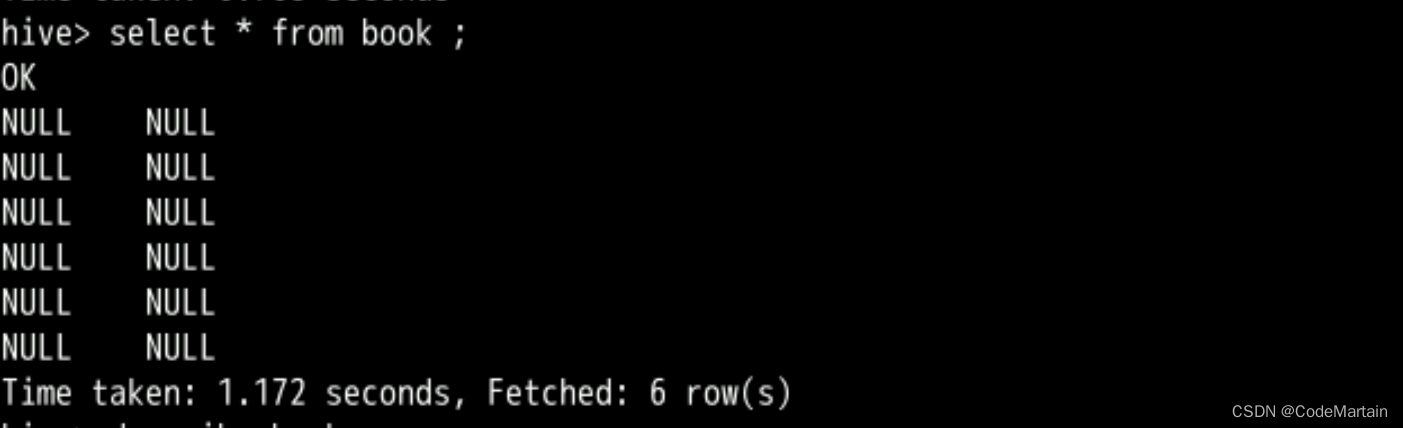
咋办?解决呗,导入的数据格式不对?
数据格式如下,间隔一个tab,每行一个换行,

查询后发现原来是创建表时没有指定换行符
新建一个表
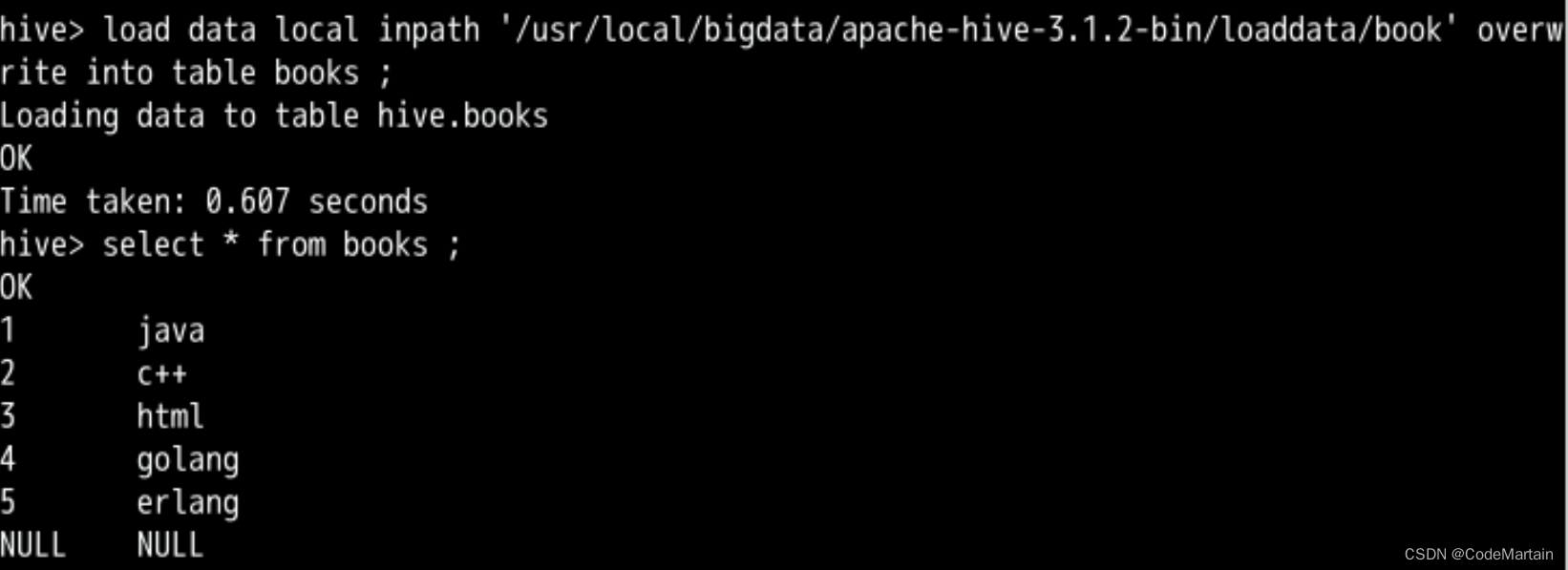
create table books (id int ,name string )row format delimited fields terminated by '\t';
重新导入数据后查看数据:
从hdfs中导入数据
将数据上传到hdfs中

newbook中数据

向hive中导入newbook

-
有local~表示从本地导入数据
-
无local~表示从哪个hdfs中导入
-
有overwrite~表示导入数据时将旧数据覆盖
-
无overwrite~表示向表中追加数据
注意:
为了保证数据能正常导入,一般在建表时就要考虑数据之间的间隔:
几个案例sql
create table if not exists hive.student(id int,name string)
row format delimited fields terminated by '\t';
create table if not exists hive.course(cid int,sid int)
row format delimited fields terminated by '\t';
上面的表book不是数据为null吗,我们使用insert 命令插入数据:
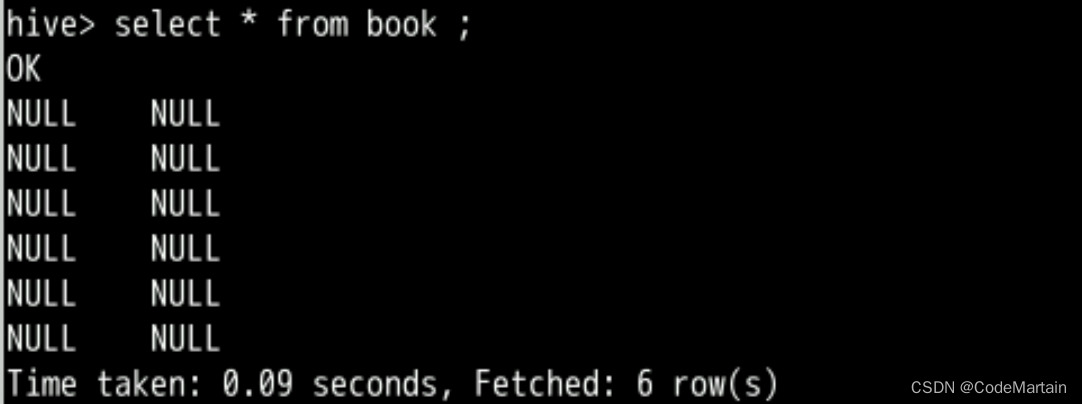
插入数据
insert overwrite table book select id ,name from books ;
执行过程中调用了MapReduce
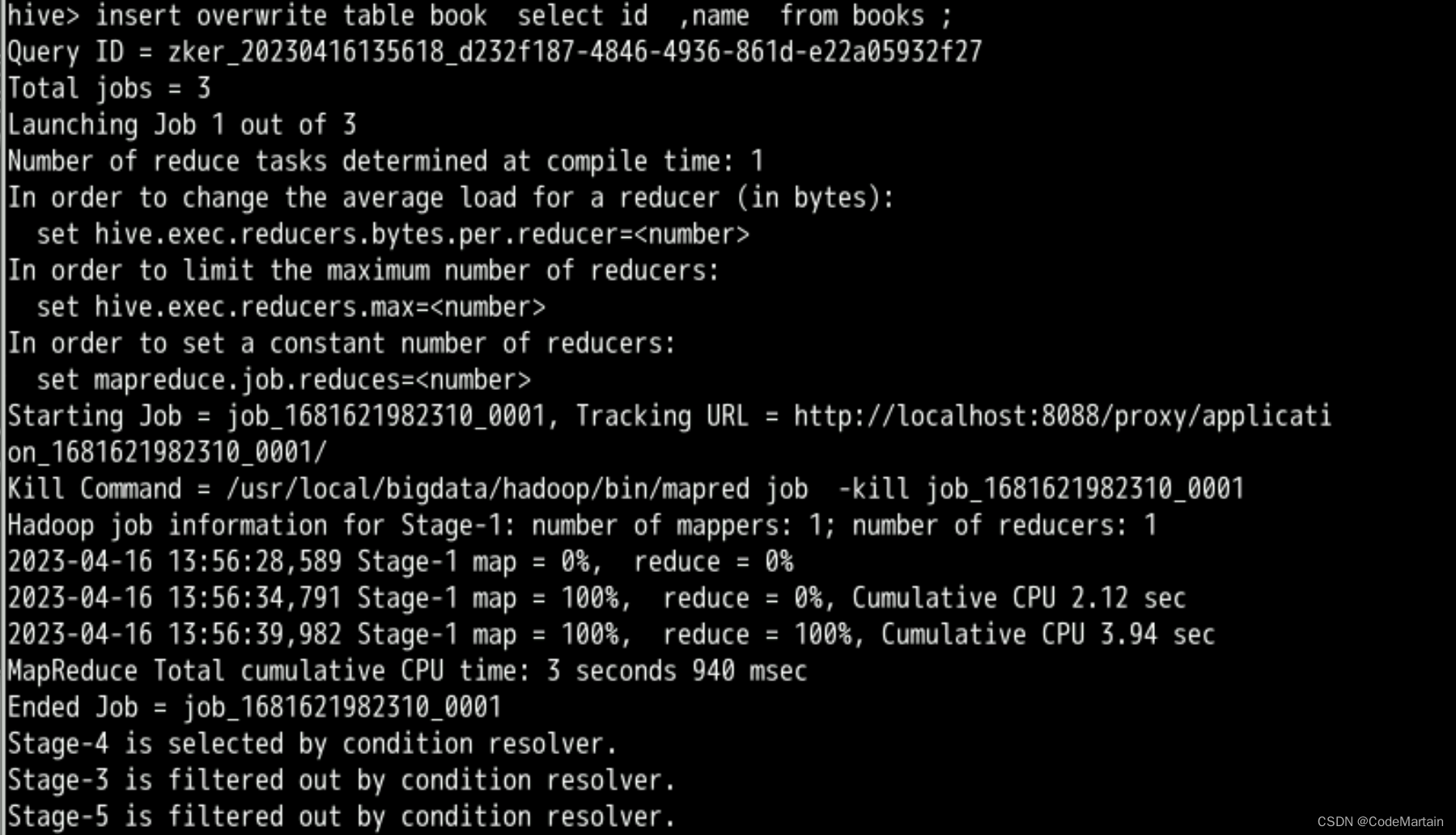
所以对于非程序员或者我这个菜鸡而言不用学习编写Java MapReduce代码了;
子查询
略微一提
标准 SQL 的子查询支持嵌套的 select 子句,HiveQL 对子查询的支持很有限,只能在from 引导的子句中出现子查询。





![[ vulnhub靶机通关篇 ] 渗透测试综合靶场 DC-5 通关详解 (附靶机搭建教程)](https://img-blog.csdnimg.cn/acc14837830946dcb0661209f9f4737f.png)