文章目录
- 一、实验简介
- 二、隐式链表实现
- 基本宏
- 块的相关函数
- mm_init
- mm_malloc
- mm_free
- mm_realloc
- extend_heap
- blk_merge
- blk_find
- blk_split
- 使用下次匹配
- 三、显式链表实现
- 四、分离适配
- 五、完整代码
- 隐式链表
- 显式链表
- 课本实现
一、实验简介
实现一个动态内存分配器。
- tar xvf malloclab-handout.tar
- 修改其中的mm.c
- 使用 make 生成测试程序,执行 ./mdriver -V查看测试程序如何使用
- 执行 ./mdriver -V,会显示失败,需要更改 config.h中的
TRACEDIR的路径 - 需要下载 traces 目录,放到自己的目录下
- 执行 ./mdriver -V,会显示失败,需要更改 config.h中的
- mm.c 需要实现 4个 函数
- init mm_init(void):初始化操作,在执行其他操作之前,执行该函数
- void *mm_malloc(sizt_t size):返回一个指向至少size字节大小的分配块的指针,该分配块不与其他块重叠且位于堆区域,需要注意进行8B对齐
- void mm_free(void *ptr):释放ptr指向的分配块
- void *mm_realloc(void *ptr, size_t size):该函数返回一个至少 size 大小的指针,如果ptr 为NULL,则效果等同 mm_malloc,如果 size 为0,则等同于 mm_free。ptr如果不为NULL,则其必须是之前调用的mm_malloc或mm_realloc函数返回的指针,该函数将ptr指向的分配块的大小更改为新的 size 大小,可能返回新的地址也可能使用旧的地址,这取决于内存分配器的实现以及旧块中内部碎片的数量以及size的大小
- mm.c中包含一个 mm_check函数,会帮助我们进行检查,所有空闲块是否都在空闲列表中、分配的块是否有重叠、是否存在未合并的连续的空闲块等问题
- 完成时需要将 mm_check函数都注释掉,因为其会降低吞吐
- 编写代码时,不可以调用 libc 中的代码,比如 sbrk、malloc等,
可以调用memlib.c中的函数,比如 mem_srk、mem_heap_lo、mem_heap_hi等,memlib可以充当内存管理系统`- mem_sbrk:从内存管理系统中申请额外的内存,用于扩展堆
- 不可以在mm.c中定义全局或静态的复合数据结构,比如数组、结构体、树等,但可以声明全局的变量,比如int、float等等
二、隐式链表实现
基本宏
由于隐式链表就是一块连续的内存区域,将其切分成不同的内存块,每个块首先开头都有一个header,末尾有一个footer。
header和footer的内容是一样,都占据4B,前27bit记录该内存块的总长度,后三位表示该内存块是否分配出去。
因此可以定义一些基本的宏,方便我们操作。结合书籍p599的内容,将其改为自己更好的理解其含义的宏。
#define WSIZE 4
#define DSIZE 8
#define HEAPSIZE (1 << 12)
#define MAX(x, y) ((x) > (y) ? (x) : (y))
#define BLK_INIT(size, alloc) ((size) | (alloc)) //初始化块的header和footer
#define GET_WORD(p) (*(unsigned int *)(p))
#define PUT_WORD(p, val) (*(unsigned int *)(p) = (val))
#define GET_SIZE(header) (GET_WORD(header) & ~0x7)
#define GET_ALLOC(header) (GET_WORD(header) & 0x1)
#define GET_HEADER(p) ((char *)(p) - WSIZE)
#define GET_FOOTER(p) ((char *)(p) + GET_SIZE(GET_HEADER(p)) - DSIZE)
#define GET_PREV_FOOTER(p) ((char *)(p) - DSIZE)
#define NEXT_BLKP(p) ((char *)(p) + GET_SIZE(GET_HEADER(p)))
#define PREV_BLKP(p) ((char *)(p) - GET_SIZE(GET_PREV_FOOTER(p)))
块的相关函数
我们需要实现分配初始化堆、分配内存块、释放内存块、内存块重分配,除了这几个题目要求的函数,我们还需要实现一些必要的函数:
- 在分配内存块时,需要匹配合适的内存块,此时需要一个内存块匹配算法,包括首次适应、最佳适应等等
- 匹配到内存块后,如果其内容大于我们的要求,需要进行块的切割,将当前块切分成两个内存块
- 当块切分后,剩余的空闲部分需要放回到堆中,当空闲块放回堆中的时候需要进行块的合并
- 当堆的内存不足够的时候,需要进行堆的扩展
static char *blk_heap;
//扩展堆
static void *extend_heap(size_t words);
//块的合并
static void *blk_merge(void *blk);
//块的分割
static void *blk_split(void *blk, size_t size);
//块匹配算法
static void *blk_find(size_t size);
mm_init
隐式链表实现时,初始的时候,包括一个序言块和一个结尾块,序言块包含一个header和footer,结尾块只需要一个header,由于要求双字对齐,所以初始的时候需要分配四个字节,即 ALGIN | 序言块Header | 序言块footer | 结尾块
int mm_init(void)
{
//首先创建一个序言块以及一个结尾块,序言块需要2个W,结尾块需要一个W,由于双字对齐,申请四个
if((blk_heap = mem_sbrk(4 * WSIZE)) == (void *)(-1)){
printf("init heap failed\n");
return -1;
}
PUT_WORD(blk_heap, 0);//对齐字节
//序言块占2B
PUT_WORD(blk_heap + WSIZE, BLK_INIT(DSIZE, 1));
PUT_WORD(blk_heap + (2 * WSIZE), BLK_INIT(DSIZE, 1));
//结尾块,结尾块header长度要求为0,分配字段为1
PUT_WORD(blk_heap + (3 * WSIZE), BLK_INIT(0, 1));
blk_heap += (2 * WSIZE);//堆指向序言块的data部分,data部分为空,因此指向footer
//创建堆的其余空间
if(extend_heap(HEAPSIZE / WSIZE) == NULL){
printf("create heap failed\n");
return -1;
}
return 0;
}
mm_malloc
分配块的过程也是比较简单的,即通过块匹配算法寻找一个合适的块,找到进行切割并返回
否则,进行堆扩展,从内存系统中再申请一块新的足够大的内存扩展堆之后进行分配,然后切割需要的大小并返回
void *mm_malloc(size_t size)
{
size_t real_size;
size_t extend_size;
char *blk;
if(size == 0){
return NULL;
}
if(size <= DSIZE){
real_size = 2 * DSIZE;
}else{
real_size = DSIZE + ((size + (DSIZE - 1)) / DSIZE) * DSIZE;
//一个DSIZE用于header和footer,size + ALIGN部分计算需要的另外的DSIZE
}
if((blk = blk_find(real_size)) == NULL){
//未找到合适的块,扩展堆
extend_size = MAX(real_size, HEAPSIZE);
if((blk = extend_heap(extend_size / WSIZE)) == NULL){
printf("extend heap failed\n");
return NULL;
}
}
//切出需要的大小
blk_split(blk, real_size);
return blk;
}
mm_free
将释放块的 alloc字段置为0,然后判断和前面、后面的块的关系,进行合并即可
void mm_free(void *ptr)
{
size_t blk_size = GET_SIZE(GET_HEADER(ptr));
PUT_WORD(GET_HEADER(ptr), BLK_INIT(blk_size, 0));
PUT_WORD(GET_FOOTER(ptr), BLK_INIT(blk_size, 0));
blk_merge(ptr);
}
mm_realloc
重分配,将一个块的大小更改为新的size,当块的指针为NULL的时候,分配一个大小为size的块,如果size为0,将块释放
否则,申请一个size大小的新块,将旧块中的内容拷贝到新块中,释放旧块并合并,返回新块的指针
void *mm_realloc(void *ptr, size_t size)
{
void *newptr;
size_t copySize;
if(ptr == NULL){
return mm_malloc(size);
}
if(size == 0){
mm_free(ptr);
}
newptr = mm_malloc(size);
if (newptr == NULL)
return NULL;
copySize = GET_SIZE(GET_HEADER(newptr));
size = GET_SIZE(GET_HEADER(ptr));
if (size < copySize)
copySize = size;
//不拷贝footer,header和footer在malloc的时候已经设置完毕
memcpy(newptr, ptr, copySize - WSIZE);
mm_free(ptr);
return newptr;
}
extend_heap
扩展堆,调用内存系统的 mem_sbrk 函数。
每次堆扩展的时候,都是在当前堆的结尾块之后进行扩展,且扩展的部分当作一整个块接入到现有堆中,因此原堆的结尾块可以当作扩展部分的header,然后初始化扩展部分的footer即可。最后,将最后一个块作为一个新的结尾块。
static void *extend_heap(size_t words){
char *new_blk;
size_t real_size;
//字节对齐
real_size = (words % 2) ? (words + 1) * WSIZE : (words * WSIZE);
if((new_blk = mem_sbrk(real_size)) == -1){
printf("extend heap failed\n");
return NULL;
}
//获取到的new_blk指针不包含header,由于每次在结尾块之后扩充
//因此拿扩充前的结尾块当作扩展部分的header,然后创建一个新的footer
PUT_WORD(GET_HEADER(new_blk), BLK_INIT(real_size, 0));
PUT_WORD(GET_FOOTER(new_blk), BLK_INIT(real_size, 0));
//创建新的结尾块
PUT_WORD(GET_HEADER(NEXT_BLKP(new_blk)), BLK_INIT(0, 1));
//如果前一个块是空闲的,需要进行合并
return blk_merge(new_blk);
}
blk_merge
块的合并需要和前后两个块进行对比,如果有块是空的,就进行合并
static void *blk_merge(void *blk){
size_t prev_alloc = GET_ALLOC(GET_FOOTER(PREV_BLKP(blk)));
size_t next_alloc = GET_ALLOC(GET_HEADER(NEXT_BLKP(blk)));
size_t size = GET_SIZE(GET_HEADER(blk));
if(prev_alloc && next_alloc){
return blk;
}
if(!prev_alloc && next_alloc){
//合并前面的
size += GET_SIZE(GET_HEADER(PREV_BLKP(blk)));
PUT_WORD(GET_FOOTER(blk), BLK_INIT(size, 0));//更新当前块的footer
PUT_WORD(GET_HEADER(PREV_BLKP(blk)), BLK_INIT(size, 0));
blk = PREV_BLKP(blk);
}else if(prev_alloc && !next_alloc){
//合并后面的
size += GET_SIZE(GET_HEADER(NEXT_BLKP(blk)));
PUT_WORD(GET_HEADER(blk), BLK_INIT(size, 0));
PUT_WORD(GET_FOOTER(blk), BLK_INIT(size, 0));
}else{
size += GET_SIZE(GET_HEADER(PREV_BLKP(blk)));
size += GET_SIZE(GET_FOOTER(NEXT_BLKP(blk)));
PUT_WORD(GET_HEADER(PREV_BLKP(blk)), BLK_INIT(size, 0));
PUT_WORD(GET_FOOTER(NEXT_BLKP(blk)), BLK_INIT(size, 0));
blk = PREV_BLKP(blk);
}
return blk;
}
blk_find
块匹配算法,这里先使用首次匹配算法
static void *blk_find(size_t size){
char *blk = blk_heap;
size_t alloc;
size_t blk_size;
while(GET_SIZE(GET_HEADER(NEXT_BLKP(blk))) > 0){
blk = NEXT_BLKP(blk);
alloc = GET_ALLOC(GET_HEADER(blk));
if(alloc == 1){
continue;
}
blk_size = GET_SIZE(GET_HEADER(blk));
if(blk_size < size){
continue;
}
return blk;
}
return NULL;
}
blk_split
块切割,计算块的大小以及需要的大小,判断剩余的部分是否足够形成一个新的块(每个新的块最少8B)
如果足够,就进行切分,如果不够就不进行切分了
static void *blk_split(void *blk, size_t size){
size_t blk_size = GET_SIZE(GET_HEADER(blk));
size_t need_size = size;
size_t leave_size = blk_size - need_size;
if(leave_size >= 2 * DSIZE){
//进行块的切分
PUT_WORD(GET_HEADER(blk), BLK_INIT(need_size, 1));
PUT_WORD(GET_FOOTER(blk), BLK_INIT(need_size, 1));
PUT_WORD(GET_HEADER(NEXT_BLKP(blk)), BLK_INIT(leave_size, 0));
PUT_WORD(GET_FOOTER(NEXT_BLKP(blk)), BLK_INIT(leave_size, 0));
}else{
PUT_WORD(GET_HEADER(blk), BLK_INIT(blk_size, 1));
PUT_WORD(GET_FOOTER(blk), BLK_INIT(blk_size, 1));
}
return blk;
}
最终结果,得分57,内存利用率还可以,但是吞吐很低,这是因为我们每次都是从头开始匹配,会有大量的时间用于匹配空闲的内存块。
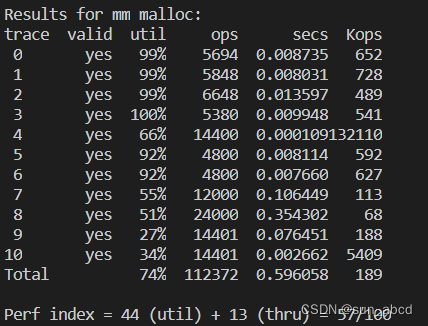
使用下次匹配
我们需要记录上一次匹配的块的位置,然后下一次匹配的时候不从头开始,而是从上一次匹配的块的下一个位置开始。
因此,需要添加一个指针用于记录上一次匹配的块的位置。
每当我们进行块的分配的时候,更新该指针。
需要注意的是块合并的时候也需要更新该指针,因为可能刚好该指针指向的块由于前面的块释放后被合并形成一个新的块,此时该指针指向的位置是新的块的data部分,会导致错误。
//添加一个新的指针
static char *next_match;
int mm_init(){
//....
next_match = blk_heap; //初始化
}
//在匹配时,使用next_match进行匹配
static void *blk_find(size_t size){
//char *blk = blk_heap;
char *blk = next_match;
size_t alloc;
size_t blk_size;
while(GET_SIZE(GET_HEADER(NEXT_BLKP(blk))) > 0){
blk = NEXT_BLKP(blk);
alloc = GET_ALLOC(GET_HEADER(blk));
if(alloc == 1){
continue;
}
blk_size = GET_SIZE(GET_HEADER(blk));
if(blk_size < size){
continue;
}
next_match = blk; //更新下一次匹配的位置
return blk;
}
blk = blk_heap;
while(blk != next_match){
blk = NEXT_BLKP(blk);
alloc = GET_ALLOC(GET_HEADER(blk));
if(alloc == 1){
continue;
}
blk_size = GET_SIZE(GET_HEADER(blk));
if(blk_size < size){
continue;
}
next_match = blk;
return blk;
}
return NULL;
}
//在合并时,也需要注意next_match的变更
static void *blk_merge(void *blk){
size_t prev_alloc = GET_ALLOC(GET_FOOTER(PREV_BLKP(blk)));
size_t next_alloc = GET_ALLOC(GET_HEADER(NEXT_BLKP(blk)));
size_t size = GET_SIZE(GET_HEADER(blk));
if(prev_alloc && next_alloc){
return blk;
}
if(!prev_alloc && next_alloc){
//合并前面的
size += GET_SIZE(GET_HEADER(PREV_BLKP(blk)));
PUT_WORD(GET_FOOTER(blk), BLK_INIT(size, 0));//更新当前块的footer
PUT_WORD(GET_HEADER(PREV_BLKP(blk)), BLK_INIT(size, 0));
blk = PREV_BLKP(blk);
}else if(prev_alloc && !next_alloc){
//合并后面的
size += GET_SIZE(GET_HEADER(NEXT_BLKP(blk)));
PUT_WORD(GET_HEADER(blk), BLK_INIT(size, 0));
PUT_WORD(GET_FOOTER(blk), BLK_INIT(size, 0));
}else{
size += GET_SIZE(GET_HEADER(PREV_BLKP(blk)));
size += GET_SIZE(GET_FOOTER(NEXT_BLKP(blk)));
PUT_WORD(GET_HEADER(PREV_BLKP(blk)), BLK_INIT(size, 0));
PUT_WORD(GET_FOOTER(NEXT_BLKP(blk)), BLK_INIT(size, 0));
blk = PREV_BLKP(blk);
}
//发生合并时,需要更新下一次匹配算法使用的指针,防止其指向的块被合并
if((next_match > (char *)blk) && (next_match < NEXT_BLKP(blk))){
//此时next_match指向合并后的块的内部
next_match = blk;
}
return blk;
}
测试结果为84:
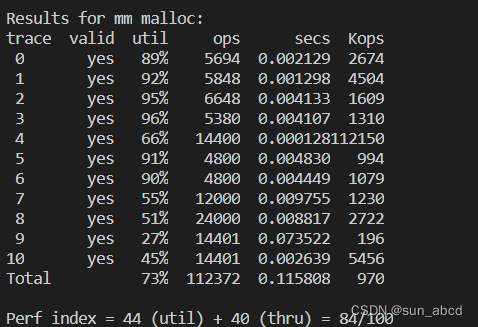
三、显式链表实现
由于隐式链表的方式,随着块的数目的增加,导致匹配块的速率会显著降低,即块的分配与堆中的块的数目呈线性下降关系。因此,我们可以构建一个显式的链表,即将空闲的块组织成链表,而不需要每次进行块的匹配的时候去匹配很多已经分配的块。
按照书上对于显示空闲链表的定义,我们在空闲块的载荷中添加两个成员,分别为 prev 和 next 分别指向前一个空闲块和下一个空闲块,当块分配出去之后,将这两个指针取消(但要保证不断链),当块被释放时,我们选择后进先出的实现,即将释放的块插入到空闲链表的末尾。
四、分离适配
五、完整代码
隐式链表
#include <stdio.h>
#include <stdlib.h>
#include <assert.h>
#include <unistd.h>
#include <string.h>
#include "mm.h"
#include "memlib.h"
team_t team = {
/* Team name */
"ateam",
/* First member's full name */
"Harry Bovik",
/* First member's email address */
"bovik@cs.cmu.edu",
/* Second member's full name (leave blank if none) */
"",
/* Second member's email address (leave blank if none) */
""
};
/* single word (4) or double word (8) alignment */
#define ALIGNMENT 8
/* rounds up to the nearest multiple of ALIGNMENT */
#define ALIGN(size) (((size) + (ALIGNMENT-1)) & ~0x7)
#define SIZE_T_SIZE (ALIGN(sizeof(size_t)))
#define WSIZE 4
#define DSIZE 8
#define HEAPSIZE (1 << 12)
#define MAX(x, y) ((x) > (y) ? (x) : (y))
#define BLK_INIT(size, alloc) ((size) | (alloc)) //初始化块的header和footer
#define GET_WORD(p) (*(unsigned int *)(p))
#define PUT_WORD(p, val) (*(unsigned int *)(p) = (val))
#define GET_SIZE(header) (GET_WORD(header) & ~0x7)
#define GET_ALLOC(header) (GET_WORD(header) & 0x1)
#define GET_HEADER(p) ((char *)(p) - WSIZE)
#define GET_FOOTER(p) ((char *)(p) + GET_SIZE(GET_HEADER(p)) - DSIZE)
#define GET_PREV_FOOTER(p) ((char *)(p) - DSIZE)
#define NEXT_BLKP(p) ((char *)(p) + GET_SIZE(((char *)(p) - WSIZE)))
#define PREV_BLKP(p) ((char *)(p) - GET_SIZE(((char *)(p) - DSIZE)))
static char *blk_heap;
static char *next_match;
//扩展堆
static void *extend_heap(size_t words);
//块的合并
static void *blk_merge(void *blk);
//块的分割
static void *blk_split(void *blk, size_t size);
//块匹配算法
static void *blk_find(size_t size);
int mm_init(void)
{
//首先创建一个序言块以及一个结尾块,序言块需要2个W,结尾块需要一个W,由于双字对齐,申请四个
if((blk_heap = mem_sbrk(4 * WSIZE)) == (void *)(-1)){
printf("init heap failed\n");
return -1;
}
PUT_WORD(blk_heap, 0);//对齐字节
//序言块占2B
PUT_WORD(blk_heap + WSIZE, BLK_INIT(DSIZE, 1));
PUT_WORD(blk_heap + (2 * WSIZE), BLK_INIT(DSIZE, 1));
//结尾块,结尾块header长度要求为0,分配字段为1
PUT_WORD(blk_heap + (3 * WSIZE), BLK_INIT(0, 1));
blk_heap += (2 * WSIZE);//堆指向序言块的data部分,data部分为空,因此指向footer
next_match = blk_heap;
//创建堆的其余空间
if(extend_heap(HEAPSIZE / WSIZE) == NULL){
printf("create heap failed\n");
return -1;
}
return 0;
}
void *mm_malloc(size_t size)
{
size_t real_size;
size_t extend_size;
char *blk;
if(size == 0){
return NULL;
}
if(size <= DSIZE){
real_size = 2 * DSIZE;
}else{
real_size = DSIZE + ((size + (DSIZE - 1)) / DSIZE) * DSIZE;
//一个DSIZE用于header和footer,size + ALIGN部分计算需要的另外的DSIZE
}
if((blk = blk_find(real_size)) == NULL){
//未找到合适的块,扩展堆
extend_size = MAX(real_size, HEAPSIZE);
if((blk = extend_heap(extend_size / WSIZE)) == NULL){
printf("extend heap failed\n");
return NULL;
}
}
//切出需要的大小
blk_split(blk, real_size);
return blk;
}
void mm_free(void *ptr)
{
size_t blk_size = GET_SIZE(GET_HEADER(ptr));
PUT_WORD(GET_HEADER(ptr), BLK_INIT(blk_size, 0));
PUT_WORD(GET_FOOTER(ptr), BLK_INIT(blk_size, 0));
blk_merge(ptr);
}
void *mm_realloc(void *ptr, size_t size)
{
void *newptr;
size_t copySize;
if(ptr == NULL){
return mm_malloc(size);
}
if(size == 0){
mm_free(ptr);
}
newptr = mm_malloc(size);
if (newptr == NULL)
return NULL;
copySize = GET_SIZE(GET_HEADER(newptr));
size = GET_SIZE(GET_HEADER(ptr));
if (size < copySize)
copySize = size;
//不拷贝footer,header和footer在malloc的时候已经设置完毕
memcpy(newptr, ptr, copySize - WSIZE);
mm_free(ptr);
return newptr;
}
static void *extend_heap(size_t words){
char *new_blk;
size_t real_size;
//字节对齐
real_size = (words % 2) ? (words + 1) * WSIZE : (words * WSIZE);
if((new_blk = mem_sbrk(real_size)) == -1){
printf("extend heap failed\n");
return NULL;
}
//获取到的new_blk指针不包含header,由于每次在结尾块之后扩充
//因此拿扩充前的结尾块当作扩展部分的header,然后创建一个新的footer
PUT_WORD(GET_HEADER(new_blk), BLK_INIT(real_size, 0));
PUT_WORD(GET_FOOTER(new_blk), BLK_INIT(real_size, 0));
//创建新的结尾块
PUT_WORD(GET_HEADER(NEXT_BLKP(new_blk)), BLK_INIT(0, 1));
//如果前一个块是空闲的,需要进行合并
return blk_merge(new_blk);
}
static void *blk_merge(void *blk){
size_t prev_alloc = GET_ALLOC(GET_FOOTER(PREV_BLKP(blk)));
size_t next_alloc = GET_ALLOC(GET_HEADER(NEXT_BLKP(blk)));
size_t size = GET_SIZE(GET_HEADER(blk));
if(prev_alloc && next_alloc){
return blk;
}
if(!prev_alloc && next_alloc){
//合并前面的
size += GET_SIZE(GET_HEADER(PREV_BLKP(blk)));
PUT_WORD(GET_FOOTER(blk), BLK_INIT(size, 0));//更新当前块的footer
PUT_WORD(GET_HEADER(PREV_BLKP(blk)), BLK_INIT(size, 0));
blk = PREV_BLKP(blk);
}else if(prev_alloc && !next_alloc){
//合并后面的
size += GET_SIZE(GET_HEADER(NEXT_BLKP(blk)));
PUT_WORD(GET_HEADER(blk), BLK_INIT(size, 0));
PUT_WORD(GET_FOOTER(blk), BLK_INIT(size, 0));
}else{
size += GET_SIZE(GET_HEADER(PREV_BLKP(blk)));
size += GET_SIZE(GET_FOOTER(NEXT_BLKP(blk)));
PUT_WORD(GET_HEADER(PREV_BLKP(blk)), BLK_INIT(size, 0));
PUT_WORD(GET_FOOTER(NEXT_BLKP(blk)), BLK_INIT(size, 0));
blk = PREV_BLKP(blk);
}
//发生合并时,需要更新下一次匹配算法使用的指针,防止其指向的块被合并
if((next_match > (char *)blk) && (next_match < NEXT_BLKP(blk))){
//此时next_match指向合并后的块的内部
next_match = blk;
}
return blk;
}
static void *blk_find(size_t size){
//char *blk = blk_heap;
char *blk = next_match;
size_t alloc;
size_t blk_size;
while(GET_SIZE(GET_HEADER(NEXT_BLKP(blk))) > 0){
blk = NEXT_BLKP(blk);
alloc = GET_ALLOC(GET_HEADER(blk));
if(alloc == 1){
continue;
}
blk_size = GET_SIZE(GET_HEADER(blk));
if(blk_size < size){
continue;
}
next_match = blk;
return blk;
}
blk = blk_heap;
while(blk != next_match){
blk = NEXT_BLKP(blk);
alloc = GET_ALLOC(GET_HEADER(blk));
if(alloc == 1){
continue;
}
blk_size = GET_SIZE(GET_HEADER(blk));
if(blk_size < size){
continue;
}
next_match = blk;
return blk;
}
return NULL;
}
static void *blk_split(void *blk, size_t size){
size_t blk_size = GET_SIZE(GET_HEADER(blk));
size_t need_size = size;
size_t leave_size = blk_size - need_size;
if(leave_size >= 2 * DSIZE){
//进行块的切分
PUT_WORD(GET_HEADER(blk), BLK_INIT(need_size, 1));
PUT_WORD(GET_FOOTER(blk), BLK_INIT(need_size, 1));
PUT_WORD(GET_HEADER(NEXT_BLKP(blk)), BLK_INIT(leave_size, 0));
PUT_WORD(GET_FOOTER(NEXT_BLKP(blk)), BLK_INIT(leave_size, 0));
}else{
PUT_WORD(GET_HEADER(blk), BLK_INIT(blk_size, 1));
PUT_WORD(GET_FOOTER(blk), BLK_INIT(blk_size, 1));
}
return blk;
}
显式链表
课本实现
/*
* Simple, 32-bit and 64-bit clean allocator based on implicit free
* lists, first-fit placement, and boundary tag coalescing, as described
* in the CS:APP3e text. Blocks must be aligned to doubleword (8 byte)
* boundaries. Minimum block size is 16 bytes.
*/
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include "mm.h"
#include "memlib.h"
/*
* If NEXT_FIT defined use next fit search, else use first-fit search
*/
#define NEXT_FITx
/* $begin mallocmacros */
/* Basic constants and macros */
#define WSIZE 4 /* Word and header/footer size (bytes) */ //line:vm:mm:beginconst
#define DSIZE 8 /* Double word size (bytes) */
#define CHUNKSIZE (1<<12) /* Extend heap by this amount (bytes) */ //line:vm:mm:endconst
#define MAX(x, y) ((x) > (y)? (x) : (y))
/* Pack a size and allocated bit into a word */
#define PACK(size, alloc) ((size) | (alloc)) //line:vm:mm:pack
/* Read and write a word at address p */
#define GET(p) (*(unsigned int *)(p)) //line:vm:mm:get
#define PUT(p, val) (*(unsigned int *)(p) = (val)) //line:vm:mm:put
/* Read the size and allocated fields from address p */
#define GET_SIZE(p) (GET(p) & ~0x7) //line:vm:mm:getsize
#define GET_ALLOC(p) (GET(p) & 0x1) //line:vm:mm:getalloc
/* Given block ptr bp, compute address of its header and footer */
#define HDRP(bp) ((char *)(bp) - WSIZE) //line:vm:mm:hdrp
#define FTRP(bp) ((char *)(bp) + GET_SIZE(HDRP(bp)) - DSIZE) //line:vm:mm:ftrp
/* Given block ptr bp, compute address of next and previous blocks */
#define NEXT_BLKP(bp) ((char *)(bp) + GET_SIZE(((char *)(bp) - WSIZE))) //line:vm:mm:nextblkp
#define PREV_BLKP(bp) ((char *)(bp) - GET_SIZE(((char *)(bp) - DSIZE))) //line:vm:mm:prevblkp
/* $end mallocmacros */
/* Global variables */
static char *heap_listp = 0; /* Pointer to first block */
#ifdef NEXT_FIT
static char *rover; /* Next fit rover */
#endif
/* Function prototypes for internal helper routines */
static void *extend_heap(size_t words);
static void place(void *bp, size_t asize);
static void *find_fit(size_t asize);
static void *coalesce(void *bp);
static void printblock(void *bp);
static void checkheap(int verbose);
static void checkblock(void *bp);
/*
* mm_init - Initialize the memory manager
*/
/* $begin mminit */
int mm_init(void)
{
/* Create the initial empty heap */
if ((heap_listp = mem_sbrk(4*WSIZE)) == (void *)-1) //line:vm:mm:begininit
return -1;
PUT(heap_listp, 0); /* Alignment padding */
PUT(heap_listp + (1*WSIZE), PACK(DSIZE, 1)); /* Prologue header */
PUT(heap_listp + (2*WSIZE), PACK(DSIZE, 1)); /* Prologue footer */
PUT(heap_listp + (3*WSIZE), PACK(0, 1)); /* Epilogue header */
heap_listp += (2*WSIZE); //line:vm:mm:endinit
/* $end mminit */
#ifdef NEXT_FIT
rover = heap_listp;
#endif
/* $begin mminit */
/* Extend the empty heap with a free block of CHUNKSIZE bytes */
if (extend_heap(CHUNKSIZE/WSIZE) == NULL)
return -1;
return 0;
}
/* $end mminit */
/*
* mm_malloc - Allocate a block with at least size bytes of payload
*/
/* $begin mmmalloc */
void *mm_malloc(size_t size)
{
size_t asize; /* Adjusted block size */
size_t extendsize; /* Amount to extend heap if no fit */
char *bp;
/* $end mmmalloc */
if (heap_listp == 0){
mm_init();
}
/* $begin mmmalloc */
/* Ignore spurious requests */
if (size == 0)
return NULL;
/* Adjust block size to include overhead and alignment reqs. */
if (size <= DSIZE) //line:vm:mm:sizeadjust1
asize = 2*DSIZE; //line:vm:mm:sizeadjust2
else
asize = DSIZE * ((size + (DSIZE) + (DSIZE-1)) / DSIZE); //line:vm:mm:sizeadjust3
/* Search the free list for a fit */
if ((bp = find_fit(asize)) != NULL) { //line:vm:mm:findfitcall
place(bp, asize); //line:vm:mm:findfitplace
return bp;
}
/* No fit found. Get more memory and place the block */
extendsize = MAX(asize,CHUNKSIZE); //line:vm:mm:growheap1
if ((bp = extend_heap(extendsize/WSIZE)) == NULL)
return NULL; //line:vm:mm:growheap2
place(bp, asize); //line:vm:mm:growheap3
return bp;
}
/* $end mmmalloc */
/*
* mm_free - Free a block
*/
/* $begin mmfree */
void mm_free(void *bp)
{
/* $end mmfree */
if (bp == 0)
return;
/* $begin mmfree */
size_t size = GET_SIZE(HDRP(bp));
/* $end mmfree */
if (heap_listp == 0){
mm_init();
}
/* $begin mmfree */
PUT(HDRP(bp), PACK(size, 0));
PUT(FTRP(bp), PACK(size, 0));
coalesce(bp);
}
/* $end mmfree */
/*
* coalesce - Boundary tag coalescing. Return ptr to coalesced block
*/
/* $begin mmfree */
static void *coalesce(void *bp)
{
size_t prev_alloc = GET_ALLOC(FTRP(PREV_BLKP(bp)));
size_t next_alloc = GET_ALLOC(HDRP(NEXT_BLKP(bp)));
size_t size = GET_SIZE(HDRP(bp));
if (prev_alloc && next_alloc) { /* Case 1 */
return bp;
}
else if (prev_alloc && !next_alloc) { /* Case 2 */
size += GET_SIZE(HDRP(NEXT_BLKP(bp)));
PUT(HDRP(bp), PACK(size, 0));
PUT(FTRP(bp), PACK(size,0));
}
else if (!prev_alloc && next_alloc) { /* Case 3 */
size += GET_SIZE(HDRP(PREV_BLKP(bp)));
PUT(FTRP(bp), PACK(size, 0));
PUT(HDRP(PREV_BLKP(bp)), PACK(size, 0));
bp = PREV_BLKP(bp);
}
else { /* Case 4 */
size += GET_SIZE(HDRP(PREV_BLKP(bp))) +
GET_SIZE(FTRP(NEXT_BLKP(bp)));
PUT(HDRP(PREV_BLKP(bp)), PACK(size, 0));
PUT(FTRP(NEXT_BLKP(bp)), PACK(size, 0));
bp = PREV_BLKP(bp);
}
/* $end mmfree */
#ifdef NEXT_FIT
/* Make sure the rover isn't pointing into the free block */
/* that we just coalesced */
if ((rover > (char *)bp) && (rover < NEXT_BLKP(bp)))
rover = bp;
#endif
/* $begin mmfree */
return bp;
}
/* $end mmfree */
/*
* mm_realloc - Naive implementation of realloc
*/
void *mm_realloc(void *ptr, size_t size)
{
size_t oldsize;
void *newptr;
/* If size == 0 then this is just free, and we return NULL. */
if(size == 0) {
mm_free(ptr);
return 0;
}
/* If oldptr is NULL, then this is just malloc. */
if(ptr == NULL) {
return mm_malloc(size);
}
newptr = mm_malloc(size);
/* If realloc() fails the original block is left untouched */
if(!newptr) {
return 0;
}
/* Copy the old data. */
oldsize = GET_SIZE(HDRP(ptr));
if(size < oldsize) oldsize = size;
memcpy(newptr, ptr, oldsize);
/* Free the old block. */
mm_free(ptr);
return newptr;
}
/*
* mm_checkheap - Check the heap for correctness
*/
void mm_checkheap(int verbose)
{
checkheap(verbose);
}
/*
* The remaining routines are internal helper routines
*/
/*
* extend_heap - Extend heap with free block and return its block pointer
*/
/* $begin mmextendheap */
static void *extend_heap(size_t words)
{
char *bp;
size_t size;
/* Allocate an even number of words to maintain alignment */
size = (words % 2) ? (words+1) * WSIZE : words * WSIZE; //line:vm:mm:beginextend
if ((long)(bp = mem_sbrk(size)) == -1)
return NULL; //line:vm:mm:endextend
/* Initialize free block header/footer and the epilogue header */
PUT(HDRP(bp), PACK(size, 0)); /* Free block header */ //line:vm:mm:freeblockhdr
PUT(FTRP(bp), PACK(size, 0)); /* Free block footer */ //line:vm:mm:freeblockftr
PUT(HDRP(NEXT_BLKP(bp)), PACK(0, 1)); /* New epilogue header */ //line:vm:mm:newepihdr
/* Coalesce if the previous block was free */
return coalesce(bp); //line:vm:mm:returnblock
}
/* $end mmextendheap */
/*
* place - Place block of asize bytes at start of free block bp
* and split if remainder would be at least minimum block size
*/
/* $begin mmplace */
/* $begin mmplace-proto */
static void place(void *bp, size_t asize)
/* $end mmplace-proto */
{
size_t csize = GET_SIZE(HDRP(bp));
if ((csize - asize) >= (2*DSIZE)) {
PUT(HDRP(bp), PACK(asize, 1));
PUT(FTRP(bp), PACK(asize, 1));
bp = NEXT_BLKP(bp);
PUT(HDRP(bp), PACK(csize-asize, 0));
PUT(FTRP(bp), PACK(csize-asize, 0));
}
else {
PUT(HDRP(bp), PACK(csize, 1));
PUT(FTRP(bp), PACK(csize, 1));
}
}
/* $end mmplace */
/*
* find_fit - Find a fit for a block with asize bytes
*/
/* $begin mmfirstfit */
/* $begin mmfirstfit-proto */
static void *find_fit(size_t asize)
/* $end mmfirstfit-proto */
{
/* $end mmfirstfit */
#ifdef NEXT_FIT
/* Next fit search */
char *oldrover = rover;
/* Search from the rover to the end of list */
for ( ; GET_SIZE(HDRP(rover)) > 0; rover = NEXT_BLKP(rover))
if (!GET_ALLOC(HDRP(rover)) && (asize <= GET_SIZE(HDRP(rover))))
return rover;
/* search from start of list to old rover */
for (rover = heap_listp; rover < oldrover; rover = NEXT_BLKP(rover))
if (!GET_ALLOC(HDRP(rover)) && (asize <= GET_SIZE(HDRP(rover))))
return rover;
return NULL; /* no fit found */
#else
/* $begin mmfirstfit */
/* First-fit search */
void *bp;
for (bp = heap_listp; GET_SIZE(HDRP(bp)) > 0; bp = NEXT_BLKP(bp)) {
if (!GET_ALLOC(HDRP(bp)) && (asize <= GET_SIZE(HDRP(bp)))) {
return bp;
}
}
return NULL; /* No fit */
#endif
}
/* $end mmfirstfit */
static void printblock(void *bp)
{
size_t hsize, halloc, fsize, falloc;
checkheap(0);
hsize = GET_SIZE(HDRP(bp));
halloc = GET_ALLOC(HDRP(bp));
fsize = GET_SIZE(FTRP(bp));
falloc = GET_ALLOC(FTRP(bp));
if (hsize == 0) {
printf("%p: EOL\n", bp);
return;
}
printf("%p: header: [%ld:%c] footer: [%ld:%c]\n", bp,
hsize, (halloc ? 'a' : 'f'),
fsize, (falloc ? 'a' : 'f'));
}
static void checkblock(void *bp)
{
if ((size_t)bp % 8)
printf("Error: %p is not doubleword aligned\n", bp);
if (GET(HDRP(bp)) != GET(FTRP(bp)))
printf("Error: header does not match footer\n");
}
/*
* checkheap - Minimal check of the heap for consistency
*/
void checkheap(int verbose)
{
char *bp = heap_listp;
if (verbose)
printf("Heap (%p):\n", heap_listp);
if ((GET_SIZE(HDRP(heap_listp)) != DSIZE) || !GET_ALLOC(HDRP(heap_listp)))
printf("Bad prologue header\n");
checkblock(heap_listp);
for (bp = heap_listp; GET_SIZE(HDRP(bp)) > 0; bp = NEXT_BLKP(bp)) {
if (verbose)
printblock(bp);
checkblock(bp);
}
if (verbose)
printblock(bp);
if ((GET_SIZE(HDRP(bp)) != 0) || !(GET_ALLOC(HDRP(bp))))
printf("Bad epilogue header\n");
}

![[kubernetes]-k8s开启swap](https://img-blog.csdnimg.cn/img_convert/e634d34352d4478c40099a943a1d535d.png)






![[附源码]Python计算机毕业设计电影院订票系统](https://img-blog.csdnimg.cn/9edf7d8267d945eaa63501a696ea3e4e.png)