目录
一、归一化/标准化
1.1 为什么我们要进行归一化/标准化?
二、归一化
2.1 定义
2.2 公式
2.3 归一化总结
三、标准化
3.1 定义
3.2 公式
3.3 标准化总结
一、归一化/标准化
1.1 为什么我们要进行归一化/标准化?
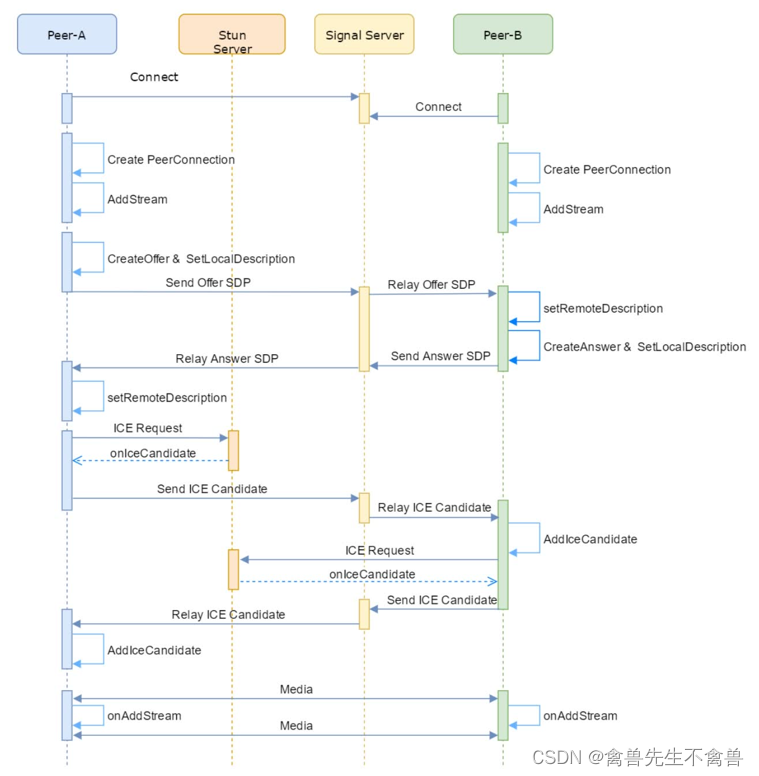
特征的单位或者大小相差较大,或者某特征的方差相比其他的特征要大出几个数量级,容易影响(支配)目标结果,使得一些算法无法学习到其它的特征。
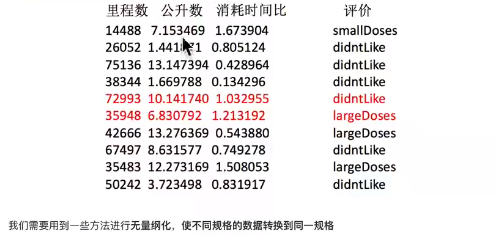
举例:约会对象数据
相亲约会对象数据,这个样本时男士的数据,三个特征(玩游戏所消耗时间的百分比、每年获得的飞行常客里程数、每周消费的冰淇淋公升数)。然后有一个所属类别,被女士评价的三个类别(不喜欢didnt、魅力一般small、极具魅力large),也许也就是说飞行里程数对于计算结果或者说相亲结果影响较大,但是统计的人觉得这三个特征同等重要。
二、归一化
2.1 定义
通过对原始数据进行变换把数据映射到(默认为[0,1])之间。
2.2 公式
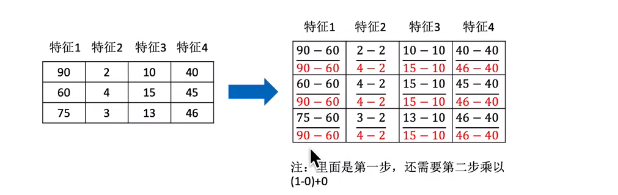
那么怎么理解这个过程呢?我们通过一个例子

1、作用于每一列,max为一列的最大值,min为一列的最小值,那么X”为最终结果。
2、mx,mi分别为指定区间值,如制定区间[mx,mi]。 默认mx为1,mi为0。
2.3 归一化总结
注意最大值最小值是变化的,最大值与最小值非常容易受异常点影响,所以这种方法鲁棒性较差;
只适合传统精确小数据场景;
三、标准化
3.1 定义
通过对原始数据进行变换把数据变换到均值为0,标准差为1范围内。
3.2 公式

作用于每一列,mean为平均值,o为标准差,x为当前值
对于归一化来说:如果出现异常点,影响了最大值和最小值,那么结果显然会发生改变;
对于标准化来说:如果出现异常点,由于具有一定数据量,少量的异常点对于平均值的影响并不大,从而方差改变较小。
3.3 标准化总结
在已有样本足够多的情况下比较稳定,适合现代嘈杂大数据场景。