一. 前言
Binder中一次拷贝的实现就是利用mmap(memory mapping)内存映射机制,我们来看看它的工作原理.
二. 参考文章
下面这几篇文章建议先好好阅读一下,都是总结的很好的文章, 每个人理解可能不一样
笔者也是看了好多博客文章和B站视频讲解, 然后加上自己的理解后 输出的一点总结
我保证写出来的都是经过思考后, 尽量输出的是对的, 不误导别人, 如果有错误,也请指出来,一起讨论
感谢!
Linux下 给一个进程分配4G虚拟地址空间的数据结构图: Linux下的4G虚拟地址空间
关于mmap概念? 可以参阅这篇文章 :认真分析mmap:是什么 为什么 怎么用
mmap映射的原理,可以参阅这篇文章: Android 内存映射mmap浅谈
Binder进程间通信, mmap使用细节: Android-内存映射mmap
binder驱动层关于mmap实现, 可以参阅这篇文章: Binder驱动概述
binder驱动层计算映射内存大小,可以参阅这篇文章: binder驱动-------之内存映射篇_binder内存映射_xiaojsj111的博客-CSDN博客
三. 理解和总结
3.1 Linux下每个进程的4G虚拟地址空间的数据结构图
我们现在所写的源代码并不是我们所说的程序,从C代码(.c/.cpp)---->链接程序(.exe)是要经过以下几个过程才能真正的运行链接的;
C源程序--->预编译处理(.c/.cpp)-->编译,优化程序(.s)--->汇编程序(.o)--->链接(.exe)
在编译运行过程中,我们首先需要将我们的程序存储到内存中才能调取运行,但是内存是有限的,不可能将所有的进程都放在内存中去,所以都会给进程分配一个4G的虚拟地址空间存储数据,在进程运行时在映射到内存中去。
在 windows下 4G的空间分布为 : 用户态:内核态=1:1
Linux下 4G的空间分布为: 用户态:内核态=3:1

4G都是虚拟地址空间.
3.2 理解用户空间和内核空间
用户空间与内核空间
Linux的进程是相互独立的,一个进程是不能直接操作或者访问别一个进程空间的。每个进程空间还分为用户空间和内核(Kernel)空间,相当于把Kernel和上层的应用程序抽像的隔离开。
用户空间和内核空间,用户空间是用户程序代码运行的地方,内核空间是内核代码运行的地方。为了安全,它们是隔离的,即使用户的程序崩溃了,内核也不受影响。
这里有两个隔离,一个进程间是相互隔离的,二是进程内有用户空间和内核空间的隔离。
1. 进程间,用户空间的数据不可共享,所以用户空间 = 不可共享空间
2. 进程间,内核空间的数据可共享, 所以内核空间 = 可共享空间
3. 每个进程的内核空间1G(地址: 0xC0000000--0xFFFFFFFF)都是共享的, 属于所有进程, 内核线性地址空间由所有进程共享,但只有运行在内核态的进程才能访问.
3.3 Binder进程间通信使用mmap
1. Linux内存映射(mmap)概念:Linux通过将一个虚拟内存区域与一个磁盘上的对象关联起来,以初始化这个虚拟内存区域的内容,这个过程称为内存映射(memory mapping)。实现映射关系后,就可以采用指针的方式读写操作这一段内存,而系统会自动回写到对应的文件磁盘上。
了解进程间通信的人都知道Android使用的是Binder进行进程间通信,它的效率高于Linux其他传统的进程间通信,因为它只要一次拷贝,而之所以只需要进行一次拷贝的原因就在于使用了mmap!
一次完整的 Binder IPC 通信过程通常是这样:
1. Server端在启动之后,调用对/dev/binder设备调用mmap。
service端进程在用户空间调用库函数mmap 是在
frameworks/native/libs/binder/ProcessState.cpp文件中
if (mDriverFD >= 0) {
// mmap the binder, providing a chunk of virtual address space to receive transactions.
mVMStart = mmap(nullptr, BINDER_VM_SIZE, PROT_READ, MAP_PRIVATE | MAP_NORESERVE, mDriverFD, 0);
if (mVMStart == MAP_FAILED) {
// *sigh*
ALOGE("Using %s failed: unable to mmap transaction memory.\n", mDriverName.c_str());
close(mDriverFD);
mDriverFD = -1;
mDriverName.clear();
}
}#define BINDER_VM_SIZE ((1 * 1024 * 1024) - sysconf(_SC_PAGE_SIZE) * 2)
#define DEFAULT_MAX_BINDER_THREADS 15
//binder默认驱动名称
const char* kDefaultDriver = "/dev/binder";
ProcessState的单例模式的惟一性,因此一个进程只打开binder设备一次,其中ProcessState的成员变量mDriverFD记录binder驱动的fd,用于访问binder设备。BINDER_VM_SIZE = (1*1024*1024) - (4096 *2), binder分配的默认内存大小为1M-8k。 _SC_PAGE_SIZE 一个页的大小为4KDEFAULT_MAX_BINDER_THREADS = 15,binder默认的最大可并发访问的线程数为16。
当一个进程启动后, 它就有属于自己的一块binder内存, 这块内存的大小就是在进程调用mmap函数时分配的大小 : 1M-8K
可以验证一下,链接上自己的手机,执行命令:
1. adb shell
2. ps -A 查看所以运行的进程, 我们找几个比较常见的应用进程
me@ubuntu:~$ adb shell
device:/ # ps -A
USER PID PPID VSZ RSS WCHAN ADDR S NAME
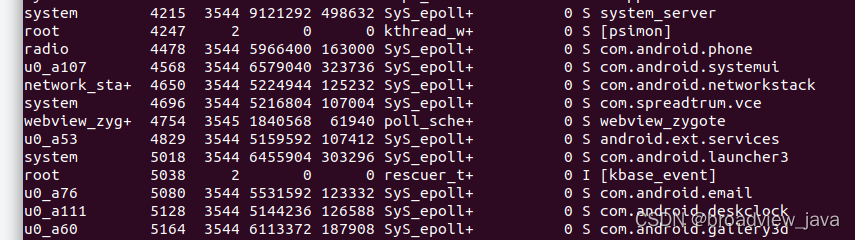
PID号在第二列显示,比如 systemui的进程号为4568 launcher的进程号为5018
系统调用mmap所分配的地址空间,并可以通过cat proc/进程号/maps | grep dev/binder 命令查看到:
看下SystemUI:

地址范围为: 7b2b1df000---7b2b2dd000 通过计算器 16进制转化成十进制计算得出为:
1040384 / 1024 = 1016K 刚好为 1M-8K
再看下Launcher3:

地址范围: 7b2b1cd000---7b2b2cb000 通过计算 转换成十进制
1040384 / 1024 = 1016K 刚好为 1M-8K
2. 内核中的binder_mmap函数进行对应的处理:申请一块物理内存,然后在Server端的用户空间和内核空间同时进行映射.
路径: bsp/kernel/kernel4.14/drivers/android/binder.c
我们再看/drivers/staging/android/binder.c驱动中static int binder_mmap(struct file *filp, struct vm_area_struct *vma)函数的含义:
vma->vm_start和vma->vm_end即为此次映射内核为我们分配的开始地址和结束地址,他们差值就是系统调用mmap中的length的值。而vma->vm_start的则是系统调用mmap调用的返回值。需要注意的是vma->vm_start和vma->vm_end都是调用进程的用户空间的虚拟地址,他们地址范围可以通过如下命令:cat /proc/pid/maps | grep "/dev/binder"看到,如上面两个图,针对Systemui.apk进程,他们vma->vm_start和vma->vm_end的值分别为:7b2b1df000和7b2b2dd000
static int binder_mmap(struct file *filp, struct vm_area_struct *vma)
{
int ret;
struct vm_struct *area;
struct binder_proc *proc = filp->private_data;
const char *failure_string;
struct binder_buffer *buffer;//内核进入这个函数时,就已经预先为此次映射分配好了调用进程在用户空间的虚拟地址范围(vma->vm_start,vma->vm_end)
if ((vma->vm_end - vma->vm_start) > SZ_4M)
vma->vm_end = vma->vm_start + SZ_4M;
binder_debug(BINDER_DEBUG_OPEN_CLOSE,
"binder_mmap: %d %lx-%lx (%ld K) vma %lx pagep %lx\n",
proc->pid, vma->vm_start, vma->vm_end,
(vma->vm_end - vma->vm_start) / SZ_1K, vma->vm_flags,
(unsigned long)pgprot_val(vma->vm_page_prot));
if (vma->vm_flags & FORBIDDEN_MMAP_FLAGS) {
ret = -EPERM;
failure_string = "bad vm_flags";
goto err_bad_arg;
}
vma->vm_flags = (vma->vm_flags | VM_DONTCOPY) & ~VM_MAYWRITE;
mutex_lock(&binder_mmap_lock);
if (proc->buffer) {
ret = -EBUSY;
failure_string = "already mapped";
goto err_already_mapped;
}
//为进程所在的内核空间申请与用户空间同样长度的虚拟地址空间,这段空间用于内核来访问和管理binder内存区域
area = get_vm_area(vma->vm_end - vma->vm_start, VM_IOREMAP);
if (area == NULL) {
ret = -ENOMEM;
failure_string = "get_vm_area";
goto err_get_vm_area_failed;
}//对应内核虚拟地址的开始,即为binder内存的开始地址
proc->buffer = area->addr;
proc->user_buffer_offset = vma->vm_start - (uintptr_t)proc->buffer;//同一块物理内存,内核的虚拟地址同应用空间的虚拟地址的差
mutex_unlock(&binder_mmap_lock);
#ifdef CONFIG_CPU_CACHE_VIPT
if (cache_is_vipt_aliasing()) {
while (CACHE_COLOUR((vma->vm_start ^ (uint32_t)proc->buffer))) {
printk(KERN_INFO "binder_mmap: %d %lx-%lx maps %p bad alignment\n", proc->pid, vma->vm_start, vma->vm_end, proc->buffer);
vma->vm_start += PAGE_SIZE;
}
}
#endif//用于存放内核分配的物理页的页描述指针:struct page,每个物理页对应这样一个struct page结构
proc->pages = kzalloc(sizeof(proc->pages[0]) * ((vma->vm_end - vma->vm_start) / PAGE_SIZE), GFP_KERNEL);
if (proc->pages == NULL) {
ret = -ENOMEM;
failure_string = "alloc page array";
goto err_alloc_pages_failed;
}
proc->buffer_size = vma->vm_end - vma->vm_start;//映射的长度即为binder内存的大小
vma->vm_ops = &binder_vm_ops;//设定
vma->vm_private_data = proc;//为binder内存的最开始的一个页的地址建立虚拟到物理页的映射,其他的虚拟地址都还没有建立相应的映射,没有映射也就还不能够被访问
if (binder_update_page_range(proc, 1, proc->buffer, proc->buffer + PAGE_SIZE, vma)) {
ret = -ENOMEM;
failure_string = "alloc small buf";
goto err_alloc_small_buf_failed;
}
buffer = proc->buffer;
INIT_LIST_HEAD(&proc->buffers);//proc->buffers用来连接所有已建立映射的binder内存块
list_add(&buffer->entry, &proc->buffers);
buffer->free = 1;
binder_insert_free_buffer(proc, buffer);//将刚分配的一个page大小的binder内存块插入到proc->free_buffers红黑树中
proc->free_async_space = proc->buffer_size / 2;
barrier();
proc->files = get_files_struct(proc->tsk);
proc->vma = vma;
proc->vma_vm_mm = vma->vm_mm;
/*printk(KERN_INFO "binder_mmap: %d %lx-%lx maps %p\n",
proc->pid, vma->vm_start, vma->vm_end, proc->buffer);*/
return 0;
err_alloc_small_buf_failed:
kfree(proc->pages);
proc->pages = NULL;
err_alloc_pages_failed:
mutex_lock(&binder_mmap_lock);
vfree(proc->buffer);
proc->buffer = NULL;
err_get_vm_area_failed:
err_already_mapped:
mutex_unlock(&binder_mmap_lock);
err_bad_arg:
printk(KERN_ERR "binder_mmap: %d %lx-%lx %s failed %d\n",
proc->pid, vma->vm_start, vma->vm_end, failure_string, ret);
return ret;
}下面binder_update_page_range函数就是为进程的内核空间和进程的用户空间针对同一块物理内存建立映射,这样进程的用户空间和内核空间就可以共享该物理内存了。
static int binder_update_page_range(struct binder_proc *proc, int allocate,
void *start, void *end,
struct vm_area_struct *vma)
{
void *page_addr;
unsigned long user_page_addr;
struct vm_struct tmp_area;
struct page **page;
struct mm_struct *mm;
binder_debug(BINDER_DEBUG_BUFFER_ALLOC,
"binder: %d: %s pages %p-%p\n", proc->pid,
allocate ? "allocate" : "free", start, end);
if (end <= start)//表示已经建立过映射,不需再映射
return 0;
trace_binder_update_page_range(proc, allocate, start, end);
if (vma)
mm = NULL;
else
mm = get_task_mm(proc->tsk);
if (mm) {
down_write(&mm->mmap_sem);
vma = proc->vma;
if (vma && mm != proc->vma_vm_mm) {
pr_err("binder: %d: vma mm and task mm mismatch\n",
proc->pid);
vma = NULL;
}
}
if (allocate == 0)//表示拆除已经建立的映射
goto free_range;
if (vma == NULL) {
printk(KERN_ERR "binder: %d: binder_alloc_buf failed to "
"map pages in userspace, no vma\n", proc->pid);
goto err_no_vma;
}
for (page_addr = start; page_addr < end; page_addr += PAGE_SIZE) {
int ret;
struct page **page_array_ptr;
page = &proc->pages[(page_addr - proc->buffer) / PAGE_SIZE];
BUG_ON(*page);
*page = alloc_page(GFP_KERNEL | __GFP_ZERO);//分配一个物理页,并将该物理页的struct page指针值存放在proc->pages二维数组中
if (*page == NULL) {
printk(KERN_ERR "binder: %d: binder_alloc_buf failed "
"for page at %p\n", proc->pid, page_addr);
goto err_alloc_page_failed;
}
tmp_area.addr = page_addr;//映射对应的内核虚拟地址
tmp_area.size = PAGE_SIZE + PAGE_SIZE /* guard page? */;//映射对应的大小
page_array_ptr = page;//该物理页对应的struct page结构体,用这个结构体可以完全的描述这个物理页
ret = map_vm_area(&tmp_area, PAGE_KERNEL, &page_array_ptr);//为内核的这段虚拟地址建立虚拟到物理页的映射
if (ret) {
printk(KERN_ERR "binder: %d: binder_alloc_buf failed "
"to map page at %p in kernel\n",
proc->pid, page_addr);
goto err_map_kernel_failed;
}
user_page_addr =
(uintptr_t)page_addr + proc->user_buffer_offset;//由内核的虚拟地址得到用户空间的虚拟地址
ret = vm_insert_page(vma, user_page_addr, page[0]);//为应用空间的这段虚拟地址建立虚拟到物理的映射
if (ret) { //至此应用空间和内核空间都映射到了同一块物理页内存
printk(KERN_ERR "binder: %d: binder_alloc_buf failed "
"to map page at %lx in userspace\n",
proc->pid, user_page_addr);
goto err_vm_insert_page_failed;
}
/* vm_insert_page does not seem to increment the refcount */
}
if (mm) {
up_write(&mm->mmap_sem);
mmput(mm);
}
return 0;
free_range://释放影射
for (page_addr = end - PAGE_SIZE; page_addr >= start;
page_addr -= PAGE_SIZE) {
page = &proc->pages[(page_addr - proc->buffer) / PAGE_SIZE];//得到该段虚拟地址对应的struct page结构体
if (vma)
zap_page_range(vma, (uintptr_t)page_addr +//拆除应用空间的映射表
proc->user_buffer_offset, PAGE_SIZE, NULL);
err_vm_insert_page_failed://查出内核空间的映射表
unmap_kernel_range((unsigned long)page_addr, PAGE_SIZE);
err_map_kernel_failed://释放对应的物理内存页,这样这块物理内存页又可以被系统其他地方使用了
__free_page(*page);
*page = NULL;
err_alloc_page_failed:
;
}
err_no_vma:
if (mm) {
up_write(&mm->mmap_sem);
mmput(mm);
}
return -ENOMEM;
}3. Client发送请求,这个请求将先放到驱动中,同时需要将数据从Client进程的用户空间拷贝(通过调用linux系统函数copy_from_user)到内核空间。
4. 驱动通过请求通知Server端有人发出请求,Server进行处理。由于内核空间和Server端进程的用户空间存在内存映射(它们都指向同一块物理内存),因此Server进程的代码可以直接访问。这样便完成了一次进程间的通信。
示例图:

四. 待更新
由于笔者的工作的方向不是bsp层, 底层的源码看到比较蒙圈, 目前只能理解到这里了,
后面有新的正确理解再更新进来, 文章中如果有写的不对的地方请在评论区更正, 也欢迎一起探讨,
谢谢!