前言:
我目前主要学习方向是c++,看到网上基本上都是用python写的爬虫,我也试过,确实非常方便,几行代码就能解决,但却就是因为python封装的太好,过于简单,使得很多人包括我最开始的时候,都很难理解爬虫原理.所以就想着能不能用c++实现一个简单的爬虫.
最后我成功实现C++版爬虫从某图片网站爬取了将近两万多张图片,便记录一下,供大家学习
有兴趣的同学可直接下载源码对比学习,下载源码点这里
5月17日更新:
也可进入我的公众号,查看升级优化版爬虫代码文章,以及完整的代码,还有持续更新的资源!
文章目录
-
- 前言:
- 一、先手动爬虫,理解爬虫原理
- 二、尝试手动爬取图片
- 四、寻找网页的规律
- 四、从手动爬虫中总结一下爬虫的过程
- 五、写代码前的知识储备
- 六、开始写代码
- 总结
一、先手动爬虫,理解爬虫原理
首先我们得清楚网页的原理,如一页展示图片的网页,右键可查看网页源代码
(考虑到该程序的特殊性,避免不必要的麻烦,不方便展示该网站名称,大家可自行找图片网站替代,尽量与本文的网站格式相近)
(当然也可以下载我的源代码,里面有详细的注释,VS2019环境下亲测可用)

网页源代码如图:

为方便演示爬虫原理,可在源代码页Ctrl+A 全选 ,再Ctrl+C复制,然后在桌面新建一个txt文本,Ctrl+V复制结果如图:

然后保存退出,修改文件后缀名为.html
修改前:

修改后:

然后直接点击该文件,可以发现显示出与先前网站一样内容的网页,只是显示样式发生了变化.

至此,我们就完成了一次手动爬取一张网页
而此次我们想爬取的不是网页,而是网页上展示的图片,所以这还不够
二、尝试手动爬取图片
正如上所诉,图片是在网页上展示的,所以我们就要尝试在网页上找到图片的地址
在网页源代码中,可以很容易找到以<img src="…"形式展示的标签
如图:

当尝试点击img 后紧跟的链接时,发现展示出一张图片,就是先前网页上看到的某张图片


然后右键该图片,另存任意位置
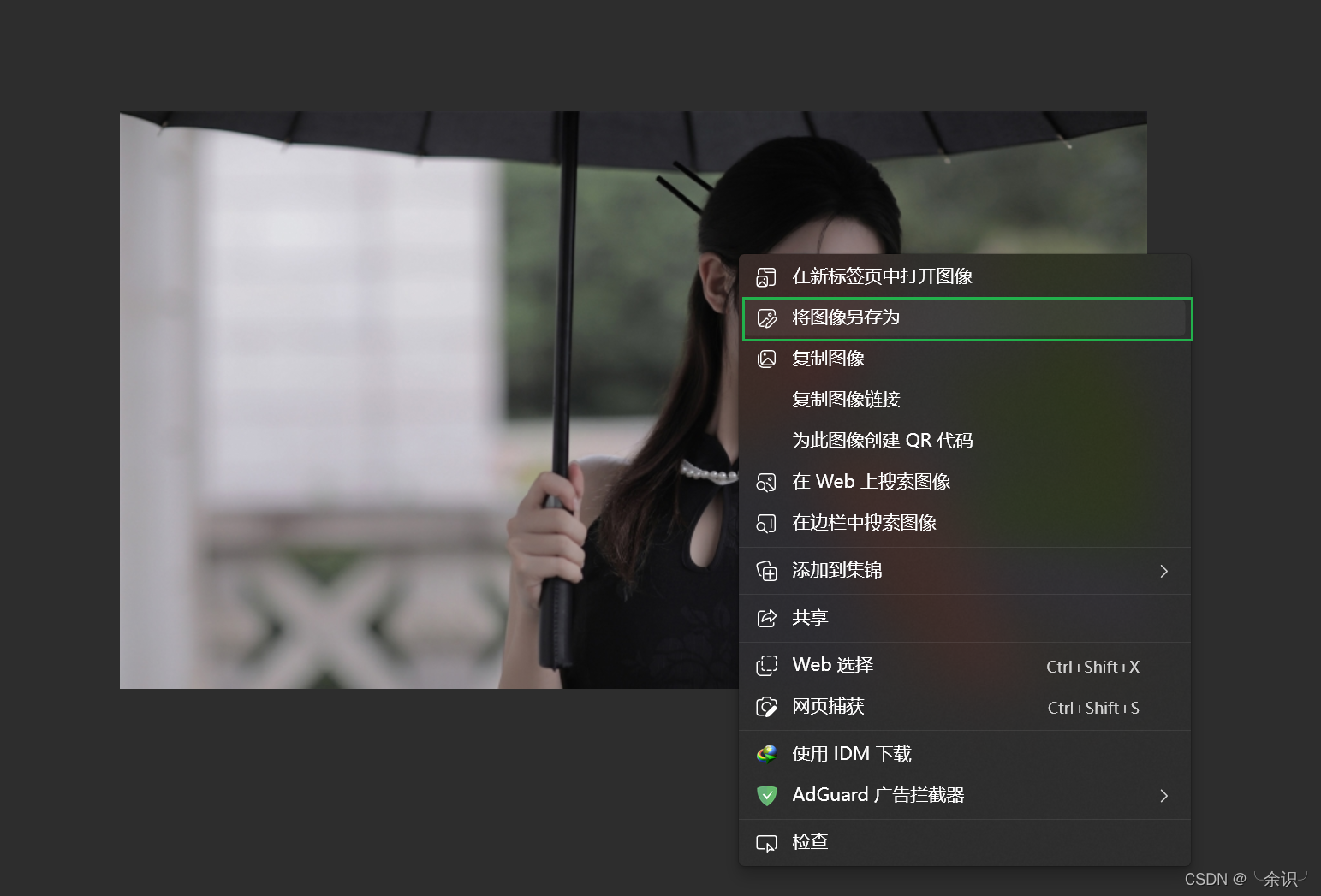
至此,我们就完成了一次手动爬取图片的过程
四、寻找网页的规律
完成了手动爬取一个网页和一张图片后,我们可以发现,即使是使用了程序代替手工,每次爬取的图片都是有限的,因为大量图片都存放在大量不同的网页中,所以我们还需要找到各个网页之间的规律
于是我点开下一页图片,可以看到地址栏发生了变化
第一页:
第二页
第三页:
可以发现,除了第一页的地址后缀为index,之后的其它网页都是index_x.html结尾,x为它的页数
至此,我们就发现了该网站网页的规律:除了第一页,其它网页都是以站名/index_X.html的格式存在,X为网页的页数
四、从手动爬虫中总结一下爬虫的过程
1.将要爬取的网页源代码下载到本地
2.从网页源代码中解析出图片的地址,然后下载到本地.
3.若不再使用网页源代码,可删除,避免占用大量磁盘空间.然后回到第一步循环,直到爬取完成
五、写代码前的知识储备
1.针对下载网页源代码和下载图片的需求,可使用微软提供的一个下载函数可以很方便实现下载功能:
头文件:
#include<Windows.h> //头文件
#pragma comment(lib,"Urlmon.lib") //链接包含该函数的静态库
函数:
HRESULT URLDownloadToFileA(
LPUNKNOWN pCaller, //用于显示下载进度,但需要继承COM接口,过于麻烦,可直接填0
LPCTSTR zURL,//填写要下载的地址
LPCTSTR szFileName,//填写下载完成到本地,保存的文件名
DWORD dwReserved,//保留参数,必须为0
LPBINDSTATUSCALLBACK lpfnCB //接受下载进度的回调函数,不需要,直接填0
);
返回值为S_OK则成功,否则下载失败
该函数功能:将zURL参数地址下载保存为本地szFileName参数文件
关于该函数的更多详细内容,请点击这里!
2.针对要从网页源代码中解析出图片地址,可以使用C++自带的正则表达式库
#include<regex>
还不会正则表达式戳这里马上学习
这里主要用到的是该库的regex_search函数
bool regex_search(
_BidIt _First, //进行匹配的起始迭代器,就是从哪里开始匹配
_BidIt _Last, //进行匹配的结束迭代器,就是从哪里结束匹配
match_results<_BidIt, _Alloc>& _Matches,//匹配到的结果返回给这个参数
const basic_regex<_Elem, _RxTraits>& _Re,//填写匹配规则的参数,也就是正则表达式
regex_constants::match_flag_type _Flgs=regex_constants::match_default //匹配模式,用默认的就行,不用填
)
该函数将在_First参数到_Last参数指定的范围匹配符合_Re模式的字符串,将结果存储到_Matches参数中
使用方法是将_Re正则表达式中,匹配到的两个小括号内的内容(.*)送回到_Matches参数,通过_Matches[index].str()获取想要的内容,index为第几个小括号匹配的内容
再通过_Matches[0].second得到当前已经匹配到的位置,方便继续循环匹配
不好理解继续往下看,实践是最好的学习方法!
六、开始写代码
首先,在任意一个盘新建一个空文件夹,方便后面使用
我在D盘下新建了一个叫ps的空文件夹
然后在VS中新建一个控制台项目,我这里项目名称为test,并新建一个叫main.cpp的空文件
添加头文件和库
#include<Windows.h>
#include<regex>
#include<iostream>
#pragma comment(lib,"Urlmon.lib")
using namespace std;
int main() {
}
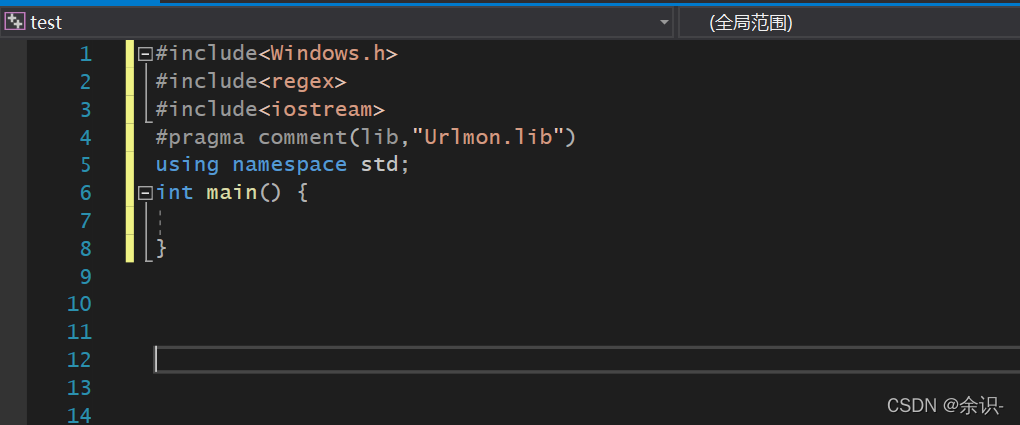
写个循环,生成所有网页的地址,因为是从第二页开始有规律的,所以这里直接从2开始循环(网站不方便展示,可下载我的源代码)
string url;
url.resize(1024);
for (int i = 2; i <= 1212; i++) {
sprintf_s((char*)url.c_str(), 1024, "http://....../index_%d.htm", i);
}
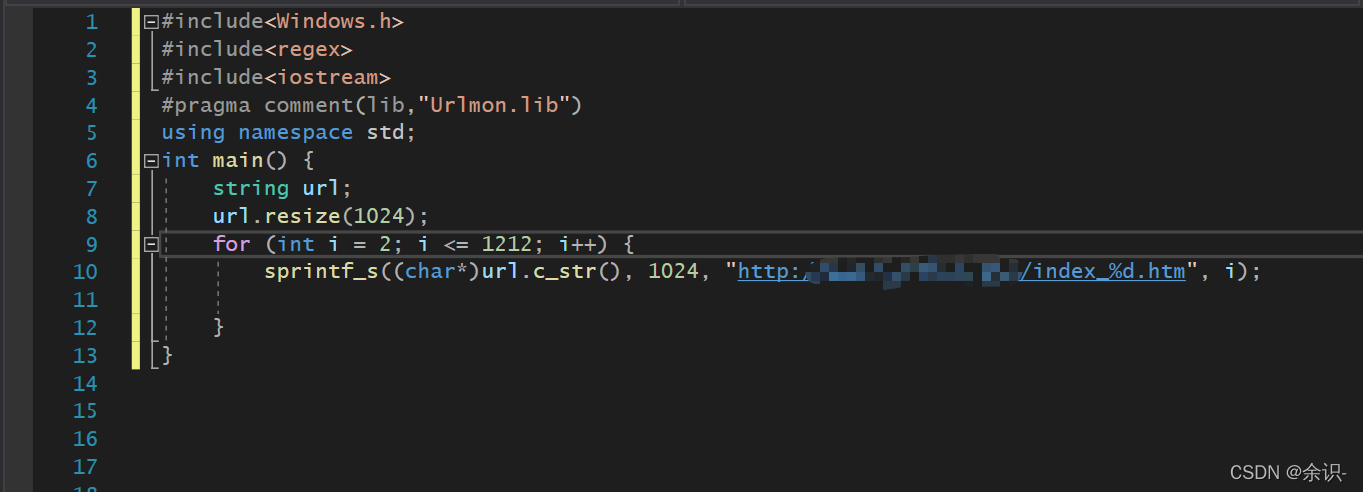
写一个通用函数GetTextFromUrlA,从指定URL中获取想要的文本内容
/// <summary>
/// 从网页中获取指定文本
/// </summary>
/// <param name="url">网页地址</param>
/// <param name="pattern">匹配模式</param>
/// <param name="patternIndex">返回第几个()中的内容</param>
/// <param name="num">返回匹配到的数量</param>
/// <returns>返回的字符串数组</returns>
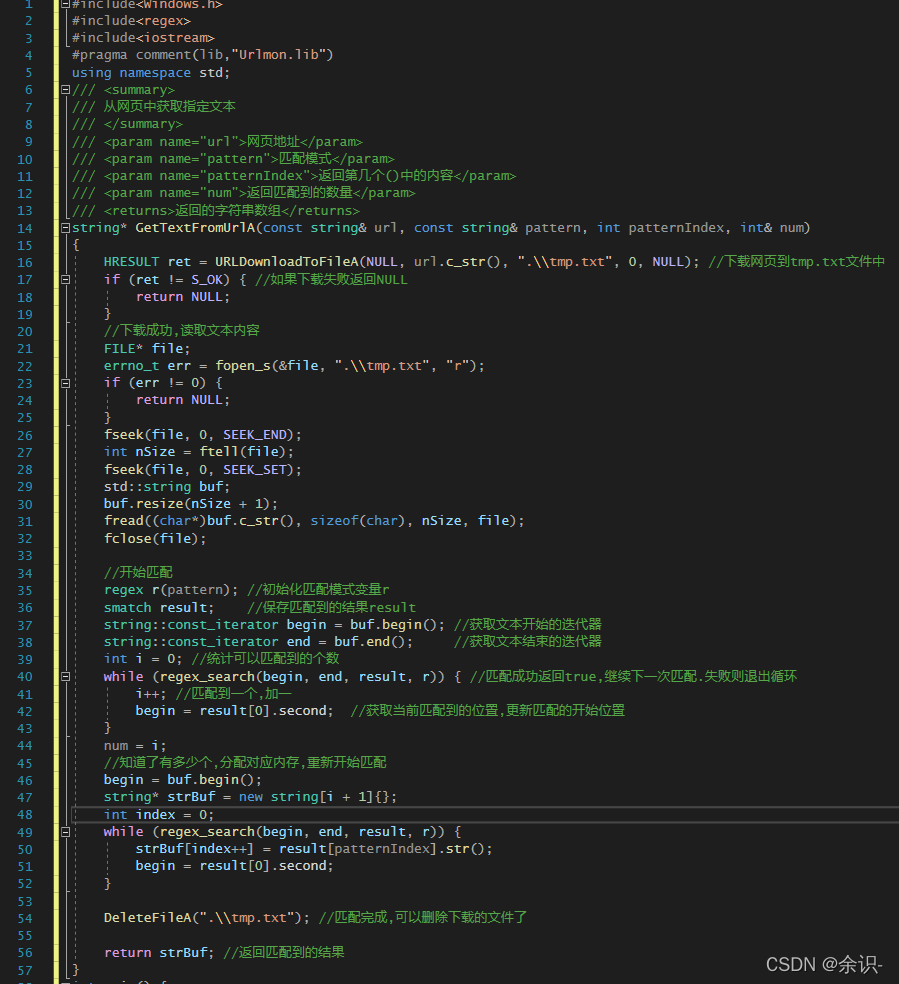
string* GetTextFromUrlA(const string& url, const string& pattern, int patternIndex, int& num)
{
HRESULT ret = URLDownloadToFileA(NULL, url.c_str(), ".\tmp.txt", 0, NULL); //下载网页到tmp.txt文件中
if (ret != S_OK) { //如果下载失败返回NULL
return NULL;
}
//下载成功,读取文本内容
FILE* file;
errno_t err = fopen_s(&file, ".\tmp.txt", "r");
if (err != 0) {
return NULL;
}
fseek(file, 0, SEEK_END);
int nSize = ftell(file);
fseek(file, 0, SEEK_SET);
std::string buf;
buf.resize(nSize + 1);
fread((char*)buf.c_str(), sizeof(char), nSize, file);
fclose(file);
//开始匹配
regex r(pattern); //初始化匹配模式变量r
smatch result; //保存匹配到的结果result
string::const_iterator begin = buf.begin(); //获取文本开始的迭代器
string::const_iterator end = buf.end(); //获取文本结束的迭代器
int i = 0; //统计可以匹配到的个数
while (regex_search(begin, end, result, r)) { //匹配成功返回true,继续下一次匹配.失败则退出循环
i++; //匹配到一个,加一
begin = result[0].second; //获取当前匹配到的位置,更新匹配的开始位置
}
num = i;
//知道了有多少个,分配对应内存,重新开始匹配
begin = buf.begin();
string* strBuf = new string[i + 1]{};
int index = 0;
while (regex_search(begin, end, result, r)) {
strBuf[index++] = result[patternIndex].str();
begin = result[0].second;
}
DeleteFileA(".\tmp.txt"); //匹配完成,可以删除下载的文件了
return strBuf; //返回匹配到的结果
}
然后写匹配模式,调用该函数,因为我写的匹配模式串中,第一个括号里的是我想要的内容,所以后面填的1,这个请根据大家具体情况写适当的匹配模式串,需要注意的是C++中 " 这个符号需要写成 "
int nums = 0;
string* str =GetTextFromUrlA(url.c_str(), "<li><a href="(.*?)"\s{0,1}title="(.*?)".*?><img src="(.*?)" .*?</li>", 1, nums);
if (nums <= 0) {
cout << "该页面下载失败!" << endl;
continue;
}
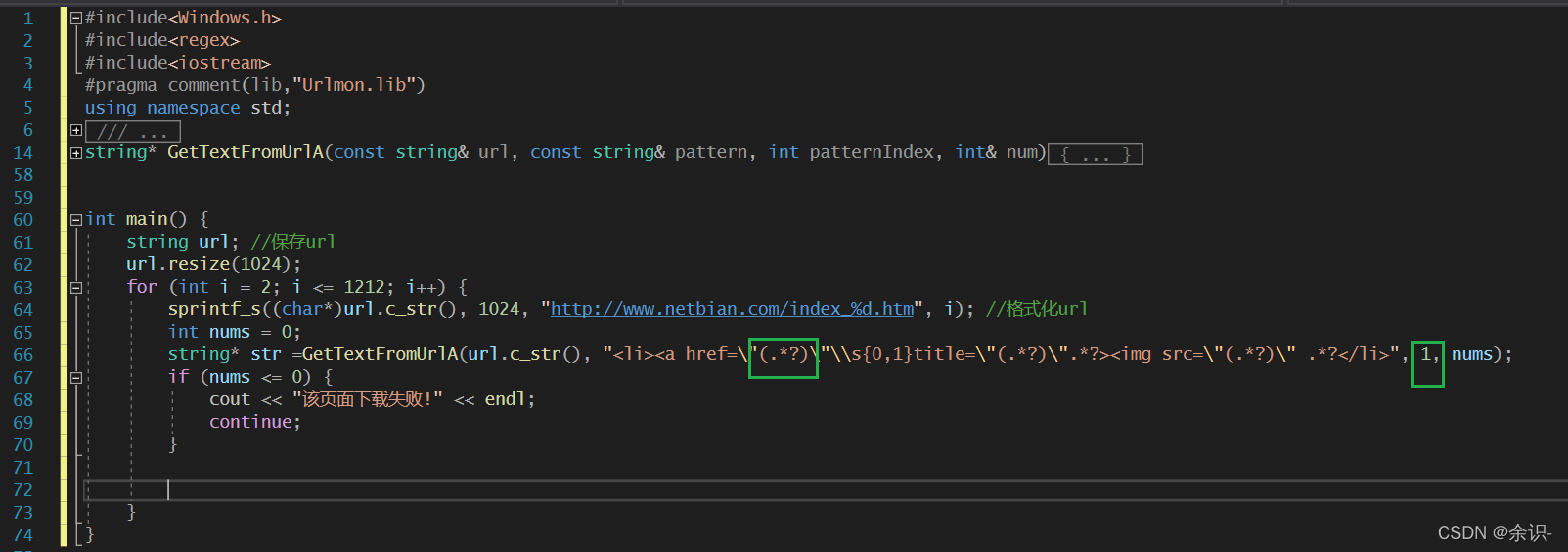
测试一下下载函数是否有问题
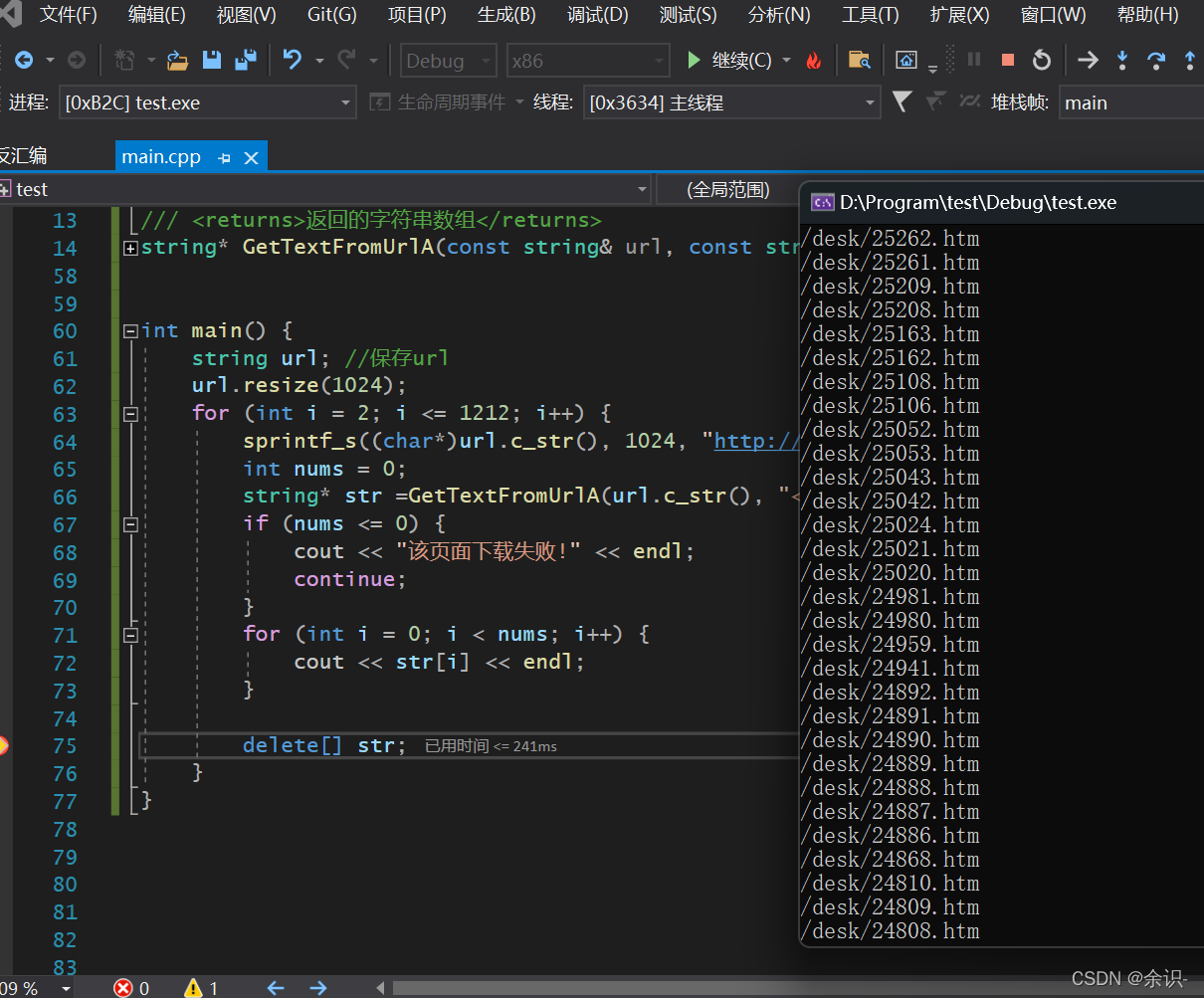
成功获取指定内容,大家可能已经发现,这些字符串都是.htm结尾,说明这还是个html文档,根本不是图片,而且都是缺少站名的部分索引
这是因为我发现,该网站是两层文档展示的,随便点进去一张图片,第二层,长这样
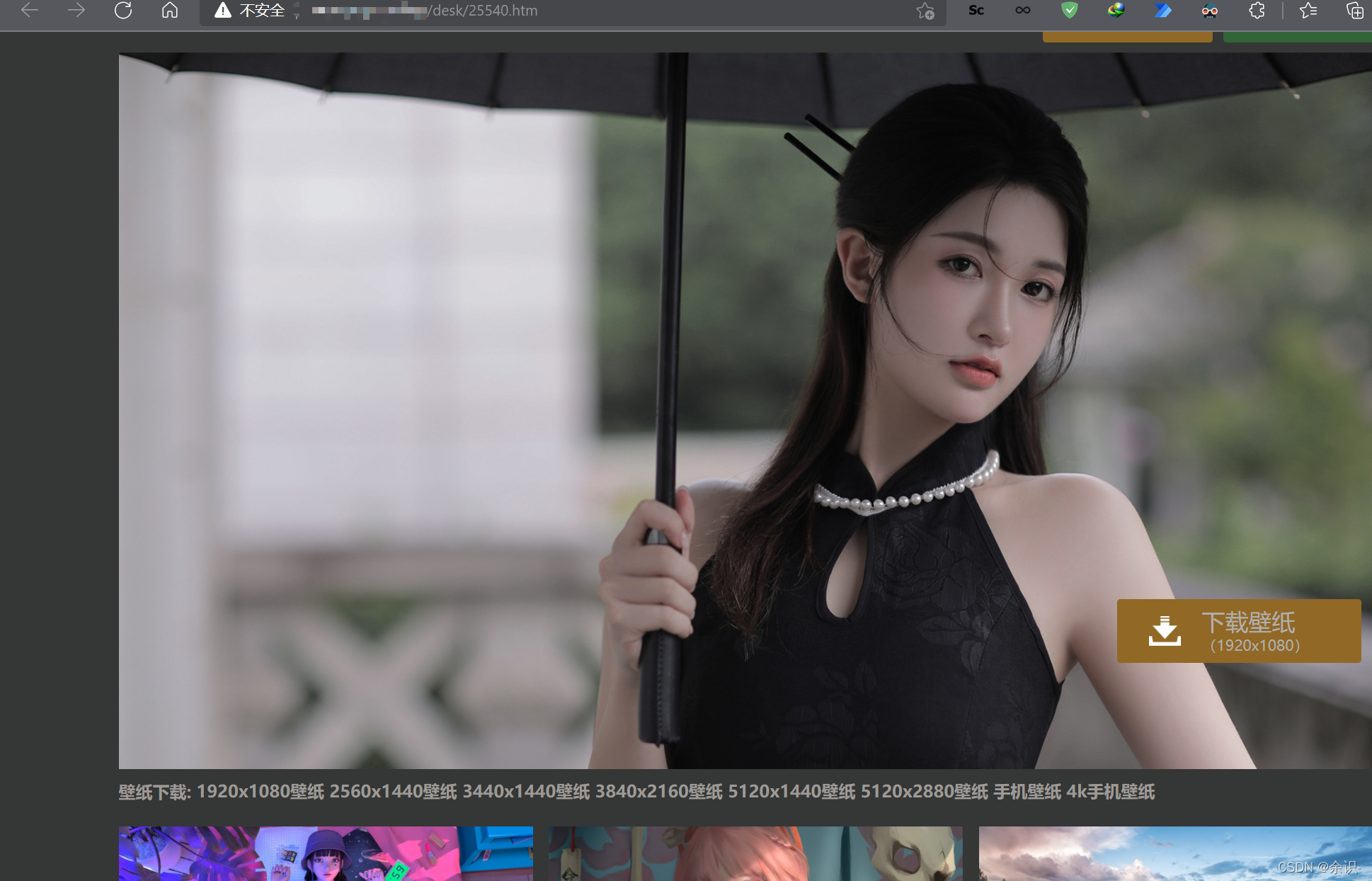
所以接下来,我们要做的就是,补全URL,再从第二层网页中获取图片地址就可以了!
for (int j = 0; j < nums; j++) {
Sleep(1000); //避免过快访问网站,被封杀ip,多次实验,1秒爬取一张,可以稳定爬取
sprintf_s((char*)url.c_str(), 1024, "http://....%s", str[j].c_str()); //格式化图片url
int nPic{};
string* sPic = GetTextFromUrlA(url.c_str(), "<div class="pic">.*?<img src="(.*?)" .*?</p>", 1, nPic);//获取图片地址
if (nPic <= 0) {
continue;
}
for (int k = 0; k < nPic; k++) {
cout << sPic[k] << endl;
}
delete[] sPic;
}
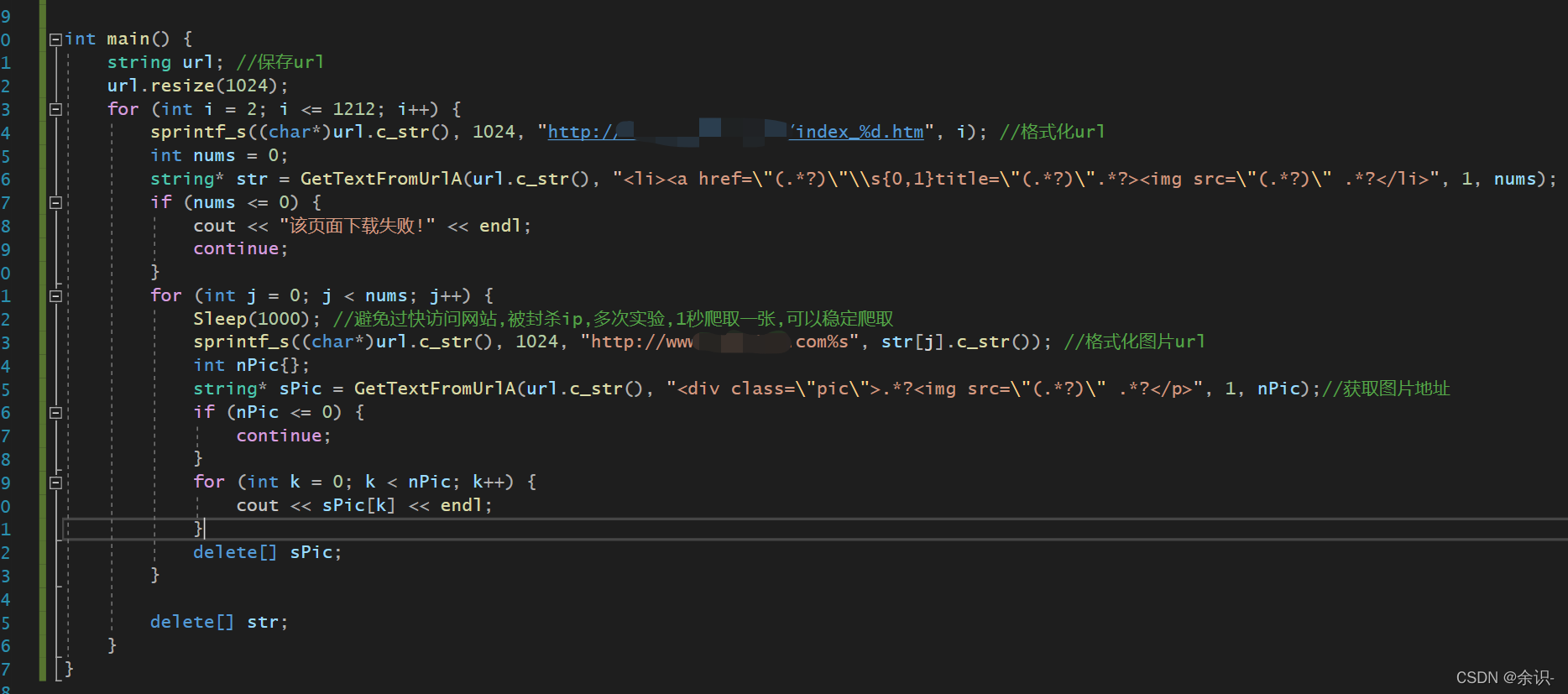
成功获取该页面所有图片的地址
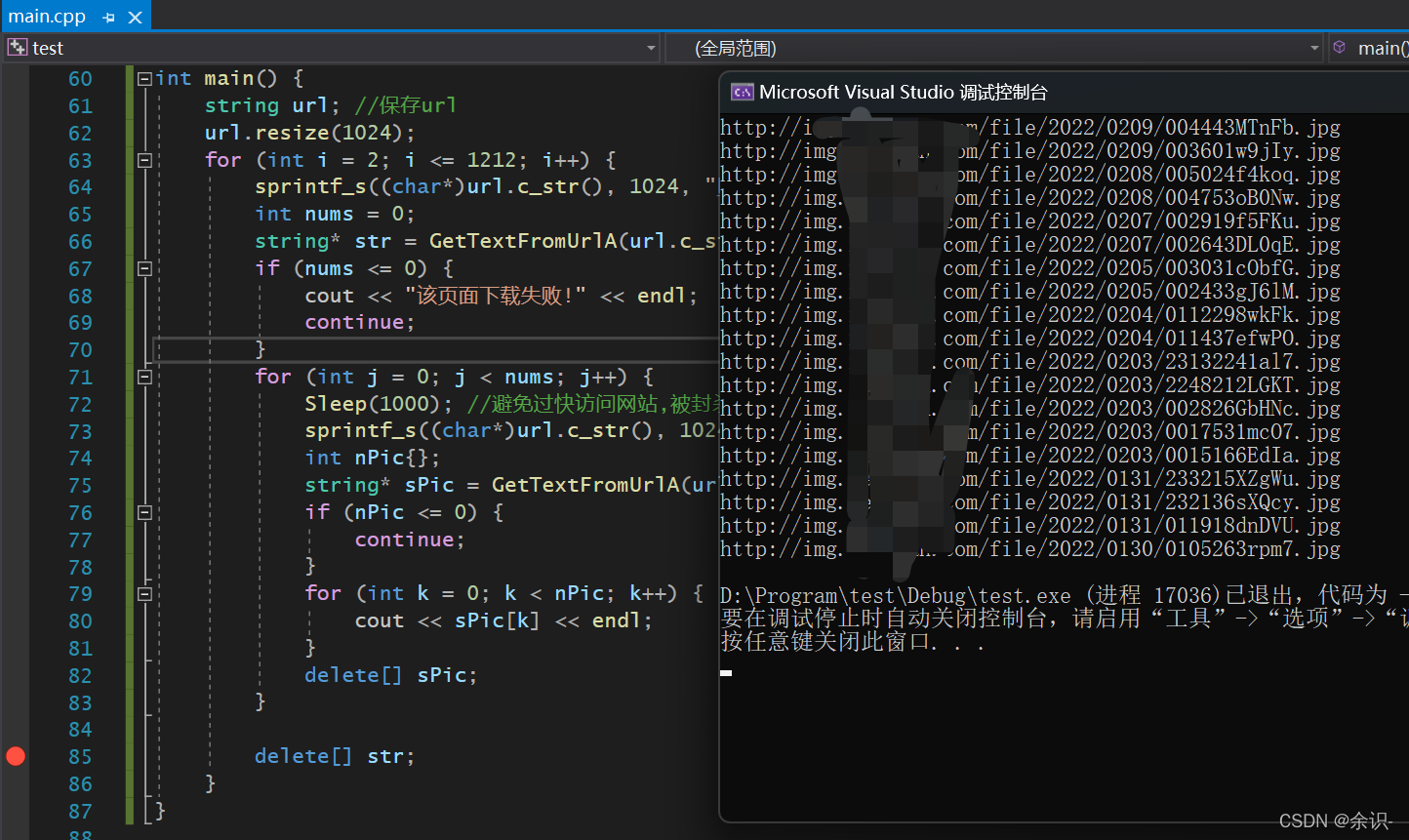
最后就简单了,将这些地址下载保存就可以了
因为需要解析名字之类的,所以最好还是写个函数
/// <summary>
/// 将url指定图片下载到本地dir目录下
/// </summary>
/// <param name="dir">存放图片的目录</param>
/// <param name="url">要下载的图片</param>
/// <returns></returns>
bool DownPic(const string& dir,const string& url) {
//将图片名字解析到name变量中
string name;
for (int i = url.size()-1; i >= 0; i--) {
if (url[i] == '/') {
name = &url[i+1];
break;
}
}
name = dir + "\" + name; //将name转化为本地目录文件
HRESULT ret=URLDownloadToFileA(NULL, url.c_str(), name.c_str(), 0, NULL);//下载
if (ret == S_OK) {
return true;
}
return false;
}
最后测试一下
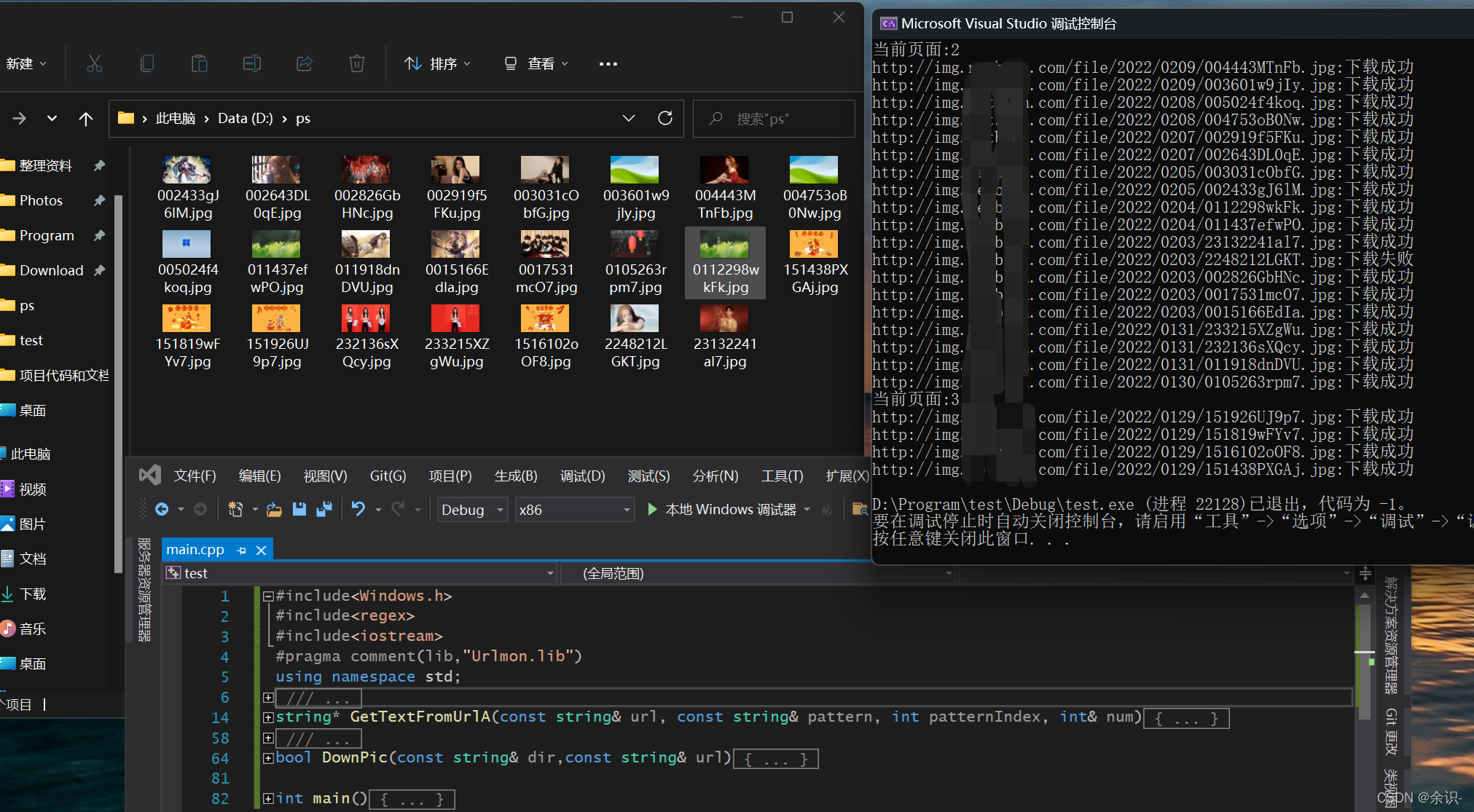
完美爬取
完整代码(缺少站名):
#include<Windows.h>
#include<regex>
#include<iostream>
#pragma comment(lib,"Urlmon.lib")
using namespace std;
/// <summary>
/// 从网页中获取指定文本
/// </summary>
/// <param name="url">网页地址</param>
/// <param name="pattern">匹配模式</param>
/// <param name="patternIndex">返回第几个()中的内容</param>
/// <param name="num">返回匹配到的数量</param>
/// <returns>返回的字符串数组</returns>
string* GetTextFromUrlA(const string& url, const string& pattern, int patternIndex, int& num)
{
HRESULT ret = URLDownloadToFileA(NULL, url.c_str(), ".\tmp.txt", 0, NULL); //下载网页到tmp.txt文件中
if (ret != S_OK) { //如果下载失败返回NULL
return NULL;
}
//下载成功,读取文本内容
FILE* file;
errno_t err = fopen_s(&file, ".\tmp.txt", "r");
if (err != 0) {
return NULL;
}
fseek(file, 0, SEEK_END);
int nSize = ftell(file);
fseek(file, 0, SEEK_SET);
std::string buf;
buf.resize(nSize + 1);
fread((char*)buf.c_str(), sizeof(char), nSize, file);
fclose(file);
//开始匹配
regex r(pattern); //初始化匹配模式变量r
smatch result; //保存匹配到的结果result
string::const_iterator begin = buf.begin(); //获取文本开始的迭代器
string::const_iterator end = buf.end(); //获取文本结束的迭代器
int i = 0; //统计可以匹配到的个数
while (regex_search(begin, end, result, r)) { //匹配成功返回true,继续下一次匹配.失败则退出循环
i++; //匹配到一个,加一
begin = result[0].second; //获取当前匹配到的位置,更新匹配的开始位置
}
num = i;
//知道了有多少个,分配对应内存,重新开始匹配
begin = buf.begin();
string* strBuf = new string[i + 1]{};
int index = 0;
while (regex_search(begin, end, result, r)) {
strBuf[index++] = result[patternIndex].str();
begin = result[0].second;
}
DeleteFileA(".\tmp.txt"); //匹配完成,可以删除下载的文件了
return strBuf; //返回匹配到的结果
}
/// <summary>
/// 将url指定图片下载到本地dir目录下
/// </summary>
/// <param name="dir">存放图片的目录</param>
/// <param name="url">要下载的图片</param>
/// <returns></returns>
bool DownPic(const string& dir,const string& url) {
//将图片名字解析到name变量中
string name;
for (int i = url.size()-1; i >= 0; i--) {
if (url[i] == '/') {
name = &url[i+1];
break;
}
}
name = dir + "\" + name; //将name转化为本地目录文件
HRESULT ret=URLDownloadToFileA(NULL, url.c_str(), name.c_str(), 0, NULL);//下载
if (ret == S_OK) {
return true;
}
return false;
}
int main() {
string url; //保存url
url.resize(1024);
for (int i = 2; i <= 1212; i++) {
cout << "当前页面:"<<i << endl;
sprintf_s((char*)url.c_str(), 1024, "http://.../index_%d.htm", i); //格式化url
int nums = 0;
string* str = GetTextFromUrlA(url.c_str(), "<li><a href="(.*?)"\s{0,1}title="(.*?)".*?><img src="(.*?)" .*?</li>", 1, nums);
if (nums <= 0) {
cout << "该页面下载失败!" << endl;
continue;
}
for (int j = 0; j < nums; j++) {
Sleep(1000); //避免过快访问网站,被封杀ip,多次实验,1秒爬取一张,可以稳定爬取
sprintf_s((char*)url.c_str(), 1024, "http://...%s", str[j].c_str()); //格式化图片url
int nPic{};
string* sPic = GetTextFromUrlA(url.c_str(), "<div class="pic">.*?<img src="(.*?)" .*?</p>", 1, nPic);//获取图片地址
if (nPic <= 0) {
continue;
}
for (int k = 0; k < nPic; k++) {
if (DownPic("D:\ps", sPic[k])) cout <<sPic[k]<<":下载成功"<<endl;
else cout << sPic[k] << ":下载失败"<<endl;
}
delete[] sPic;
}
delete[] str;
}
}
总结
对比之下,python写爬虫确实非常方便,也推荐大家用python写爬虫.
但在此之前,应该要理解爬虫的原理,C++虽然繁琐,但却是理解原理的好助手.
当大家慢慢积累出属于自己的C++类库时,也许比python更好用也说不一定呢
源码下载
先自我介绍一下,小编13年上师交大毕业,曾经在小公司待过,去过华为OPPO等大厂,18年进入阿里,直到现在。深知大多数初中级java工程师,想要升技能,往往是需要自己摸索成长或是报班学习,但对于培训机构动则近万元的学费,着实压力不小。自己不成体系的自学效率很低又漫长,而且容易碰到天花板技术停止不前。因此我收集了一份《java开发全套学习资料》送给大家,初衷也很简单,就是希望帮助到想自学又不知道该从何学起的朋友,同时减轻大家的负担。添加下方名片,即可获取全套学习资料哦