环境:centos7.6,腾讯云服务器
Linux文章都放在了专栏:【 Linux 】欢迎支持订阅 🌹
相关文章推荐:
【Linux】冯.诺依曼体系结构与操作系统
【Linux】进程理解与学习Ⅰ-进程概念
浅谈Linux下的shell--BASH
【Linux】进程理解与学习Ⅱ-进程状态
【Linux】进程理解与学习Ⅲ-环境变量
前言
在C/C++阶段对于内存分布相关知识我们耳熟能详。知道 内存空间的划分是为了更好的管理和使用空间。就比如说栈区存放局部变量、静态区存放静态全局变量等。但是,我们这里的空间真的指的是
实际的物理空间吗?换句话来说,我们真的了解该空间吗?本次章节将对此进行探讨。
进程地址空间
前文回顾
首先,我们先来回顾一下,在指针阶段我们学习了,内存被划分为一个一个内存单元,每一个单元的大小为1字节。而每一个内存单元都有自己的编号,从0-0xFFFFFFFF。这里的编号就是我们所说的地址。而我们所说的指针就是这一个个的编号,即指针就是地址。不过这里的地址真的是物理意义上的地址吗?
进程地址空间
我们先来看这样一段代码:
#include<unistd.h>
#include<stdlib.h>
#include<sys/wait.h>
//定义全局变量
int tmp=100;
int main()
{
//fork创建子进程
pid_t id=fork();
if(id == 0)
{
//child
//对全局变量做修改
tmp+=100;
printf("子进程:tmp:%d,&tmp:%p\n",tmp,&tmp);
exit(1);
}
//father
waitpid(id,NULL,0);
printf("父进程:tmp:%d,&tmp:%p\n",tmp,&tmp);
return 0;
} 
对于此现象,我们在前文也知道了,这是由于进程的独立性,子进程在对数据进行修改时,会触发写时拷贝所造成的。但是,假如这里的地址是物理地址的话,同一块地址处却有不同的值,这肯定是不现实的。★因此,我们可以得出这样的结论:
我们在语言层面所看到的地址(栈区、堆区、静态区...),并不是真正意义上的物理地址(因为假如是物理地址,就不会出现同一个地址却有不同的值)。
那么这种非物理的地址叫什么呢?在Linux中我们称之为虚拟地址/线性地址。
OS则是将虚拟地址转化为物理地址(如何转化后面会讲到)
如何理解进程地址空间?
首先我们要知道,什么是进程地址空间?
实际上进程地址空间就是操作系统喂给进程的一块“饼”,OS会跟每个进程说,你们有4G的内存空间(栈区、堆区、静态区...)可以使用,但实际上,只有当进程需要用的时候,OS才会分配空间给进程。
举个例子来说,就好比一位富翁,对他的几个儿子说,我的10亿的资产都是你们的。此时儿子心里就会觉得:我有10亿资产可以使用。但实际上富翁并不会直接就是给儿子10亿资产,儿子也不会直接拿到10亿资产。但是假如说,儿子要拿1w元买东西,富翁还是会给儿子·的。此时给的1w才是真正意义上实际的。
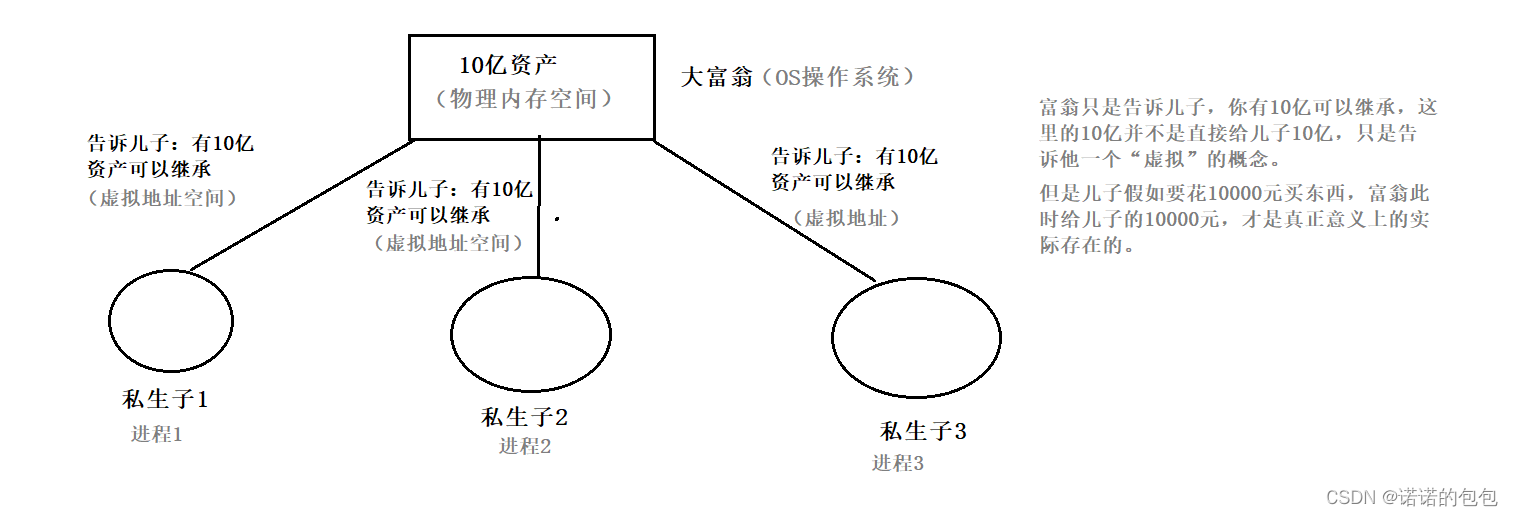
接下来谈一谈OS如何管理我们所说的进程地址空间(即我们所说的栈区、堆区等)?
答:先描述,再组织。实际上我们所说的进程地址空间本质上是一个内核数据结构,struct_mmstruct{}。在该结构体里存在着大量的_start与_end。用来表示每一个区域各自的边界值。
就比如说:堆区的区域范围为[heap_start,heap_end]。而对进程地址空间中各个区域的调整,实际上就是转换为了调整各个区域对应的_start与_end。
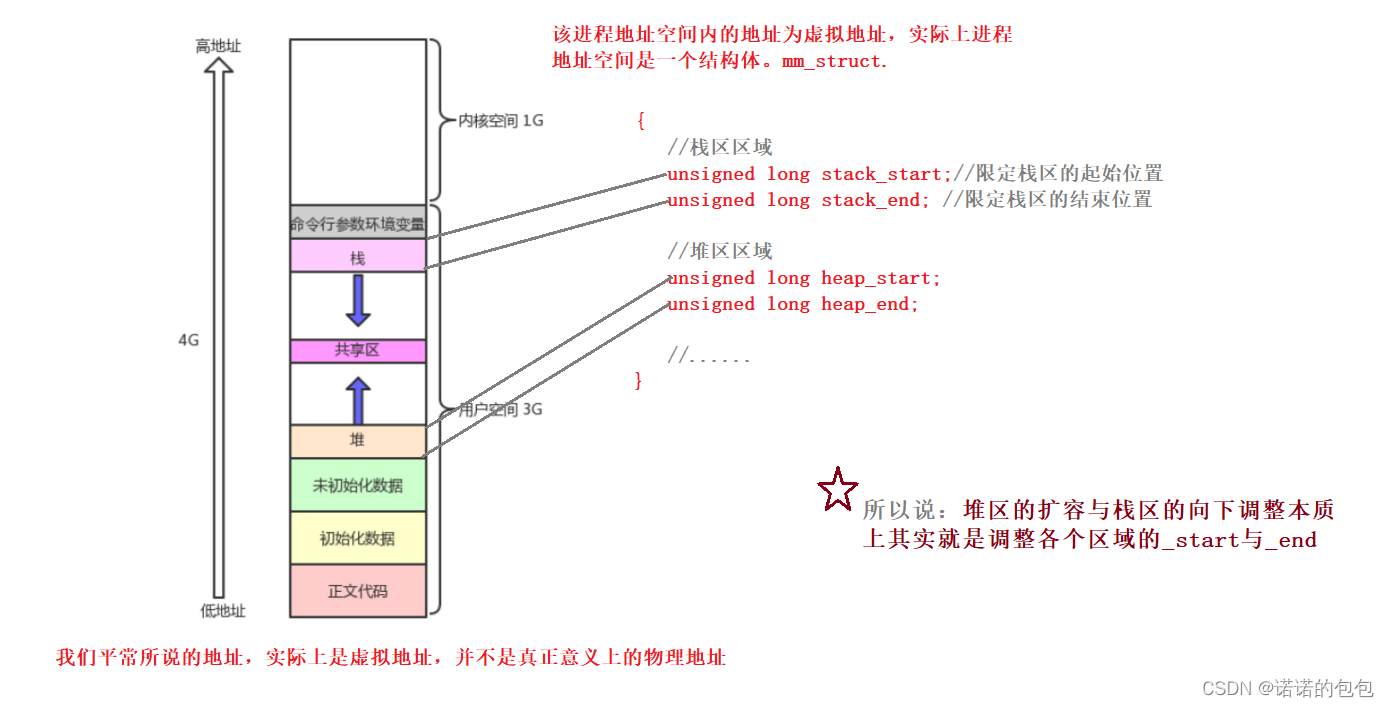
物理空间与虚拟空间
既然我们所说的地址都是虚拟地址,那么真正的物理地址在哪里呢???虚拟地址与物理地址之间又有什么关系呢?
实际上,OS会通过页表,以及MMU的存在,将我们所谓的虚拟地址与物理地址之间建立一种映射关系,通过虚拟地址映射后的地址,可以寻到物理地址。同时可以将物理地址,经过页表映射虚拟地址返回给进程。就好像下面这样:
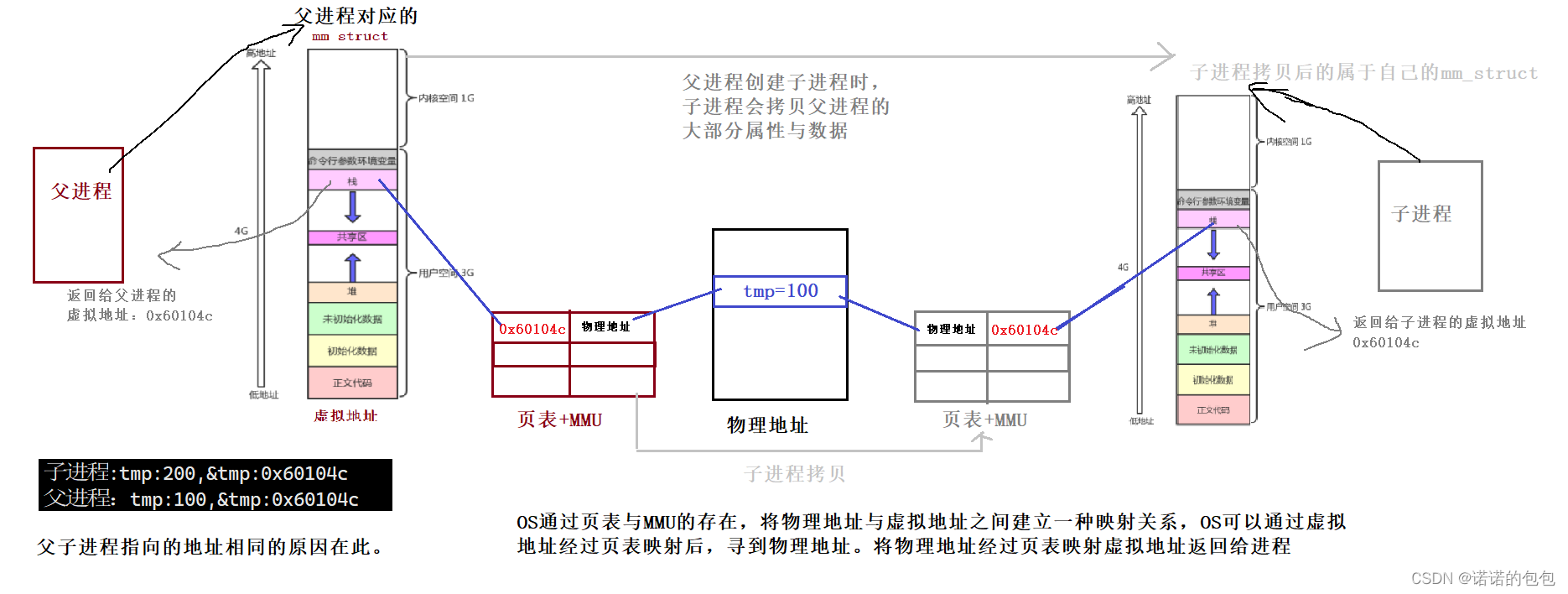
写时拷贝
我们来解释一下最开始的现象:为什么父子进程的tmp地址相同,但结果不同呢?
实际上当一方进程想要对数据进行修改时,会触发写时拷贝,将物理空间原有的指向内容拷贝出一份,在拷贝后的那里进行对数据的修改,并将拷贝后的物理地址重新与原有的虚拟地址建立映射关系:
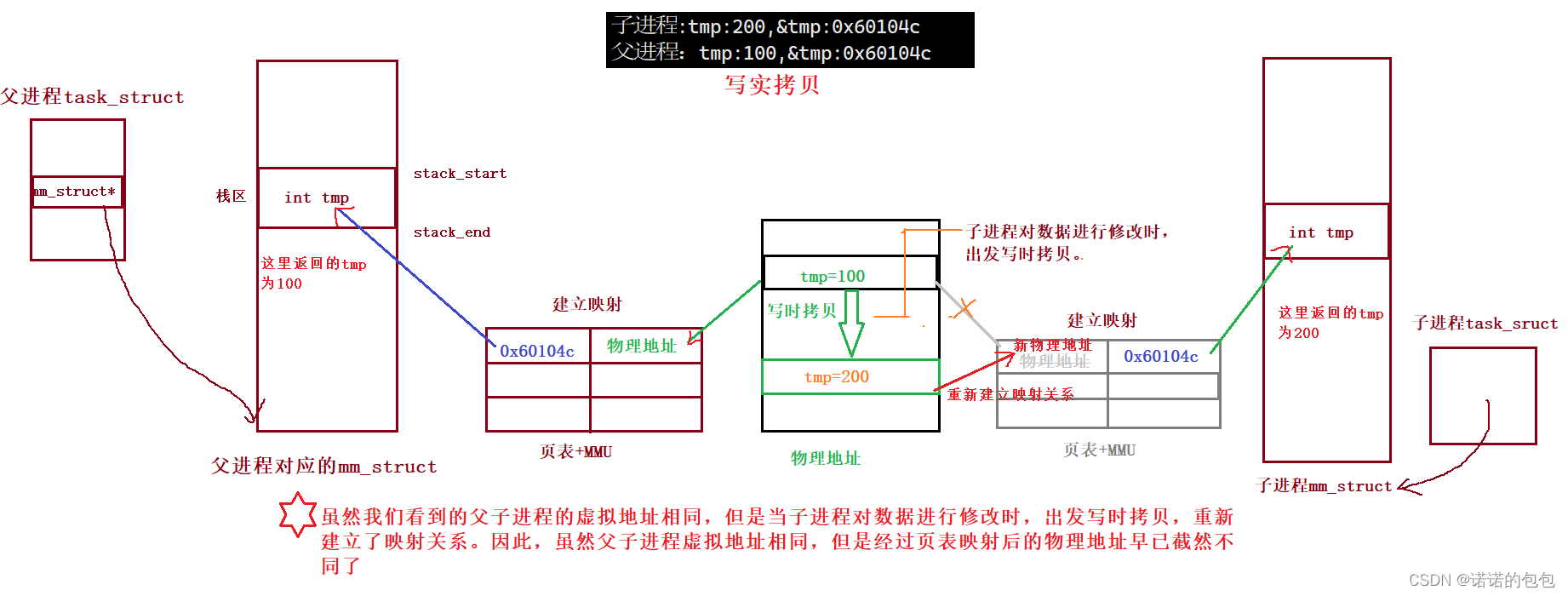
因此我们也可以这么来说,所谓的写时拷贝,实际上是操作系统的一种赌博式行为。OS赌你不会对数据进行修改,所以当各个进程不对数据进行修改时,多个进程在此时访问同一个数据,实际上该数据所在的物理空间是同一块。只有当进程对数据进行修改时,OS才会另外开辟空间,并将原物理空间的内容拷贝进去,重新建立一种映射关系。并满足进程对数据的修改。而这也是进程独立性的一种重要表现,即多个进程互不影响。
而写时拷贝这种“赌博行为”机制的好处就在于:
1、减少了物理空间的使用(多个进程的数据访问的是同一块空间)
2、减少了写时拷贝的次数(只有需要修改数据时才会发生拷贝,否则不会),提高了运行效率(写时拷贝一定会调用拷贝构造进行深拷贝,会有一定效率的影响)。
拓展:为什么存在进程地址空间?
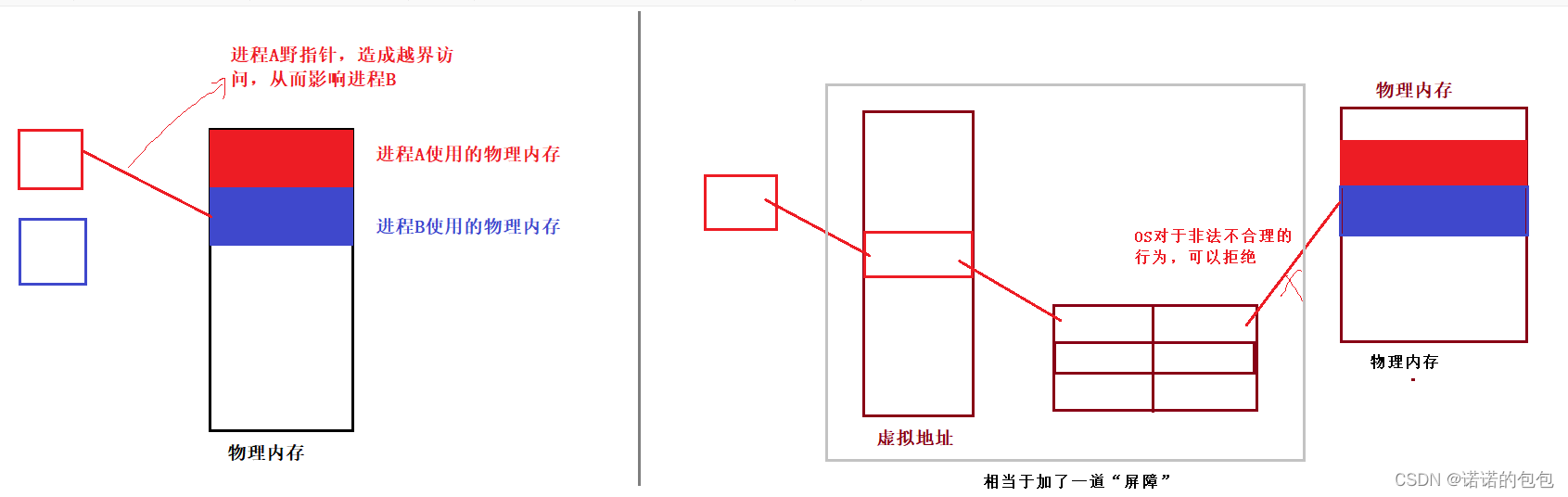
一、防止地址随意访问,保护物理内存与其它进程
实际上,在最开始的时候,还没有虚拟地址这种概念。早期的进程是直接与物理内存打交道。但是可能会存在野指针问题:
假如我们写的程序中存在野指针,这就造成了对物理内存越界访问,就有可能会影响到其它进程。但是现在有了虚拟地址,进程不会与物理内存直接打交道,OS就相当于多了一道屏障,对于进程发出的不合理的请求,OS可以拒绝。
(就好比富翁不会直接把10亿元直接给儿子,因为儿子可能一会儿就败光了,而是告诉儿子,你有10亿元的资产可以使用,我帮你保管,你需要时再给你。这样当儿子发出不合理的使用时,富翁可以直接拒绝)
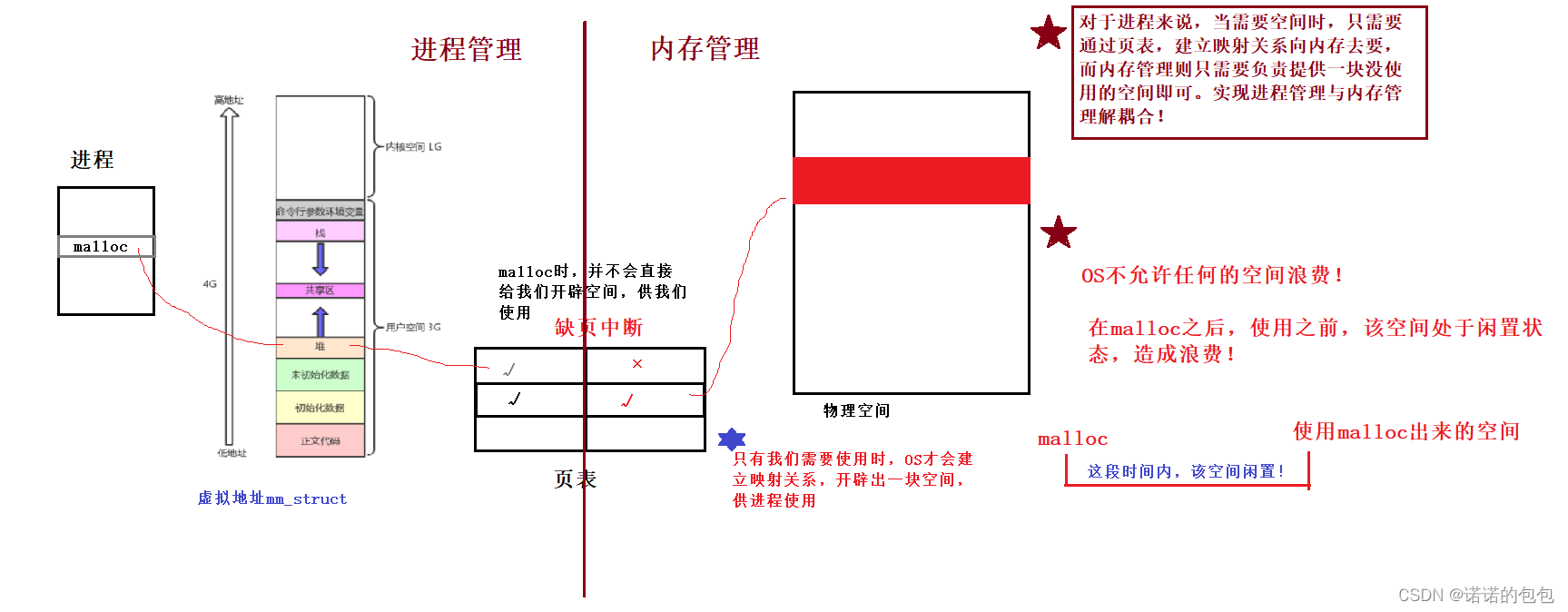
二、将进程管理与内存管理进行解耦合
我们先来谈一谈malloc的本质,实际上我们平常使用malloc开辟一块空间时,OS并不是说直接给我们开辟出一块空间给我们。而是只有当我们需要这块空间时,OS再开辟空间供我们使用。
这是因为OS不允许任何空间的浪费。而当我们malloc之后,使用之前,这块空间处于一种闲置状态,OS是绝对不允许的。这就是所谓的"缺页中断"。
因此对于进程来说,我只需要通过页表映射向内存去要,对于内存来说,我只需要在进程使用空间时提供一块没被使用的空间。这就实现了进程管理与内存管理之间的解耦!
三、让进程以统一的视角,看待自己的代码与数据
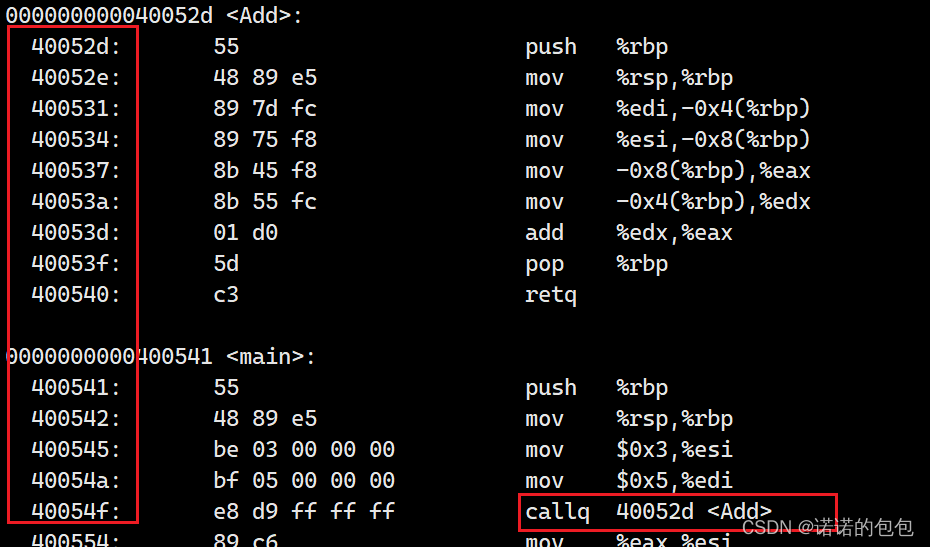
实际上虚拟地址的这种策略并不仅仅只有OS才有,我们的编译器也会遵循。也就是说,我们的程序在被编译时,本身内部已经存在了虚拟地址。我们可以输入指令objdump -S 可执行程序的指令,来查看该程序的反汇编,就好像下面这样,这些都是虚拟地址:
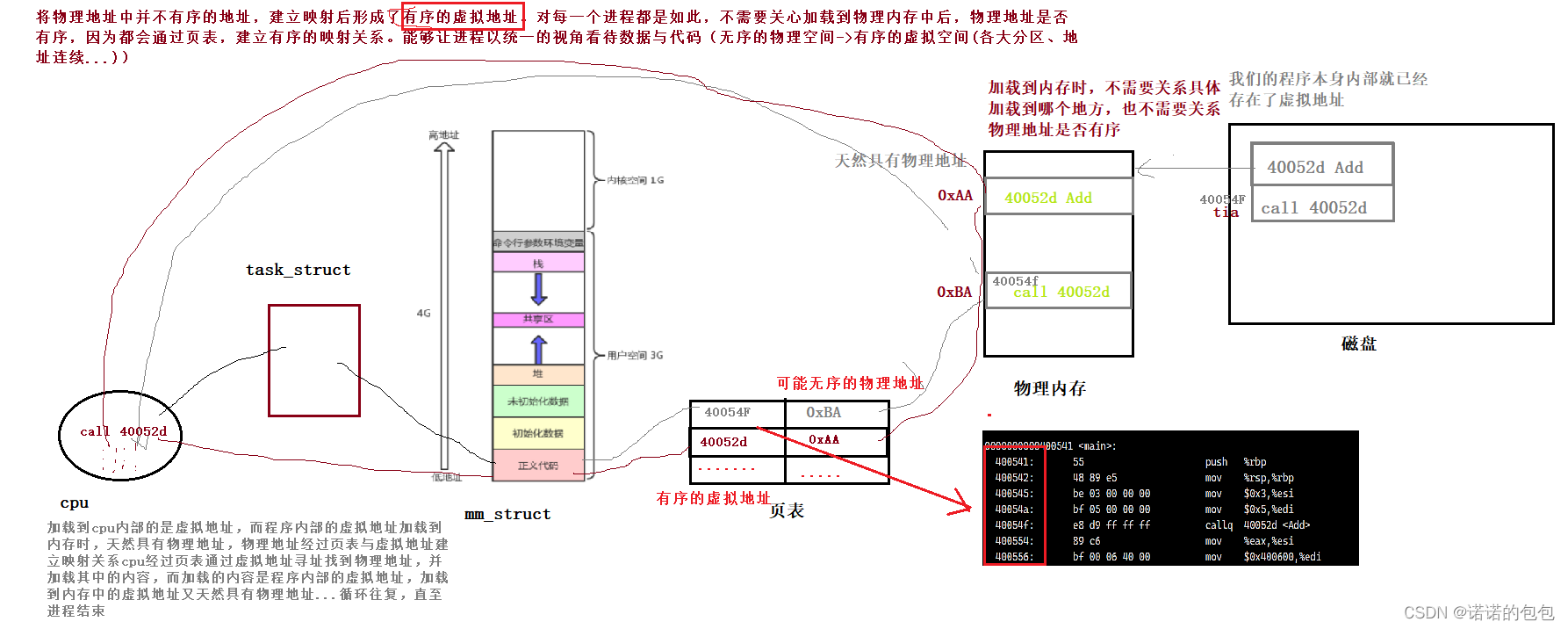
也就是说,我们的程序在被加载到内存之前,本身内部就已经有了虚拟地址: 加载到物理内存之后,则天然具有物理地址,然后通过 页表映射,建立与虚拟地址之间的联系。而当CPU进行调度时,通过虚拟地址经过页表映射后,将物理地址的内容加载到CPU运行,此时 CPU内部全都是程序内部已经存在的虚拟地址,再紧接着,CPU通过虚拟地址经过页表寻址到物理地址,并加载到CPU运行...循环以往,直到跑完整个程序。
因此 对于每一个进程来说,我并不需要关心我内部的代码与数据被加载到物理内存的哪一个位置,不管是否物理地址连续有序,都会经过页表映射建立与虚拟地址之间的联系,将物理内存的并不连续有序的物理地址,转化为了虚拟内存中有序的虚拟地址。每一个进程都是如此,将看待物理内存中并不有序的物理地址,经过映射后转化为看待虚拟内存中的有序地址。
end.
生活原本沉闷,但跑起来就会有风!🌹