Golang并发编程
文章目录
- Golang并发编程
- 1. 协程
- 2. channel
- 2.1 channel的创建
- 2.2 使用waitGroup实现同步
- 3. 并发编程
- 3.1 并发编程之runtime包
- 3.2 mutex互斥锁
- 3.3 channel遍历
- 3.3.1 for + if遍历
- 3.3.2 for range
- 3.4 select switch
- 3.5 Timer
- 3.5.1 time.NewTimer()
- 3.5.2 Stop、reset
- 3.6 ticker
- 4. 原子操作
- 4.1 原子操作使用
- 4.2 原子操作原理
- 4.2.1 增减操作
- 4.2.2 载入、存储、cas
笔者在学习golang之前就听过不少golang并发的东西,应该说golang的goroutine也就是我们所说的协程,是golang这门语言最具竞争力的优势之一
Go语言中的并发程序主要是通过基于CSP(communicating sequential processes)的goroutine和channel来实现,当然也支持使用传统的多线程共享内存的并发方式
在开始之前让我们回顾一下Java中的并发模型:
共享内存模型,顾名思义就是通过共享内存来实现并发的模型,当多个线程在并发执行中使用共享资源时如不对所共享的资源进行约定或特殊处理时就会出现读到脏数据、无效数据等问题;而为了决解共享资源所引起的这些问题,Java中引入了同步、锁、原子类型等这些用于处理共享资源的操作
-
优点:内存共享模型或称线程与锁模型使用面很广,而且现在几乎每个操作系统中也存在这种模型,所以也算非常见的一种模型。
-
缺点:线程与锁模型存在的一些问题有,没有直接支持并发、无法或难于实现分布式共享内存的系统,线程与锁模型有非常不好的地方就是难于测试,在多线程编程中很多时候不经意间就出现问题了这时都还不知道,而且当突然出现了Bug这时往往我们也难于重现这个Bug,共享内存模型又是不可建立数学模型的,其中有很大的不确定性,而不确定性就说明可能掩藏着问题,人的思维也只是单线程的;
还有由于创建线程也是非常消耗资源的,而多线程间的竟态条件、锁等竞争如果处理不好也是会非常影响性能的
1. 协程
golang中的并发是函数相互独立的能力。Goroutines是并发运行的函数。golang提供了Goroutines作为并发处理操作的一种方式
创建一个协程非常简单,就是在一个任务函数前添加一个go关键字:
go task()
举个栗子:
package main
import (
"fmt"
"time"
)
func main() {
showMsg("java")
showMsg("golang")
}
func showMsg(msg string) {
for i := 0; i < 5; i++ {
fmt.Printf("%v:【%v】 \n", msg, i)
// 休眠100ms
time.Sleep(time.Millisecond * 100)
}
}
我们知道程序是从上往下执行的,所以结果为:
java:【0】
java:【1】
java:【2】
java:【3】
java:【4】
golang:【0】
golang:【1】
golang:【2】
golang:【3】
golang:【4】
当我们使用go关键字启动协程来执行后:
func main() {
// 通过go关键字启动协程来执行
go showMsg("java")
showMsg("golang")
}
java:【0】
golang:【0】
golang:【1】
java:【1】
java:【2】
golang:【2】
java:【3】
golang:【3】
java:【4】
golang:【4】
其实现在就是这样的运行,之前只有主协程在运行,现在多开启了一个协程运行:

2. channel
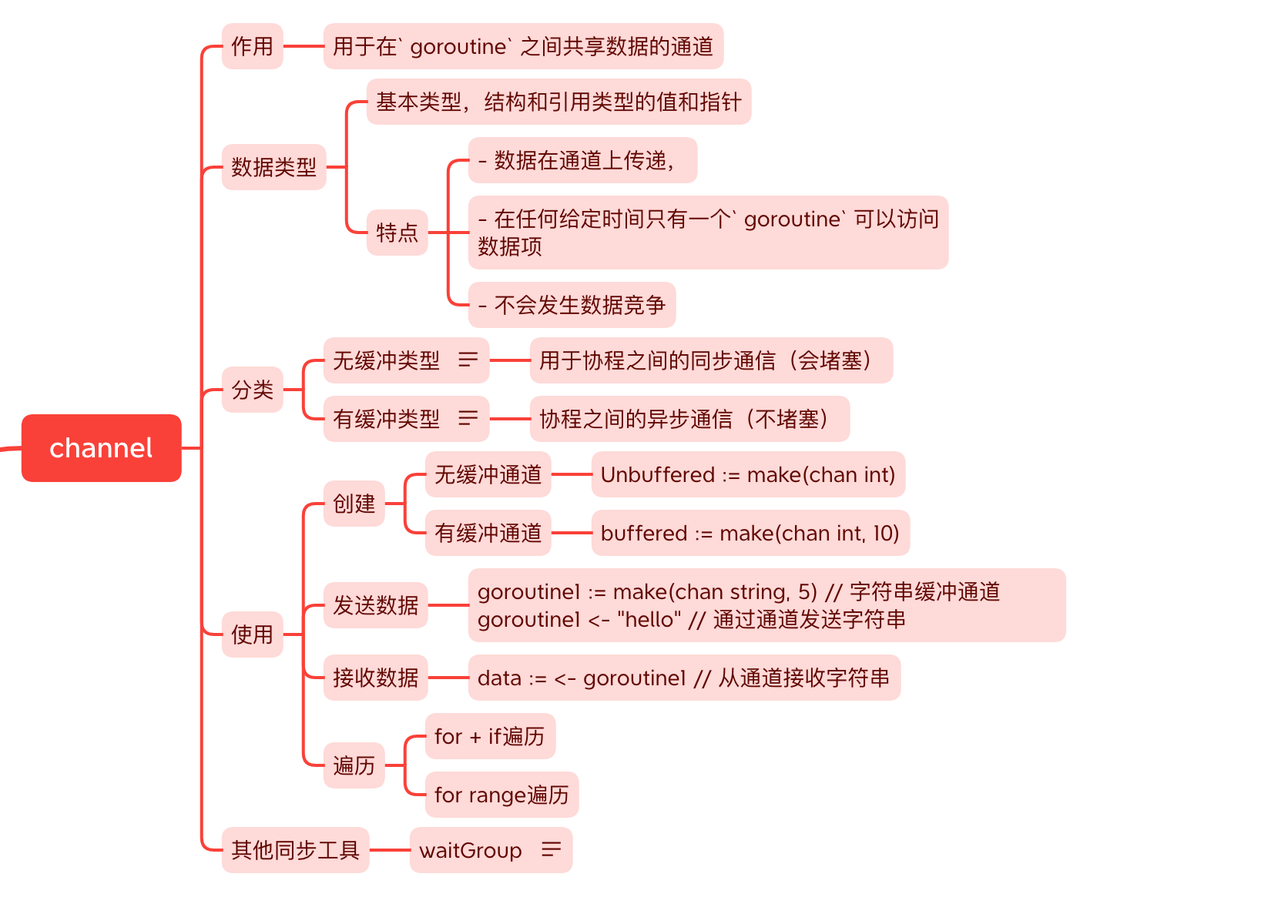
golang提供了一种称之为通道的机制,用于在goroutine之间共享数据。当您作为goroutine执行并发活动时,需要在goruntine之间共享资源或数据,通道充当goroutine之间的通道(管道)并提供一种机制来保证同步交换
需要在申明通道时指定数据类型。我们可以共享内置、命名、结构和引用类型的值和指针。
- 数据在通道上传递,
- 在任何给定时间只有一个
goroutine可以访问数据项 - 不会发生数据竞争
根据数据交换的行为,有两种类型的通道:
- 无缓冲通道
- 缓存通道
无缓冲通道用于执行goroutine之间的同步通信,而缓冲通道用于执行异步通信。无缓冲通道保证在发送和接收发生的瞬间执行两个goroutine之间的交换。
缓冲通道没有以上的保证
-
无缓冲区
在无缓冲通道中,在接收到任意值之前没有能力保存它。在这种类型的通道中,发送和接收
goroutine在任何发送或接收操作完成之前的同一时刻都准备就绪。如果两个goruntine没有在同一时刻准备好,则通道会让执行其各自发送或接收操作的goroutine首先等待。同步是通道上发送和接收之间交互的基础。没有另一个就不可能发生 -
缓冲通道
在缓冲通道中,有能力在接收到一个或多个值之前保存它们。在这种类型的通道中,不要强制
goroutine在同一时刻准备好执行发送和接收。当发送或接收堵塞时也有不同的条件。只有当通道中没有要接收的值时,接收才会堵塞
通道由make函数创建,该函数指定chan关键字和通道的元素类型
通道发送和接收特性
- 对于同一个通道,发送操作之间是互斥的,接收操作之间也是互斥的
- 发送操作和接收操作中对元素值的处理都是不可分割的
- 发送操作在完全完成之前会被堵塞。接收操作也是如此
2.1 channel的创建
创建语法
Unbuffered := make(chan int) // 整型无缓冲通道
buffered := make(chan int, 10) // 整型有缓冲通道
使用内置函数make创建无缓冲和缓冲通道。make的第一个参数需要关键字chan,然后是通道允许交换的数据类型
-
将值发送到通道的代码块需要使用
<-运算符goroutine1 := make(chan string, 5) // 字符串缓冲通道 goroutine1 <- "hello" // 通过通道发送字符串上述代码创建了一个包含5个值的缓冲区的字符串类型的
goroutine1通道。然后我们可以通过通道发送字符串 -
从通道接收值
data := <- goroutine1 // 从通道接收字符串<-运算符附加到通道变量goroutine1的左侧,以接收来自通道的值
举个例子:
package main
import (
"fmt"
"math/rand"
"time"
)
func main() {
// 从通道接收值
// 当主函数退出后关闭通道
defer close(values)
// 启动协程
go send()
fmt.Println("wait...")
// 从channel中拿到值
value := <-values
fmt.Printf("receive:【%v】 \n", value)
fmt.Println("end...")
}
// 创建一个channel,指定只能传输int值
var values = make(chan int)
func send() {
rand.Seed(time.Now().UnixNano())
value := rand.Intn(10)
fmt.Printf("send:【%v】 \n", value)
time.Sleep(time.Second * 5)
// 向channel中发送数据
values <- value
}
2.2 使用waitGroup实现同步
先看个栗子
package main
import (
"fmt"
)
func main() {
for i := 0; i < 10; i++ {
// 每次都启动协程去执行
go showMsg(i)
}
// 主协程退出,其他协程也会退出
fmt.Println("end...")
}
func showMsg(i int) {
fmt.Printf("i=%v \n", i)
}
输出:
end...
我们看到因为协程之间没有同步,所以当主协程退出时,其他协程还没有执行完也会跟着一起退出
怎么解决呢?我们可以使用waitGroup进行解决
package main
import (
"fmt"
"sync"
)
func main() {
for i := 0; i < 10; i++ {
// 每次都启动协程去执行
// 通过channel等待数据,从而实现同步
wp.Add(1)
go showMsg(i)
}
// 主协程退出,其他协程也会退出
// 主协程等待子协程的退出
wp.Wait()
fmt.Println("end...")
}
// 定义一个waitGroup
var wp sync.WaitGroup
func showMsg(i int) {
// 使用waitGroup进行同步,每次调用都-1,跟countDownLatch差不多
defer wp.Add(-1)
// 也可以使用wp.Done()
fmt.Printf("i=%v \n", i)
}
i=0
i=5
i=2
i=4
i=6
i=7
i=9
i=8
i=1
i=3
end...
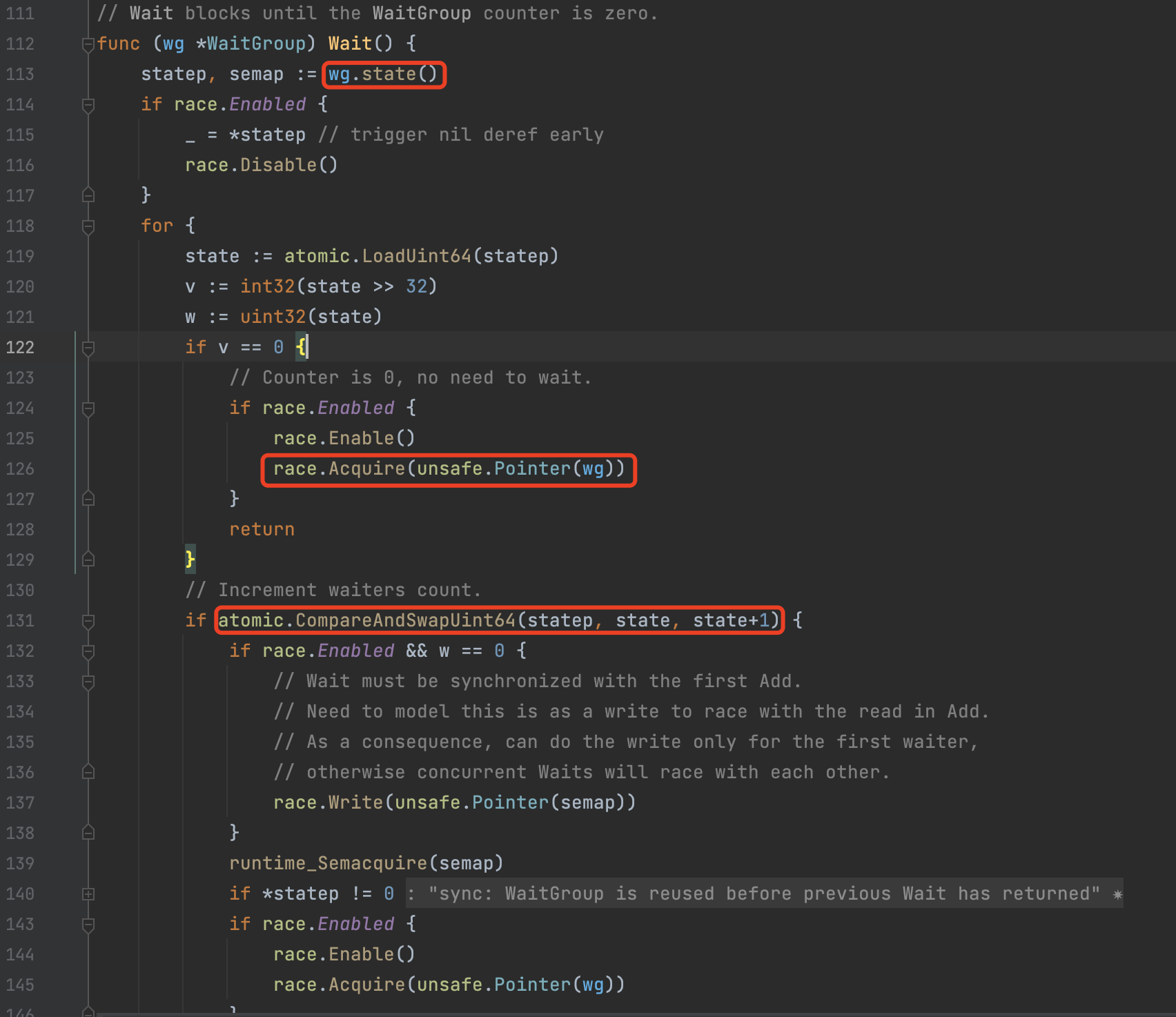
可以看到我们通过waitGroup实现了线程同步,我们可以感受到其实这个特别想java中的countDownLatch,在java中为了解决并发的问题,countDownLatch底层使用的cas乐观锁来保证线程安全,通过unsafe类进行capareAndSwap,保证操作的原子性
我们来看一下waitGroup的源码会发现,好家伙,不能说有点像,只能说一摸一样
3. 并发编程

3.1 并发编程之runtime包
runtime包里面定义了一些与协程管理相关的api
概览:
- runtime.Gosched():让出cpu时间片,重新等待安排任务
- runtime.Goexit():让协程退出,主协程也会一起退出
- runtime.GOMAXPROCS:设置最大协程个数
具体代码示例
-
runtime.Gosched()
让出cpu时间片,重新等待安排任务
package main import ( "fmt" "runtime" ) func main() { go show("java") for i := 0; i < 2; i++ { // 让出时间片,等待其他协程先执行 runtime.Gosched() fmt.Println("golang") } fmt.Println("end...") } func show(msg string) { for i := 0; i < 2; i++ { fmt.Printf("msg:%v \n", msg) } }但是并不能严格保证执行的顺序
msg:java golang msg:java golang end... // 也有可能是这样的 msg:java msg:java golang golang end... -
runtime.Goexit()
func main() { go show2() time.Sleep(time.Second) } func show2() { for i := 0; i < 10; i++ { fmt.Printf("i:%v \n", i) if i > 5 { // 让协程退出,主协程也会一起退出 runtime.Goexit() } } } // 输出 i:0 i:1 i:2 i:3 i:4 i:5 i:6 -
runtime.GOMAXPROCS
package main import ( "fmt" "runtime" "time" ) func main() { fmt.Printf("cpu num is:%v \n", runtime.NumCPU()) // 设置并发的协程数为1 runtime.GOMAXPROCS(1) go a() go b() time.Sleep(time.Second) } func a() { for i := 0; i < 10; i++ { fmt.Printf("A:%v \n", i) } } func b() { for i := 0; i < 10; i++ { fmt.Printf("B:%v \n", i) } } // 输出 cpu num is:4 B:0 B:1 B:2 B:3 B:4 B:5 B:6 B:7 B:8 B:9 A:0 A:1 A:2 A:3 A:4 A:5 A:6 A:7 A:8 A:9
3.2 mutex互斥锁
除了使用channel管道实现线程同步之外,还可以使用mutex互斥锁进行线程之间的同步
package main
import "fmt"
func main() {
for i := 0; i < 100_000; i++ {
go add()
sub()
}
}
// 共享资源
var i int = 100
func add() {
i++
fmt.Printf("add,i:%v \n", i)
}
func sub() {
i--
fmt.Printf("sub,i=%v \n", i)
}
最后的结果:
sub,i=-331
现在并发操作并不是原子的,有数据不一致的问题
那么如何解决呢?可以通过加mutex互斥锁的方式
package main
import (
"fmt"
"sync"
"time"
)
func main() {
for i := 0; i < 1_000; i++ {
wg.Add(1)
go add()
wg.Add(1)
go sub()
}
wg.Wait()
}
// 共享资源
var i int = 100
var wg sync.WaitGroup
var lock sync.Mutex
func add() {
defer wg.Done()
// 加锁互斥,add的时候不允许sub
lock.Lock()
i++
fmt.Printf("add,i:%v \n", i)
// 执行完等待10ms
time.Sleep(time.Millisecond * 10)
lock.Unlock()
}
func sub() {
defer wg.Done()
// 加锁互斥,sub的时候不允许add
lock.Lock()
i--
fmt.Printf("sub,i=%v \n", i)
// 执行完等待2ms
time.Sleep(time.Millisecond * 2)
lock.Unlock()
}
3.3 channel遍历
3.3.1 for + if遍历
我们先来看一下当我们使用channel进行协程之前数据同步,但是发送和接收数量不对等时会发生什么
- 写大于等于读,不会有问题
- 写小于读,会有问题
以下案例中写了一次,但是却读了两次
package main
import "fmt"
func main() {
go func() {
for i := 0; i < 1; i++ {
c <- i
}
}()
// 读取缓冲区内的数据
r := <-c
fmt.Printf("r=%v \n", r)
// 读第二次
r = <-c
fmt.Printf("r=%v \n", r)
}
var c = make(chan int)
输出:
r=0
fatal error: all goroutines are asleep - deadlock!
goroutine 1 [chan receive]:
main.main()
/Users/fengyuan-liang/workspace/goland/study/study_thread/channel/test_channel_iterate.go:15 +0xac
可以看到发生了死锁,因为发送一次接收一次channel才会关闭,这里显然少了一次接收,就发生了死锁
我们可以发送发消息后可以主动关闭channel
go func() {
// 主动关闭通道
defer close(c)
for i := 0; i < 1; i++ {
c <- i
}
}()
// 读取缓冲区内的数据
r := <-c
fmt.Printf("r=%v \n", r)
// 读第二次
r = <-c
fmt.Printf("r=%v \n", r)
// 输出,第一个值是读取到的值,第二个值是channel关闭后取了int的默认值
r=0
r=0
遍历的方式和下一小节一起演示
3.3.2 for range
package main
import "fmt"
func main() {
go func() {
defer close(c)
for i := 0; i < 10; i++ {
c <- i
}
}()
// 第一种方式:读取缓冲区内的数据
for value := range c {
fmt.Printf("value:%v \n", value)
}
// 第二种方式:死循环读取
for {
v, ok := <-c
if ok {
fmt.Printf("v=%v \n", v)
} else {
// 没有读到直接退出
break
}
}
}
var c = make(chan int)
3.4 select switch
-
select是Go中的一个控制结构,类似于
switch语句,用于处理异步IO操作。select会监听case语句中channel的读写操作,当case中channel读写操作作为非堵塞状态(即能读写)时,将会触发相应的动作select中的case语句必须是一个
channel操作select中的
default子句总是可运行的 -
如果有多个
case都可以运行,select会随机公平地宣传一个执行,其他不会执行 -
如果没有可以运行的
case语句,且有defalut语句,那么就会执行defalut的动作 -
如果没有可以运行的
case语句,且没有defalut语句,select将阻塞,直到某个case通信可以运行 -
通道关闭后,会随机进入一个case,读出来的会是默认值。通道没关闭,会进入default。通道没关闭并且没写default会死锁。
举个栗子:
package main
import (
"fmt"
"time"
)
func main() {
go func() {
defer close(chanInt)
defer close(chanStr) // 主动关闭后没有读到会显示默认值
chanInt <- 100
chanStr <- "hello"
}()
for {
select {
case r := <-chanInt:
fmt.Println(r)
case r := <-chanStr:
fmt.Println(r)
default: // 如果去掉defalut,channel又没有默认值,就会发生死锁
fmt.Println("没有读到...")
}
time.Sleep(time.Second)
}
}
var chanInt = make(chan int)
var chanStr = make(chan string)
3.5 Timer
3.5.1 time.NewTimer()
Timer顾名思义,就是定时器的意思,可以实现一些定时操作,内部也是通过channel来进行实现
例如我要实现一个等待两秒的操作:
package main
import (
"fmt"
"time"
)
func main() {
timer := time.NewTimer(time.Second * 2)
fmt.Printf("time is:%v \n", time.Now())
// 堵塞中,直到时间到了
t1 := <-timer.C
fmt.Println("两秒钟后...")
fmt.Printf("t1:%v \n", t1)
}
// 打印输出
time is:2023-01-15 20:45:29.048689 +0800 CST m=+0.000103485
两秒钟后...
t1:2023-01-15 20:45:31.049711 +0800 CST m=+2.001108436
当然我们如果只是休眠可以直接使用time.Sleep(time.Second)来实现
我们也可以使用time.After()来实现定时操作
fmt.Printf("this time is:%v \n", time.Now())
// 也可以使用after进行延迟操作
<-time.After(time.Second * 2)
fmt.Println("两秒钟后...")
fmt.Printf("this time is:%v \n", time.Now())
3.5.2 Stop、reset
timer := time.NewTimer(time.Second * 2)
go func() {
<-timer.C
fmt.Println("func...")
}()
// 调用stop方法,暂停记时
isStop := timer.Stop()
if isStop {
fmt.Println("time is stop")
}
time.Sleep(time.Second * 3)
fmt.Println("main end...")
打印:
time is stop
main end...
可以看time.Stop()是让其他线程的timer停了,主线程的并不会停
如果我们想要重新计时就可以使用time.Reset(time.Second)来进行
timer := time.NewTimer(time.Second * 5)
// 之前设置的是五秒钟,现在可以重新进行设置
fmt.Printf("this time is:%v \n", time.Now())
timer.Reset(time.Second * 1)
// 堵塞 直到时间到了
<-timer.C
fmt.Printf("this time is:%v \n", time.Now())
输出
this time is:2023-01-15 22:08:44.529515 +0800 CST m=+0.000120579
this time is:2023-01-15 22:08:45.530782 +0800 CST m=+1.001387985
3.6 ticker
timer只执行一次,ticker可以周期执行
举个例子:
package main
import (
"fmt"
"time"
)
func main() {
ticker := time.NewTicker(time.Second)
for range ticker.C {
fmt.Println("ticker...")
}
}
然后就会一秒执行一次,类似于js里面的setInterval,而timer类似于setTimeOut
4. 原子操作
在之前的栗子中我们发现多个协程同时操作一个变量时会发生脏写的问题,之前我们是通过加互斥锁mutex进行解决的
在这里我们引入一些原子操作类,进行原子操作,从而保证线程安全
4.1 原子操作使用
package main
import (
"fmt"
"sync/atomic"
"time"
)
func main() {
func() {
for i := 0; i < 1_000_000; i++ {
go add()
go sub()
}
}()
time.Sleep(time.Second * 2)
fmt.Println("end, cnt = ", cnt)
}
var cnt int32 = 100
func add() {
// cnt++并不是原子操作,换成原子操作
atomic.AddInt32(&cnt, 1)
}
func sub() {
atomic.AddInt32(&cnt, -1)
}
输出:
end, cnt = 100
4.2 原子操作原理
atomic提供的原子操作能够确保任一时刻只有一个goroutine对变量进行操作,善用atomic能够避免程序中出现大量的锁操作
常见的atomic操作有:
- 增减
- 载入(read)
- 存储(store)
- cas(比较并交换)
- 交换
4.2.1 增减操作
atomic包中提供了如下以Add为前缀的增减操作:
- func AddInt32(addr *int32, delta int32) (new int32)
- func AddInt64(addr *int64, delta int64) (new int64)
- func AddUint32(addr *uint, delta uint32) (new uint32)
- func AddUint64(addr *uint, delta uint64) (new uint64)
- func AddUintptr(addr *uintptr, delta uintptr) (new uintptr)
4.2.2 载入、存储、cas
载入就是读取,在读的时候容易出现并发问题,其实这就是java中用volatile关键字来保证线程可见性一样
那么golang是如何解决多线程间数据不一致问题的呢?就是通过原子载入的方式
package main
import (
"fmt"
"sync/atomic"
)
func main() {
var cnt int32 = 100
// 原子读
cnt = atomic.LoadInt32(&cnt)
fmt.Println("原子读读取到的数据,cnt = ", cnt) // 原子读读取到的数据,cnt = 100
// 原子写
atomic.StoreInt32(&cnt, 1)
fmt.Println("原子读读取到的数据,cnt = ", atomic.LoadInt32(&cnt)) // 原子读读取到的数据,cnt = 1
// cas
ok := atomic.CompareAndSwapInt32(&cnt, 1, 2)
fmt.Println("cas 结果:", ok) // cas 结果: true
fmt.Println("cas后的数据,cnt = ", atomic.LoadInt32(&cnt)) // cas后的数据,cnt = 2
}
nt64) (new int64)
- func AddUint32(addr *uint, delta uint32) (new uint32)
- func AddUint64(addr *uint, delta uint64) (new uint64)
- func AddUintptr(addr *uintptr, delta uintptr) (new uintptr)
#### 4.2.2 载入、存储、cas
载入就是读取,在读的时候容易出现并发问题,其实这就是java中用`volatile`关键字来保证线程可见性一样
那么golang是如何解决多线程间数据不一致问题的呢?就是通过原子载入的方式
```go
package main
import (
"fmt"
"sync/atomic"
)
func main() {
var cnt int32 = 100
// 原子读
cnt = atomic.LoadInt32(&cnt)
fmt.Println("原子读读取到的数据,cnt = ", cnt) // 原子读读取到的数据,cnt = 100
// 原子写
atomic.StoreInt32(&cnt, 1)
fmt.Println("原子读读取到的数据,cnt = ", atomic.LoadInt32(&cnt)) // 原子读读取到的数据,cnt = 1
// cas
ok := atomic.CompareAndSwapInt32(&cnt, 1, 2)
fmt.Println("cas 结果:", ok) // cas 结果: true
fmt.Println("cas后的数据,cnt = ", atomic.LoadInt32(&cnt)) // cas后的数据,cnt = 2
}