目录
- elasticsearch
- ELK技术栈
- Lucene与Elasticsearch关系
- 为什么不是其他搜索技术?
- Elasticsearch核心概念
- Cluster:集群
- Node:节点
- Shard:分片
- Replia:副本
- 全文检索
- 倒排索引
- 正向和倒排
- es的一些概念
- 文档和字段
- 索引和映射
- mysql与elasticsearch
- ES逻辑设计(文档-->类型-->索引)
- docker安装elasticsearch(单机)
- Postman客户端工具
- kibana
- 索引操作
- 新增
- 查询索引配置
- 更新索引
- 删除索引
- 映射管理
- 映射介绍
- 字段数据类型
- 映射(索引库)参数
- 创建映射
- 查询映射
- 修改映射
- 删除映射
- 总结
- 文档操作
- 创建文档
- 查询文档
- 删除文档
- 修改文档
- 全量修改
- 增量修改
- 总结
- Elasticsearch之查询的两种方式
- 查询字符串(一般不用)
- 结构化查询
- match查询
- match_all查询全部
- match_phrase短语查询
- match_phrase_prefix(最左前缀查询)
- multi_match(多字段查询)
- match系列小结
- term查询
- 查询排序sort
- 不是什么数据类型都能排序
- 分页查询from/size
- 布尔查询bool
- must
- should
- must_not
- filter
- 总结
- 查询结果过滤
- 结果过滤:_source
- 高亮查询
- 默认高亮显示
- 自定义高亮显示
- 聚合函数
- avg
- max
- min
- sum
- 分组查询
- 集群搭建,数据分片
- ES集群相关概念
- docker搭建ek集群
elasticsearch
Elasticsearch 是一个基于Lucene的分布式搜索和分析引擎。
ES是elaticsearch简写, Elasticsearch是一个开源的高扩展的分布式全文检索引擎,它可以近乎实时的存储、检索数据;本身扩展性很好,可以扩展到上百台服务器,处理PB级别的数据。
Elasticsearch使用Java开发,在Apache许可条款下开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便
使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的RESTful API来隐藏Lucene的复杂性,使得全文检索变得简单
设计用途:用于分布式全文检索,通过HTTP使用JSON进行数据索引,速度快
ELK技术栈
elasticsearch结合kibana、Logstash、Beats,也就是elastic stack(ELK)。被广泛应用在日志数据分析、实时监控等领域:

而elasticsearch是elastic stack的核心,负责存储、搜索、分析数据。
Lucene与Elasticsearch关系
-
elasticsearch底层是基于lucene来实现的。
-
Lucene是一个Java语言的搜索引擎类库,是Apache公司的顶级项目,由DougCutting于1999年研发。官网地址:https://lucene.apache.org/ 。

elasticsearch的发展历史:
- 2004年Shay Banon基于Lucene开发了Compass
- 2010年Shay Banon 重写了Compass,取名为Elasticsearch。

为什么不是其他搜索技术?
目前比较知名的搜索引擎技术排名:
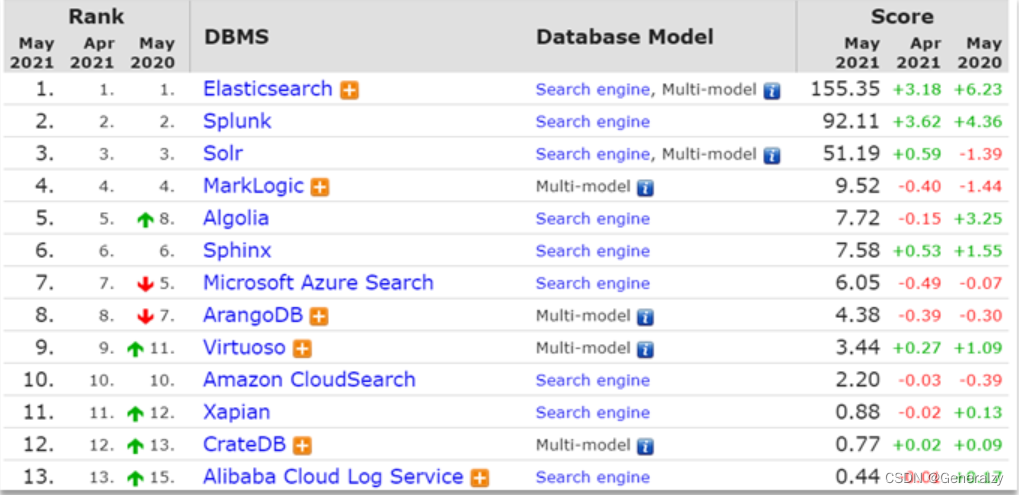
虽然在早期,Apache Solr是最主要的搜索引擎技术,但随着发展elasticsearch已经渐渐超越了Solr,独占鳌头,Elasticsearch 与 Solr 的比较总结:
- 二者安装都很简单
- Solr 利用 Zookeeper 进行分布式管理,而 Elasticsearch 自身带有分布式协调管理功能
- Solr 支持更多格式的数据,而 Elasticsearch 仅支持json文件格式
- Solr 官方提供的功能更多,而 Elasticsearch 本身更注重于核心功能,高级功能多有第三方插件提供
- Solr 在传统的搜索应用中表现好于 Elasticsearch,但在处理实时搜索应用时效率明显低于 Elasticsearch
- Solr 是传统搜索应用的有力解决方案,但 Elasticsearch 更适用于新兴的实时搜索应用
Elasticsearch核心概念
Cluster:集群
ES可以作为一个独立的单个搜索服务器。不过,为了处理大型数据集,实现容错和高可用性,ES可以运行在许多互相合作的服务器上。这些服务器的集合称为集群。
Node:节点
形成集群的每个服务器称为节点。
Shard:分片
-
当有大量的文档时,由于内存的限制、磁盘处理能力不足、无法足够快的响应客户端的请求等,一个节点可能不够。这种情况下,数据可以分为较小的分片。每个分片放到不同的服务器上。
-
当你查询的索引分布在多个分片上时,ES会把查询发送给每个相关的分片,并将结果组合在一起,而应用程序并不知道分片的存在。即:这个过程对用户来说是透明的。
Replia:副本
- 为提高查询吞吐量或实现高可用性,可以使用分片副本。
- 副本是一个分片的精确复制,每个分片可以有零个或多个副本。
- ES中可以有许多相同的分片,其中之一被选择更改索引操作,这种特殊的分片称为主分片。
- 当主分片丢失时,如:该分片所在的数据不可用时,集群将副本提升为新的主分片。
全文检索
- 全文检索就是对一篇文章进行索引,可以根据关键字搜索,类似于mysql里的like语句。
- 全文索引就是把内容根据词的意义进行分词,然后分别创建索引,例如”今日是周日我们出去玩” 可能会被分词成:“今天“,”周日“,“我们“,”出去玩“ 等token,这样当你搜索“周日” 或者 “出去玩” 都会把这句搜出来。
倒排索引
倒排索引中有两个非常重要的概念:
- 文档(
Document):用来搜索的数据,其中的每一条数据就是一个文档。例如一个网页、一个商品信息 - 词条(
Term):对文档数据或用户搜索数据,利用某种算法分词,得到的具备含义的词语就是词条。例如:我是中国人,就可以分为:我、是、中国人、中国、国人这样的几个词条
创建倒排索引是对正向索引的一种特殊处理,流程如下:
- 将每一个文档的数据利用算法分词,得到一个个词条
- 创建表,每行数据包括词条、词条所在文档id、位置等信息
- 因为词条唯一性,可以给词条创建索引,例如hash表结构索引
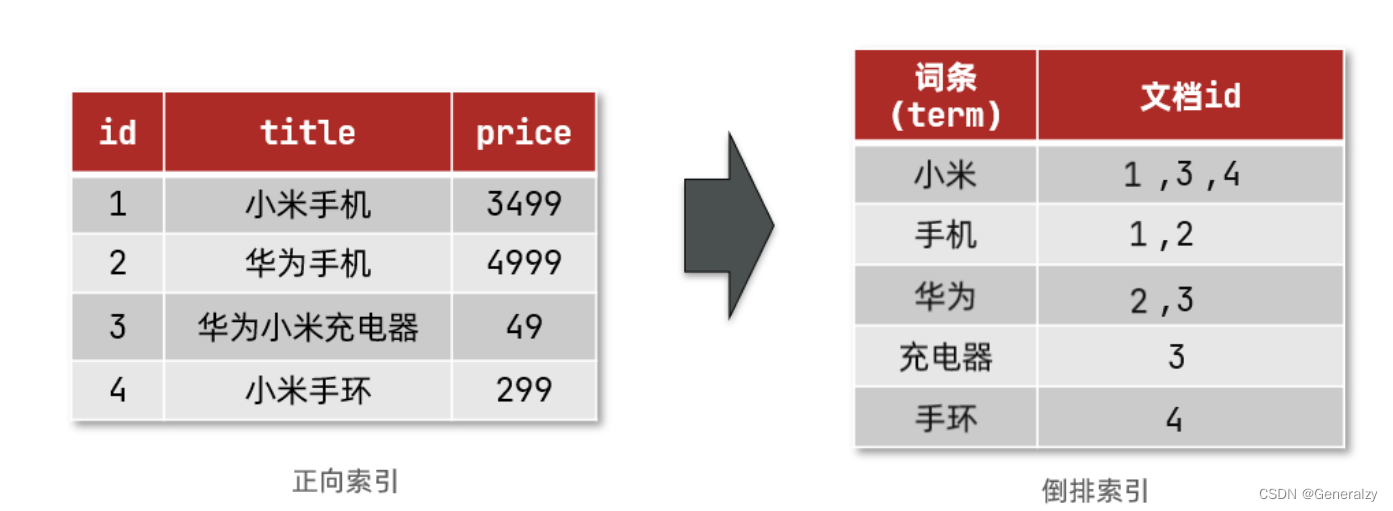
倒排索引的搜索流程如下(以搜索"华为手机"为例):
1)用户输入条件"华为手机"进行搜索。
2)对用户输入内容分词,得到词条:华为、手机。
3)拿着词条在倒排索引中查找,可以得到包含词条的文档id:1、2、3。
4)拿着文档id到正向索引中查找具体文档。
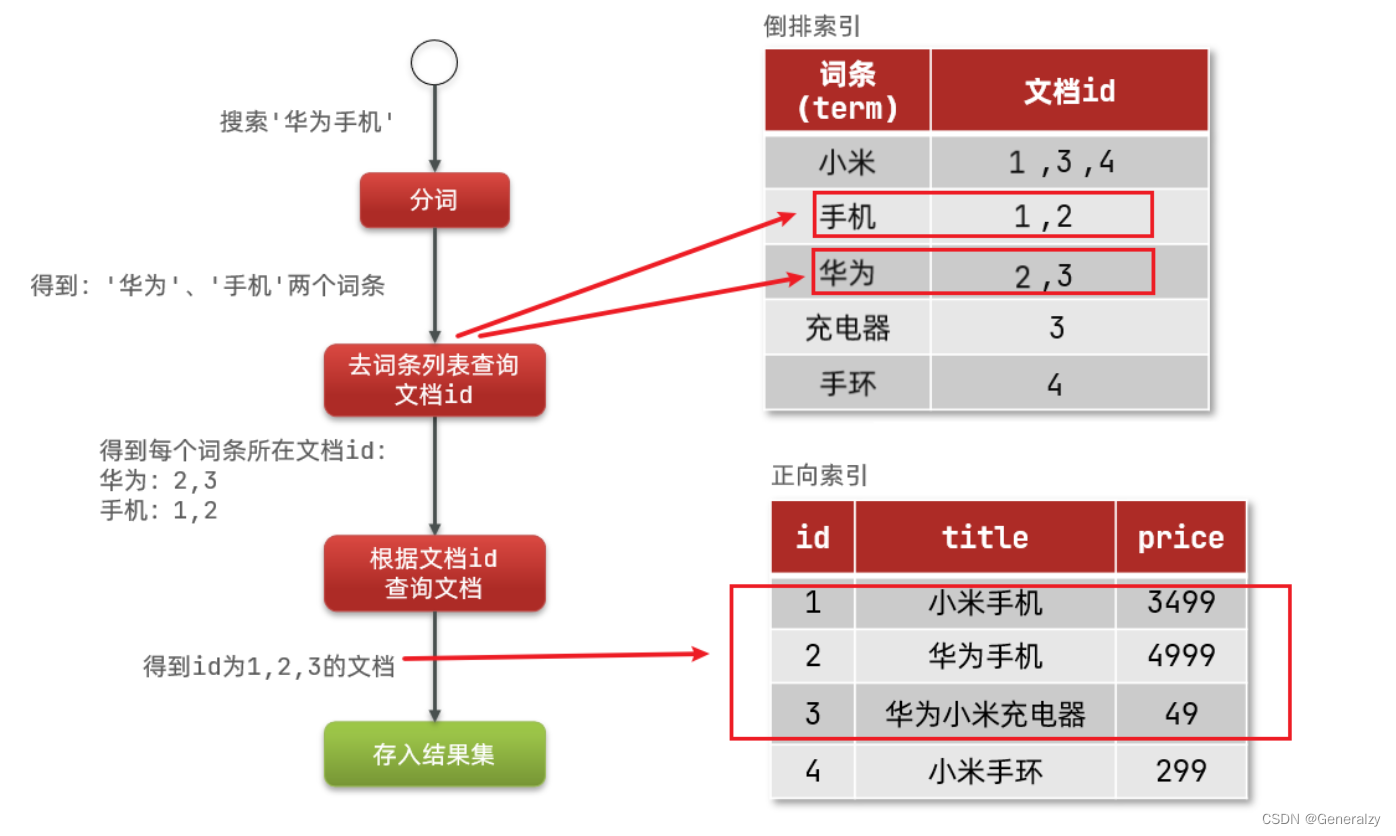
虽然要先查询倒排索引,再查询倒排索引,但是无论是词条、还是文档id都建立了索引,查询速度非常快!无需全表扫描。
正向和倒排
-
正向索引是最传统的,根据id索引的方式。但根据词条查询时,必须先逐条获取每个文档,然后判断文档中是否包含所需要的词条,是根据文档找词条的过程。
-
而倒排索引则相反,是先找到用户要搜索的词条,根据词条得到保护词条的文档的id,然后根据id获取文档。是根据词条找文档的过程。
那么两者方式的优缺点是什么呢?
正向索引:
- 优点:
- 可以给多个字段创建索引
- 根据索引字段搜索、排序速度非常快
- 缺点:
- 根据非索引字段,或者索引字段中的部分词条查找时,只能全表扫描。
倒排索引:
- 优点:
- 根据词条搜索、模糊搜索时,速度非常快
- 缺点:
- 只能给词条创建索引,而不是字段
- 无法根据字段做排序
es的一些概念
elasticsearch中有很多独有的概念,与mysql中略有差别,但也有相似之处。
文档和字段
elasticsearch是面向文档(Document)存储的,可以是数据库中的一条商品数据,一个订单信息。文档数据会被序列化为json格式后存储在elasticsearch中:

而Json文档中往往包含很多的字段(Field),类似于数据库中的列。
索引和映射
索引(Index),就是相同类型的文档的集合。
例如:
- 所有用户文档,就可以组织在一起,称为用户的索引;
- 所有商品的文档,可以组织在一起,称为商品的索引;
- 所有订单的文档,可以组织在一起,称为订单的索引;

因此,我们可以把索引当做是数据库中的表。
数据库的表会有约束信息,用来定义表的结构、字段的名称、类型等信息。因此,索引库中就有映射(mapping),是索引中文档的字段约束信息,类似表的结构约束。
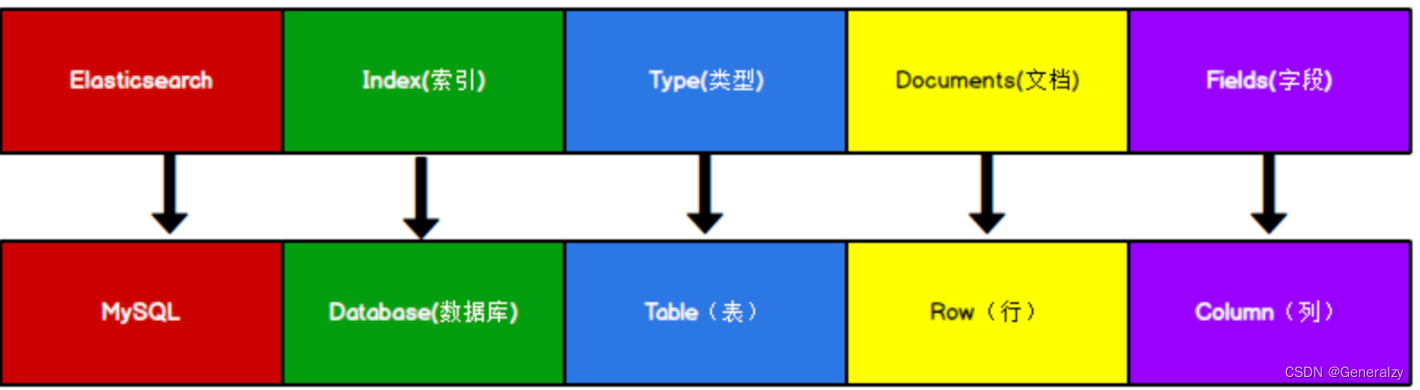
mysql与elasticsearch
我们统一的把mysql与elasticsearch的概念做一下对比:
| MySQL | Elasticsearch | 说明 |
|---|---|---|
| Table | Index | 索引(index),就是文档的集合,类似数据库的表(table) |
| Row | Document | 文档(Document),就是一条条的数据,类似数据库中的行(Row),文档都是JSON格式 |
| Column | Field | 字段(Field),就是JSON文档中的字段,类似数据库中的列(Column) |
| Schema | Mapping | Mapping(映射)是索引中文档的约束,例如字段类型约束。类似数据库的表结构(Schema) |
| SQL | DSL | DSL是elasticsearch提供的JSON风格的请求语句,用来操作elasticsearch,实现CRUD |
两者各自有自己的擅长支出:
-
Mysql:擅长事务类型操作,可以确保数据的安全和一致性
-
Elasticsearch:擅长海量数据的搜索、分析、计算
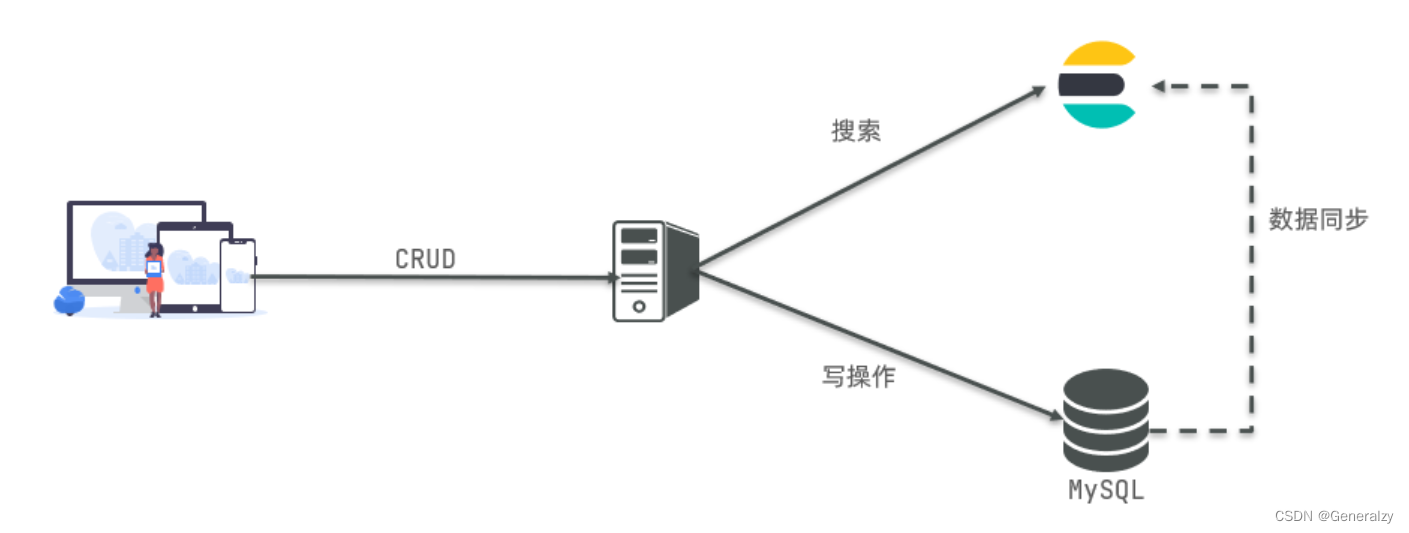
因此在企业中,往往是两者结合使用:
- 对安全性要求较高的写操作,使用mysql实现
- 对查询性能要求较高的搜索需求,使用elasticsearch实现
- 两者再基于某种方式,实现数据的同步,保证一致性
ES逻辑设计(文档–>类型–>索引)
- 一个索引类型中,包含多个文档,比如说文档1,文档2。
- 当我们索引一篇文档时,可以通过这样的顺序找到它:索引▷类型▷文档ID,通过这个组合我们就能索引到某个具体的文档。注意:ID不必是整数,实际上它是个字符串。
docker安装elasticsearch(单机)
- 创建一个es专用网络
docker network create es-net
- 拉取镜像
# 拉取镜像
docker pull elasticsearch:7.17.5
docker pull kibana:7.17.5
- 建立对应文件夹
mkdir /elasticsearch
mkdir logs data plugins
# 不给权限会报错
chmod -R 777 $PWD
- 运行es
docker run -d \
--name es \
-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \
-e "discovery.type=single-node" \
-v /elasticsearch/data:/usr/share/elasticsearch/data \
-v /elasticsearch/logs:/usr/share/elasticsearch/logs \
-v /elasticsearch/plugins:/usr/share/elasticsearch/plugins \
--privileged=true \
--restart=always \
--network es-net \
-p 9200:9200 \
-p 9300:9300 \
elasticsearch:7.17.5
命令解释:
-e “cluster.name=es-docker-cluster”:设置集群名称
-e “http.host=0.0.0.0”:监听的地址,可以外网访问
-e “ES_JAVA_OPTS=-Xms512m -Xmx512m”:内存大小
-e “discovery.type=single-node”:非集群模式
-v es-data:/usr/share/elasticsearch/data:挂载逻辑卷,绑定es的数据目录
-v es-logs:/usr/share/elasticsearch/logs:挂载逻辑卷,绑定es的日志目录
-v es-plugins:/usr/share/elasticsearch/plugins:挂载逻辑卷,绑定es的插件目录
–privileged:授予逻辑卷访问权
–network es-net :加入一个名为es-net的网络中
-p 9200:9200:端口映射配置
- 连接es验证
- 接着部署kibana
docker run -d \
--name kibana \
-e ELASTICSEARCH_HOSTS=http://es:9200 \
--network=es-net \
--restart=always \
-p 5601:5601 \
kibana:7.17.5
参数解释:
–network es-net :加入一个名为es-net的网络中,与elasticsearch在同一个网络中
-e ELASTICSEARCH_HOSTS=http://es:9200":设置elasticsearch的地址,因为kibana已经与elasticsearch在一个网络,因此可以用容器名直接访问elasticsearch
-p 5601:5601:端口映射配置
kibana启动一般比较慢,需要多等待一会,可以通过命令:docker logs -f kibana查看日志。
- ik分词器安装
# 进入容器
docker exec -it elasticsearch /bin/bash
# 在线安装(可能会因为网络错误安装不上,反正我是下载不下来)
./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.17.5/elasticsearch-analysis-ik-7.17.5.zip
或去官网下载ik分词器压缩包:elasticsearch-analysis-ik-7.17.5.zip
上传到es容器的插件数据卷中:/elasticsearch/plugins,解压到ik文件夹中,重启容器docker restart es.
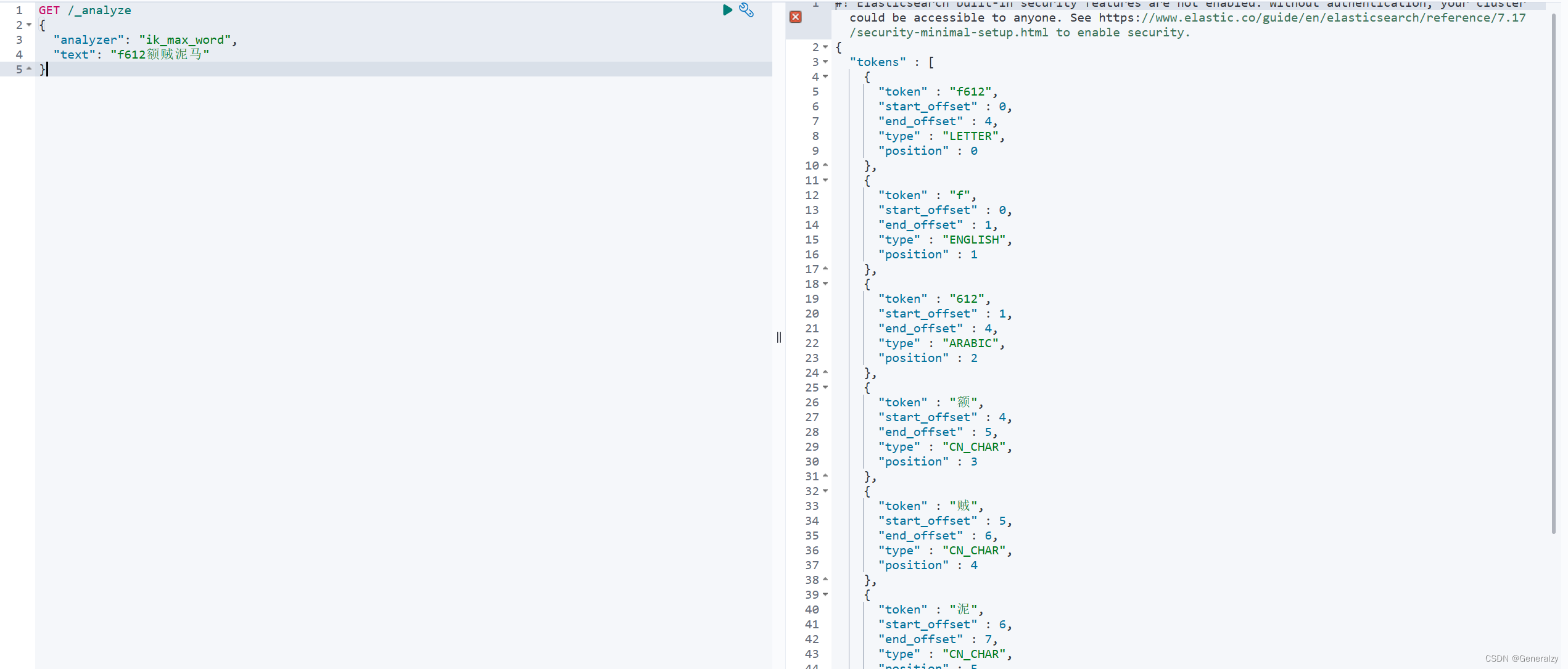
- 测试
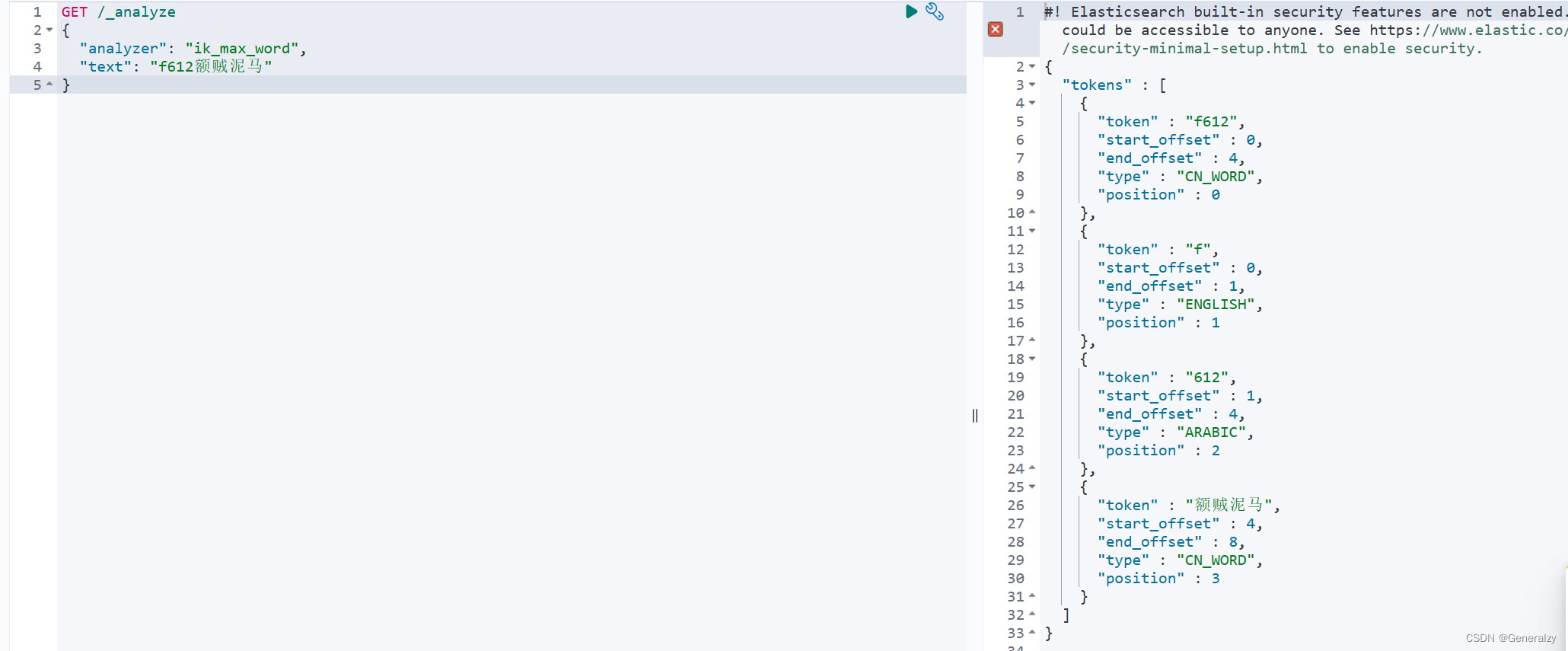
GET /_analyze
{
"analyzer": "ik_max_word",
"text": "f612额贼泥马"
}
如果需要扩展词汇,打开IK分词器config目录,在IKAnalyzer.cfg.xml配置文件内容添加:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 *** 添加扩展词典-->
<entry key="ext_dict">mywords.dic</entry>
</properties>
新建一个 mywords.dic,可以参考config目录下复制一个配置文件进行修改:
f612
额贼泥马
停用词词典同理,需要新增一个dic文件,然后写入禁止使用的词语,然后加入xml配置文件。
Postman客户端工具
如果直接通过浏览器向 Elasticsearch 服务器发请求,那么需要在发送的请求中包含
HTTP 标准的方法,而 HTTP 的大部分特性且仅支持 GET 和 POST 方法。所以为了能方便地进行客户端的访问,可以使用 Postman 软件Postman 是一款强大的网页调试工具,提供功能强大的 Web API 和 HTTP 请求调试。
软件功能强大,界面简洁明晰、操作方便快捷,设计得很人性化。 Postman 中文版能够发送任何类型的 HTTP 请求 (GET, HEAD, POST, PUT…),不仅能够表单提交,且可以附带任意类型请求体。
kibana
Kibana 是一款开源的数据分析和可视化平台,它是 Elastic Stack 成员之一,设计用于和 Elasticsearch 协作。
可以使用 Kibana 对 Elasticsearch 索引中的数据进行搜索、查看、交互操作。
可以很方便的利用图表、表格及地图对数据进行多元化的分析和呈现
索引操作
对比关系型数据库,创建索引就等同于创建数据库。
ES 里的 Index 可以看做一个库,而 Types 相当于表, Documents 则相当于表的行。这里 Types 的概念已经被逐渐弱化, Elasticsearch 6.X 中,一个 index 下已经只能包含一个type, Elasticsearch 7.X 中, Type 的概念已经被删除了。
新增
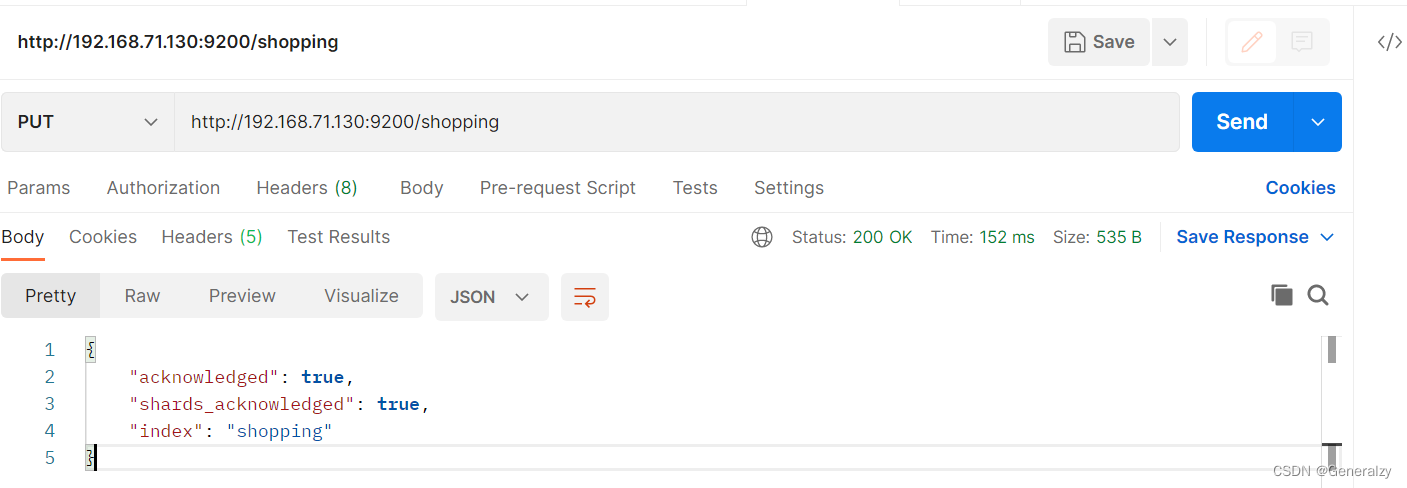
#新建一个lqz2的索引,索引分片数量为5,索引副本数量为1
# 如果不携带任何参数的请求,则默认创建主分片一个,副本分片一个
PUT lqz2
{
"settings": {
"index":{
"number_of_shards":5,
"number_of_replicas":1
}
}
}
'''
number_of_shards
每个索引的主分片数,默认值是 5 。这个配置在索引创建后不能修改。
number_of_replicas
每个主分片的副本数,默认值是 1 。对于活动的索引库,这个配置可以随时修改。
'''
查询索引配置
#获取lqz2索引的配置信息
GET lqz2/_settings
#获取所有索引的配置信息
GET _all/_settings
#同上
GET _settings
#获取lqz和lqz2索引的配置信息
GET lqz,lqz2/_settings
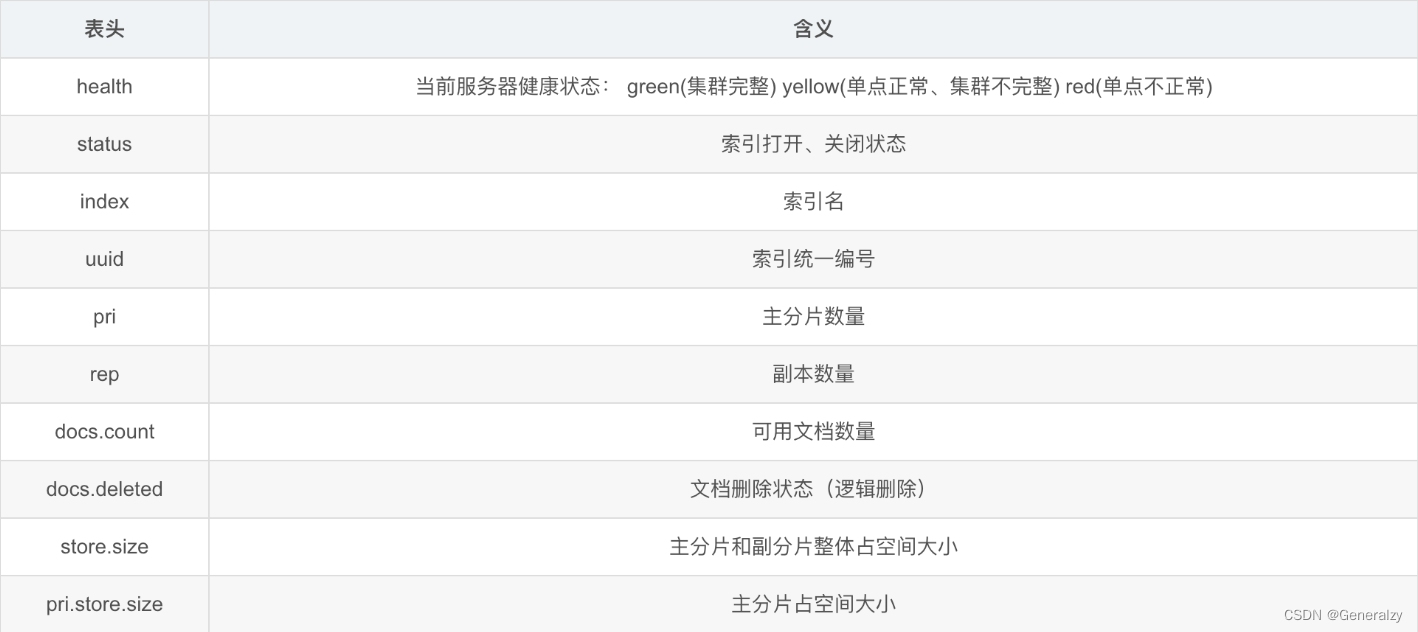
# 查看所有索引
GET _cat/indices?v
# 查看单个索引
GET shopping
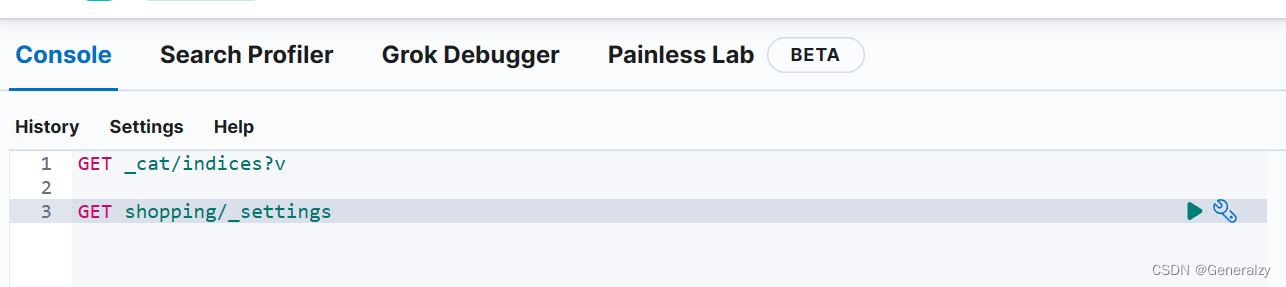
更新索引
#修改索引副本数量为2
PUT lqz/_settings
{
"number_of_replicas": 2
}
#如遇到报错:cluster_block_exception,因为
#这是由于ES新节点的数据目录data存储空间不足,导致从master主节点接收同步数据的时候失败,此时ES集群为了保护数据,会自动把索引分片index置为只读read-only
PUT _all/_settings
{
"index": {
"blocks": {
"read_only_allow_delete": false
}
}
}
删除索引
#删除lqz索引
DELETE lqz
映射管理
在Elasticsearch 6.0.0或更高版本中创建的索引只包含一个mapping type。 在5.x中使用multiple mapping types创建的索引将继续像以前一样在Elasticsearch 6.x中运行。 Mapping types将在Elasticsearch 7.0.0中完全删除
映射介绍
在创建索引的时候,可以预先定义字段的类型及相关属性
Es会根据Json数据源的基础类型,猜测你想要映射的字段,将输入的数据转变成可以搜索的索引项。
Mapping是我们自己定义的字段数据类型,同时告诉es如何索引数据及是否可以被搜索
作用:会让索引建立的更加细致和完善
创建映射可以在索引刚创建的时候创建,也可以在索引创建完了之后再接着去创建,并且创建完了之后可以不停的追加映射,但是不能修改原有的映射
字段数据类型
string类型:text,keyword
数字类型:long,integer,short,byte,double,float
日期类型:data
布尔类型:boolean
binary类型:binary
复杂类型:object(实体,对象),nested(列表)
geo类型:geo-point,geo-shape(地理位置)
专业类型:ip,competion(搜索建议)
映射(索引库)参数
| 属性 | 描述 | 适合类型 |
|---|---|---|
| store | 值为yes表示存储,no表示不存储,默认为yes | all |
| index | yes表示分析,no表示不分析,默认为true | text |
| null_value | 如果字段为空,可以设置一个默认值,比如"NA"(传过来为空,不能搜索,na可以搜索) | all |
| analyzer | 可以设置索引和搜索时用的分析器,默认使用的是standard分析器,还可以使用whitespace,simple。都是英文分析器 | all |
| include_in_all | 默认es为每个文档定义一个特殊域_all,它的作用是让每个字段都被搜索到,如果想让某个字段不被搜索到,可以设置为false | all |
| format | 时间格式字符串模式 | date |
| properties | 该字段的子字段 | all |
创建映射
text类型会取出词做倒排索引,keyword不会被分词,原样存储,原样匹配
mapping类型一旦确定,以后就不能修改了
语法:
- 请求方式:PUT
- 请求路径:
/索引,可以自定义 - 请求参数:mapping映射
#6.x的版本没问题
PUT books
{
"mappings": {
"book":{
"properties":{
"title":{
"type":"text",
"analyzer": "ik_max_word"
},
"price":{
"type":"integer"
},
"addr":{
"type":"keyword"
},
"company":{
"properties":{
"name":{"type":"text"},
"company_addr":{"type":"text"},
"employee_count":{"type":"integer"}
}
},
"publish_date":{"type":"date","format":"yyy-MM-dd"}
}
}
}
}
7.x版本以后
PUT books
{
"mappings": {
"properties":{
"title":{
"type":"text",
"analyzer": "ik_max_word"
},
"price":{
"type":"integer"
},
"addr":{
"type":"keyword"
},
"company":{
"properties":{
"name":{"type":"text"},
"company_addr":{"type":"text"},
"employee_count":{"type":"integer"}
}
},
"publish_date":{"type":"date","format":"yyy-MM-dd"}
}
}
}
查询映射
基本语法:
-
请求方式:GET
-
请求路径:
/索引 -
请求参数:无
格式:
GET /索引
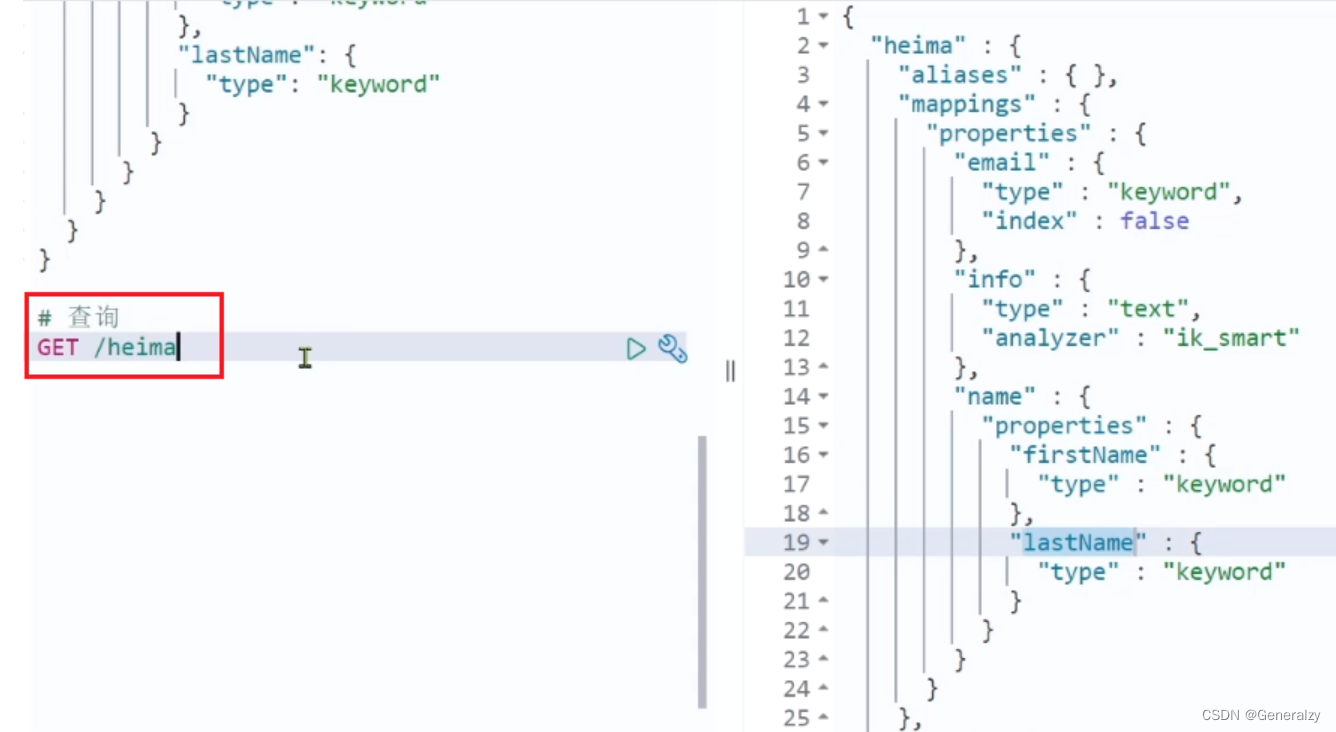
#查看books索引的mapping
GET books/_mapping
#获取所有的mapping
GET _all/_mapping
修改映射
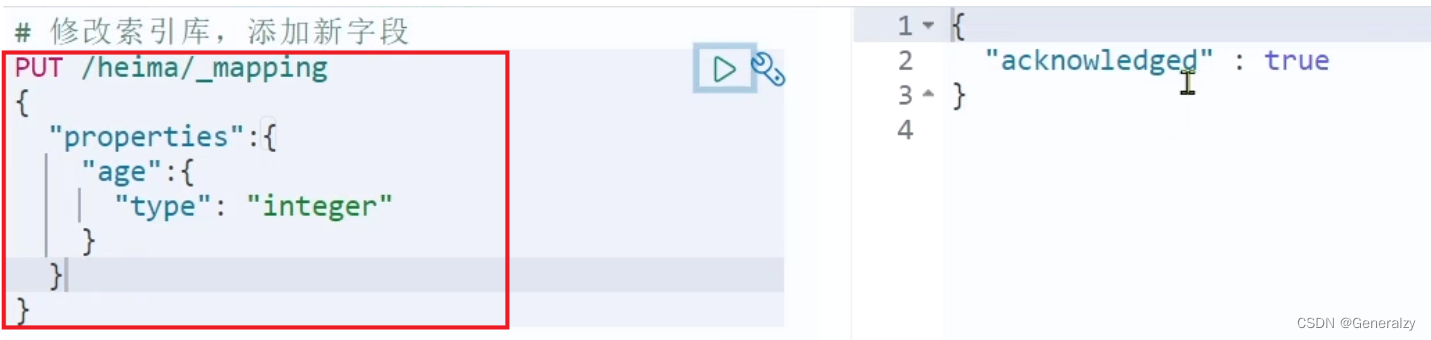
倒排索引结构虽然不复杂,但是一旦数据结构改变(比如改变了分词器),就需要重新创建倒排索引,因此索引库一旦创建,无法修改mapping。
虽然无法修改mapping中已有的字段,但是却允许添加新的字段到mapping中,因为不会对倒排索引产生影响。
PUT /索引/_mapping
{
"properties": {
"新字段名":{
"type": "integer"
}
}
}
删除映射
语法:
-
请求方式:DELETE
-
请求路径:
/索引 -
请求参数:无
格式:
DELETE /索引
总结
映射操作有哪些?
- 创建索引库:PUT /索引
- 查询索引库:GET /索引
- 删除索引库:DELETE /索引
- 添加字段:PUT /索引/_mapping
文档操作
注意:当执行PUT命令时,如果数据不存在,则新增该条数据,如果数据存在则修改该条数据。
创建文档
POST shopping/_doc
{
"title":"小米手机",
"category":"小米",
"images":"http://www.gulixueyuan.com/xm.jpg",
"price":3999.00
}
如果想要自定义唯一性标识,需要在创建时指定: http://127.0.0.1:9200/shopping/_doc/1
PUT lqz/doc/1
{
"name":"顾老二",
"age":30,
"from": "gu",
"desc": "皮肤黑、武器长、性格直",
"tags": ["黑", "长", "直"]
}
所以,新增的语法为:
POST /索引库名/_doc/文档id
{
"字段1": "值1",
"字段2": "值2",
"字段3": {
"子属性1": "值3",
"子属性2": "值4"
},
// ...
}
查询文档
根据rest风格,新增是post,查询应该是get,不过查询一般都需要条件,这里我们把文档id带上。
GET /{索引库名称}/_doc/{id}
在 Postman或kibana 中,向 ES 服务器发 GET 请求 : http://127.0.0.1:9200/shopping/_doc/1 。
{
"_index": "shopping",
"_type": "_doc",
"_id": "1",
"_version": 1,
"_seq_no": 1,
"_primary_term": 1,
"found": true,
"_source": {
"title": "小米手机",
"category": "小米",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 3999
}
}
查找不存在的内容
{
"_index": "shopping",
"_type": "_doc",
"_id": "1001",
"found": false
}
查看索引下所有数据,向 ES 服务器发 GET 请求 : http://127.0.0.1:9200/shopping/_search:
{
"took": 726,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 1.0,
"hits": [
{
"_index": "shopping",
"_type": "_doc",
"_id": "_XPLhoIBg3C-pJdYUv6X",
"_score": 1.0,
"_source": {
"title": "小米手机",
"category": "小米",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 3999.00
}
},
{
"_index": "shopping",
"_type": "_doc",
"_id": "1",
"_score": 1.0,
"_source": {
"title": "小米手机",
"category": "小米",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 3999.00
}
}
]
}
}
删除文档
删除使用DELETE请求,同样,需要根据id进行删除:
语法:
DELETE /{索引库名}/_doc/id值
示例:
# 根据id删除数据
DELETE /heima/_doc/1
修改文档
修改有两种方式:
- 全量修改:直接覆盖原来的文档
- 增量修改:修改文档中的部分字段
全量修改
全量修改是覆盖原来的文档,其本质是:
- 根据指定的id删除文档
- 新增一个相同id的文档
注意:如果根据id删除时,id不存在,第二步的新增也会执行,也就从修改变成了新增操作了。
语法:
PUT /{索引库名}/_doc/文档id
{
"字段1": "值1",
"字段2": "值2",
// ... 略
}
示例:
PUT /heima/_doc/1
{
"info": "黑马程序员高级Java讲师",
"email": "zy@itcast.cn",
"name": {
"firstName": "云",
"lastName": "赵"
}
}
增量修改
增量修改是只修改指定id匹配的文档中的部分字段.
语法:
POST /{索引库名}/_update/文档id
{
"doc": {
"字段名": "新的值",
}
}
示例:
POST /heima/_update/1
{
"doc": {
"email": "ZhaoYun@itcast.cn"
}
}
总结
文档操作有哪些?
- 创建文档:POST /{索引库名}/_doc/文档id { json文档 }
- 查询文档:GET /{索引库名}/_doc/文档id
- 删除文档:DELETE /{索引库名}/_doc/文档id
- 修改文档:
- 全量修改:PUT /{索引库名}/_doc/文档id { json文档 }
- 增量修改:POST /{索引库名}/_update/文档id { “doc”: {字段}}
Elasticsearch之查询的两种方式
elasticsearch提供两种查询方式:
- 查询字符串(query string),简单查询,就像是像传递URL参数一样去传递查询语句,被称为简单搜索或查询字符串(query string)搜索。
- 另外一种是通过DSL语句来进行查询,被称为DSL查询(Query DSL),DSL是Elasticsearch提供的一种丰富且灵活的查询语言,该语言以json请求体的形式出现,通过restful请求与Elasticsearch进行交互。
查询字符串(一般不用)
GET lqz/doc/_search?q=from:gu
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 3,
"max_score" : 0.6931472,
"hits" : [
{
"_index" : "lqz",
"_type" : "doc",
"_id" : "4",
"_score" : 0.6931472,
"_source" : {
"name" : "石头",
"age" : 29,
"from" : "gu",
"desc" : "粗中有细,狐假虎威",
"tags" : [
"粗",
"大",
"猛"
]
}
},
{
"_index" : "lqz",
"_type" : "doc",
"_id" : "1",
"_score" : 0.2876821,
"_source" : {
"name" : "顾老二",
"age" : 30,
"from" : "gu",
"desc" : "皮肤黑、武器长、性格直",
"tags" : [
"黑",
"长",
"直"
]
}
},
{
"_index" : "lqz",
"_type" : "doc",
"_id" : "3",
"_score" : 0.2876821,
"_source" : {
"name" : "龙套偏房",
"age" : 22,
"from" : "gu",
"desc" : "mmp,没怎么看,不知道怎么形容",
"tags" : [
"造数据",
"真",
"难"
]
}
}
]
}
}
hits是返回的结果集——所有from属性为gu的结果集。重点中的重点是_score得分,根据算法算出跟查询条件的匹配度,匹配度高得分就高。
结构化查询
GET lqz/doc/_search
{
"query": {
"match": {
"from": "gu"
}
}
}
上例,查询条件是一步步构建出来的,将查询条件添加到match中即可,而match则是查询所有from字段的值中含有gu的结果就会返回。
match查询
match_all查询全部
match_all的值为空,表示没有查询条件,那就是查询全部。就像select * from table_name一样。
GET lqz/doc/_search
{
"query":{
"match_all":{}
}
}
查询指定字段
GET lqz/doc/_search
{
"query":{
"match_all":{}
},
# 只显示title字段
# 相当于mysql的select
"_source":["title"]
}
match_phrase短语查询
查询带"中国"的结果,而不是带"中","国"的结果
GET t1/doc/_search
{
"query": {
"match_phrase": {
"title": {
"query": "中国"
}
}
}
}
要想搜索中国和世界相关的文档,但又忘记其余部分了,怎么做呢?
搜索中国和世界这两个指定词组时,但又不清楚两个词组之间有多少别的词间隔。那么在搜的时候就要留有一些余地。这时就要用到了slop了。相当于正则中的中国.*?世界。这个间隔默认为0
GET t1/doc/_search
{
"query": {
"match_phrase": {
"title": {
# 查询中国 - - 世界的结果
"query": "中国世界",
# 间隔代表中国和世界之间有2个分词
"slop": 2
}
}
}
}
match_phrase_prefix(最左前缀查询)
GET t3/doc/_search
{
"query": {
"match_phrase_prefix": {
# 查询desc字段以bea开头的结果
"desc": "bea"
}
}
}
前缀查询是短语查询类似,但前缀查询可以更进一步的搜索词组,只不过它是和词组中最后一个词条进行前缀匹配(如搜这样的you are bea)。应用也非常的广泛,比如搜索框的提示信息,当使用这种行为进行搜索时,最好通过max_expansions来设置最大的前缀扩展数量,因为产生的结果会是一个很大的集合,不加限制的话,影响查询性能。
GET t3/doc/_search
{
"query": {
"match_phrase_prefix": {
"desc": {
"query": "bea",
"max_expansions": 1
}
}
}
}
该max_expansions设置定义了在停止搜索之前模糊查询将匹配的最大术语数,也可以对模糊查询的性能产生显着影响。但是,减少查询字词会产生负面影响,因为查询提前终止可能无法找到某些有效结果。重要的是要理解max_expansions查询限制在分片级别工作,这意味着即使设置为1,多个术语可能匹配,所有术语都来自不同的分片。此行为可能使其看起来好像max_expansions没有生效,因此请注意,计算返回的唯一术语不是确定是否有效的有效方法max_expansions。
我们只需知道该参数工作于分片层,也就是Lucene部分,使用前缀查询会非常的影响性能,要对结果集进行限制,就加上这个参数。
multi_match(多字段查询)
要在多个字段中查询同一个关键字,该怎么做呢?
GET t3/doc/_search
{
"query": {
"multi_match": {
# 在title,desc字段中查找beautiful
"query": "beautiful",
"fields": ["title", "desc"]
}
}
}
除此之外,multi_match甚至可以当做match_phrase和match_phrase_prefix使用,只需要指定type类型即可:
GET t3/doc/_search
{
"query": {
"multi_match": {
"query": "gi",
"fields": ["title"],
"type": "phrase_prefix"
}
}
}
GET t3/doc/_search
{
"query": {
"multi_match": {
"query": "girl",
"fields": ["title"],
"type": "phrase"
}
}
}
match系列小结
- match:返回所有匹配的分词。
- match_all:查询全部。
- match_phrase:短语查询,在match的基础上进一步查询词组,可以指定slop分词间隔。
- match_phrase_prefix:前缀查询,根据短语中最后一个词组做前缀匹配,可以应用于搜索提示,但注意和max_expanions搭配。其实默认是50…
- multi_match:多字段查询,使用相当的灵活,可以完成match_phrase和match_phrase_prefix的工作。
term查询
默认情况下,elasticsearch在对文档分析期间(将文档分词后保存到倒排索引中),会对文档进行分词,比如默认的标准分析器会对文档进行:
- 删除大多数的标点符号。
- 将文档分解为单个词条,我们称为token。
- 将token转为小写。
- 完事再保存到倒排索引上,当然,原文件还是要保存一分的,而倒排索引使用来查询的。
例如Beautiful girl!,在经过分析后是这样的了:
POST _analyze
{
"analyzer": "standard",
"text": "Beautiful girl!"
}
# 结果
["beautiful", "girl"]
而当在使用match查询时,elasticsearch同样会对查询关键字进行分析:
也就是对查询关键字Beautiful girl!进行分析,得到[“beautiful”, “girl”],然后分别将这两个单独的token去索引中进行查询,结果就是将多篇文档都返回。
这在有些情况下是非常好用的,但是,如果我们想查询确切的词怎么办?也就是精确查询,将Beautiful girl!当成一个token而不是分词后的两个token。
这就要用到了term查询了,term查询的是没有经过分析的查询关键字。
但是,这同样需要限制,如果你要查询的字段类型是text(因为elasticsearch会对文档进行分析,上面说过),那么你得到的可能是不尽如人意的结果或者压根没有结果:
所以,我们这里得到一个论证结果:不要使用term对类型是text的字段进行查询,要查询text类型的字段,请改用match查询。
GET w10/doc/_search
{
"query": {
"term": {
"t1": "Beautiful"
}
}
}
有结果返回,因为elasticsearch在对文档进行分析时,倒排索引上存的是小写的beautiful,而查询的是大写的Beautiful。
要想使用term查询多个精确的值怎么办?
GET w10/doc/_search
{
"query": {
"terms": {
"t1": ["beautiful", "sexy"]
}
}
}
查询排序sort
降序:desc,升序:asc
GET lqz/doc/_search
{
"query":{
"match_all":{}
},
"sort":{
# 按照price降序排序
"price":{
"order":"desc"
}
}
}
不是什么数据类型都能排序
注意:在排序的过程中,只能使用可排序的属性进行排序。
- 数字
- 日期
分页查询from/size
GET lqz/doc/_search
{
"query":{
"match_all":{}
},
# 从0开始
"from":0,
# 分页大小为2
"size":2
}
对于elasticsearch来说,所有的条件都是可插拔的,彼此之间用,分割。
GET lqz/doc/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"age": {
"order": "desc"
}
}
],
"from": 4,
"size": 2
}
布尔查询bool
布尔查询是最常用的组合查询,根据子查询的规则,只有当文档满足所有子查询条件时,elasticsearch引擎才将结果返回。布尔查询支持的子查询条件共4中:
- must(and)
- should(or)
- must_not(not)
- filter
must
- must字段对应的是个列表,也就是说可以有多个并列的查询条件,一个文档满足各个子条件后才最终返回。
- must相当于数据库的&&。
假设想找出小米牌子,价格为3999元的。
GET lqz/doc/_search
{
"query":{
"bool":{
"must":[{
"match":{
"category":"小米"
}
},{
"match":{
"price":3999.00
}
}]
}
}
}
should
- 或关系的不能用must的了,而是要用should,只要符合其中一个条件就返回。
假设想找出小米和华为的牌子。(should相当于数据库的||)
{
"query": {
"bool": {
"should": [{
"match": {
"category": "小米"
}
}, {
"match": {
"category": "华为"
}
}],
}
}
}
must_not
要查询from既不是gu并且tags也不是可爱,还有age不是18的数据(条件中age对应的18写成整形还是字符串都没啥)
GET lqz/doc/_search
{
"query": {
"bool": {
"must_not": [
{
"match": {
"from": "gu"
}
},
{
"match": {
"tags": "可爱"
}
},
{
"match": {
"age": 18
}
}
]
}
}
}
filter
要查询from为gu,age大于25的数据
GET lqz/doc/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"from": "gu"
}
}
],
"filter": {
"range": {
"age": {
"gt": 25
}
}
}
}
}
}
这里就用到了filter条件过滤查询,过滤条件的范围用range表示,gt表示大于(gte大于等于,lt小于,lte小于等于)
查询from是gu,age在25~30之间的:
GET lqz/doc/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"from": "gu"
}
}
],
"filter": {
"range": {
"age": {
"gte": 25,
"lte": 30
}
}
}
}
}
}
如果在filter过滤条件中使用should的话,结果可能不会尽如人意!建议使用must代替。
注意:filter工作于bool查询内,不能放到外面
总结
- must:与关系,相当于关系型数据库中的and。
- should:或关系,相当于关系型数据库中的or。
- must_not:非关系,相当于关系型数据库中的not。
- filter:过滤条件。
- range:条件筛选范围。
- gt:大于,相当于关系型数据库中的>。
- gte:大于等于,相当于关系型数据库中的>=。
- lt:小于,相当于关系型数据库中的<。
- lte:小于等于,相当于关系型数据库中的<=。
查询结果过滤
结果过滤:_source
在所有的结果中,只需要查看name和age两个属性,其他的不要
GET lqz/doc/_search
{
"query": {
"match": {
"name": "顾老二"
}
},
"_source": ["name", "age"]
}
高亮查询
默认高亮显示
GET lqz/doc/_search
{
"query": {
"match": {
"name": "石头"
}
},
"highlight": {
"fields": {
"name": {}
}
}
}
使用highlight属性来实现结果高亮显示,需要的字段名称添加到fields内即可,elasticsearch会自动帮我们实现高亮。
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 1,
"max_score" : 1.5098256,
"hits" : [
{
"_index" : "lqz",
"_type" : "doc",
"_id" : "4",
"_score" : 1.5098256,
"_source" : {
"name" : "石头",
"age" : 29,
"from" : "gu",
"desc" : "粗中有细,狐假虎威",
"tags" : [
"粗",
"大",
"猛"
]
},
"highlight" : {
"name" : [
"<em>石</em><em>头</em>"
]
}
}
]
}
}
自定义高亮显示
GET lqz/chengyuan/_search
{
"query": {
"match": {
"from": "gu"
}
},
"highlight": {
"pre_tags": "<b class='key' style='color:red'>",
"post_tags": "</b>",
"fields": {
"from": {}
}
}
}
在highlight中,pre_tags用来实现我们的自定义标签的前半部分,在这里,我们也可以为自定义的标签添加属性和样式。post_tags实现标签的后半部分,组成一个完整的标签。至于标签中的内容,则还是交给fields来完成。
需要注意的是:自定义标签中属性或样式中的逗号一律用英文状态的单引号表示,应该与外部elasticsearch语法的双引号区分开。
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 1,
"max_score" : 0.5753642,
"hits" : [
{
"_index" : "lqz",
"_type" : "chengyuan",
"_id" : "1",
"_score" : 0.5753642,
"_source" : {
"name" : "老二",
"age" : 30,
"sex" : "male",
"birth" : "1070-10-11",
"from" : "gu",
"desc" : "皮肤黑,武器长,性格直",
"tags" : [
"黑",
"长",
"直"
]
},
"highlight" : {
"name" : [
"<b class='key' style='color:red'>老</b><b class='key' style='color:red'>二</b>"
]
}
}
]
}
聚合函数
elasticsearch中也没玩出新花样:
- avg
- max
- min
- sum
avg
GET lqz/doc/_search
{
"query": {
"match": {
"from": "gu"
}
},
"aggs": {
"my_avg": {
"avg": {
"field": "age"
}
}
},
"_source": ["name", "age"]
}
首先匹配查询from是gu的数据。在此基础上做查询平均值的操作,这里就用到了聚合函数,其语法被封装在aggs中,而my_avg则是为查询结果起个别名,封装了计算出的平均值。那么,要以什么属性作为条件呢?是age年龄,查年龄的什么呢?是avg,查平均年龄。
虽然我们已经使用_source对字段做了过滤,但是还不够,只想看平均值,就可以用size:
GET lqz/doc/_search
{
"query": {
"match": {
"from": "gu"
}
},
"aggs": {
"my_avg": {
"avg": {
"field": "age"
}
}
},
"size": 0,
"_source": ["name", "age"]
}
{
"took" : 8,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 3,
"max_score" : 0.0,
"hits" : [ ]
},
"aggregations" : {
"my_avg" : {
"value" : 27.0
}
}
}
max
GET lqz/doc/_search
{
"query": {
"match": {
"from": "gu"
}
},
"aggs": {
"my_max": {
"max": {
"field": "age"
}
}
},
"size": 0
}
只需要在查询条件中将avg替换成max即可。
min
GET lqz/doc/_search
{
"query": {
"match": {
"from": "gu"
}
},
"aggs": {
"my_min": {
"min": {
"field": "age"
}
}
},
"size": 0
}
sum
GET lqz/doc/_search
{
"query": {
"match": {
"from": "gu"
}
},
"aggs": {
"my_sum": {
"sum": {
"field": "age"
}
}
},
"size": 0
}
分组查询
查询所有人的年龄段,并且按照1520,2025,25~30分组,并且算出每组的平均年龄。
- 分组
GET lqz/doc/_search
{
"size": 0,
"query": {
"match_all": {}
},
"aggs": {
"age_group": {
"range": {
"field": "age",
"ranges": [
{
"from": 15,
"to": 20
},
{
"from": 20,
"to": 25
},
{
"from": 25,
"to": 30
}
]
}
}
}
}
在aggs的自定义别名age_group中,使用range来做分组,field是以age为分组,分组使用ranges来做,from和to是范围,我们根据需求做出三组。
{
"took" : 3,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 5,
"max_score" : 0.0,
"hits" : [ ]
},
"aggregations" : {
"age_group" : {
"buckets" : [
{
"key" : "15.0-20.0",
"from" : 15.0,
"to" : 20.0,
"doc_count" : 1
},
{
"key" : "20.0-25.0",
"from" : 20.0,
"to" : 25.0,
"doc_count" : 1
},
{
"key" : "25.0-30.0",
"from" : 25.0,
"to" : 30.0,
"doc_count" : 2
}
]
}
}
}
- 对每个小组内的数据做平均年龄处理
GET lqz/doc/_search
{
"size": 0,
"query": {
"match_all": {}
},
"aggs": {
"age_group": {
"range": {
"field": "age",
"ranges": [
{
"from": 15,
"to": 20
},
{
"from": 20,
"to": 25
},
{
"from": 25,
"to": 30
}
]
},
"aggs": {
"my_avg": {
"avg": {
"field": "age"
}
}
}
}
}
}
使用aggs对age做平均数处理,这样就可以了。
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 5,
"max_score" : 0.0,
"hits" : [ ]
},
"aggregations" : {
"age_group" : {
"buckets" : [
{
"key" : "15.0-20.0",
"from" : 15.0,
"to" : 20.0,
"doc_count" : 1,
"my_avg" : {
"value" : 18.0
}
},
{
"key" : "20.0-25.0",
"from" : 20.0,
"to" : 25.0,
"doc_count" : 1,
"my_avg" : {
"value" : 22.0
}
},
{
"key" : "25.0-30.0",
"from" : 25.0,
"to" : 30.0,
"doc_count" : 2,
"my_avg" : {
"value" : 27.0
}
}
]
}
}
}
注意:聚合函数的使用,一定是先查出结果,然后对结果使用聚合函数做处理
小结:
- avg:求平均
- max:最大值
- min:最小值
- sum:求和
集群搭建,数据分片
单机的elasticsearch做数据存储,必然面临两个问题:海量数据存储问题、单点故障问题。
- 海量数据存储问题:将索引库从逻辑上拆分为N个分片(shard),存储到多个节点
- 单点故障问题:将分片数据在不同节点备份(replica )
ES集群相关概念
-
集群(cluster):一组拥有共同的 cluster name 的 节点。
-
节点(node) :集群中的一个 Elasticearch 实例
-
分片(shard):索引可以被拆分为不同的部分进行存储,称为分片。在集群环境下,一个索引的不同分片可以拆分到不同的节点中
解决问题:数据量太大,单点存储量有限的问题。
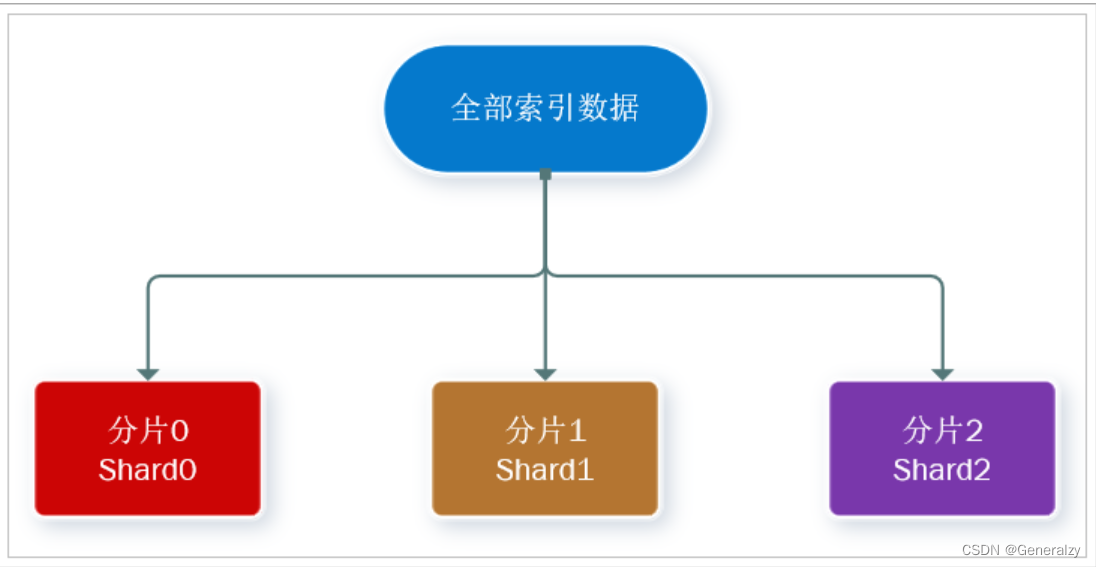
-
主分片(Primary shard):相对于副本分片的定义。
-
副本分片(Replica shard)每个主分片可以有一个或者多个副本,数据和主分片一样。
docker搭建ek集群
- 将配置文件也挂载出来:
-v /elasticsearch/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml
- 修改配置文件
#集群名称 每个节点的集群名字要相同
cluster.name: es-docker-cluster
#本节点名称
node.name: node-1
#是不是有资格主节点
node.master: true
#是否存储数据
node.data: true
#跨域设置(head 插件需要这打开这两个配置)
http.cors.enabled: true
http.cors.allow-origin: "*"
http.max_content_length: 200mb
#http端口
http.port: 9200
#java端口
transport.tcp.port: 9300
#可以访问es集群的ip 0.0.0.0表示不绑定
network.bind_host: 0.0.0.0
#es集群相互通信的ip 0.0.0.0默认本地网络搜索
network.publish_host: 0.0.0.0
#7.x配置
# es7.x 之后新增的配置,初始化一个新的集群时需要此配置来选举 master
cluster.initial_master_nodes: ["node-1"]
#es7.x 之后新增的配置,节点发现
discovery.seed_hosts: ["linux1:9300","linux2:9300","linux3:9300"]
# gateway.recover_after_nodes: 2
# network.tcp.keep_alive: true
# network.tcp.no_delay: true
# transport.tcp.compress: true
#集群内同时启动的数据任务个数,默认是 2 个
# cluster.routing.allocation.cluster_concurrent_rebalance: 16
#添加或删除节点及负载均衡时并发恢复的线程个数,默认 4 个
# cluster.routing.allocation.node_concurrent_recoveries: 16
#初始化数据恢复时,并发恢复线程的个数,默认 4 个
# cluster.routing.allocation.node_initial_primaries_recoveries: 16
# discovery.zen.minimum_master_nodes: 2
# 一般的规则是集群节点数除以2(向下取整)再加一。比如3个节点集群要设置为2。这么着是为了防止脑裂(split brain)问题。
- 分别启动三个es