目录
前言
1、开发中常用的 IDEA 编辑器,如何做到不用每次都重新配置?
2、如何使用 Python 获取视频文件信息?
3、使用 Java 的 try-with-resources 优化代码
4、使用 shell 脚本批量修改服务器某一目录下的文件后缀名称
5、MySQL优化:使用varchar替代char
6、如何升级 ES-7.8.0 的 log4j 版本?
7、spring 自带定时任务的使用
8、Windows 系统如何自定义命令?
9、解决http请求报401,invalid token问题
10、Redis 键过期问题
前言
由于最近比较忙,没有多少时间去写专题的博文,而且在平时工作和学习中,也会产生不少的碎片化知识点或问题。基于目前这些情况,经过一番思考,自己就计划每周进行一次总结梳理,并以博文的形式记录下来,希望提升技术的同时也保持写作能力吧~
目前自己是以 Java 为主的,并且工作需要会使用到许多的流行框架,中间件及工具。另外,自己也对 Python 和其他脚本语言感兴趣,这样的话涉及的技术栈看起来就比较广泛了,就很容易产生多而不精的问题。因此,通过每周的一次碎片化知识总结和梳理,逐步构建起属于自己的知识体系,也可以温故而知新。
那就从三月份开始吧,将平时只躺在笔记里的知识点利用起来!
1、开发中常用的 IDEA 编辑器,如何做到不用每次都重新配置?
工作中可能会遇到 IDEA 需要卸载重装,或者换电脑了去安装 IDEA 等情况,而每次安装 IDEA 就意味着需要重新去做一些配置,比如:设置快捷键、定义字体等格式、设置 maven 仓库位置等。有没有什么方法不用重新配置呢?当然有。
如果自己习惯了以前使用的 IDEA 编辑器设置,此时将之前的设置导出,然后再导入新的 IDEA 就可以避免重新配置 IDEA 的情况,具体操作如下:
<1>. 原 IDEA 编辑器,打开一个项目 => File => Manage IDE Settings => Export Settings...
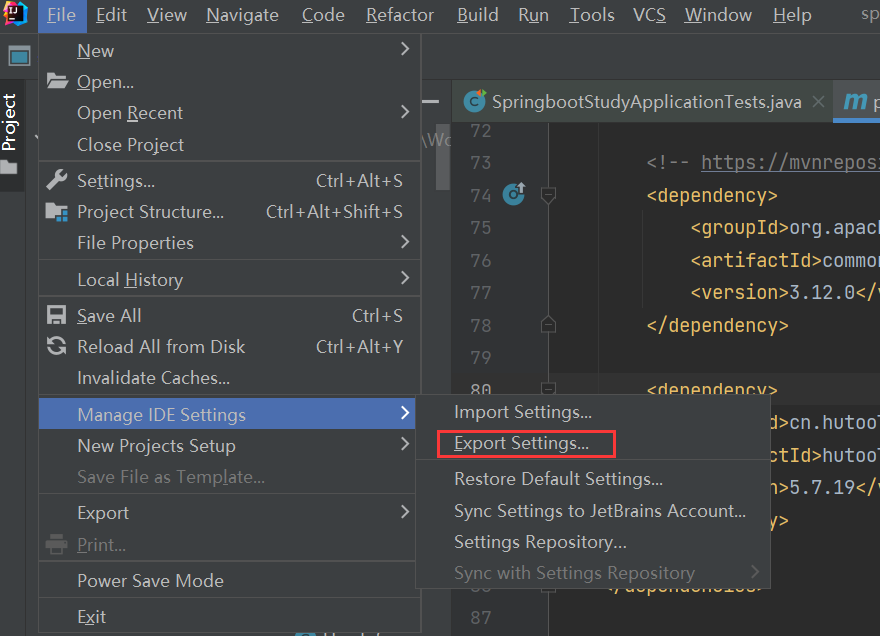
<2>. 根据需求勾选导出的选项,选择导出路径等,默认为settings.zip文件,如下:
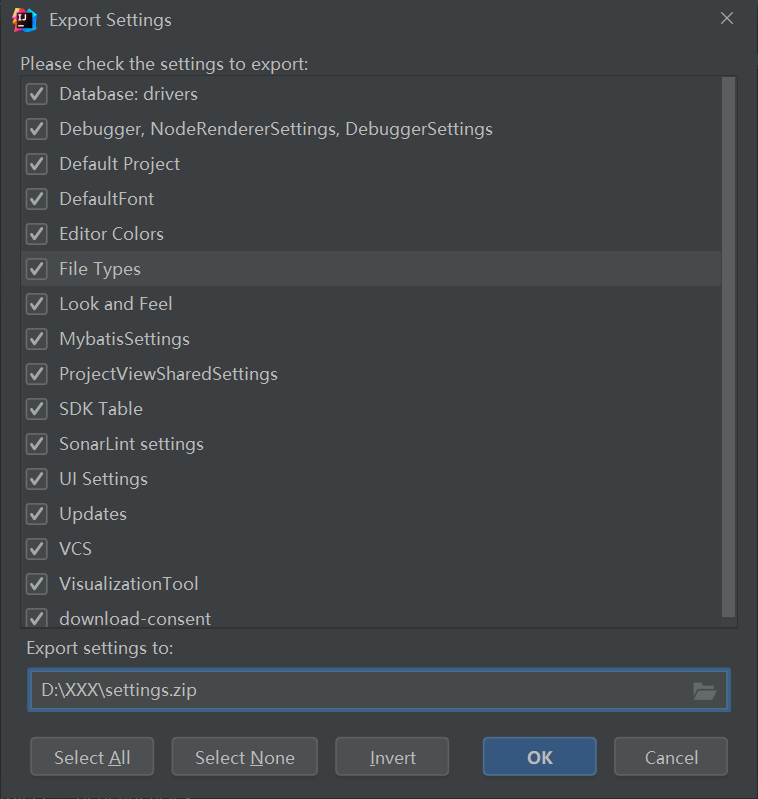
<3>. 重新安装 IDEA 后,选择通过 IDEA 刚开始界面导入settings.zip,也可以先打开某个项目再导入settings.zip。
- 打开idea => Customize => Import Settings => 选择settings.zip。
- 打开idea => 打开项目 => File => Manage IDE Settings => Import Settings => 选择settings.zip。
由此,就可以继续保持之前 IDEA 的设置了。
2、如何使用 Python 获取视频文件信息?
Python 作为一门强大的解释性编程语言,离不开第三方模块的支持。通过 Python 获取视频文件信息,比如视频大小,fps,时长等,需要引入第三方模块 moviepy。
获取视频属性,演示如下:
import os
from moviepy import editor
video_clip = editor.VideoFileClip(r"超级奶爸.mp4")
# 获取宽度和高度
print(video_clip.size)
print(video_clip.w, video_clip.h)
# 获取 fps
print(video_clip.fps)
# 获取时长,单位是秒
print(video_clip.duration)
# 获取大小
size = os.stat(r"超级奶爸.mp4").st_size
print(size)
print(size / 1024 ** 2)此外,该三方模块还可用于一些像剪切,拼接,插入标题等基本操作、视频合成、视频处理、创建高级特效等,如果感兴趣的话,可以通过 moviepy · PyPI 进行深入了解。
3、使用 Java 的 try-with-resources 优化代码
try-with-resource 是 Java7 引入的异常处理机制,相比于 try-catch-finally 语句而言,有以下优点:
- try-with-resource 声明要求其中定义的变量实现 AutoCloseable 接口,这样系统可自动调用它们的 close 方法,从而替代了 finally 中关闭资源的功能。
- try-with-resource 不会屏蔽原始异常信息,而 try-catch-finally 的话,如果在 finally 语句抛了异常则会淹没掉 try 语句的原始异常信息。
- try-with-resource 代码书写起来更加简洁了,非常推荐!
下面通过实现一个简单的文件复制功能,感受下优化效果。
使用 try-catch-finally:
public static void copy1(String src, String dst) {
InputStream in = null;
OutputStream out = null;
try {
in = new FileInputStream(src);
out = new FileOutputStream(dst);
byte[] buff = new byte[1024];
int n;
while ((n = in.read(buff)) >= 0) {
out.write(buff, 0, n);
}
} catch (IOException e) {
e.printStackTrace();
} finally {
if (in != null) {
try {
in.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (out != null) {
try {
out.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}使用 try-with-resource:
public static void copy2(String src, String dst) {
try (InputStream in = new FileInputStream(src);
OutputStream out = new FileOutputStream(dst)) {
byte[] buff = new byte[1024];
int n;
while ((n = in.read(buff)) >= 0) {
out.write(buff, 0, n);
}
} catch (IOException e) {
e.printStackTrace();
}
}感受两种方式的代码,一目了然,使用 try-with-resources 会觉得整个世界清爽多了!!
4、使用 shell 脚本批量修改服务器某一目录下的文件后缀名称
如题描述,实现步骤如下:
<1>. 使用 touch 命令创建一个脚本文件,比如 rename.sh,放在批量修改文件后缀的目录下。
<2>. 使用 vi/vim 命令编辑该脚本:
#!/bin/bash
for i in $(find . -name "*.$1")
do
name=$(echo $i | awk -F ".$1" '{print $1}');
mv $i $name.$2;
done<3>. 保存并退出后,赋予执行权限:chmod +x rename.sh。
<4>. 执行脚本,比如把 .txt 改成 .aaa:
./rename.sh txt aaa5、MySQL优化:使用varchar替代char
有时候设计 MySQL 数据库表的字段类型时,需要考虑的东西有很多,就比如字符串类型的字段,为什么大多数场景下都使用varchar类型呢?
首先,了解下二者的区别:char 是按声明大小存储,不足时补空格,而 varchar 是按数据实际长度存储。这样的话,在节约存储空间方面 varchar 明显优于 char 。其实,到底该使用 varchar 还是 char ?是需要区分场景的!
对于经常被修改的字段,且每次修改的长度都不一样,如果定义成 varchar 类型的话,容易引起"行迁移"现象,这种现象是需要避免发生的!
正常情况下,字段都需要定义成 varchar 类型,如果定义 char 类型的话,由于插入数据时不足会补充空格,而查询操作则需要额外去除掉这些空格才行,不仅浪费存储空间,操作也比较麻烦!
6、如何升级 ES-7.8.0 的 log4j 版本?
背景:因为之前 log4j 出现了严重的漏洞,最近工作中需要排查并替换掉 ES 的 log4j 版本。
操作步骤,如下:
<1>. 升级 jar 包准备,可去 apache 官网下载对应版本。
<2>. 先终止服务器上的 ES 服务,kill -9 进程号。
<3>. 使用 find 命令,查找 ES 安装目录下存在的 log4 j的 jar 包:
[xxw@123456 es]$ find ./elasticsearch-7.8.0/ -name 'log4j*.jar'
./elasticsearch-7.8.0/modules/x-pack-identity-provider/log4j-slf4j-impl-2.11.1.jar
./elasticsearch-7.8.0/modules/x-pack-security/log4j-slf4j-impl-2.11.1.jar
./elasticsearch-7.8.0/modules/x-pack-core/log4j-1.2-api-2.11.1.jar
./elasticsearch-7.8.0/lib/log4j-core-2.11.1.jar
./elasticsearch-7.8.0/lib/log4j-api-2.11.1.jar<4>. 移动这些jar包到临时的备份目录(出现意外时可回滚这些文件)。
<5>. 将新jar包对应替换:
cp log4j-slf4j-impl-2.17.1.jar ./elasticsearch-7.8.0/modules/x-pack-identity-provider/
cp log4j-slf4j-impl-2.17.1.jar ./elasticsearch-7.8.0/modules/x-pack-security/
cp log4j-1.2-api-2.17.1.jar ./elasticsearch-7.8.0/modules/x-pack-core/
cp log4j-core-2.17.1.jar ./elasticsearch-7.8.0/lib/
cp log4j-api-2.17.1.jar ./elasticsearch-7.8.0/lib/<6>. 替换之后,使用 find 命令确认是否替换完成:
[xxw@123456 es]$ find ./elasticsearch-7.8.0/ -name 'log4j*.jar'
./elasticsearch-7.8.0/modules/x-pack-identity-provider/log4j-slf4j-impl-2.17.1.jar
./elasticsearch-7.8.0/modules/x-pack-security/log4j-slf4j-impl-2.17.1.jar
./elasticsearch-7.8.0/modules/x-pack-core/log4j-1.2-api-2.17.1.jar
./elasticsearch-7.8.0/lib/log4j-core-2.17.1.jar
./elasticsearch-7.8.0/lib/log4j-api-2.17.1.jar<7>. 重启 ES 服务,并进行验证 ES 服务是否正常运行。
启动方式有以下2种:
- 窗口启动:./elasticsearch-7.8.0/bin/elasticsearch
- 后台启动:./elasticsearch-7.8.0/bin/elasticsearch -d
查看进程验证:jps 或 ps -ef|grep elasticsearch
发送请求验证:curl http://宿主机IP:配置端口号/
7、spring 自带定时任务的使用
背景:项目使用的是 springboot,需要用到定时任务去执行某项重复操作。由于这个操作的需求简单,没必要引入 xxl-job 中间件(主要是考虑中间件的部署和维护成本高),于是就采用 spring 框架自带的定时任务实现。做法也很简单,主要有两步。
第一步,自定义 Job 类和 task 方法,演示如下:
@Component
@Slf4j
public class OpearJob {
/**
* 定时任务,每10分钟执行一次
*/
@Scheduled(cron = "0 0/10 * * * ?")
public void processDataTask() {
log.info("OpearJob.processDataTask() | 当前Job执行时间:{}"
, new SimpleDateFormat("yyyyMMddHHmmss").format(new Date()));
// 执行逻辑......
}
}第二步,在启动类添加注解 @EnableScheduling。
8、Windows 系统如何自定义命令?
Windows 是平时办公中经常会使用的操作系统,通过 win + r 快捷键出现的弹框里输入 cmd 命令,就可以召唤出黑窗口。
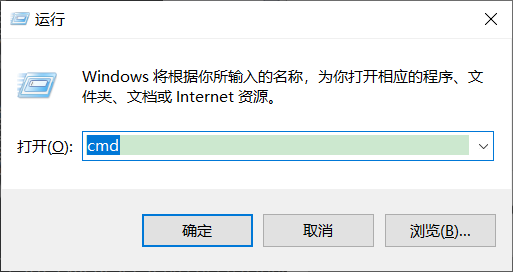
按照这种方式,是否也可以把桌面上一大堆的应用程序快捷键给干掉,然后通过自定义的命令召唤并打开对应的应用程序呢?当然可以了,只不过要进行一些设置。
<1>. 在任意磁盘分区下新建文件,可命名为 shortcut,这里我选择的是F盘。
<2>. 将文件或软件的快捷方式移动到 shortcut 文件夹下,并改个好记的名字(如微信:wx)。

<3>. 打开高级系统设置-环境变量设置,在系统变量的 Path 下添加 shortcut 路径(本人的是F:\shortcut\)。
<4>. 设置完成后,win+r,如键入wx即可打开微信应用程序了。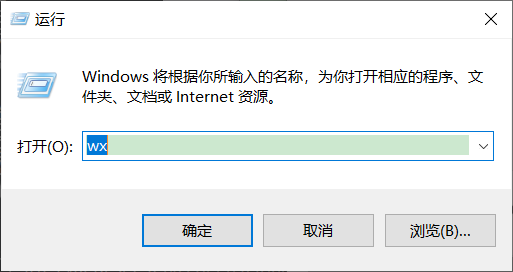
通过这一通操作,Windows 桌面就干净多了,程序员应该如此嘛,哈哈哈~~
9、解决http请求报401,invalid token问题
背景:之前使用 postman 调用请求接口一直都是正常的,某天请求时突然出现了 401 结果码,看上去是 token 失效了?然而这个项目并不会使用到 token,首次遇到这种情况就感到很疑惑!
{
"code": "401",
"msg": "invalid token"
}当时这个问题困扰我了一天多,最终被排查到原因并得以解决。
第一阶段,问度娘。度娘上虽然都是描述 token 失效问题,但大家遇到的情况和我的完全不一样,刚开始尝试了其中的一些方法,均不奏效!!
第二阶段,静下来思考 token 的可能来源。其实,token 是一串服务器返回的随机字符串,用于访问服务器的身份令牌,如果接口请求中携带的 token 过期,则阻止用户访问没有登录的页面。
当前项目的接口请求并不会携带 token,那么这个 token 会不会是某个 jar 包里带进来的呢,为了验证这个想法,需要对项目引入的 jar 包做下排查,排查关键字有 token、auth、shiro 等,确实发现了几个可疑 jar 包,如下:
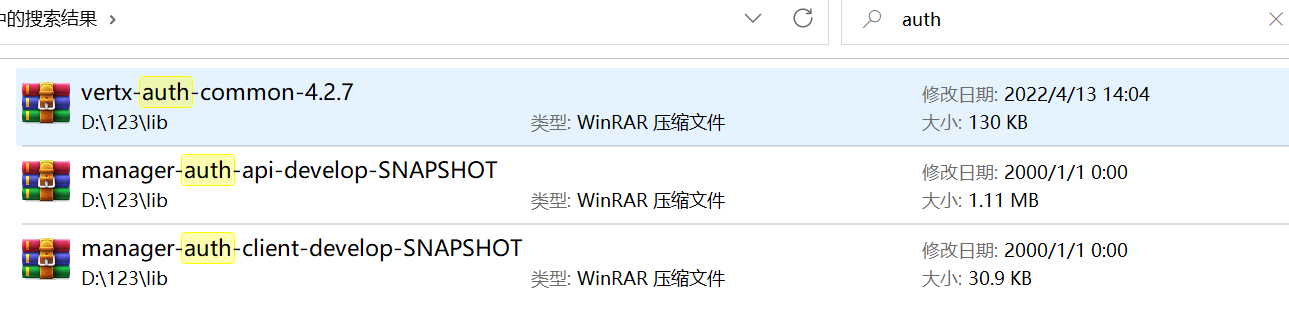
接着,尝试排除掉这些 jia 包,我通过 IDEA 下载了 maven helper 插件,通过依赖树可找到这些 jar 包,如下:
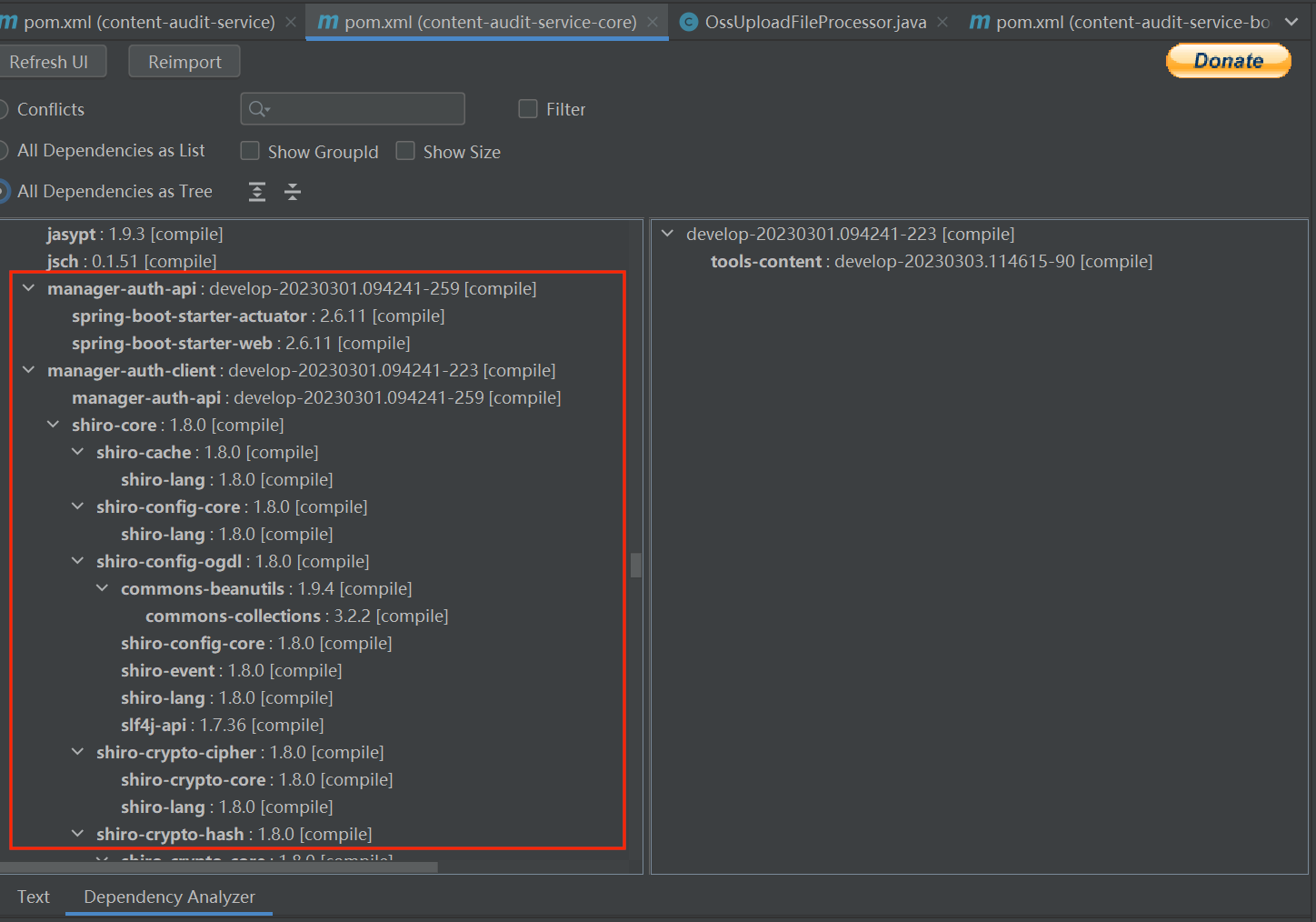
右键选择 "Exclude",就可以在 pom.xml 排除相关的 jar 包了,如下:

排除 jar 包后,重新编译和启动项目,发送请求就正常了,如下:
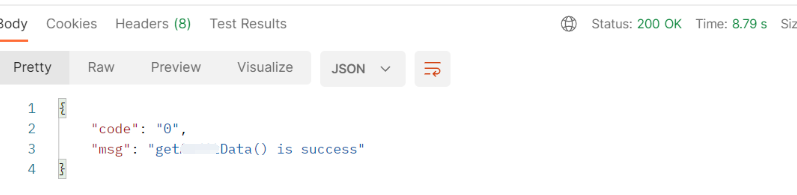
就此原因就找到了,是因为引入的工具包里包含了验证 token 的 jar 包!!!
10、Redis 键过期问题
这一部分会涉及到,如何设置、查询、删除过期键等基本操作?过期键删除策略有哪些及 Redis 使用何种策略?持久化功能和复制功能中是如何处理键过期问题的?Redis 未通过 过期键删除策略 删除过期键有可能导致内存满的问题,该怎么解决呢?
10.1 设置、查询、取消过期键
命令如下:
// 设置键在指定时间 秒数 或 毫秒数 之后到期/过期
SET key value ex seconds
EXPIRE key seconds
PEXPIRE key milliseconds
// 设置在指定 时间戳(Unix时间戳格式) 之后键到期/过期
EXPIREAT key seconds-timestamp
PEXPIREAT key milliseconds-timestamp
// 获取键的剩余到期时间(秒数 或 毫秒数)
TTL key
PTTL key
// 取消指定键的过期时间,得永生
PERSIST key10.2 过期键策略
如果 Redis 数据库的键过期时间到了,会有三种删除策略可供选择,优缺点从内存和 CPU 时间角度考虑:
第一种,定时删除:
概念:创建定时器 timer,键过期时间到来时,立即删除过期的键。
优点:会尽快释放内存。
缺点:在不要求内存但要求 CPU 时间的情况下,创建 timer 并执行删除过期键的操作会占用 CPU 时间,对服务器响应时间和吞吐量造成影响。(如:有大量的命令请求等待服务器处理时,服务器会优先将 CPU 的时间放在处理请求上面,而通过这种策略删除数量比较多的过期键时,明显是不合理的)
第二种,惰性删除:
概念:只有 get 键时才去检查这个键是否过期,过期的话会被删除。
优点:对 CPU 较友好。
缺点:很明显对内存不友好,大量过期无用的键被积压会占用大量内存,对于依赖内存的 Redis 服务器来说是很严重的问题,甚至可能会造成内存泄露。
第三种,定期删除:
概念:可以理解为介于定时删除和惰性删除的一种折中策略。
难点:定期删除策略要控制好执行时长和频率,否则可以会退化成定时删除策略或者惰性策略。
第一、三种是一种主动删除策略,而第二种是被动删除策略,实际上 Redis 服务器使用的是第二、三种键过期删除策略。
定期删除时,Redis 默认每个 100ms 检查,有过期 Key 则删除。需要说明的是,Redis 不是每个 100ms 将所有的 Key 检查一次,而是随机抽取进行检查。如果只采用定期删除策略,会导致很多 Key 到时间没有删除,这样惰性删除派上用场。
10.3 持久化功能和复制功能中是如何处理键过期问题的?
RDB持久化:
- 生成RDB文件:通过SAVE或BGSAVE命令生成RDB文件时,会检查键是否过期,过期的键不会存放到RDB文件中。
- 载入RDB文件:载入该文件时也会检查键是否过期,过期不会被放到RDB文件中。
AOF持久化:
- AOF文件写入:
- 若没有通过 过期删除策略 删除过期的键,该过期键会被写入到 AOF 文件。
- 若过期删除策略删除了过期键,AOF 文件写入时通过del命令显式的记录并放到 AOF 文件中。
- AOF文件重写:
- 检查所有的键是否存在过期,过期的键不会被重写到AOF文件中。
复制:
比如:存在一对主从服务器,在进行交互的时候,过期键的删除是主服务器控制的。
- 主服务器的数据库存在过期键时会被删除,并通过del命令通知所有的从服务器,需要删除哪些过期键。
- 从服务器存在过期键,没有收到主服务器的告知,会无视过期键,将它们等同于正常的键对待,如果有客户端请求从服务器,会正常操作该过期键。
- 从服务器接收到主服务器del命令告知后,才会删除过期键。
10.4 内存淘汰策略
如果 Redis 的过期键删除策略未生效,会导致内存中的数据越来越多,可能出现内存爆满的情况,内存满了之后该怎么办呢?Redis 提供了以下六种内存淘汰策略:
设置过期时间的键空间移除
- volatile-lru:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,移除最近最少使用的 Key。这种情况一般是把 Redis 既当缓存,又做持久化存储的时候才用。(不推荐)
- volatile-random:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,随机移除某个 Key。(依然不推荐)
- volatile-ttl:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,有更早过期时间的 Key 优先移除。(不推荐)
全局性的键空间移除
- noeviction:当内存不足以容纳新写入数据时,新写入操作会报错。
- allkeys-lru:当内存不足以容纳新写入数据时,在键空间中,移除最近最少使用的 Key。(推荐使用,目前项目在用这种)(最近最少使用算法)
- allkeys-random:当内存不足以容纳新写入数据时,在键空间中,随机移除某个 Key。(应该也没人用吧,你不删最少使用 Key,去随机删)
#在 redis.conf 中开启内存淘汰策略配置:
maxmemory-policy volatile-lru三月第一周总结梳理,就到这~