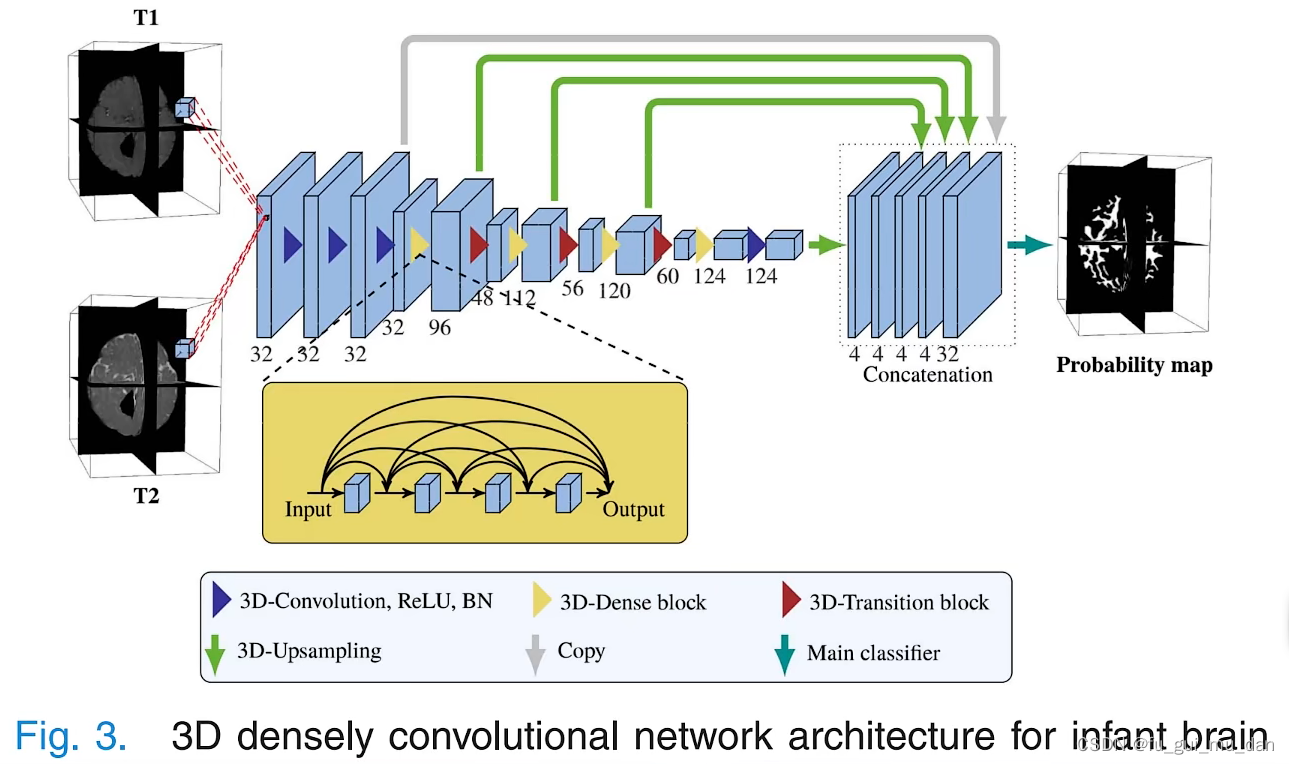
蓝色三角、黄色三角、红色三角相对应。
得到第三个feature map,反卷积会恢复到原来的尺寸
Dense block,通道增加了
Transition,池化
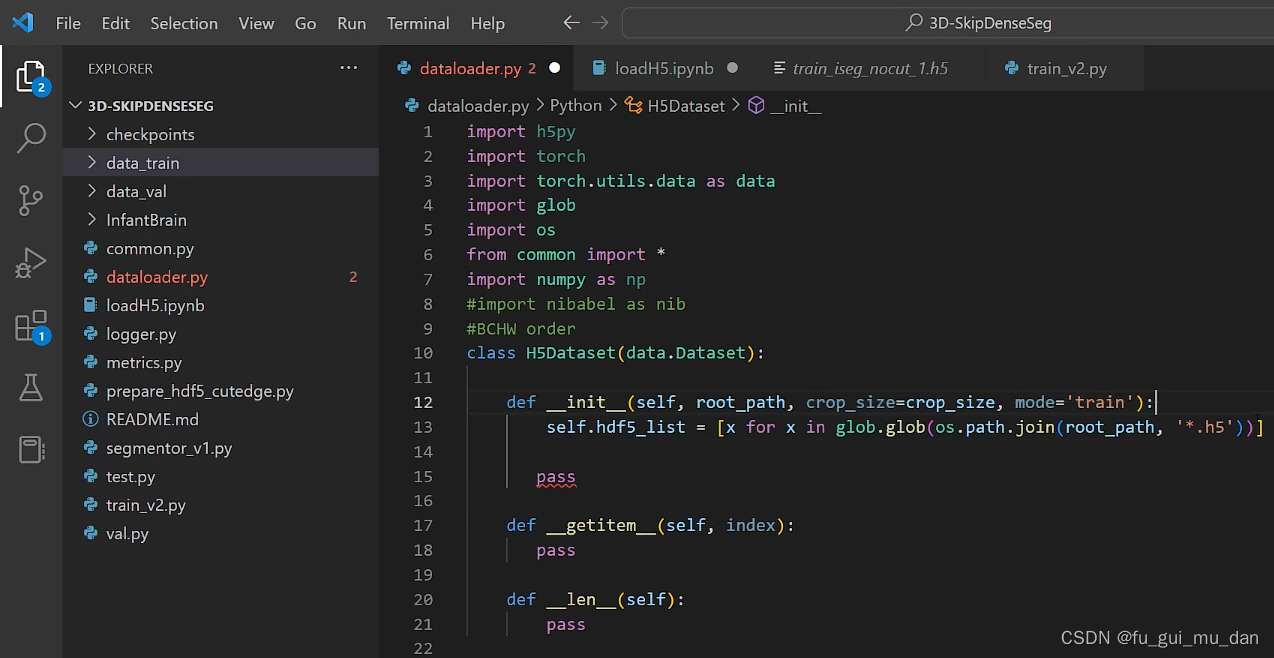
用正则表达式把里面的h5文件匹配一下吧
os.path.join()把两个部分的路径拼一下
root_path —data_train
*.h5,不管名字是什么,只要后缀是h5,就把它匹配一下
glob,遍历所有.h5文件
得到data_train里面的八个subject
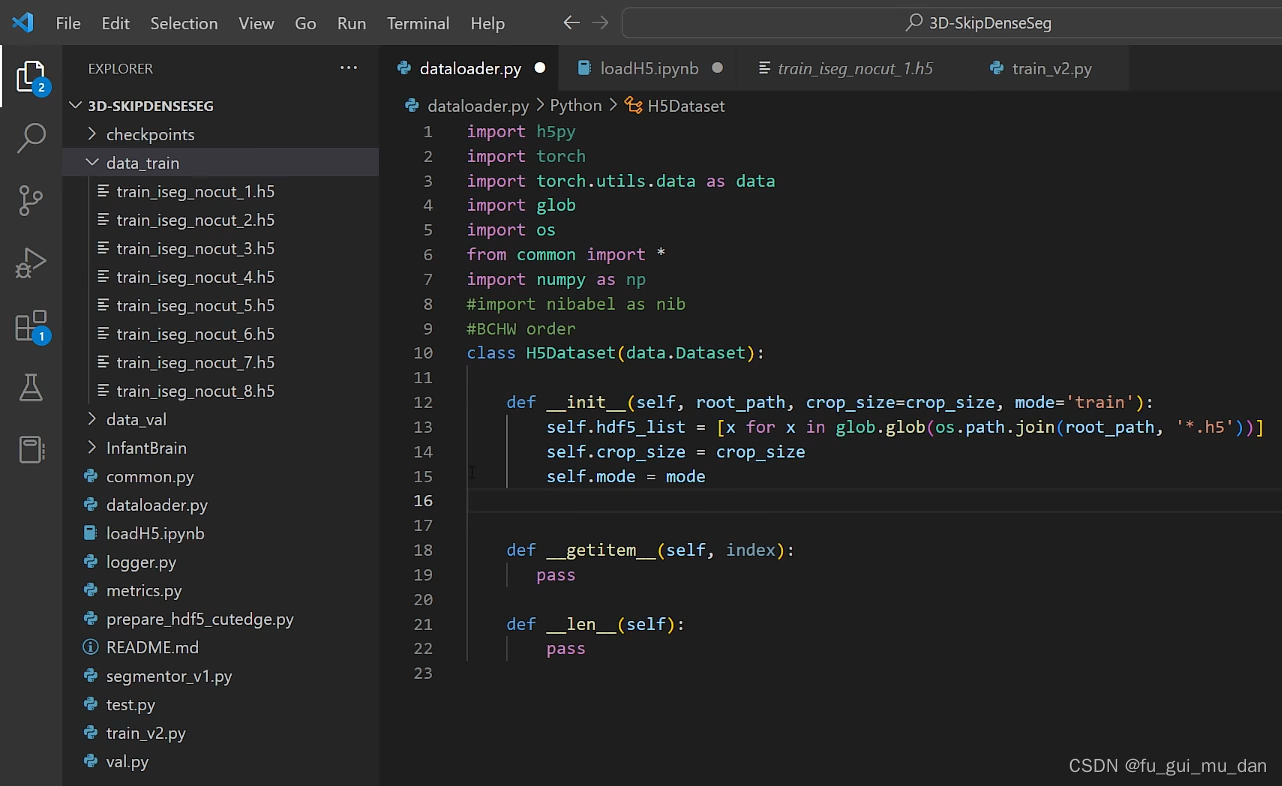
mode,数据集处理的是训练集or测试集or验证集,用一个标志位键区别一下。传进来的是train,就知道对training dataset进行一个处理
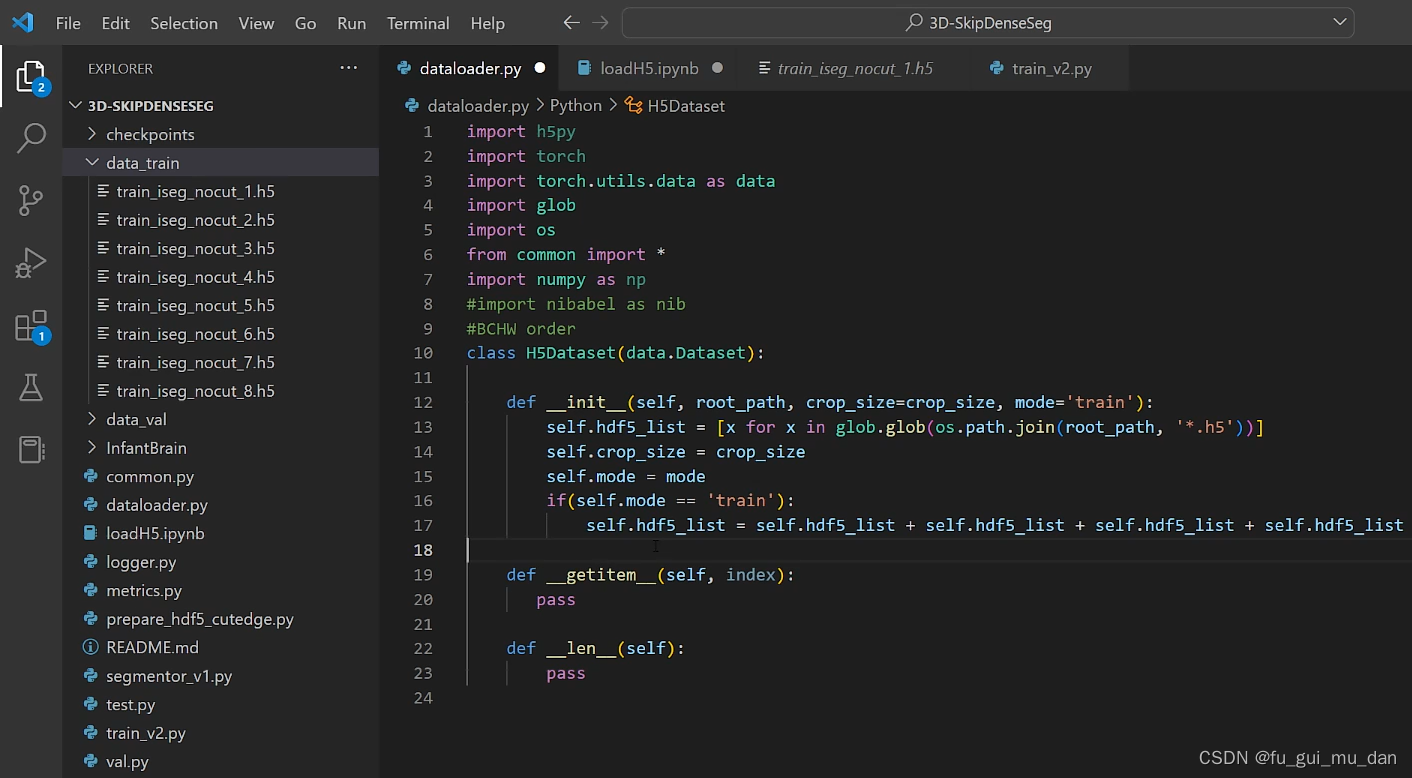
数据扩充,尽量保持原始数据
前提是训练数据,验证集不能扩充,验证集扩充,准确率就没有意义了
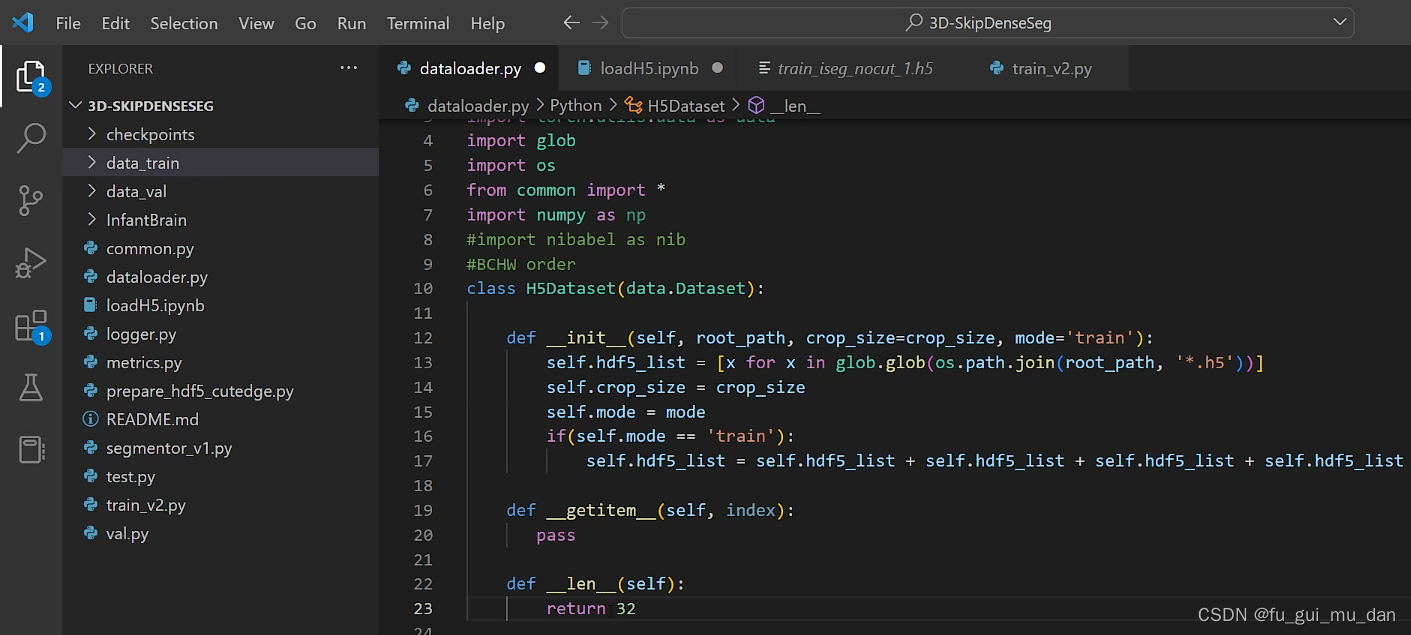
有可能传进来的,是对测试集和验证集处理
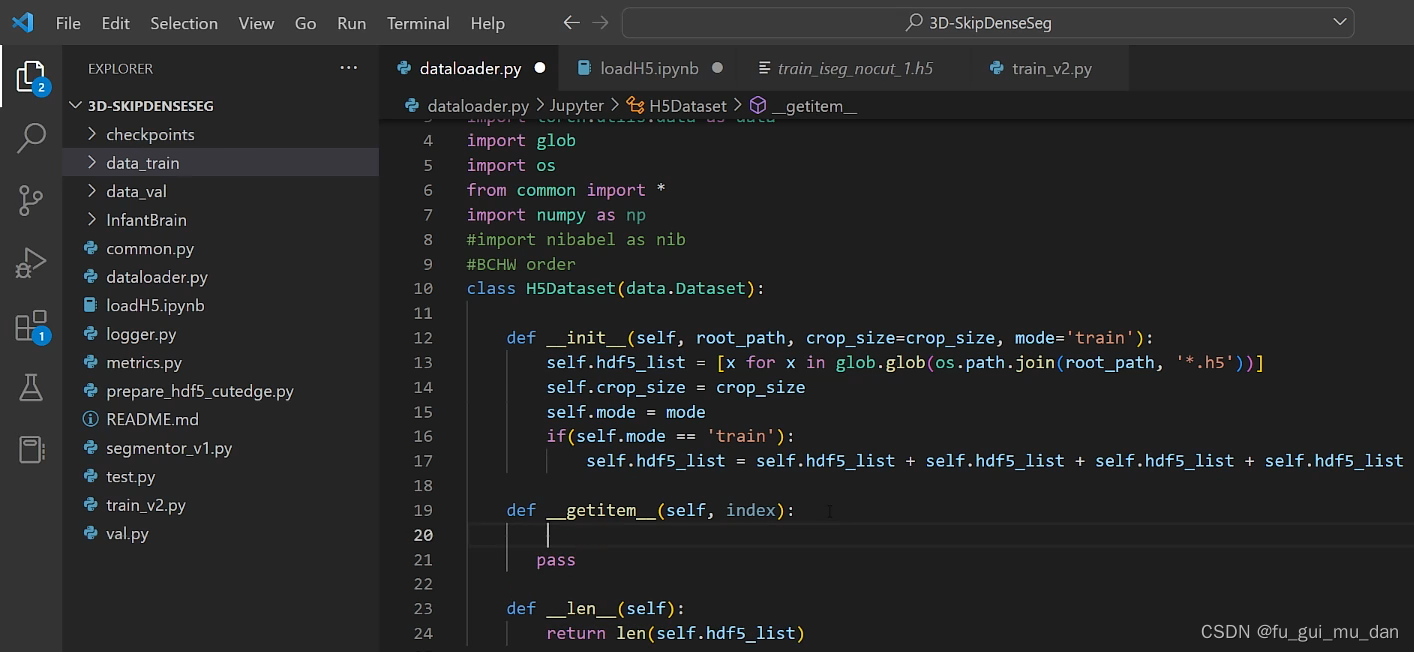
知道长度了,给我一个索引,返回一个训练样本
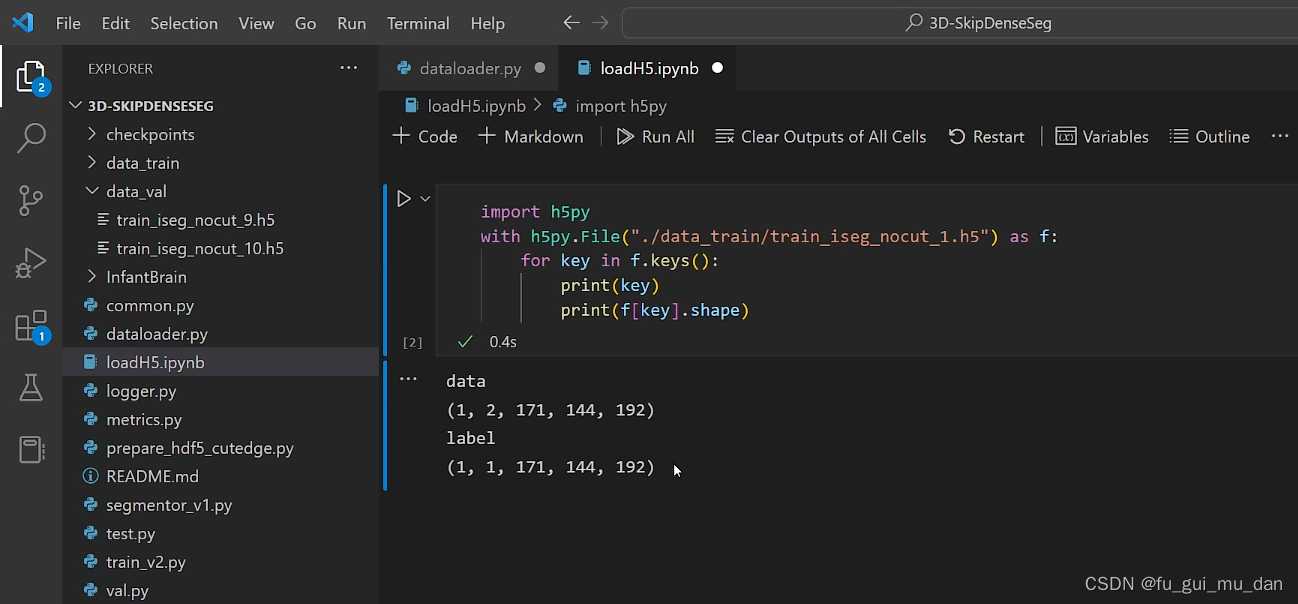
要转成64 * 64 * 64固定大小的patch
得到这样的数据
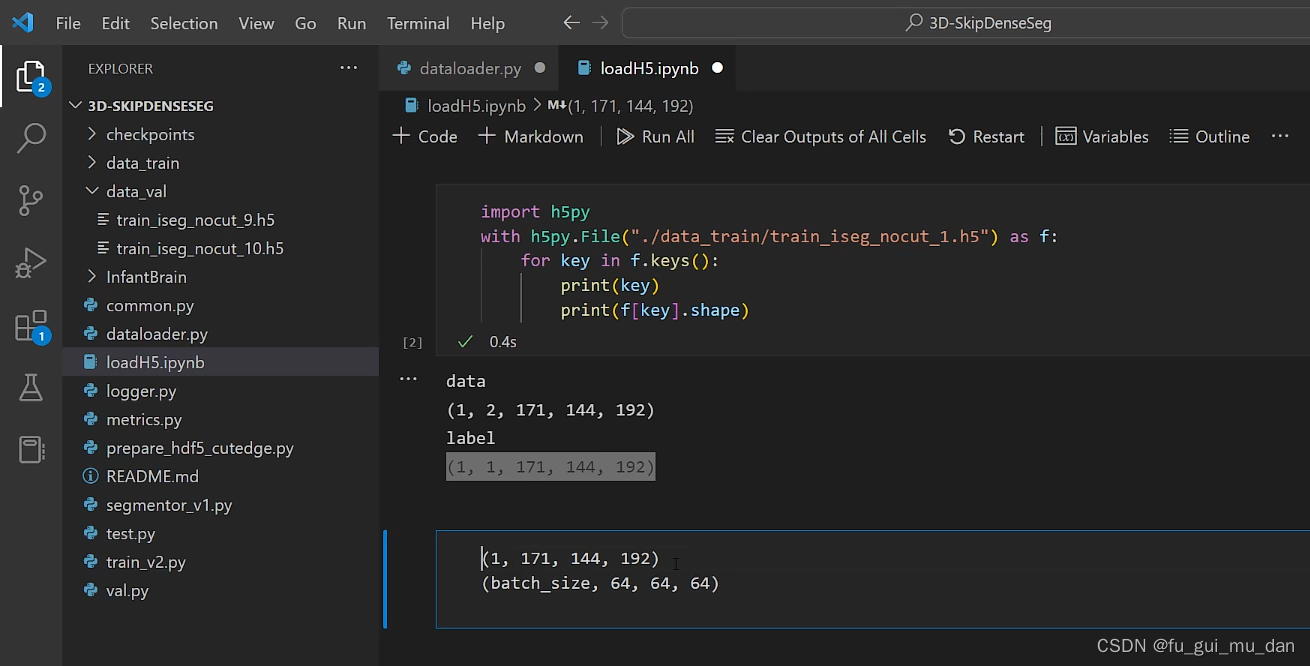
需要64 64 64,还需要什么,还需要一个batch_size,batch_size个patch,去掉一个维度
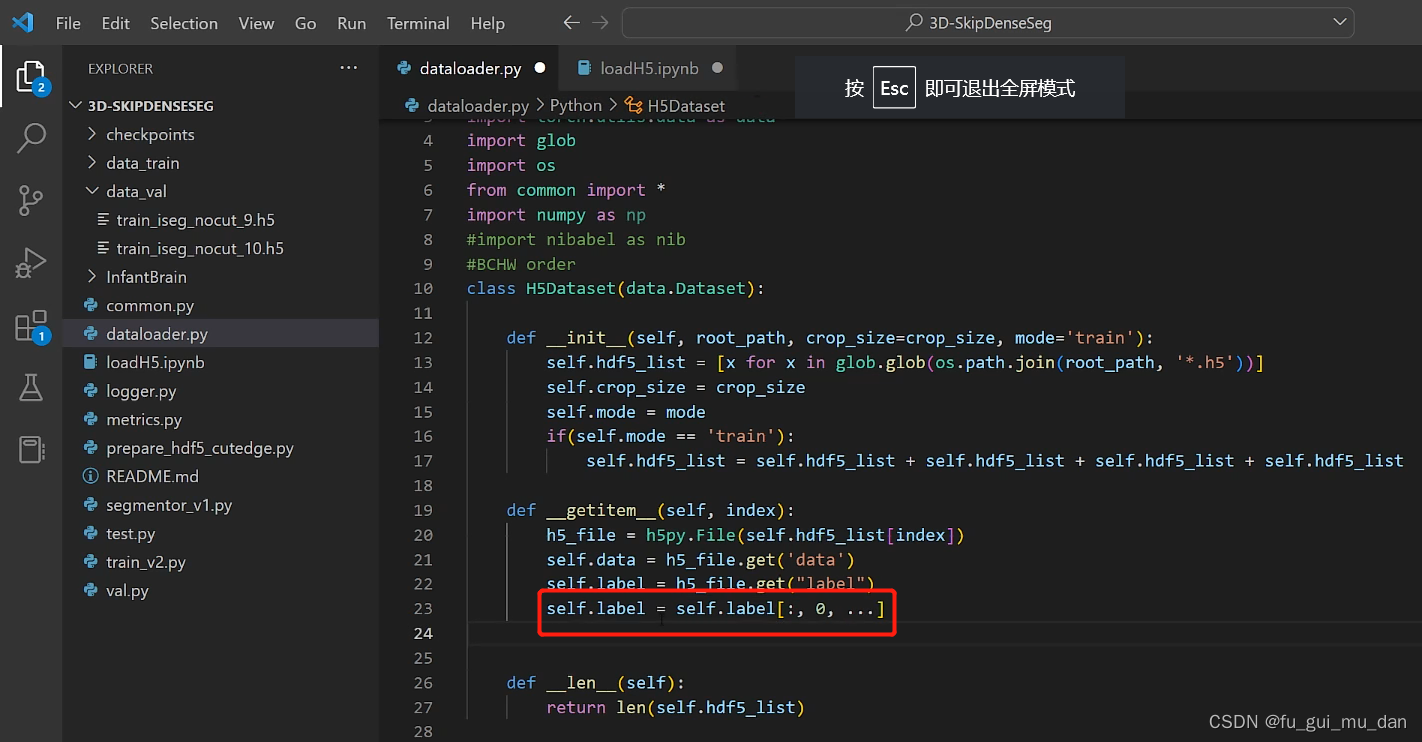
去掉第二个维度,其余不变
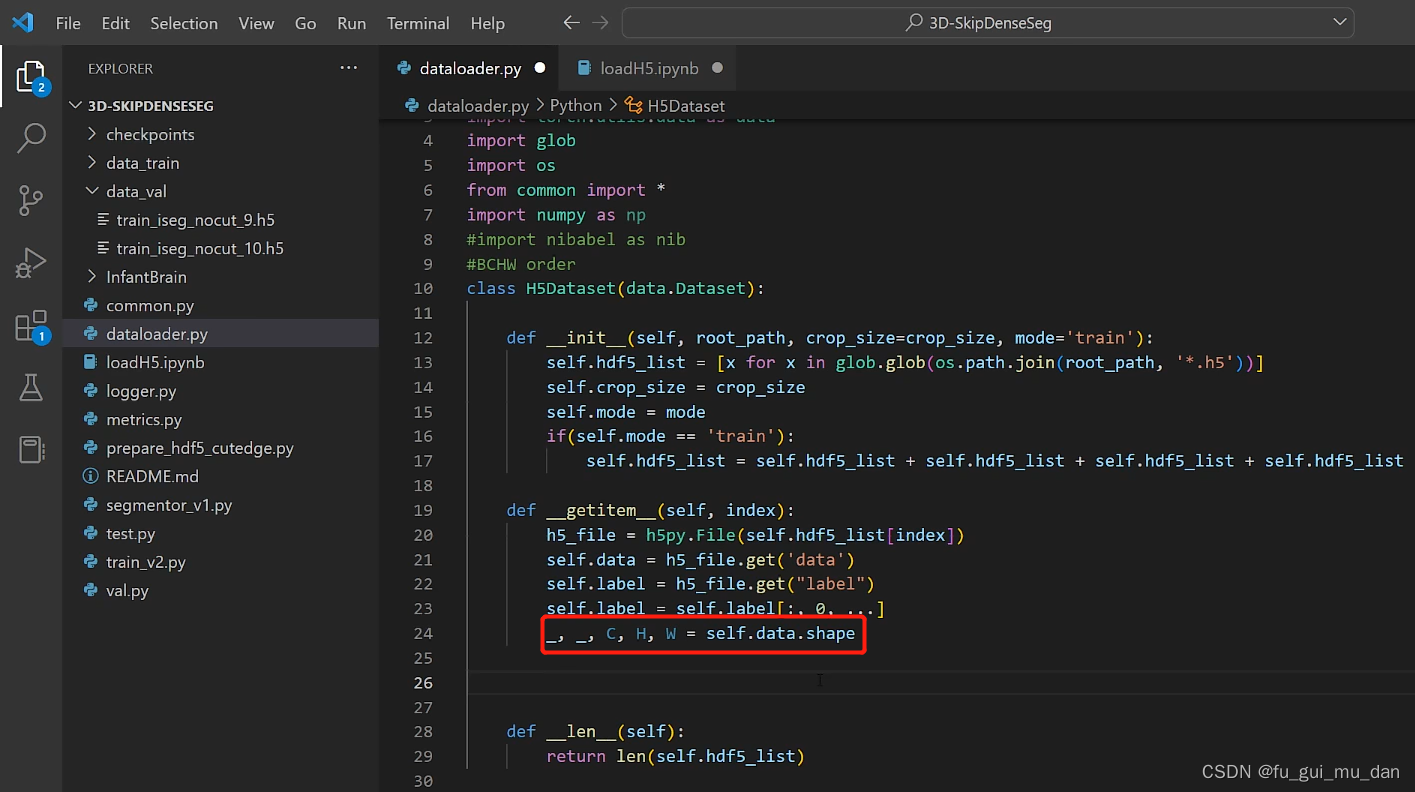
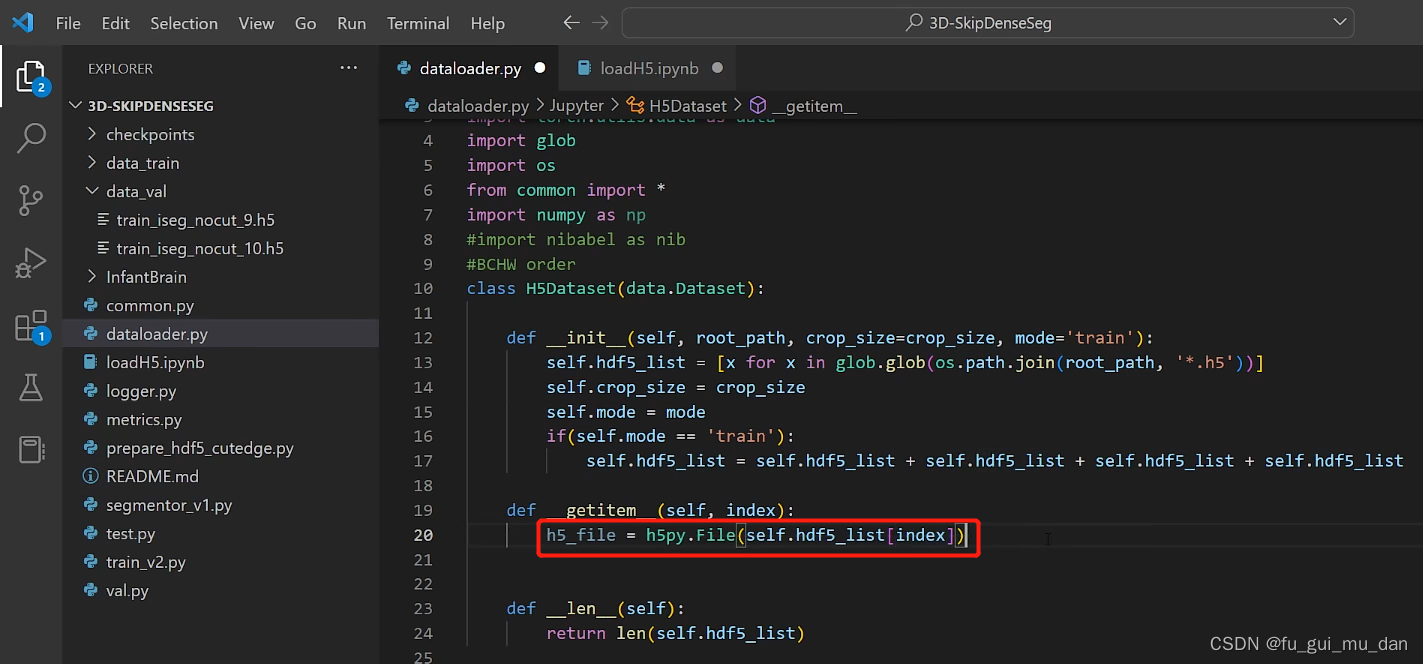
为什么记录长宽高,我们要从不固定大小的脑图像中裁patch
裁的开始位置是有讲究的
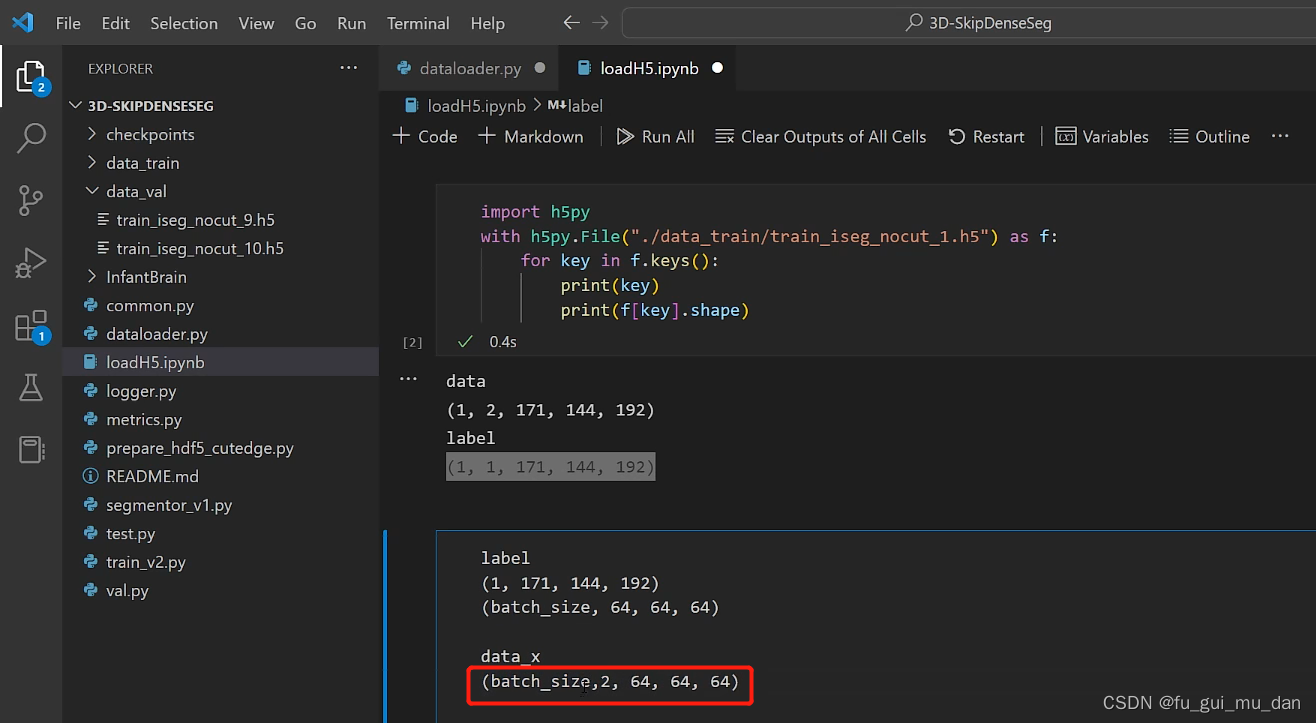
T1和T2两个特征,data_x不需要去维度了
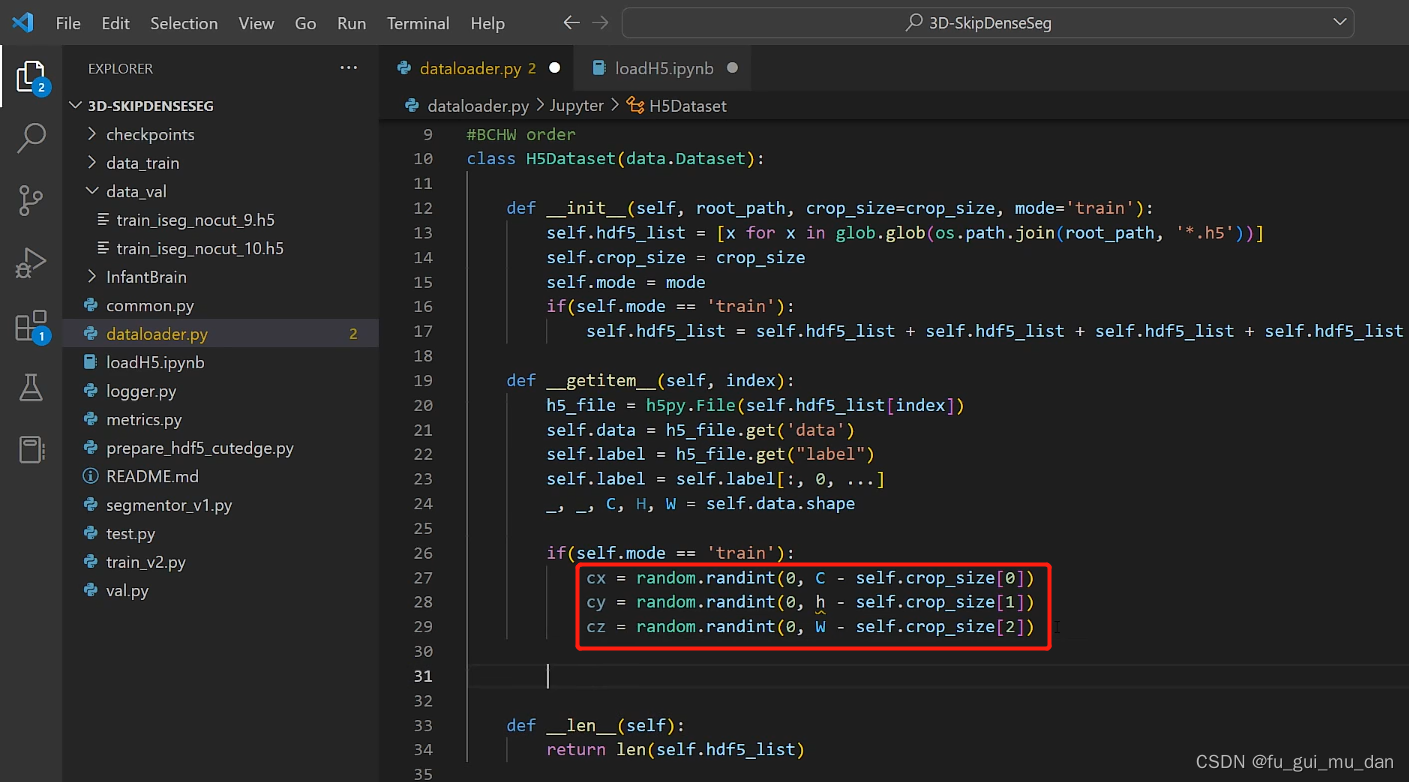
cx是C的起始位置,cy是H的起始位置,cz是W的起始位置。0,1,2维度
为什么要随机裁,不从0开始
每一轮迭代的过程中,都希望从样本中取一个数据,每次从样本里取一个patch,如果每次从0开始取的话,就不能遍历脑图像的所有区域了。所以通过随机值的方式随机地取一个patch,如果训练轮数足够多的话,理论上是可以把闹图像的所有区域遍历到。
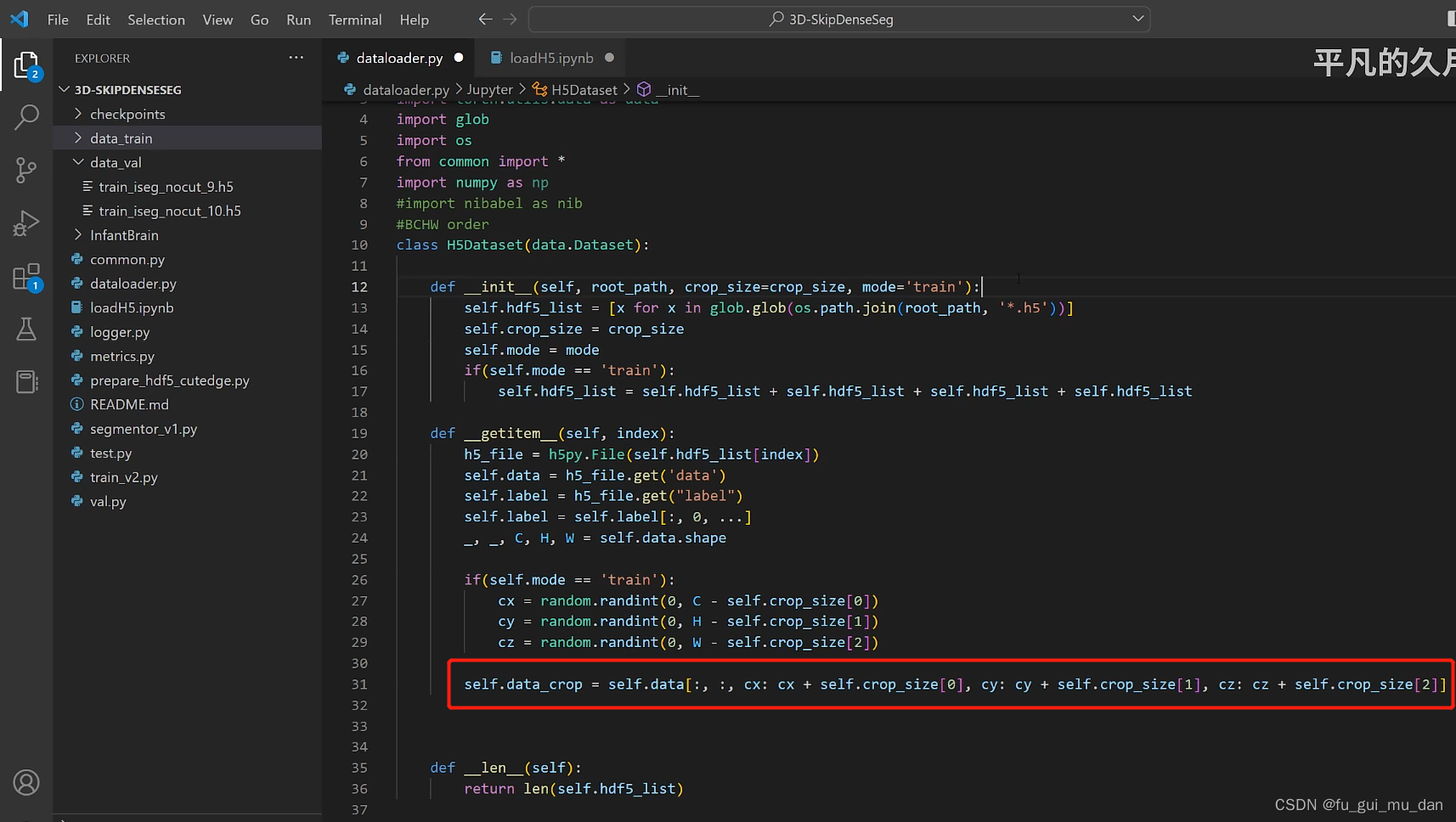
裁的开始位置是cx,结束位置,这个维度的
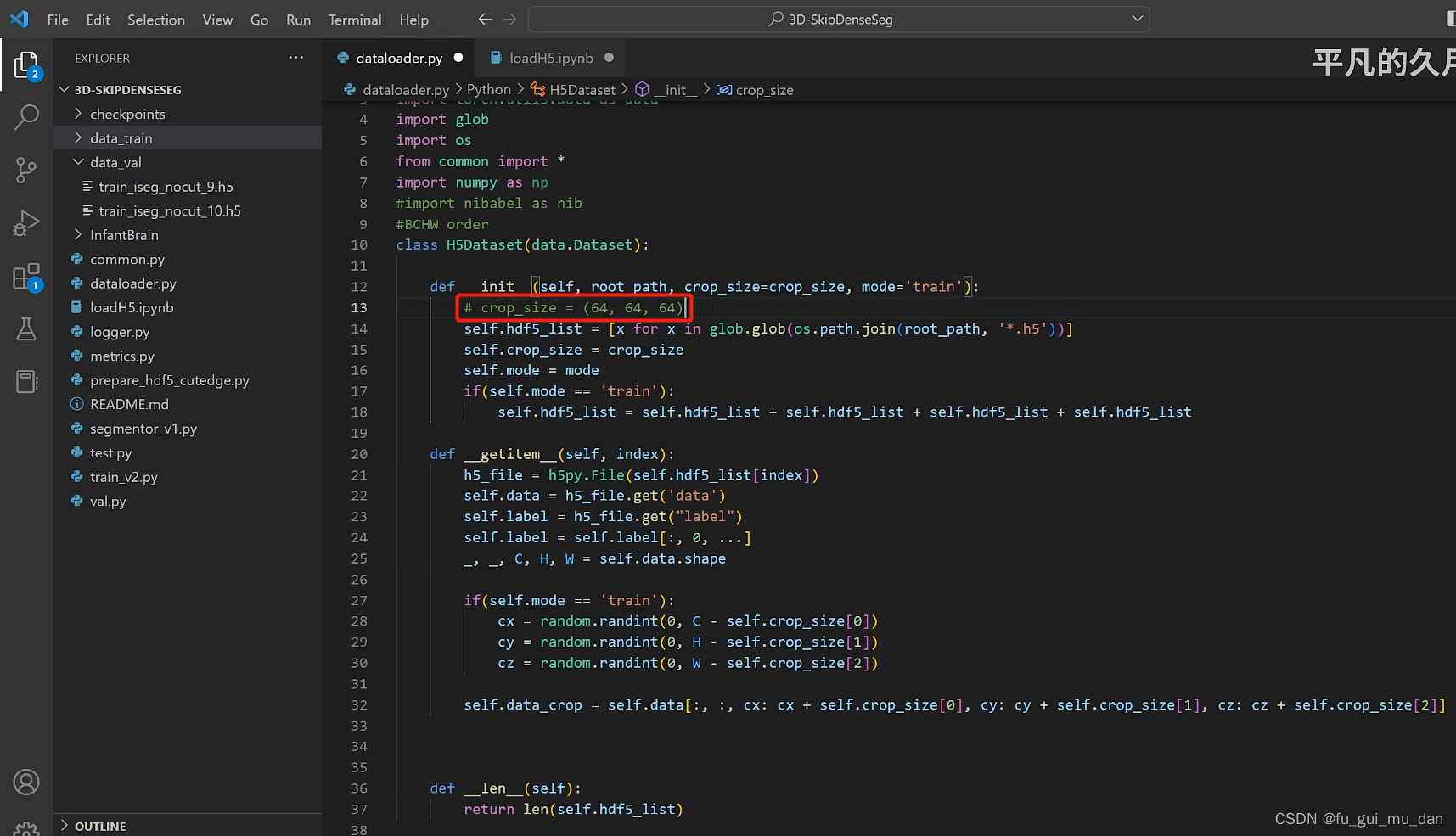
不直接传一个数字,往往我们需要64 48 32,所以体现这样写的用意了
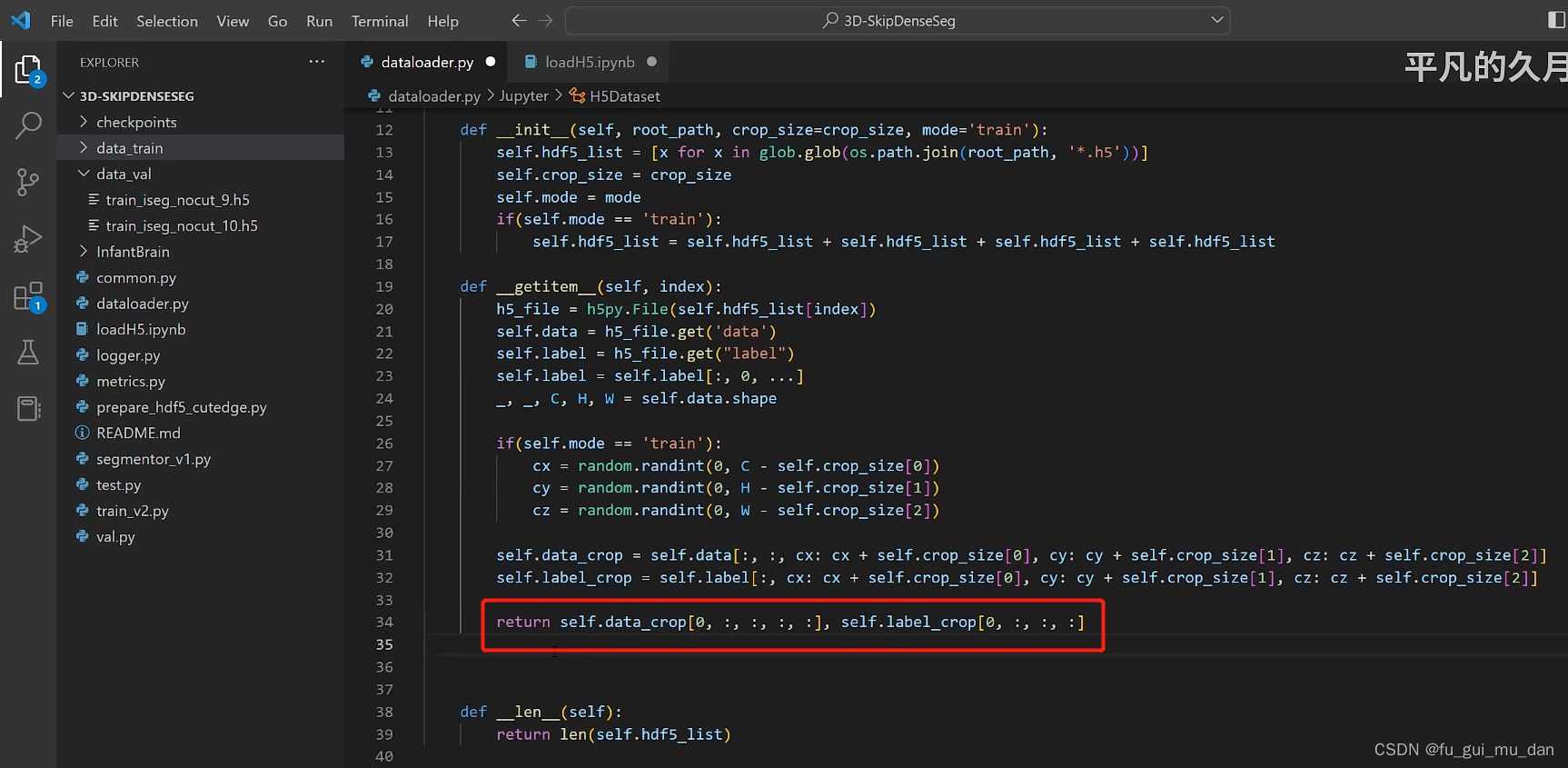
为什么是0,限制返回的结果是一个,一条索引返回一个数据
batch_size的维度一定要相同,

验证集取中心位置,每一个iteration都是这个位置,验证集才有价值。如果每轮patch都在变的话,验证就失去价值了
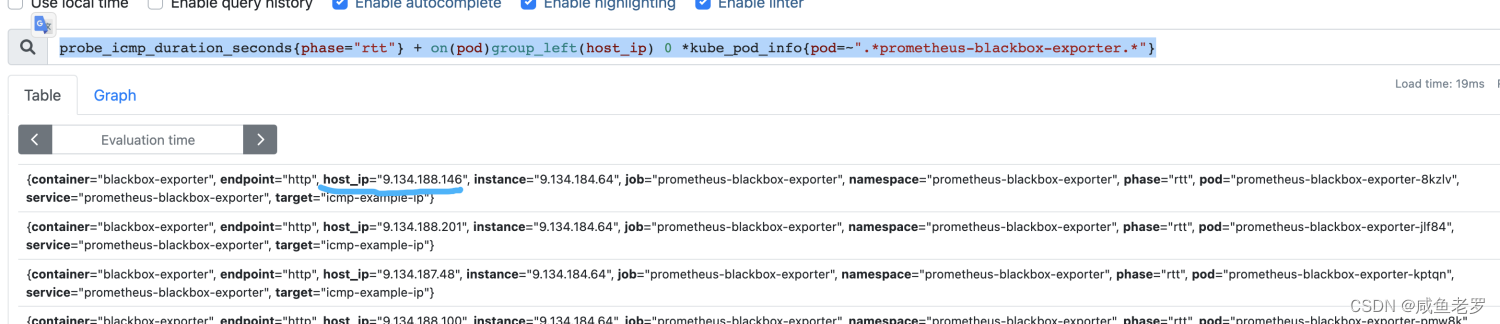
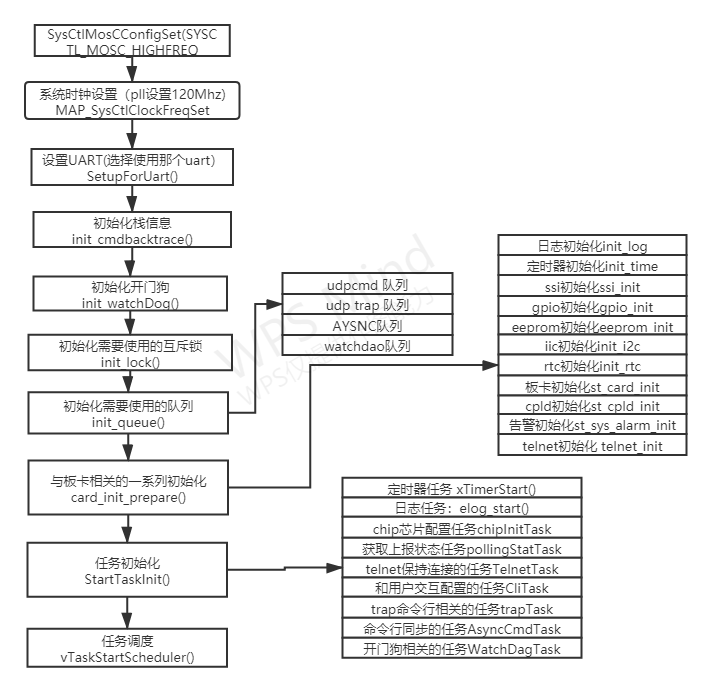
一分零七
![[kubernetes]-k8s开启swap](https://img-blog.csdnimg.cn/img_convert/e634d34352d4478c40099a943a1d535d.png)






![[附源码]Python计算机毕业设计电影院订票系统](https://img-blog.csdnimg.cn/9edf7d8267d945eaa63501a696ea3e4e.png)