PaddlePaddle是百度公司提出的深度学习框架。近年来深度学习在很多机器学习领域都有着非常出色的表现,在图像识别、语音识别、自然语言处理、机器人、网络广告投放、医学自动诊断和金融等领域有着广泛应用。面对繁多的应用场景,深度学习框架有助于建模者节省大量而繁琐的外围工作,更聚焦业务场景和模型设计本身。
写在前面
首先我们先去下载github下载源码:
https://github.com/PaddlePaddle
随后我们进入Paddle的官网地址 (很重要)
https://www.paddlepaddle.org.cn/
这里一定要按照官网给出的版本进行对应。
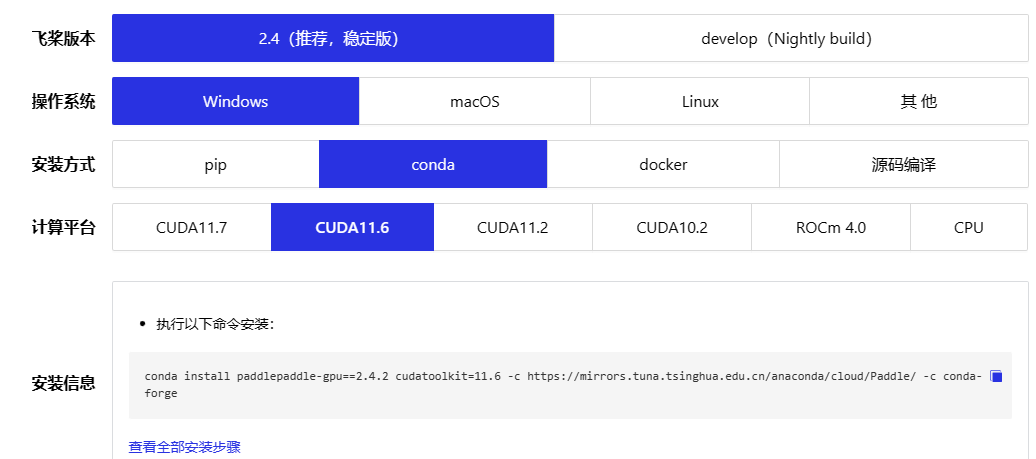
前期准备
博主先前装的是CUDA11.7,但总是出问题,根本原因是这个CUDA是打游戏时使用的,而非我们在做专业计算时使用的,随后博主安装的CUDA版本为11.6,对应的cudnn为8.4。
具体安装教程可以参考博主这篇博文:
https://blog.csdn.net/pengxiang1998/article/details/127673591
CUDA下载地址:
https://developer.nvidia.com/cuda-toolkit-archive
cudnn下载地址:
https://developer.nvidia.com/rdp/cudnn-archive
值得一提的是,CUDA的安装与你的显卡以及系统版本有关,比如30系显卡只能安装CUDA11以上,而 CUDA11.2 最高只能支持到 Windows10 版本
将这些CUDA环境安装好后我们就可以开始配置对应的CUDA虚拟环境了。
环境配置
首先是创建cuda环境
conda create -n paddle python=3.7
随后切换到项目主目录,安装requirement中指定的依赖包
pip install -r requirements.txt --index-url https://pypi.douban.com/simple
这个时间可能需要很久,耐心等待。
此时我们可以另开一个cmd窗口来安装paddle,大家按照官网给定的版本命令来执行即可,博主是CUDA11.6
conda install paddlepaddle-gpu==2.4.2 cudatoolkit=11.6 -c https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/Paddle/ -c conda-forge
随后安装完成,此时我们的环境就基本没有什么问题了,接下来便是调试程序了。
代码调试
paddle中给我们了详细的步骤,我们安装其要求来即可。(呜呜呜,虽然如此,这个项目连同环境配置到代码调试花费了我一整天的时间)
首先是数据集准备,博主使用的是Cityscapes数据集。
在这里博主用血和泪的教训告诉大家一定要了解你所用的数据集,否则你会遇到许多不必要的麻烦。
数据集介绍
Cityscapes大致有两个数据集,分别为精细的标注数据集(3475张训练图像,1525张测试图像)和粗糙的标注数据集(3475+19888张额外的粗糙标注),共19个类别,我们一般只使用精确的那个。
该数据集下载时需要使用到一个edu邮箱账号,如果没有的话可以去淘宝上买一个,或者找下网盘资源。
下载完成后主要用到的就是这两个文件,分别是语义分割的标注文件与图像数据。

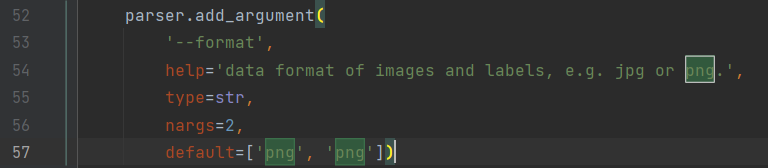
随后通过paddle项目中的tools/data/create_dataset_list.py来生成数据集,修改下数据集的地址与对应的format即可:

format是图片匹配格式,即根据图像后缀名匹配
生成格式为:
源数据图像 标注数据图像
分别生成train.txt,val.txt.test.txt文件在你指定的数据集目录下。
随后便是数据集配置文件的修改了,按照官方给出的提示,在config/quick_start/pp_liteseg_optic_disc_512x512_1k.yml内修改,这里可以自己如果使用自己的数据集再重新创建一下即可。
主要修改这里即可:
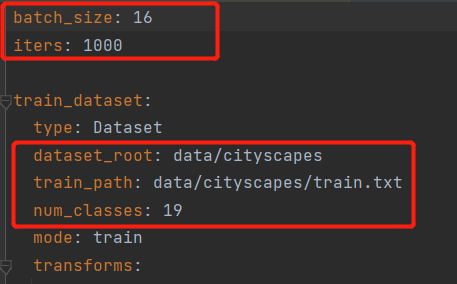
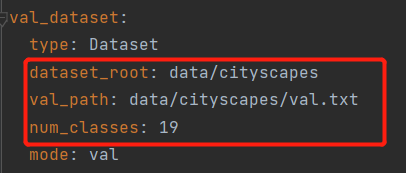
随后在train.py中指定一下数据集路径即可,然后我们便可以进行运行了。运行成功。
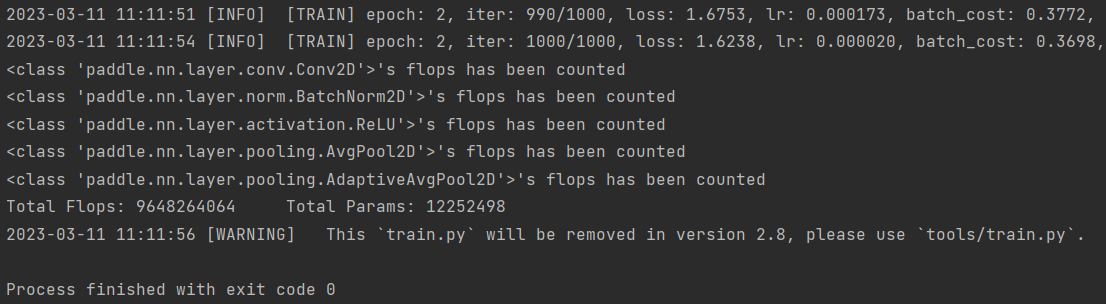
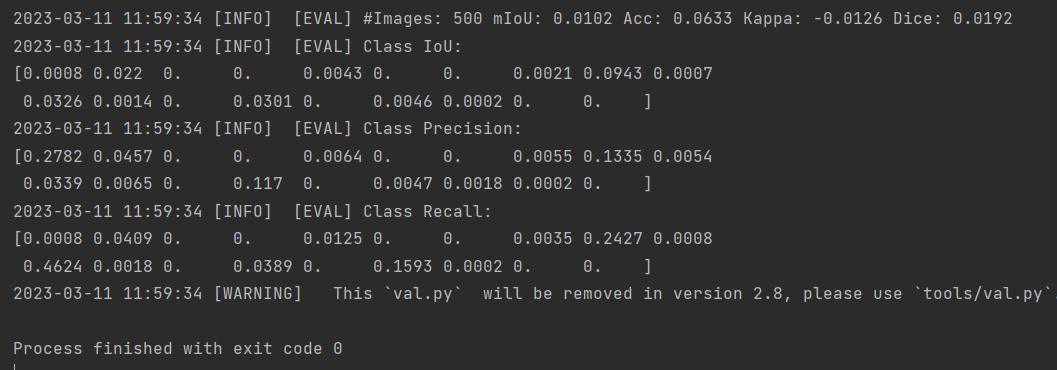
至于val.py,将数据集地址修改后也是手到擒来。


![[手撕数据结构]栈的深入学习-java实现](https://img-blog.csdnimg.cn/bec4322e33dd46e78ca00edfb2654de6.png)
![[洛谷-P3047] [USACO12FEB]Nearby Cows G(树形DP+换根DP)](https://img-blog.csdnimg.cn/5aa58266b0e548fa9ba3f5dbc44234c7.png)