目录
前言
Kafka
什么是Kafka
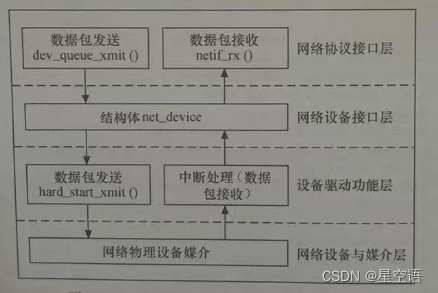
Kafka软件结构
Kafka的特点
怎么启动Kafka
下载Kafka
配置Kafka
Zookeeper
启动Kafka
Kafka案例
添加依赖
添加配置
配置启动类
创建生产者
创建消费者
测试
结语
前言
前几日总结了消息队列的一些知识,相信看完的同学们对消息队列的功能和作用都多少有了些基础的了解,为了让大家更快的上手消息队列,今天将给大家带来一篇大数据中常用的Kafka的介绍和实战教程,学完此篇,你将了解什么是Kafka,怎么使用Kafka和怎么将Kafka应用到项目中。
Kafka
什么是Kafka
Kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写。Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者在网站中的所有动作流数据。 这种动作(网页浏览,搜索和其他用户的行动)是在现代网络上的许多社会功能的一个关键因素。 这些数据通常是由于吞吐量的要求而通过处理日志和日志聚合来解决。 对于像Hadoop一样的日志数据和离线分析系统,但又要求实时处理的限制,这是一个可行的解决方案。Kafka的目的是通过Hadoop的并行加载机制来统一线上和离线的消息处理,也是为了通过集群来提供实时的消息。
Kafka软件结构
Producer:生产者,消息发送方,消息来源;
Consumer:消费者,消息接收方;
Topic:话题,消息收发方根据话题才能找到对的那个人,不会乱发;
Record:消息记录,是生产者和消费者传递的内容,保存在指定Topic内。
Kafka的特点
前文提到,Kafka是针对大数据设计的,官方号称并发1w/s,运行时堪比内存,可见其功能还是很强大的。
实际运行中,Kafka将消息队列中的信息保存在硬盘,它堪比内存的效率是因为对硬盘的读取规则做了优化,这点很强。主要是:顺序读写,零拷贝,日志压缩等技术。详情推荐这篇博客:整理了一周的Kafka规划和优化方案
Kafka在处理队列中的数据时,能够一直向服务器硬盘中保存队列信息,理论上没有大小限制,除非服务器硬盘满了。默认信息保存7天,时间可配置,数据量比较大的情况一天一处理,可以有效提高服务器性能,减少Kafka消耗。
怎么启动Kafka
下载Kafka
下载地址:Kafka下载地址
下载后博主是放在一个叫Kafka的文件夹内,文件夹下放下载后解压的Kafka和一个用来存储Kafka运行过程中产生数据的data(空目录)文件:

配置Kafka
进入 kafka_2.13-2.4.1/config文件,用记事本打开如下文件:
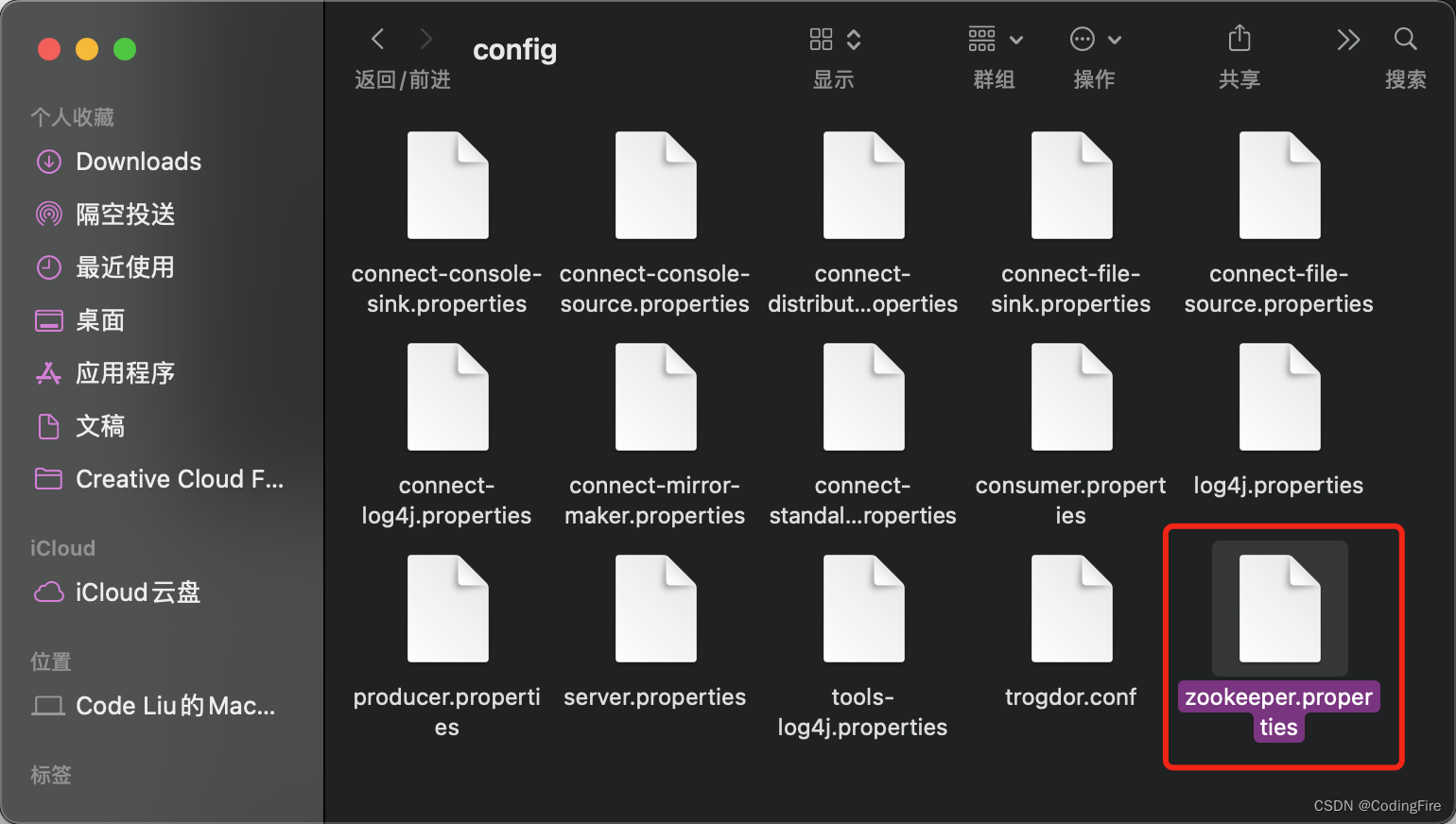
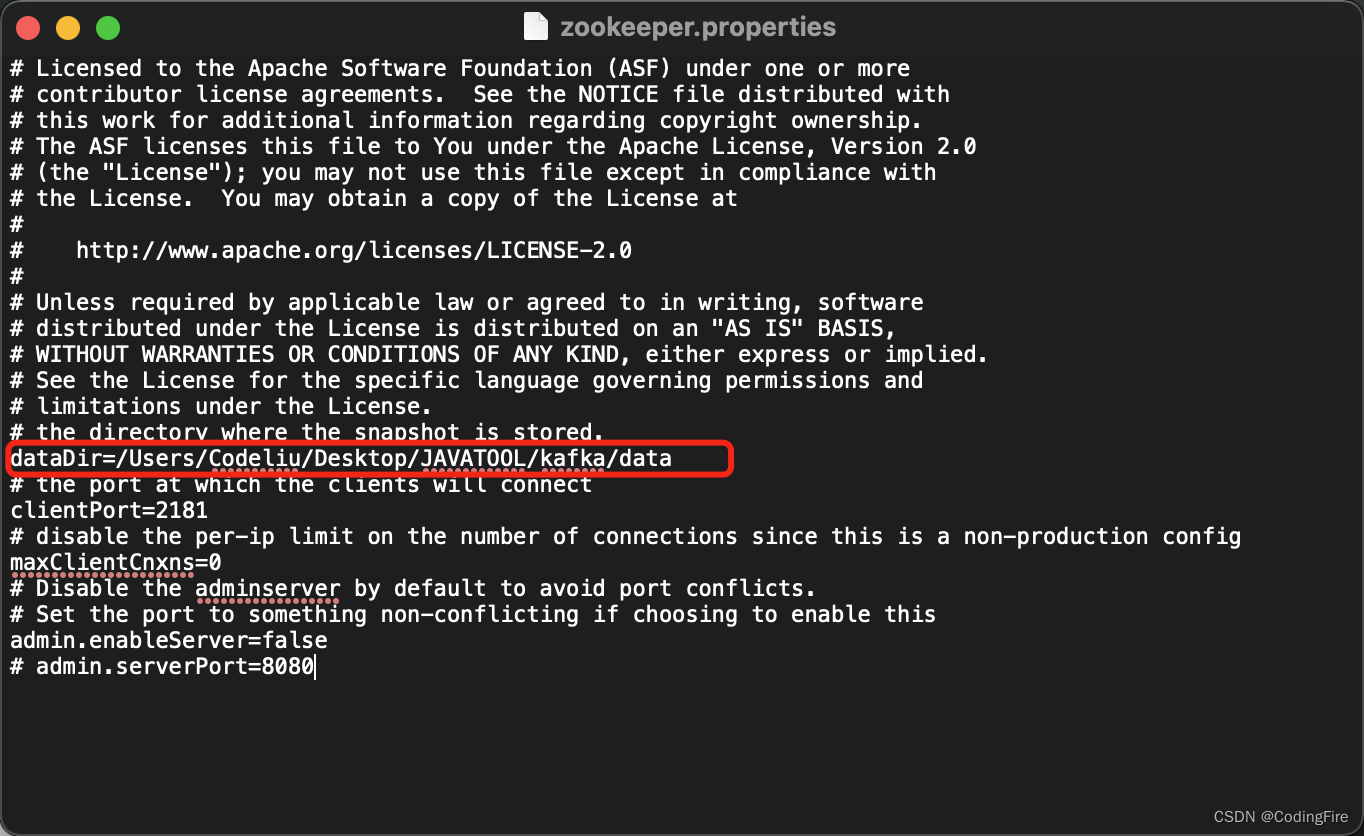
将dataDir后面的路径修改成你自己的data文件夹地址:
保存,关闭。再打开server.properties文件:
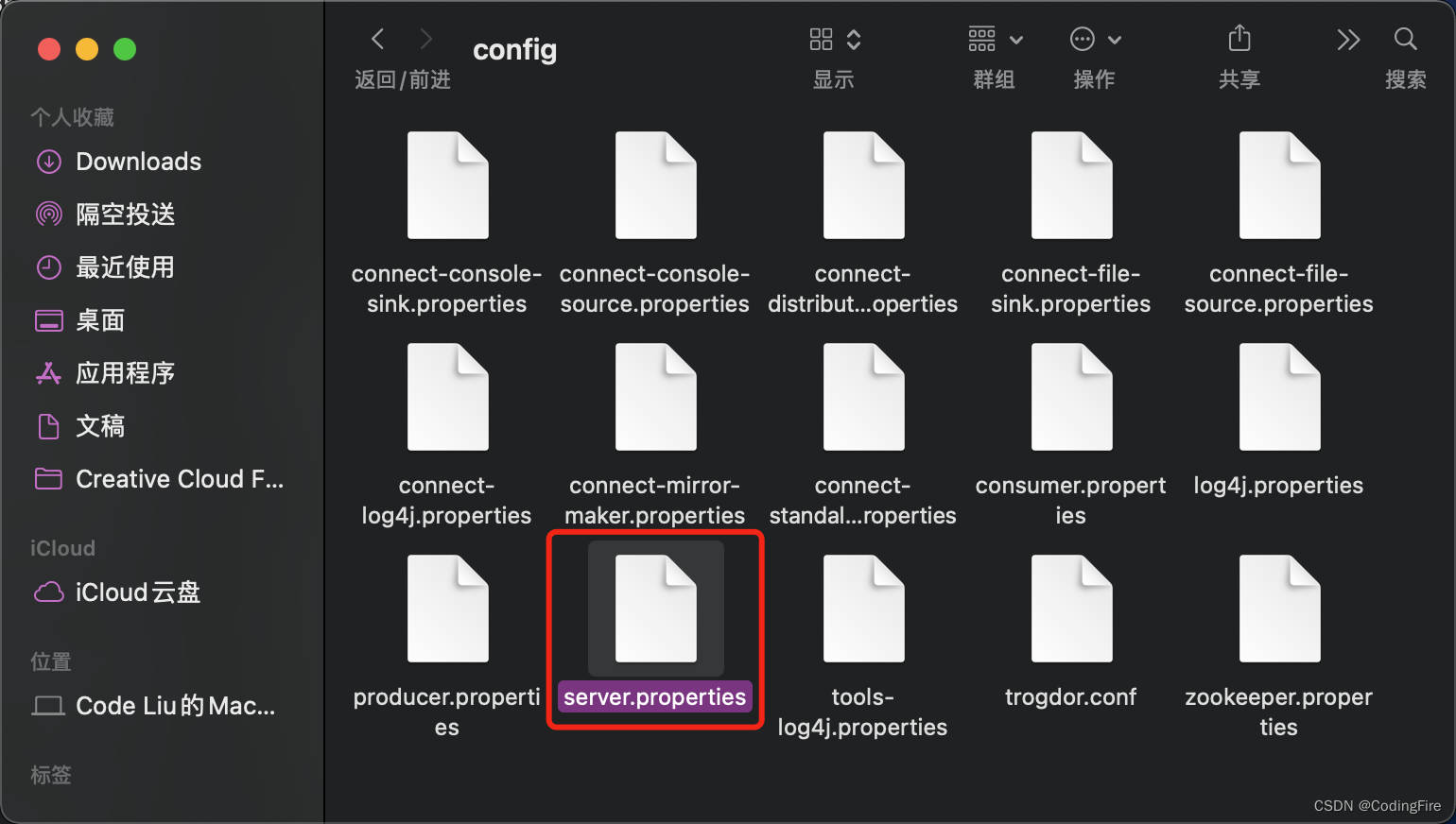
修改log.dirs后面的路径为你自己电脑上data的地址,和上面的地址是一样的:
做完这些记得保存啊,不保存啥用也没有。
Zookeeper
说起Zookeeper,其实我们上面的配置是配置的Zookeeper,但却和Kafka息息相关,想知道他们之间的关系吗?我们继续往下看。
ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。
上面的解释很官方,不是很好理解。通俗地说就是:早期的服务器软件安装后都有各自的配置,但是要安装的软件很多,配置多了就不好管理了,Zookeeper可以修改服务器系统中所有软件的配置,久而久之,很多软件就删除了自己写配置文件的功能,改从Zookeeper中获取。ZooKeeper就像一个动物园的饲养员,为什么说是动物园饲养员呢,你看MySql的标志是不是海豚,Tomcat是只猫,等等,你去看,这些软件都是动物标志,像个动物园一样。
启动Kafka
启动kafka要先启动zookeeper,mac电脑终端进入Kafka的bin文件目录下:
# 进入Kafka文件夹
cd Desktop/JAVATOOL/kafka/kafka_2.13-2.4.1/bin
# 启动Zookeeper服务
./zookeeper-server-start.sh ../config/zookeeper.properties
# 启动Kafka服务
./kafka-server-start.sh ../config/server.properties
zookeeper启动后终端输出:

kafka启动后终端输出:
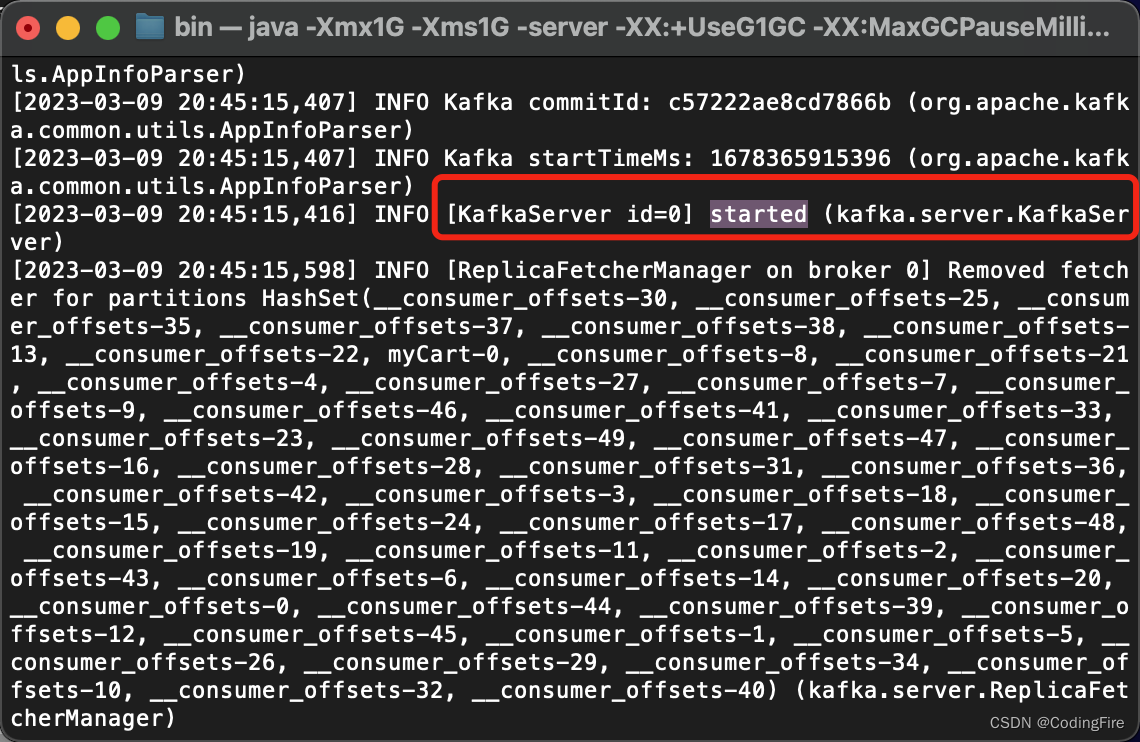
主要是看到这个started字样。
关闭Kafka命令:
# 关闭Kafka服务
./kafka-server-stop.sh
# 启动Zookeeper服务
./zookeeper-server-stop.sh需要先关闭Kafka,再关闭zookeeper,否则Kafka会一直报断开连接的错。
文件路径写你自己的,不要写博主的,两个服务启动用两个窗口来运行命令,运行期间窗口不要关闭。
Windows电脑需要进入到kafka/bin/windows目录下,接着输入以下命令:
启动zookeeper:
zookeeper-server-start.bat ..\..\config\zookeeper.properties启动kafka:
kafka-server-start.bat ..\..\config\server.propertieswindow关闭服务直接x掉窗口就可以。
Kafka案例
我们在此前微服务项目的cart子项目中演示Kafka的消息收发,下面跟着博主一步步来做吧。
添加依赖
<dependency>
<groupId>com.google.code.gson</groupId>
<artifactId>gson</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
这里特别提醒下,没有看前面微服务项目的童鞋你需要添加的依赖会少一些,建议先去看看微服务内容,把微服务基础项目先搭建起来,后续的开发很多都会在此基础上进行。 传送门:Java开发 - 数风流人物,还看“微服务”
添加配置
spring:
kafka:
# 定义kafka的位置
bootstrap-servers: localhost:9092
# 话题的分组名称,是必须配置的
# 为了区分当前项目和其他项目使用的,防止不同项目相同话题的干扰
# 本质是在话题名称前添加项目名称为前缀来防止的
consumer:
group-id: cart
配置启动类
在启动类上添加两个注解:
// 启动kafka的功能
@EnableKafka
// 为了测试kafka,我们可以周期性的发送消息到消息队列
// 使用SpringBoot自带的调度工具即可
@EnableScheduling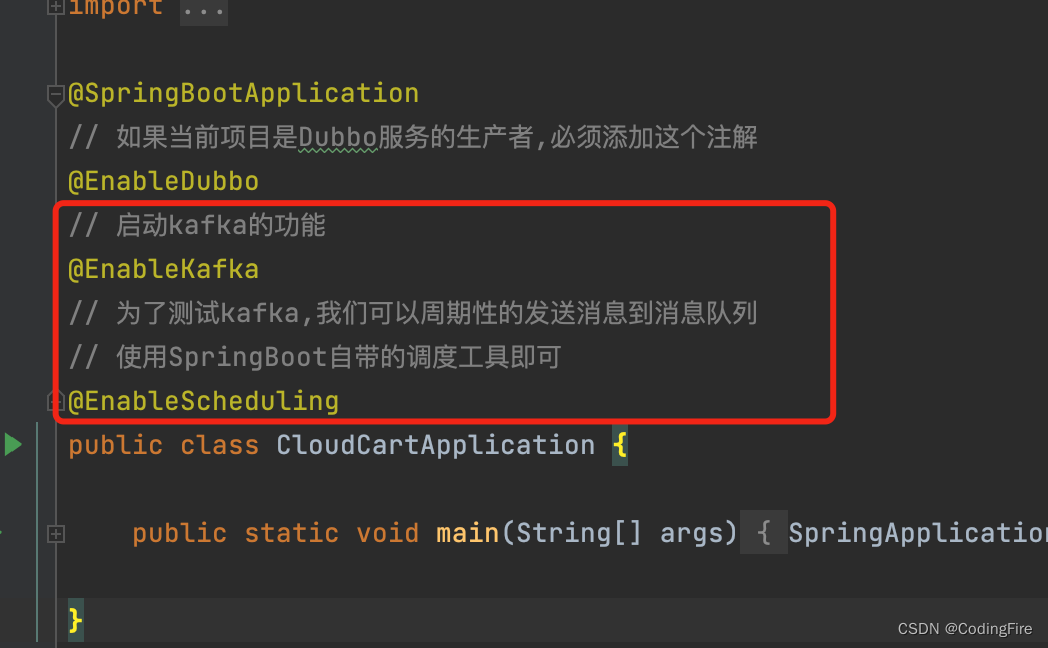
创建生产者
在cart包下新建一个kafka包,包下建一个叫Producer的类:
package com.codingfire.cloud.cart.kafka;
import com.codingfire.cloud.commons.pojo.cart.entity.Cart;
import com.google.gson.Gson;
import org.apache.commons.lang.math.RandomUtils;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.scheduling.annotation.Scheduled;
import org.springframework.stereotype.Component;
// 我们需要周期性的向Kafka发送消息
// 需要将具备SpringBoot调度功能的类保存到Spring容器才行
@Component
public class Producer {
// 能够实现将消息发送到Kafka的对象
// 只要Kafka配置正确,这个对象会自动保存到Spring容器中,我们直接装配即可
// KafkaTemplate<[话题名称的类型],[传递消息的类型]>
@Autowired
private KafkaTemplate<String,String> kafkaTemplate;
// 每隔10秒向Kafka发送信息
int i=1;
// fixedRate是周期运行,单位毫秒 10000ms就是10秒
@Scheduled(fixedRate = 10000)
// 这个方法只要启动SpringBoot项目就会按上面设置的时间运行
public void sendMessage(){
// 实例化一个Cart类型对象,用于发送消息
Cart cart=new Cart();
cart.setId(i++);
cart.setCommodityCode("PC100");
cart.setPrice(RandomUtils.nextInt(100)+200);
cart.setCount(RandomUtils.nextInt(5)+1);
cart.setUserId("UU100");
// 将cart对象转换为json格式字符串
Gson gson=new Gson();
// 执行转换
String json=gson.toJson(cart);
System.out.println("本次发送的消息为:"+json);
// 执行发送
// send([话题名称],[发送的消息]),需要遵循上面kafkaTemplate声明的泛型类型
kafkaTemplate.send("myCart",json);
}
}
创建消费者
在kafka包下创建Consumer类:
package com.codingfire.cloud.cart.kafka;
import com.codingfire.cloud.commons.pojo.cart.entity.Cart;
import com.google.gson.Gson;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.stereotype.Component;
// 因为Kafka接收消息是自动的,所以这个类也必须交由Spring容器管理0
@Component
public class Consumer {
// SpringKafka框架接收Kafka中的消息使用监听机制
// SpringKafka框架提供一个监听器,专门负责关注指定的话题名称
// 只要该话题名称中有消息,会自动获取该消息,并调用下面方法
@KafkaListener(topics = "myCart")
// 上面注解和下面方法关联,方法的参数就是接收到的消息
public void received(ConsumerRecord<String,String> record){
// 方法参数类型必须是ConsumerRecord
// ConsumerRecord<[话题名称类型],[消息类型]>
// 获取消息内容
String json=record.value();
// 要想在java中使用,需要转换为java对象
Gson gson=new Gson();
// 将json转换为java对象,需要提供转换目标类型的反射
Cart cart=gson.fromJson(json,Cart.class);
System.out.println("接收到对象为:"+cart);
}
}
测试
下面,我们启动项目,由于我们的项目配置了nacos和seata,所以这两个服务要保证是开启的。如果你是新起的项目可以不用。
项目运行后,根据我们的代码,我们应该是每10s能到一条消息输入和输出的,我们在控制台看一下:
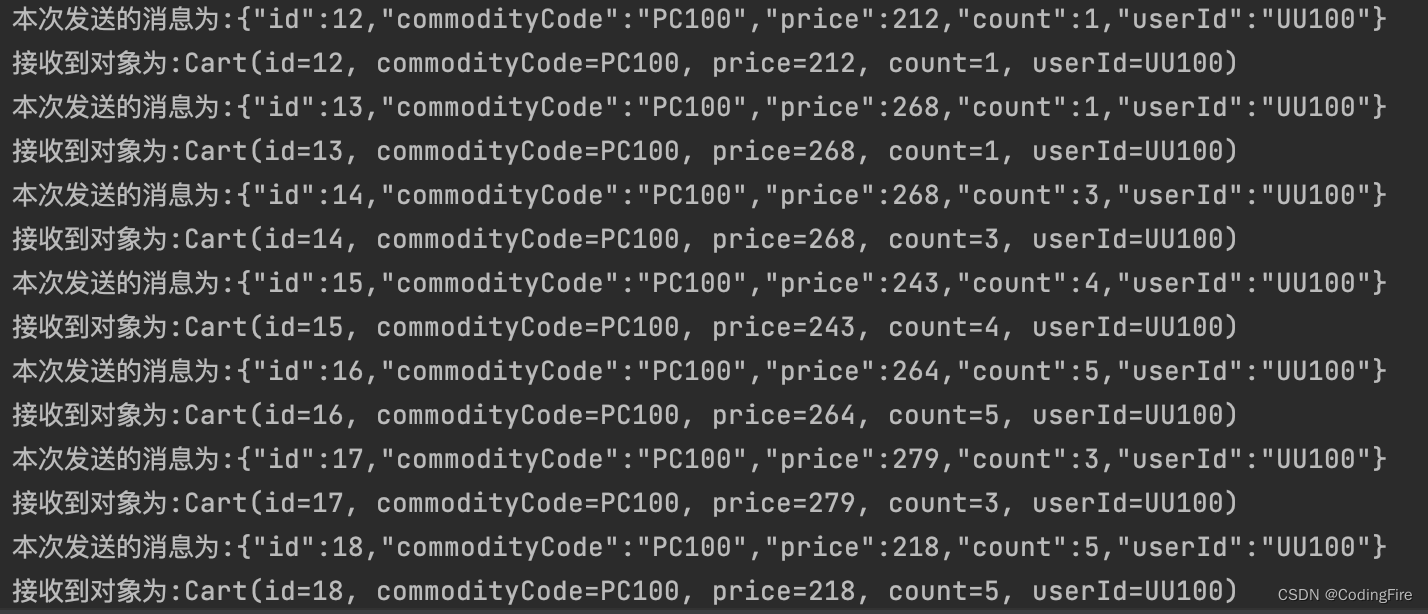
说明我们的测试是成功的,我们已经完成了一个完整的消息发送和接收的过程。
但是,这也只是Kafka一个最简单的使用案例,关于Kafka肯定不止是做这么一点点事情,关于Kafka更多的功能,博主也还在学习中,推荐一个网址给大家学习:kafka中文教程
结语
最后了,说点什么吧。只能说,Kafka博大精深,微服务深不可测,真不是三言两语,三篇两篇就能说得清楚的,这篇博客就如标题一样,只能算是初体验了,相较于es和redis来说,这篇博客只能算是皮毛,要学的东西还有很多很多,最重要的是实战。
最后要说的是专注,学习不要好高骛远,专注于一个点去学习,光是微服务中任何一个辅助软件都足够研究很久了,先学会用,其次再深入学习,关于更多Kafka的实战应用,后期博主吃透后会给大家详细剖析,一起努力吧。






![[acwing周赛复盘] 第 94 场周赛20230311](https://img-blog.csdnimg.cn/4803447c73444805a85425e045de926f.png)