一 CAP理论
1.1 CAP理论
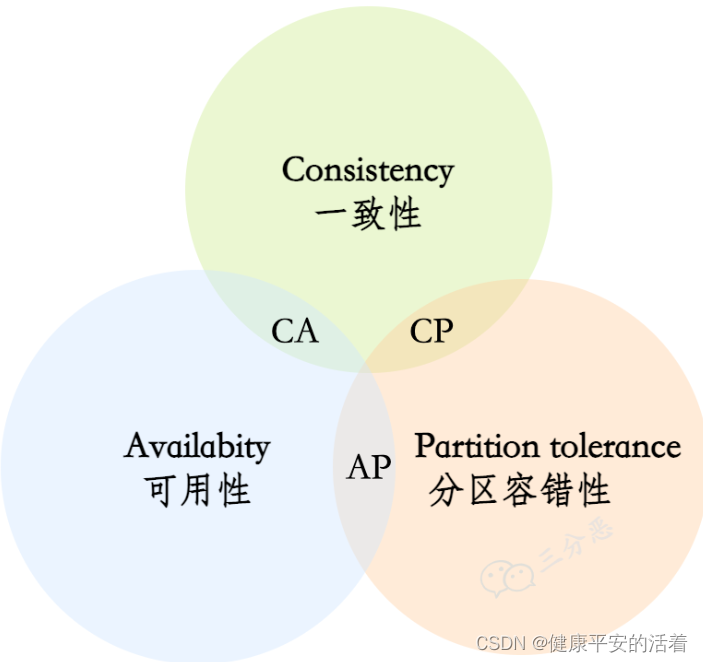
CAP原则又称CAP定理,指的是在一个分布式系统中,Consistency(一致性)、 Availability(可用性)、Partition tolerance(分区容错性)这3个基本需求,最多只能同时满足其中的2个。
| 选项 | 描述 |
|---|---|
| Consistency(一致性) | 指数据在多个副本之间能够保持一致的特性(严格的一致性) |
| Availability(可用性) | 指系统提供的服务必须一直处于可用的状态,每次请求都能获取到非错的响应(不保证获取的数据为最新数据) |
| Partition tolerance(分区容错性) | 分布式系统在遇到任何网络分区故障的时候,仍然能够对外提供满足一致性和可用性的服务,除非整个网络环境都发生了故障 |
1.2 CAP案例场景
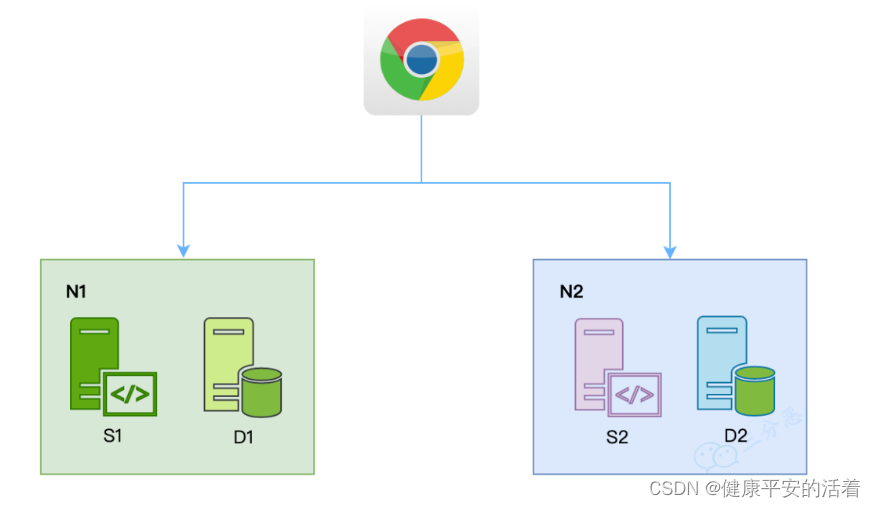
假如现在有这样的场景:
-
用户访问了N1,修改了D1的数据。
-
用户再次访问,请求落在了N2。此时D1和D2的数据不一致。
接下来:
-
保证
一致性:此时D1和D2数据不一致,要保证一致性就不能返回不一致的数据,可用性无法保证。 -
保证
可用性:立即响应,可用性得到了保证,但是此时响应的数据和D1不一致,一致性无法保证。
所以,可以看出,分区容错的前提下,一致性和可用性是矛盾的。
1.3 对应的模型应用
-
ZooKeeper 保证的是 CP
-
Eureka 保证的则是 AP
-
Nacos 不仅支持 CP 也支持 AP
二 分布式锁
2.1 分布式锁的实现方式
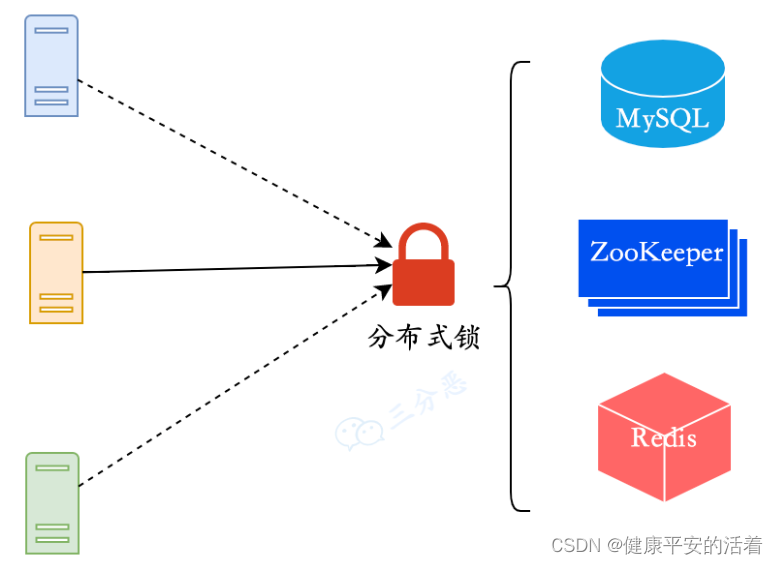
常见的分布式锁实现方案有三种:MySQL分布式锁、ZooKepper分布式锁、Redis分布式锁
2.1.1 MySQL分布式锁
数据库悲观锁实现的分布式锁:可以使用 select ... for update 来实现分布式锁。
用数据库实现分布式锁比较简单,就是创建一张锁表,数据库对字段作唯一性约束。加锁的时候,在锁表中增加一条记录即可;释放锁的时候删除记录就行。
如果有并发请求同时提交到数据库,数据库会保证只有一个请求能够得到锁。
这种属于数据库 IO 操作,效率不高,而且频繁操作会增大数据库的开销,因此这种方式在高并发、高性能的场景中用的不多
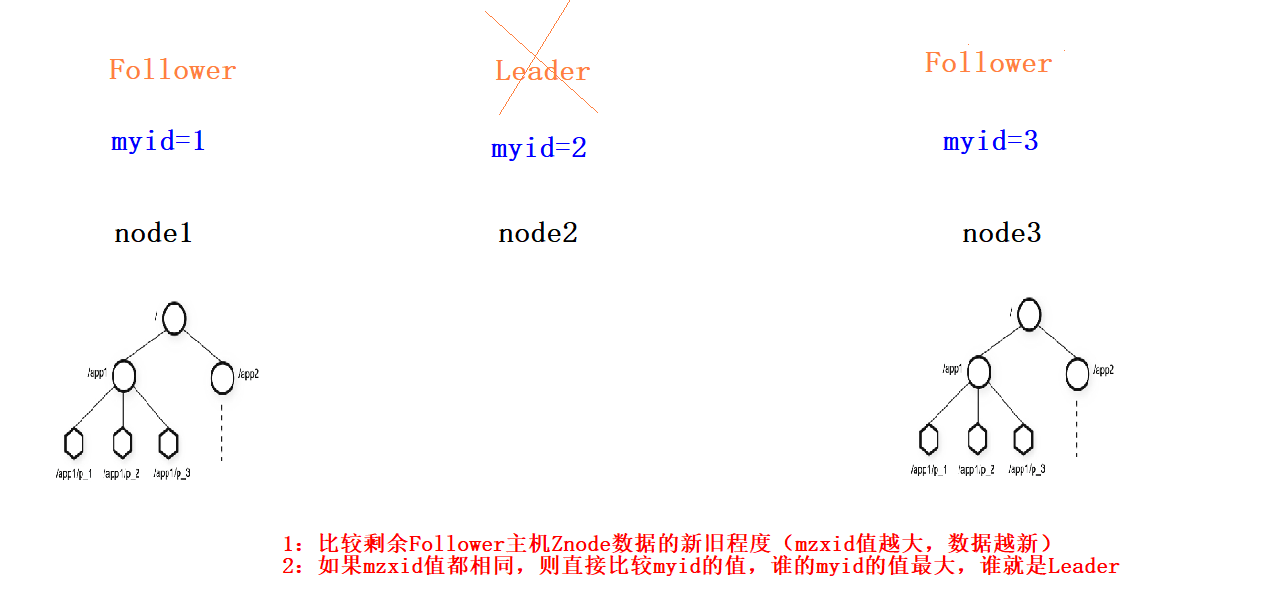
2.1.2 基于zk实现分布式锁
ZooKeeper的数据节点和文件目录类似,例如有一个lock节点,在此节点下建立子节点是可以保证先后顺序的,即便是两个进程同时申请新建节点,也会按照先后顺序建立两个节点。
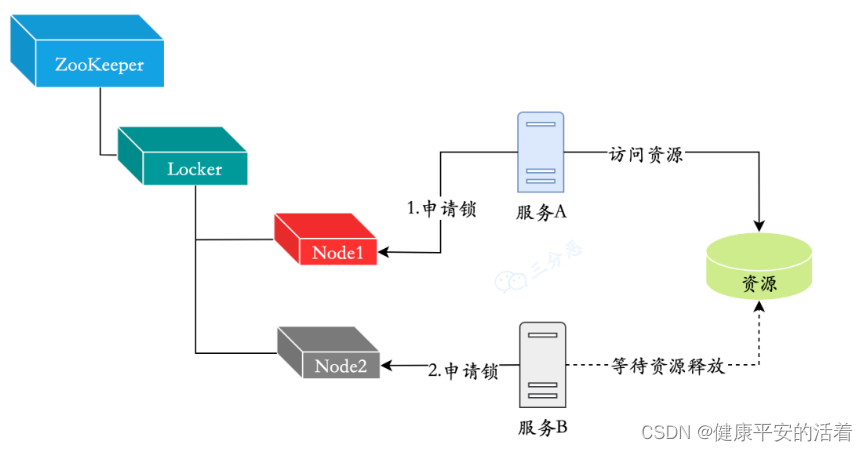
2.1.3 基于redis实现分布式锁
基于 Redis 分布式锁一般有以下这几种实现方式:setnx+expire。
加锁了之后如果机器宕机,那我这个锁就无法释放,所以需要加入过期时间,而且过期时间需要和setNx同一个原子操作,在Redis2.8之前需要用lua脚本,但是redis2.8之后redis支持nx和ex操作是同一原子操作。
三 分布式事务
3.1 分布式事务
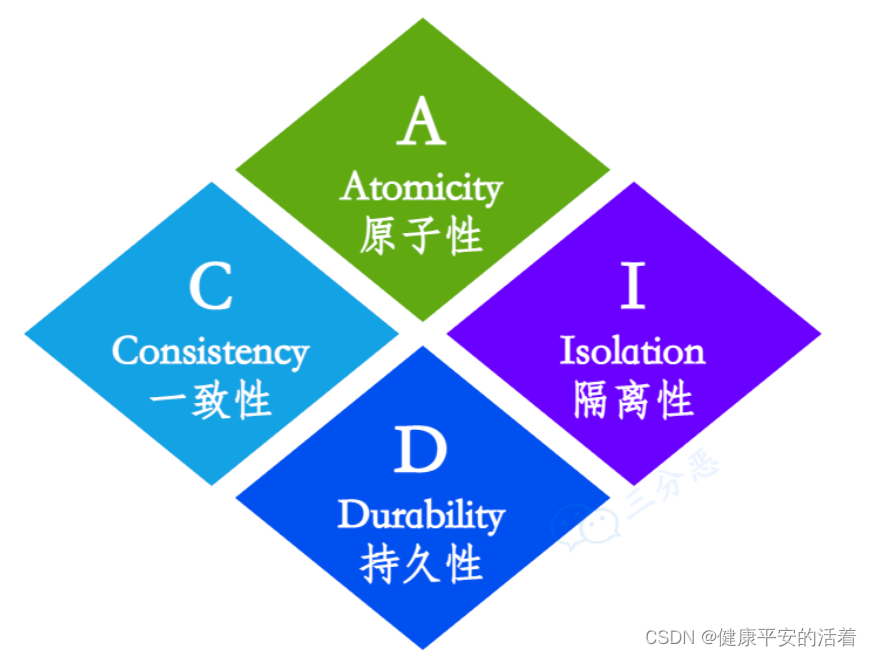
1.首先满足事务特性:ACID
2.而在分布式环境下,会涉及到多个数据库
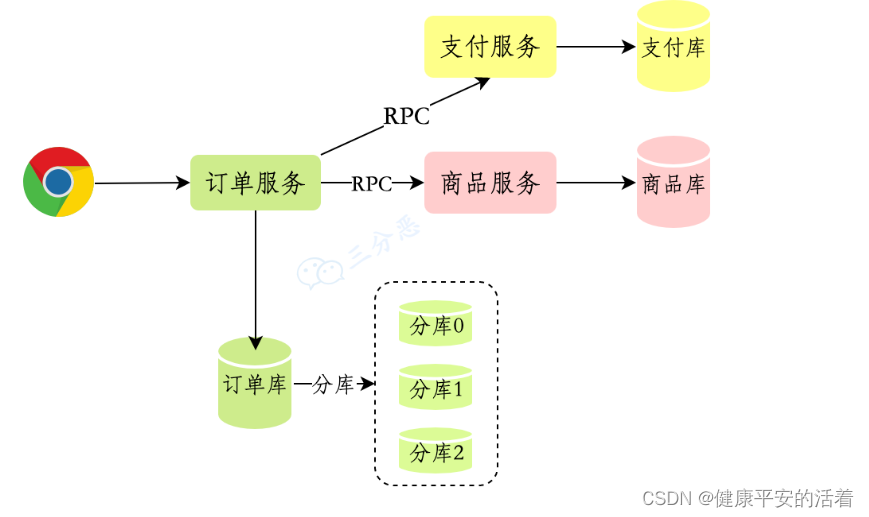
分布式事务处理的关键是:
1.需要记录事务在任何节点所做的所有动作;
2.事务进行的所有操作要么全部提交,要么全部回滚。
目的是为了保证分布式系统中的数据一致性。
2.2 分布式事务的解决方案
分布式夺命12连问