合集目录:
前言
一、Dijkstra
二、Bellman-Ford与SPFA(本文)
三、Dijkstra与SPFA的比较
四、Floyd
五、启发式搜索
Bellman-Ford
1. 算法介绍
The algorithm was first proposed by Alfonso Shimbel (1955), but is instead named after Richard Bellman and Lester Ford Jr., who published it in 1958 and 1956, respectively. Edward F. Moore also published a variation of the algorithm in 1959, and for this reason it is also sometimes called the Bellman–Ford–Moore algorithm. ——WIKIPEDIA
Bellman-Ford算法也是用于解决单源最短路问题,不过与Dijkstra不同的是,它可以解决带有负权边的单源最短路。Bellman-Ford算法通过限制经过边的数量,对每一条边都进行松弛,从而逐步得到最优解。
在一个 n n n个点的图中,任意两个点之间的最短路径最多有 n − 1 n-1 n−1条边(暂不考虑负环)。我们还是构造一个 d i s [ i ] dis[i] dis[i]数组,表示源点 s s s到点 i i i的最短距离。在算法最外层有一个 n − 1 n-1 n−1层的循环,第 i i i层循环表示从源点 s s s至某点 k k k的最短距离最多只经过 i i i条边。在此前提下,在第 n − 1 n-1 n−1层我们就能得到答案。同时,我们对 d i s dis dis数组进行划分层次, d i s i dis^i disi表示第 i i i层的 d i s dis dis数组。接下来考虑如何更新 d i s dis dis数组。当 i = 1 i=1 i=1时, d i s i [ k ] = w [ s ] [ k ] dis^i[k]=w[s][k] disi[k]=w[s][k]( w [ s ] [ k ] w[s][k] w[s][k]为点 s s s至点 k k k的边的长度);在每次循环中,我们依次遍历每条边,记某条边的起点和终点分别为 a a a和 b b b,通过这条边来更新 b b b点的 d i s dis dis数组,也就是“松弛”操作,即 d i s i [ k ] = m i n ( d i s i − 1 [ k ] , d i s i − 1 + w [ a ] [ b ] ) dis^i[k]=min(dis^{i-1}[k], dis^{i-1}+w[a][b]) disi[k]=min(disi−1[k],disi−1+w[a][b])。
以洛谷P3371 【模板】单源最短路径(弱化版)为例(70pts,不能通过全部测试点):
#include <bits/stdc++.h>
#define A 500010
using namespace std;
int n, m, s, a[A], b[A];
long long dis[A], c[A];
void Bellman_ford(int s) {
for (int i = 1; i <= n; i++) dis[i] = pow(2, 31) - 1;
dis[s] = 0;
for (int i = 1; i < n; i++)
for (int j = 1; j <= m; j++)
if (dis[b[j]] > dis[a[j]] + c[j])
dis[b[j]] = dis[a[j]] + c[j];
}
int main(int argc, char const *argv[]) {
cin >> n >> m >> s;
for (int i = 1; i <= m; i++) scanf("%d%d%lld", &a[i], &b[i], &c[i]);
Bellman_ford(s);
for (int i = 1; i <= n; i++) printf("%lld ", dis[i]);
}
通过循环可以看出,Bellman-Ford的时间复杂度为 Θ ( n ⋅ m ) \Theta{(n·m)} Θ(n⋅m)。
2. 算法常见优化
在实际问题中,Bellman-Ford算法一般不需要做 n − 1 n-1 n−1层松弛操作就能得到最优解,因为最短路径经过的点数往往没有那么多,所以我们可以在某次循环不再进行松弛操作时,就直接退出循环。
for (int i = 1; i < n; i++) {
bool check = 0;
for (int j = 1; j <= m; j++)
if (dis[b[j]] > dis[a[j]] + c[j])
dis[b[j]] = dis[a[j]] + c[j], check = 1;
if (!check) break;
}
对代码做了这个小小的改动后,就可以通过上面的题目了。
另外还有队列优化,也就是SPFA,会在下文着重讲解。
3. 判断负环
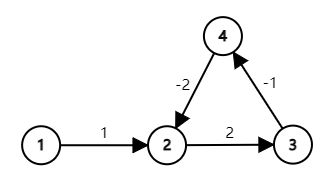
在这个图中,我们可以注意到有一个环,而且环中边权的和为负数,这就说明我们可以在环上走无数多次来达到更小的距离。这种情况下,最短路径是不存在的。在Bellman-Ford中,就体现为:第
n
n
n次松弛操作仍可得到更优的解。故可以通过下面的方式判断负环:
void Bellman_ford(int s) {
for (int i = 1; i <= n; i++) dis[i] = pow(2, 31) - 1;
dis[s] = 0;
for (int i = 1; i < n; i++) {
bool check = 0;
for (int j = 1; j <= m; j++)
if (dis[b[j]] > dis[a[j]] + c[j])
dis[b[j]] = dis[a[j]] + c[j], check = 1;
if (!check) break;
}
for (int j = 1; j <= m; j++)
if (dis[b[j]] > dis[a[j]] + c[j]) {
puts("Negative ring");
return;
}
}
4. 其他
Bellman-Ford算法容易理解且容易书写,但缺点就在于算法时间复杂度太高,所以在算法竞赛中很少见到它的身影。而它的队列优化版本SPFA,由于有着在稀疏随机图中优秀的时间复杂度,在算法竞赛中就较为重要。
SPFA
1. 算法介绍
可以确定,松弛操作必定只会发生在最短路径前导节点松弛成功的节点上,所以我们只用松弛成功的点在下一轮进行松弛,用一个队列记录松弛过的节点,避免了大量冗余计算。用一个 v i s [ i ] vis[i] vis[i]数组记录点 i i i是否在队列 q q q中,队列 q q q中是上一轮松弛成功的点,每次取出队列的队首,再用这个点进行松弛。
这是Bellman-Ford的队列优化版本,这种优化方式在1959年由Edward F. Moore作为广度优先搜索的扩展发表,所以也被称为Bellman-Ford-Moore算法。相同算法在1994年由段凡丁重新发现,他之前没有看过Moore的论文,所以给这种算法起了个通俗易懂的名字:Shortest Path Fast Algorithm。
#include <bits/stdc++.h>
#define A 1000010
using namespace std;
struct node{int next, to, w;}e[A];
int head[A], num;
void add(int fr, int to, int w) {
e[++num].next = head[fr]; e[num].to = to;
e[num].w = w; head[fr] = num;
}
int dis[A], n, m, s; bool vis[A];
void spfa(int s) {
memset(vis, 0, sizeof vis); for (int i = 1; i <= n; i++) dis[i] = INT_MAX;
dis[s] = 0; vis[s] = 1; queue<int> q; q.push(s);
while (!q.empty()) {
int fr = q.front(); q.pop(); vis[fr] = 0; // 将队首元素取出队列
for (int i = head[fr]; i; i = e[i].next) {
int ca = e[i].to;
if (dis[ca] > dis[fr] + e[i].w) {
dis[ca] = dis[fr] + e[i].w;
if (!vis[ca]) vis[ca] = 1, q.push(ca); // 将松弛成功的点加入队列
}
}
}
}
int main(int argc, char const *argv[]) {
cin >> n >> m >> s;
for (int i = 1; i <= m; i++) {
int a, b, c; scanf("%d%d%d", &a, &b, &c);
add(a, b, c);
}
spfa(s);
for (int i = 1; i <= n; i++) printf("%d ", dis[i]);
}
2. 常见优化
这两种优化方式都使用了deque双端队列。
(1)SLF优化(Small Label First)
直译过来是:小的元素放前面。类似堆优化的Dijkstra,优先松弛距离较小的点。
void spfa_SLF(int s) {
memset(vis, 0, sizeof vis); for (int i = 1; i <= n; i++) dis[i] = INT_MAX;
dis[s] = 0; vis[s] = 1; deque<int> q; q.push_back(s);
while (!q.empty()) {
int fr = q.front(); q.pop_front(); vis[fr] = 0;
for (int i = head[fr]; i; i = e[i].next) {
int ca = e[i].to;
if (dis[ca] > dis[fr] + e[i].w) {
dis[ca] = dis[fr] + e[i].w;
if (!vis[ca]) {
vis[ca] = 1;
if (q.empty() or dis[ca] > dis[q.front()]) q.push_back(ca);
else q.push_front(ca);
}
}
}
}
}
(2)LLL优化(Large Label Last)
直译过来是:大的元素放后面。LLL引入了平均值,距离大于平均值的节点会被移到队列尾端。前面的SLF是对入队做优化,LLL是对出队做优化,所以两者的说法并无冲突。
void spfa_LLL(int s) {
memset(vis, 0, sizeof vis); for (int i = 1; i <= n; i++) dis[i] = INT_MAX;
dis[s] = 0; vis[s] = 1; deque<int> q; q.push_back(s); int cnt = 1, sum = 0;
while (!q.empty()) {
int fr = q.front(); q.pop_front();
cnt--; sum -= dis[fr];
if (dis[fr] * cnt > sum) {
q.push_back(fr);
cnt++; sum += dis[fr];
continue;
}
vis[fr] = 0;
for (int i = head[fr]; i; i = e[i].next) {
int ca = e[i].to;
if (dis[ca] > dis[fr] + e[i].w) {
dis[ca] = dis[fr] + e[i].w;
if (!vis[ca]) {
vis[ca] = 1;
q.push_back(ca);
cnt++; sum += dis[ca];
}
}
}
}
}
(3)SLF+LLL优化
前面也说到两种优化并无冲突,所以可以结合起来使用,出队使用LLL,入队使用SLF。
这两种优化算法大都是直观的理解,为此我找到了LLL优化的论文出处,论文中做了数值实验,详细介绍了几种优化算法。
原论文:Parallel_asynchronous_label-correcting_methods_for_shortest_paths
(4)MinPoP优化
这个是我在翻论文时看到的,这篇论文以SPFA为基础,将新提出的这个优化算法与SLF优化进行比较。原文中也提到了,“the improved algorithm is a little more efficient than SPFA and its SLF optimization algorithm”,提升并不是很大。原论文:An_Improved_SPFA_Algorithm_for_Single-Source_Shortest_Path_Problem_Using_Forward_Star_Data_Structure
void spfa_MinPoP(int s) { // 根据伪代码写的代码
memset(vis, 0, sizeof vis); for (int i = 1; i <= n; i++) dis[i] = INT_MAX;
dis[s] = 0; vis[s] = 1; deque<int> q; q.push_back(s); int minn = INT_MAX;
while (!q.empty()) {
int p = 0;
int fr = q.front(); q.pop_front();
vis[fr] = 0;
for (int i = head[fr]; i; i = e[i].next) {
int ca = e[i].to;
if (dis[ca] > dis[fr] + e[i].w) {
dis[ca] = dis[fr] + e[i].w;
if (!vis[ca]) vis[ca] = 1, q.push_back(ca);
if (dis[ca] < minn) minn = dis[ca], p = ca;
}
}
if (p) q.push_front(p), vis[p] = 1;
}
}
3. 判断负环
类比Bellman-Ford的判断负环的方法, 一个点最多被松弛
n
−
1
n-1
n−1次,否则就一定存在负环。
洛谷P3385 【模板】负环:
#include <bits/stdc++.h>
#define A 10010
using namespace std;
struct node{int next, to, w;}e[A];
int head[A], num;
void add(int fr, int to, int w) {
e[++num].next = head[fr]; e[num].to = to;
e[num].w = w; head[fr] = num;
}
int dis[A], n, m, s, cnt[A]; bool vis[A];
void spfa(int s) {
memset(vis, 0, sizeof vis); for (int i = 1; i <= n; i++) dis[i] = INT_MAX;
dis[s] = 0; vis[s] = 1; queue<int> q; q.push(s);
while (!q.empty()) {
int fr = q.front(); q.pop(); vis[fr] = 0;
for (int i = head[fr]; i; i = e[i].next) {
int ca = e[i].to;
if (dis[ca] > dis[fr] + e[i].w) {
dis[ca] = dis[fr] + e[i].w;
if (!vis[ca]) {
if (++cnt[ca] >= n) {
puts("YES");
return;
}
vis[ca] = 1, q.push(ca);
}
}
}
}
puts("NO");
}
int main(int argc, char const *argv[]) {
int T; cin >> T;
while (T--) {
cin >> n >> m;
memset(head, 0, sizeof head); num = 0;
memset(cnt, 0, sizeof cnt);
for (int i = 1; i <= m; i++) {
int a, b, c; scanf("%d%d%d", &a, &b, &c);
if (c >= 0) add(a, b, c), add(b, a, c);
else add(a, b, c);
}
spfa(1);
}
}
4. 时间复杂度
SPFA的最坏时间复杂度与Bellman-Ford相同,可以在特殊数据(网格图、菊花图等)下达到 Θ ( n ⋅ m ) \Theta{(n·m)} Θ(n⋅m),可以将其看成是Bellman-Ford算法的特例情况,并没有对算法实质上的优化,所以有一些人不会承认SPFA。
5. 争议
在NOI2018D1T1归程中,出题人构造了特殊的数据,使得使用SPFA的选手从可以100分到了60分,并且在讲解题目时提出了“关于SPFA,它死了”这种说法。

这道题目当时在OI界引起了很大的争议,在这之后,如何构造出卡SPFA的数据被越来越多人熟知,也有人逐一卡掉了SPFA的优化算法,其实一切的根源还是SPFA的假复杂度。所以说正权图最好还是用堆优化Dijkstra。



![[手撕数据结构]栈的深入学习-java实现](https://img-blog.csdnimg.cn/bec4322e33dd46e78ca00edfb2654de6.png)
![[洛谷-P3047] [USACO12FEB]Nearby Cows G(树形DP+换根DP)](https://img-blog.csdnimg.cn/5aa58266b0e548fa9ba3f5dbc44234c7.png)