索引分类
索引和数据就是位于存储引擎中:
- 按「数据结构」分类:B+tree索引、Hash索引、Full-text索引。
- 按「物理存储」分类:聚簇索引(主键索引)、二级索引(辅助索引)。
- 按「字段特性」分类:主键索引、唯一索引、普通索引、前缀索引。
- 按「字段个数」分类:单列索引、联合索引。
为什么 MySQL InnoDB 选择 B+tree 作为索引的数据结构?
1、B+Tree vs B Tree
-
B+Tree 只在叶子节点存储数据,而 B 树 的非叶子节点也要存储数据,所以 B+Tree 的单个节点的数据量更小,在相同的磁盘 I/O 次数下,就能查询更多的节点。
-
另外,B+Tree 叶子节点采用的是双链表连接,适合 MySQL 中常见的基于范围的顺序查找,而 B 树无法做到这一点。
2、B+Tree vs 二叉树
-
对于有 N 个叶子节点的 B+Tree,其搜索复杂度为O(logdN),其中 d 表示节点允许的最大子节点个数为 d 个。
-
在实际的应用当中, d 值是大于100的,这样就保证了,即使数据达到千万级别时,B+Tree 的高度依然维持在 3~4 层左右,也就是说一次数据查询操作只需要做 3~4 次的磁盘 I/O 操作就能查询到目标数据。
-
而二叉树的每个父节点的儿子节点个数只能是 2 个,意味着其搜索复杂度为 O(logN),这已经比 B+Tree 高出不少,因此二叉树检索到目标数据所经历的磁盘 I/O 次数要更多。
3、B+Tree vs Hash
-
Hash 在做等值查询的时候效率贼快,搜索复杂度为 O(1)。
-
Hash需要一次性将数据加载到内存中,如果数据比较大,则加载时间长,而B+tree是分节点加载数据
-
但是 Hash 表不适合做范围查询,它更适合做等值的查询,这也是 B+Tree 索引要比 Hash 表索引有着更广泛的适用场景的原因。
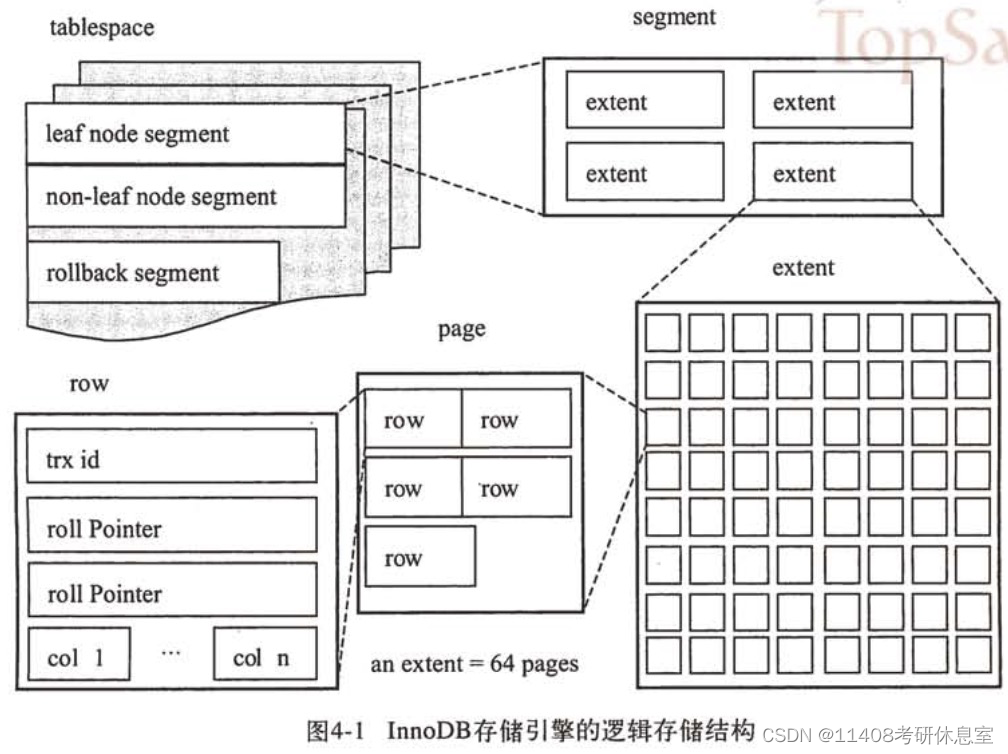
聚簇索引(主键索引)、二级索引(辅助索引)
- 主键索引的 B+Tree 的叶子节点存放的是实际数据,所有完整的用户记录都存放在主键索引的 B+Tree 的叶子节点里;
二级索引的 B+Tree 的叶子节点存放的是主键值,而不是实际数据。 覆盖索引- 在查询时使用了二级索引,如果查询的数据能在二级索引里查询的到(也就是查询的数据是主键值),不需要读取索引中的数据,只需要查一个 B+ 树就能找到数据,那么就不需要回表,这个过程就是覆盖索引。
回表- 如果某个查询语句使用了二级索引,但是查询的数据不是主键值,这时找到对应的叶子节点,获取到主键值后,需要去聚簇索引中获得数据行,就能查询到数据了,这个过程就是回表。
InnoDB 在创建聚簇索引时,会根据不同的场景选择不同的列作为索引:
- 如果有主键,默认会使用主键作为聚簇索引的索引键;
- 如果没有主键,就选择第一个不包含 NULL 值的唯一列作为聚簇索引的索引键;
- 在上面两个都没有的情况下,InnoDB 将自动生成一个隐式自增 id 列作为聚簇索引的索引键;
一张表只能有一个聚簇索引,那为了实现非主键字段的快速搜索,就引出了二级索引
字段特性
主键索引:
- 建立在主键字段上的索引,通常在创建表的时候一起创建,一张表最多只有一个主键索引,索引列的值不允许有空值。
唯一索引:
- 建立在 UNIQUE 字段上的索引,一张表可以有多个唯一索引,索引列的值必须唯一,但是允许有空值。
普通索引:
- 就是建立在普通字段上的索引,既不要求字段为主键,也不要求字段为 UNIQUE。
前缀索引
- 是指对字符类型字段的前几个字符建立的索引,而不是在整个字段上建立的索引,前缀索引可以建立在字段类型为 char、 varchar、binary、varbinary 的列上。使用前缀索引的目的是为了减少索引占用的存储空间,提升查询效率。
单列索引和联合索引
- 建立在单列上的索引称为单列索引,比如主键索引;
- 建立在多列上的索引称为联合索引;
联合索引范围
- 联合索引查询,不代表联合索引中的所有字段都用到了联合索引进行索引查询,可能存在部分字段用到联合索引的 B+Tree,部分字段没有用到联合索引的 B+Tree 的情况。
- 联合索引的最左匹配原则会一直向右匹配直到遇到「范围查询」就会停止匹配。也就是范围查询的字段可以用到联合索引,但是在范围查询字段的后面的字段无法用到联合索引。
注意,对于 >=、<=、BETWEEN、like 前缀匹配的范围查询,并不会停止匹配
select * from t_table where a > 1 and b = 2
单列索引与联合索引区别
- 组成方式:单列索引只包含一列,而联合索引则由多列组成。
- 使用范围:单列索引适用于单列查询,联合索引适用于多列查询
- 索引大小:联合索引的大小通常比单列索引大
- 更新操作:联合索引,如果更新操作涉及到了索引的任何一列,都会导致索引重建,单列索引,只有更新涉及到了该列才会导致索引重建
- 单列索引适用于单列查询,适用于频繁更新的情况;而联合索引适用于多列查询,适用于读操作多、写操作少的情况
联合索引相比单列索引有什么优点
- 联合索引在进行查询过程中,可能索引列就是我们要查询的数据,使用覆盖索引,避免了回表操作,减少IO次数,提高查询性能
最左匹配原则
- 在使用
多列索引时,如果查询中包含索引的第一个列,则可以利用该索引进行搜索;如果查询中不包含索引的第一个列,则无法使用该索引。
索引下推原理
- 一般在联合索引来优化查询,但是,在某些情况下,联合索引并不完全适用于所有的查询条件,于是从 MySQL 5.6 之后使用索引下推
- 可以在联合索引遍历过程中,对联合索引中包含的字段先做判断,直接过滤掉不满足条件的记录,减少回表次数。(在引擎层判断数据是否合法,如果合法直接返回,如果不合法继续判断,减少回表操作)
索引下推原理
- 截断的字段不会在 Server 层进行条件判断,而是会被下推到「存储引擎层」进行条件判断(因为 c 字段的值是在 (a, b, c) 联合索引里的),然后过滤出符合条件的数据后再返回给 Server 层。由于在引擎层就过滤掉大量的数据,无需再回表读取数据来进行判断,减少回表次数,从而提升了性能。
Innodb的B+Tree、BTree、二级索引、MyISAM的B+Tree
Innodb的B+Tree:非叶子节点存放索引值,叶子结点存放数值(索引即文件)BTree:非叶子结点与叶子结点都存放数据二级索引:非叶子结点存放索引值,叶子结点存放的是主键值MyISAM的B+Tree:非叶子结点存放索引值,叶子结点存放指向数据的指针。(索引与文件分开)
索引失效
- 当我们使用左或者左右模糊匹配的时候,也就是 like %xx 或者 like %xx%这两种方式都会造成索引失效;
- 当我们在查询条件中对索引列使用函数,就会导致索引失效。
- 当我们在查询条件中对索引列进行表达式计算,也是无法走索引的。
- MySQL 在遇到字符串和数字比较的时候,会自动把字符串转为数字,然后再进行比较。如果字符串是索引列,而条件语句中的输入参数是数字的话,那么索引列会发生隐式类型转换,由于隐式类型转换是通过 CAST 函数实现的,等同于对索引列使用了函数,所以就会导致索引失效。
- 联合索引要能正确使用需要遵循最左匹配原则,也就是按照最左优先的方式进行索引的匹配,否则就会导致索引失效。
- 在 WHERE 子句中,如果在 OR 前的条件列是索引列,而在 OR 后的条件列不是索引列,那么索引会失效。
MySQL 使用 like “%x“,索引不一定会失效
- 当表中的字段全部都使用到了索引,例如表中只有id和name俩列,id为主键索引,name为二级索引
- 这张表的字段没有「非索引」字段,所以
select *相当于select id,name,然后这个查询的数据都在二级索引的 B+ 树,因为二级索引的 B+ 树的叶子节点包含「索引值+主键值」,所以查二级索引的 B+ 树就能查到全部结果了,这个就是覆盖索引。 - 但是执行计划里的 type 是 index,这代表着是通过全扫描二级索引的 B+ 树的方式查询到数据的,也就是遍历了整颗索引树。

文章总结https://www.xiaolincoding.com/


![[acwing周赛复盘] 第 94 场周赛20230311](https://img-blog.csdnimg.cn/4803447c73444805a85425e045de926f.png)