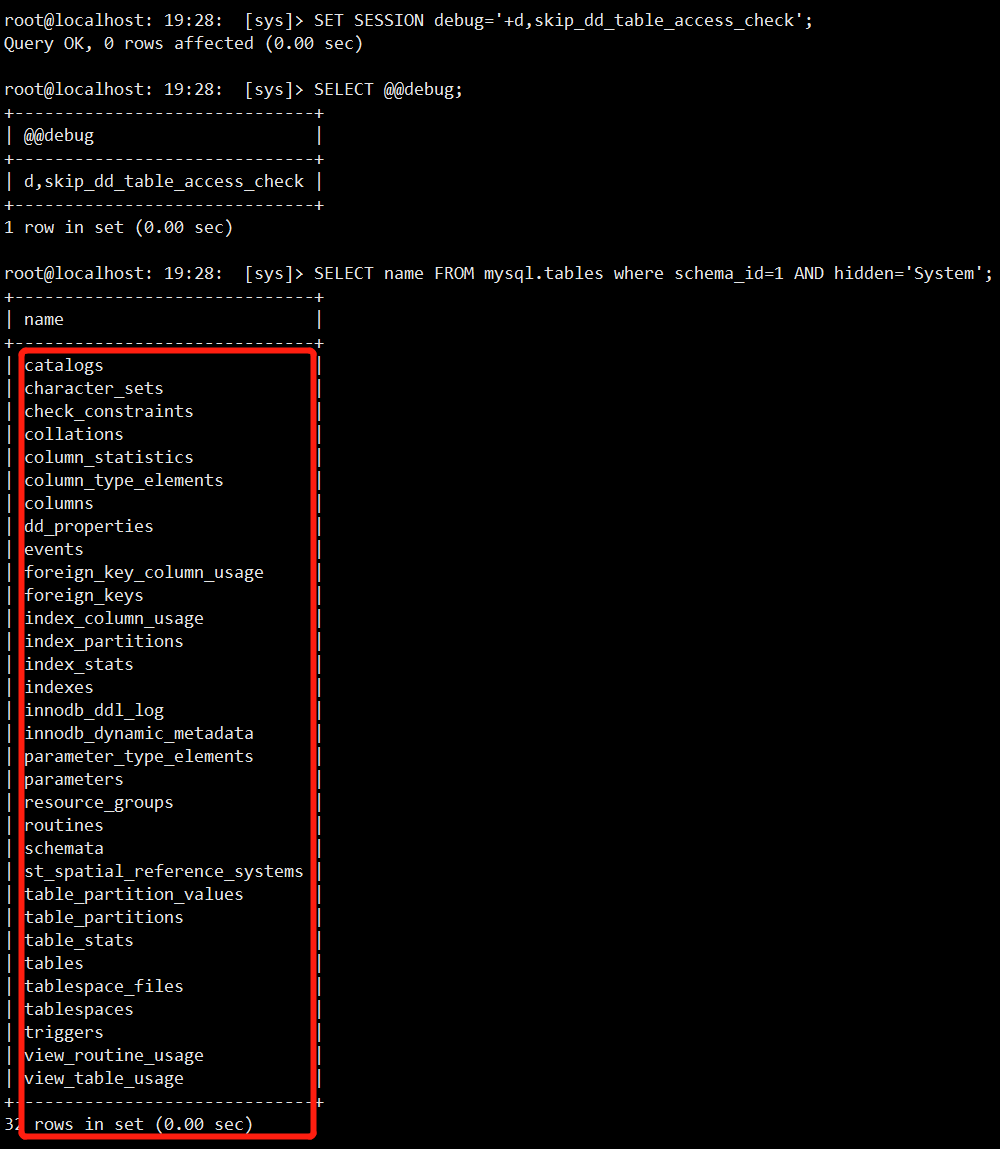
1.LinkedList官方介绍
双链表实现的list和Deque接口。实现所有可选的列表操作,并允许所有元素(包括null)。
所有的操作都按照双链表的预期执行。索引到列表中的操作将从列表的开始或结束遍历列表,以更接近指定索引的为准。
注意,这个实现不是同步的。如果多个线程并发访问一个链表,并且其中至少有一个线程在结构上修改了链表,那么它必须在外部同步。(结构修改是添加或删除一个或多个元素的任何操作;仅仅设置元素的值并不是结构修改。)这通常是通过在自然封装列表的某些对象上同步来实现的。如果不存在这样的对象,则应该使用集合“包装”列表。synchronizedList方法。这最好在创建时完成,以防止意外的不同步访问列表:
列表列表=集合。synchronizedList(新LinkedList(…));
这个类的迭代器和listIterator方法返回的迭代器是快速失败的:如果在迭代器创建后的任何时候,以除迭代器自己的remove或add方法以外的任何方式对列表进行了结构修改,迭代器将抛出ConcurrentModificationException异常。因此,在面对并发修改时,迭代器会快速而干净地失败,而不是在未来不确定的时间发生任意的、不确定的行为。
注意,迭代器的快速失败行为不能得到保证,因为一般来说,在存在不同步的并发修改时,不可能做出任何硬保证。快速失败迭代器尽可能地抛出ConcurrentModificationException。因此,编写一个依赖于此异常的程序是错误的:迭代器的快速失败行为应该只用于检测错误。
这个类是Java集合框架的成员。
2.LinkedLis的add方法
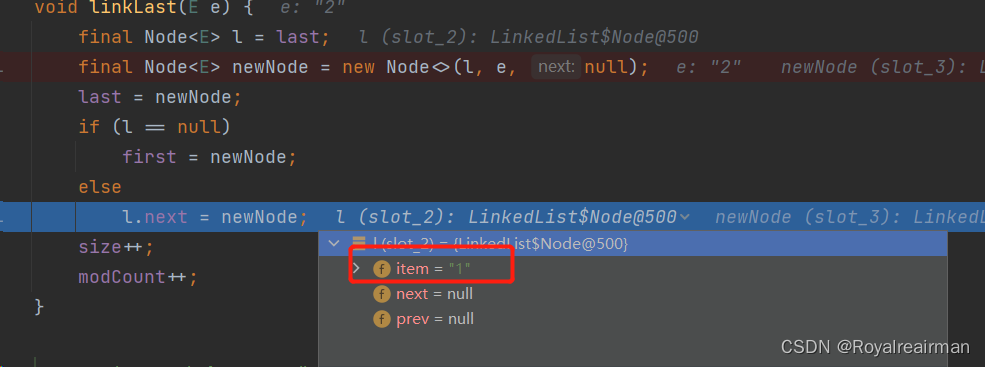
debug启动
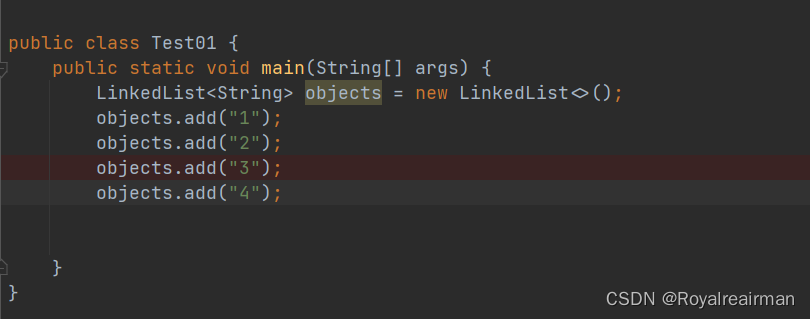
一直下一步,进入node方法 自己是2,他的上一个元素是1,下一个元素没有存,所以是null,
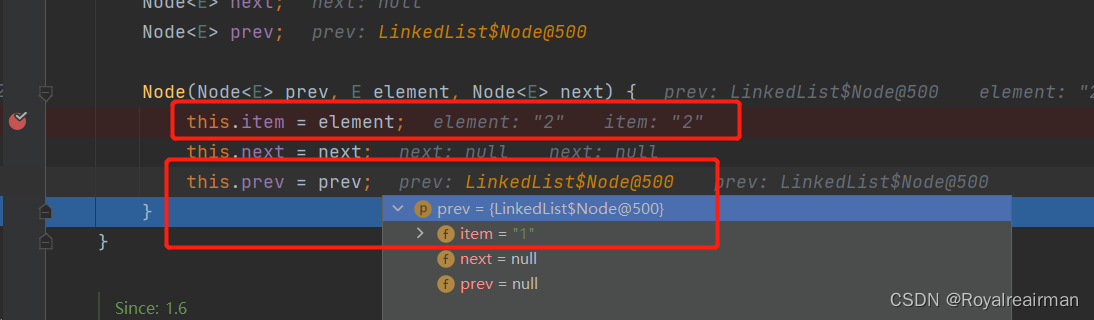
之前最后一个元素是1,现在新的最后一个元素是2
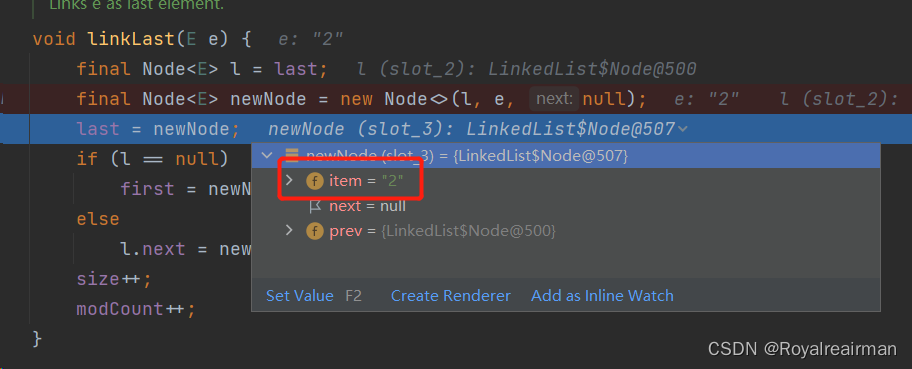
指明1的下一个节点就是2,也是就每次添加都添加在尾部
new node的目的就是为了指向上一个节点,下面的l.next就是为了指向下一个节点
3.手写LinkedList
package com.example.list.list;
//手写LinkedList
public class LinkedList<E> {
private Node<E> first; //第一个节点
private Node<E> last;//最后一个节点
int size = 0;//LinkedList存放元素的个数
private static class Node<E> {
private E item; //当前结点的值
private Node<E> prev;//上一个结点
private Node<E> next;//下一个节点
/**
* @param item 当前节点的值
* @param prev 当前节点的上一个节点
* @param next 当面结点的下一个节点
*/
public Node(Node<E> prev, E item, Node<E> next) {
this.item = item;
this.prev = prev;
this.next = next;
}
}
public void add(E e) {
Node l = last; //获取当前链表中最后一个节点
//创建一个新的node结点
Node<E> newNode = new Node<>(l, e, null);//指向上一个节点
last = newNode;
if (l == null) {
//如果在链表中没有最后一个节点,链表是为空
first = newNode;
} else {
l.next = newNode; //指向下一个节点
}
size++;
}
public E get(int index) {
//下标如果越界,需要
return node(index).item;
}
Node<E> node(int index) {
if (index < size >> 1) {
//查询左边的元素
Node<E> f = first;
for (int i = 0; i < index; i++) {
f = f.next;
}
return f;
} else {
//查询右边元素
Node<E> l = last;
for (int i = size - 1; i > index; i--) {
l = l.prev;
}
return l;
}
}
public E remove(int index) {
return unlike(node(index));
}
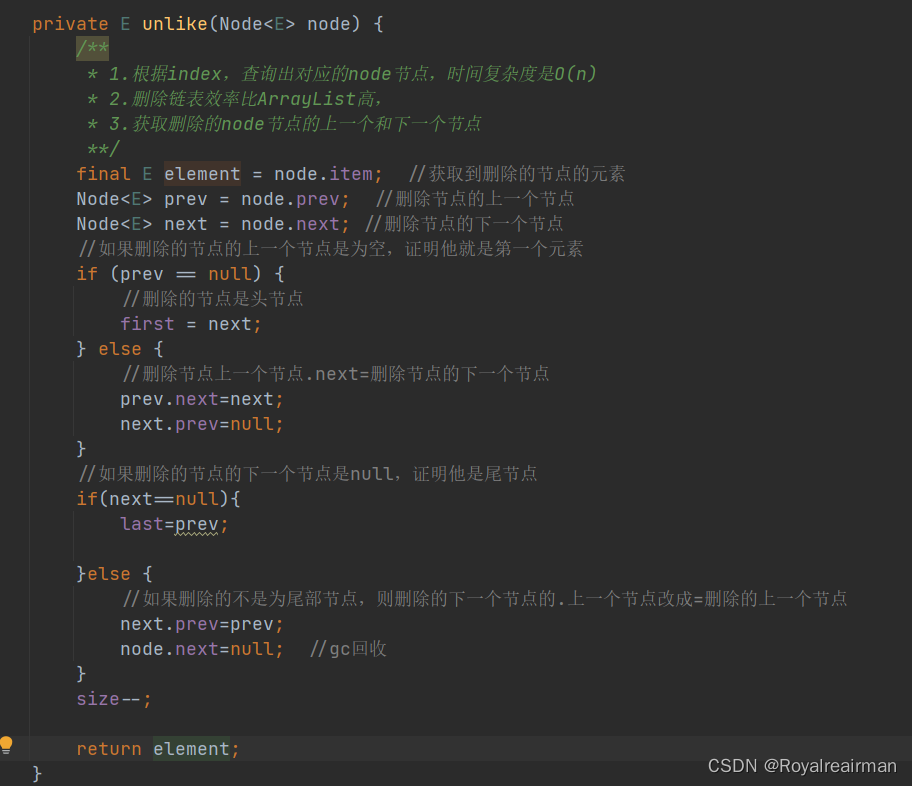
private E unlike(Node<E> node) {
/**
* 1.根据index,查询出对应的node节点,时间复杂度是O(n)
* 2.删除链表效率比ArrayList高,
* 3.获取删除的node节点的上一个和下一个节点
**/
final E element = node.item; //获取到删除的节点的元素
Node<E> prev = node.prev; //删除节点的上一个节点
Node<E> next = node.next; //删除节点的下一个节点
//如果删除的节点的上一个节点是为空,证明他就是第一个元素
if (prev == null) {
//删除的节点是头节点
first = next;
} else {
//删除节点上一个节点.next=删除节点的下一个节点
prev.next=next;
next.prev=null;
}
//如果删除的节点的下一个节点是null,证明他是尾节点
if(next==null){
last=prev;
}else {
//如果删除的不是为尾部节点,则删除的下一个节点的.上一个节点改成=删除的上一个节点
next.prev=prev;
node.next=null; //gc回收
}
size--;
return element;
}
public static void main(String[] args) {
LinkedList<String> list = new LinkedList<>();
list.add("1");
list.add("2");
list.add("3");
list.add("3");
System.out.println(list.get(0));
}
}从手写的,我们很清楚的看 出LinkedList事一个双向链表,在add方法也可以直接看出
4. LinkedList的get方法
debug运行
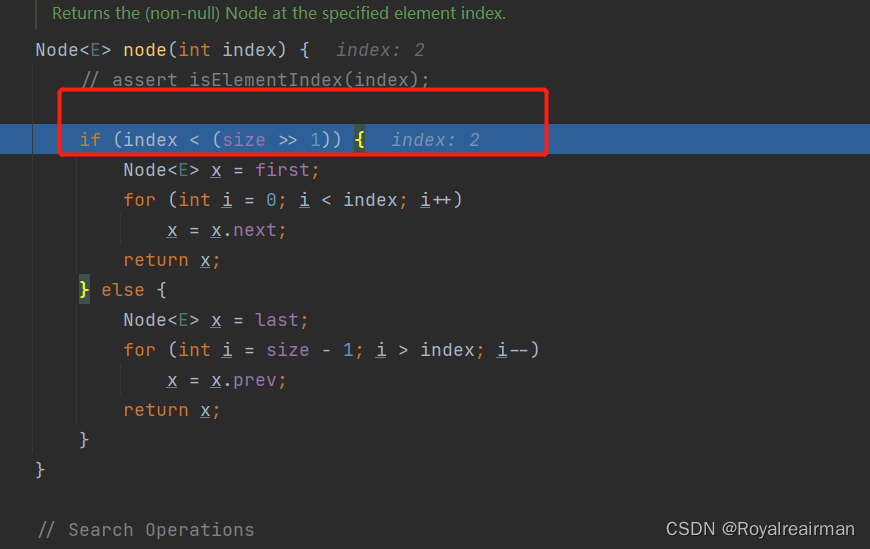
折半算法,目前的容量>>1(可以理解为除以2,但是不是完全除以2),如果index比整数小,就去离链表头近的一边去查,反之就去靠近尾部的一边去查
我们这个 从尾部开始查询,如果是去index小于size/2为true,就是从头开始查
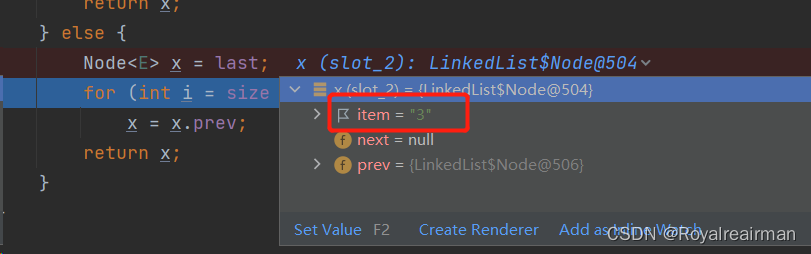
当i=2的时候我们就找到了
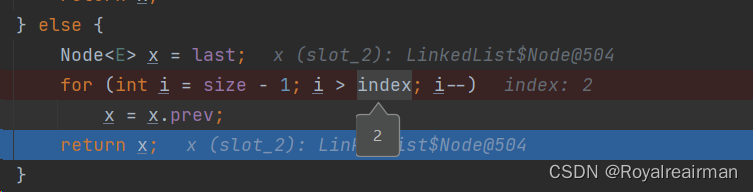 我们得到3的删一个元素2
我们得到3的删一个元素2

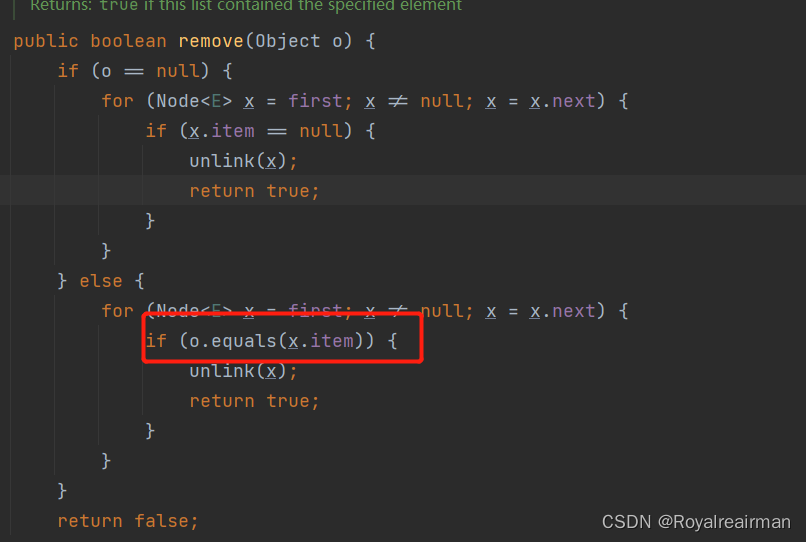
5.LinkedList的remove方法
根据index删除解读
如果删除对象,他就是把所有元素都遍历一遍效率是很低的,一个一个去比较
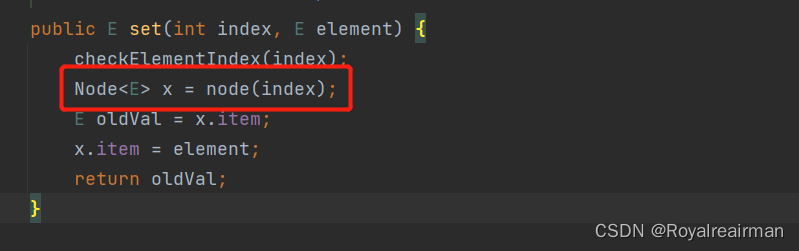
6.LinkedList的set方法
看见这个是不是 很眼熟,这个就是我们查询方法,把查询的道节点的值换成你要改的值
查询效率低,当然这个也快不了。
 7.LinkedList总结
7.LinkedList总结
1.LinkedList是双向链表的list
2.是非线程安全的
3.元素允许为空,允许重复元素
4.删除效率高,查询效率低(根据index的)
5.没有办法扩容
6.实现了栈和队列的操作方法,因此也可以作为栈、队列和双端队列来使用