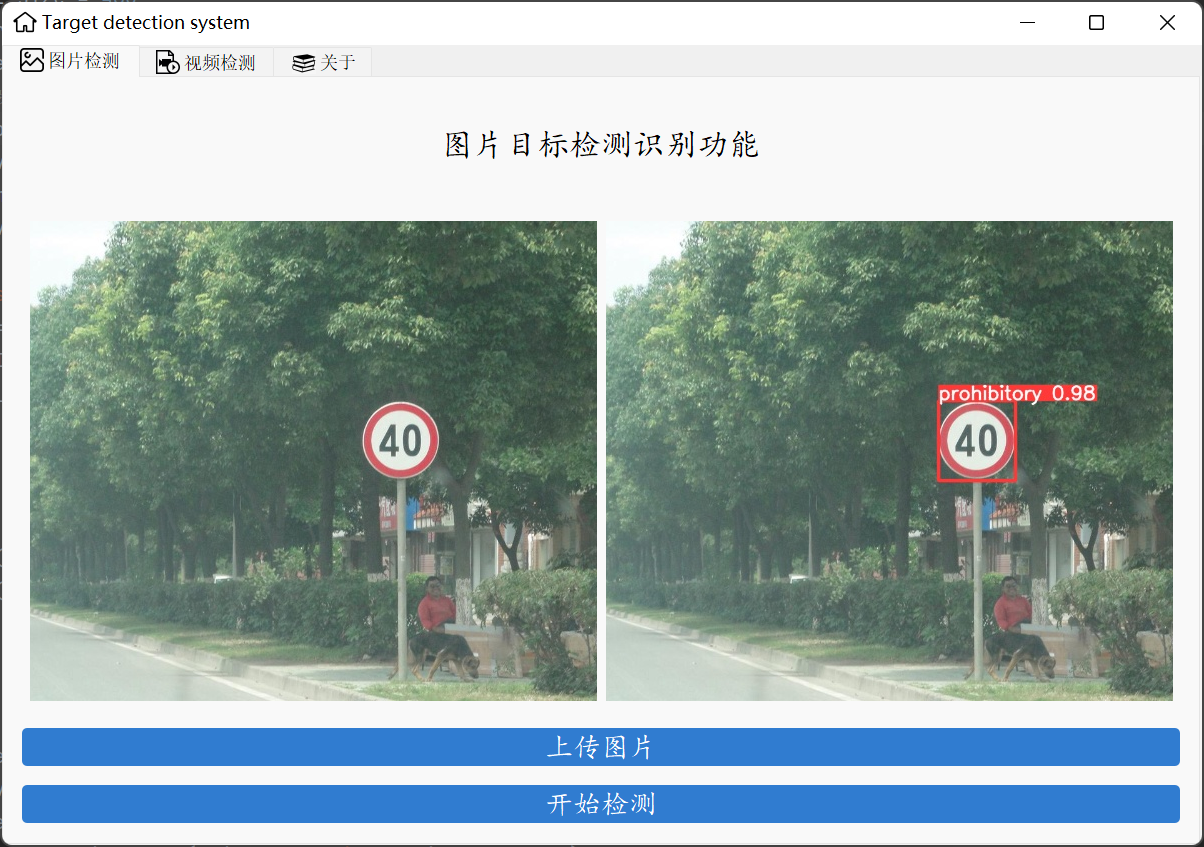
项目介绍
上一篇文章介绍了基于卷积神经网络的交通标志分类识别Python交通标志识别基于卷积神经网络的保姆级教程(Tensorflow),并且最后实现了一个pyqt5的GUI界面,并且还制作了一个简单的Falsk前端网页实现了前后端的一个简单交互,只能实现单张交通标志图像的分类,没有位置检测功能,并且不支持视频的实时检测识别,总体上来讲较为简单。本文介绍一个交通标志识别的进阶项目–基于Yolov5的交通标志检测识别,它不仅能实现图片的多目标检测识别还可以实现视频的实时检测识别。大家可以看一下视频展示效果如下链接
视频演示:交通标志检测视频演示

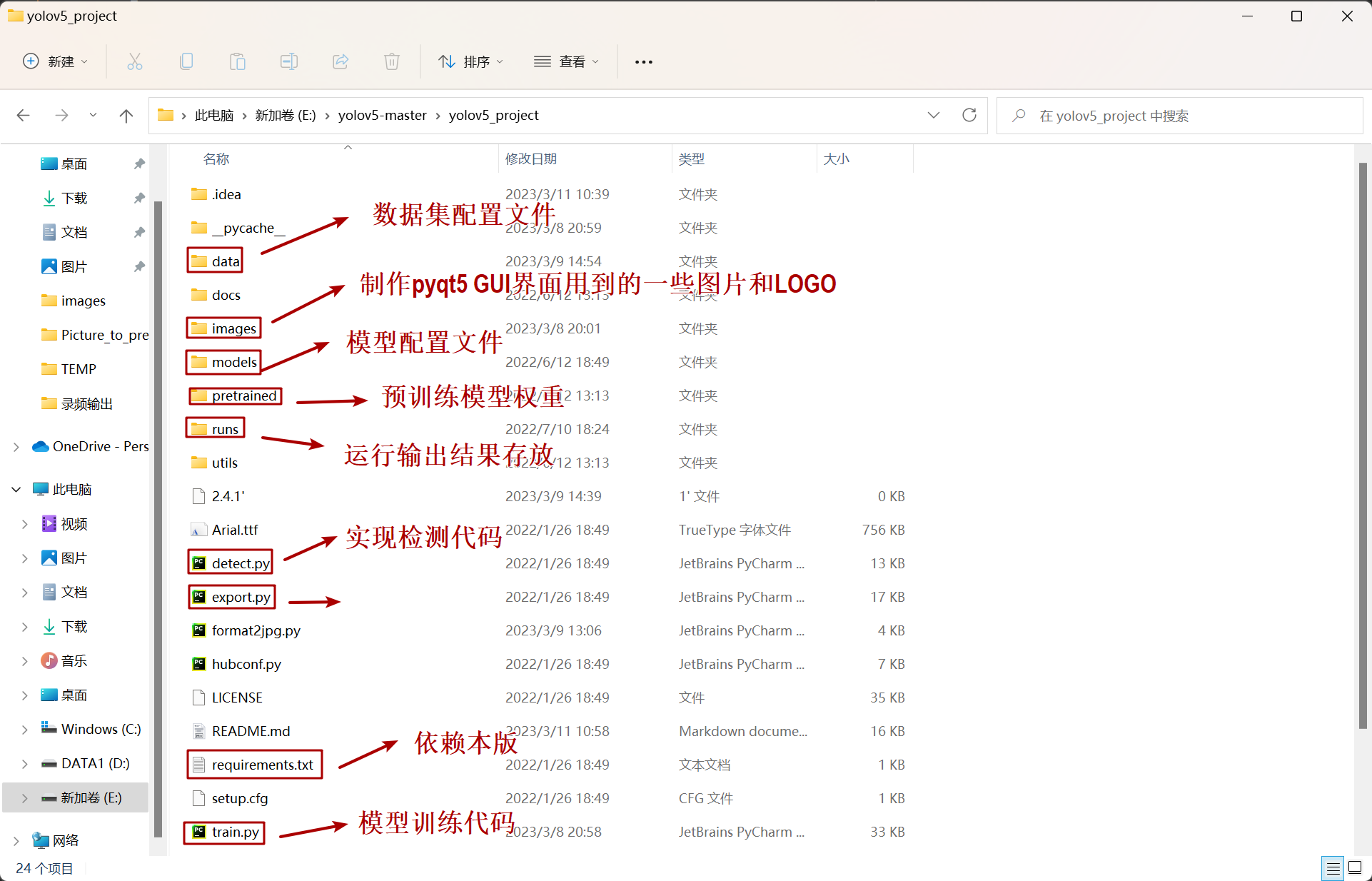
获取代码
创建虚拟环境
conda create -n yolov5 python=3.8.5
安装pytorch(如果不会弄GPU的直接安装CPU版本)
安装CPU版本torch
conda install pytorch==1.8.0 torchvision==0.9.0 torchaudio==0.8.0 cpuonly
安装GPU版本torch(以我个人为例:我的显卡是3060Ti,CUDA版本是11.7)
pip install torch==1.11.0+cu113 torchvision==0.12.0+cu113 torchaudio==0.11.0 --extra-index-url https://download.pytorch.org/whl/cu113
安装其他依赖库
pip install -r requirements.txt
pip install pyqt5==5.15.6
pip install pycocotools-windows==2.0.0.2
测试代码是否能跑
python detect.py --source data/images/traffic_sign.jpg --weights runs/train/exp7/weights/best.pt
项目文件夹data/images/bus.jpg图片在识别前的样子

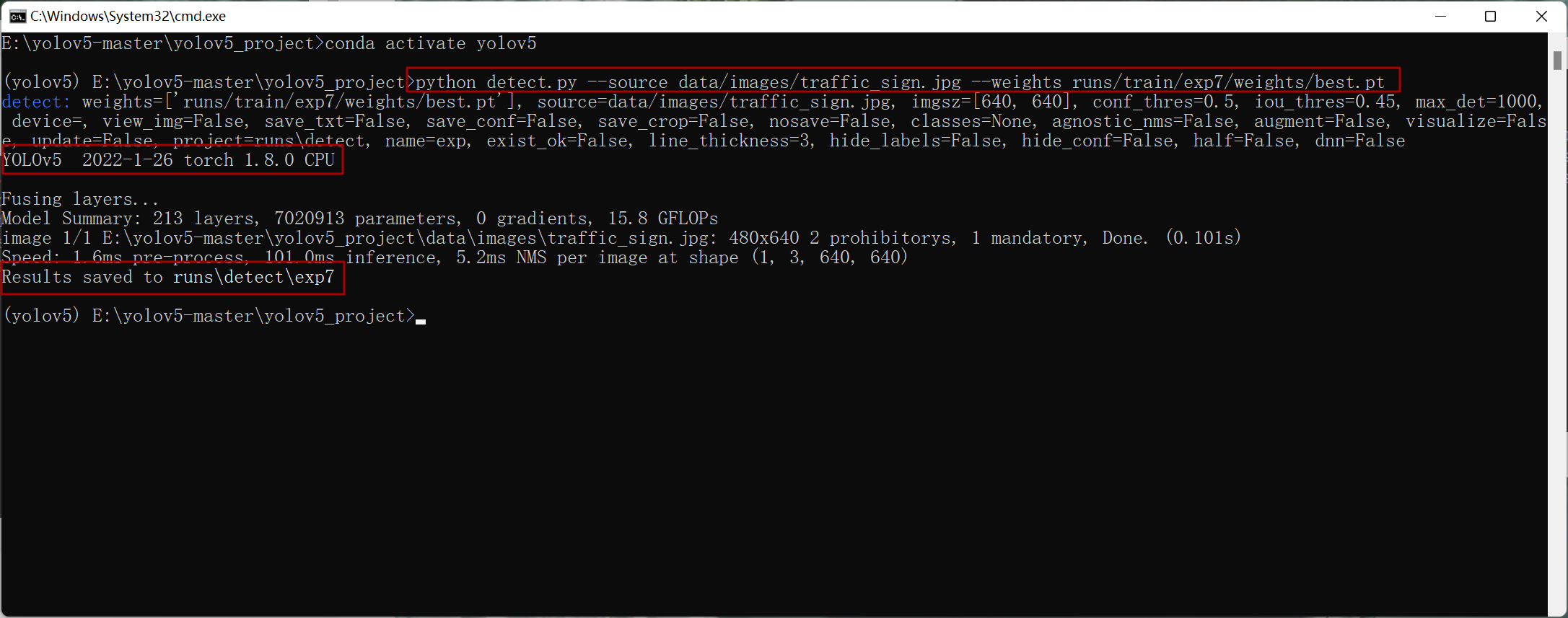
成功运行命令如上图显示信息所示:识别结果存在项目文件夹runs\detect\exp7文件中:

训练(可忽略)
接下来用pycharm打开项目,然后在Terminal中操作,输入以下命令
python train.py --data traffic_sign_data.yaml --cfg mask_yolov5s.yaml --weights pretrained/yolov5s.pt --epoch 100 --batch-size 4
训练比较耗时,我给的项目压缩包中是已经训练好的了。所以训练的步骤可以跳过。
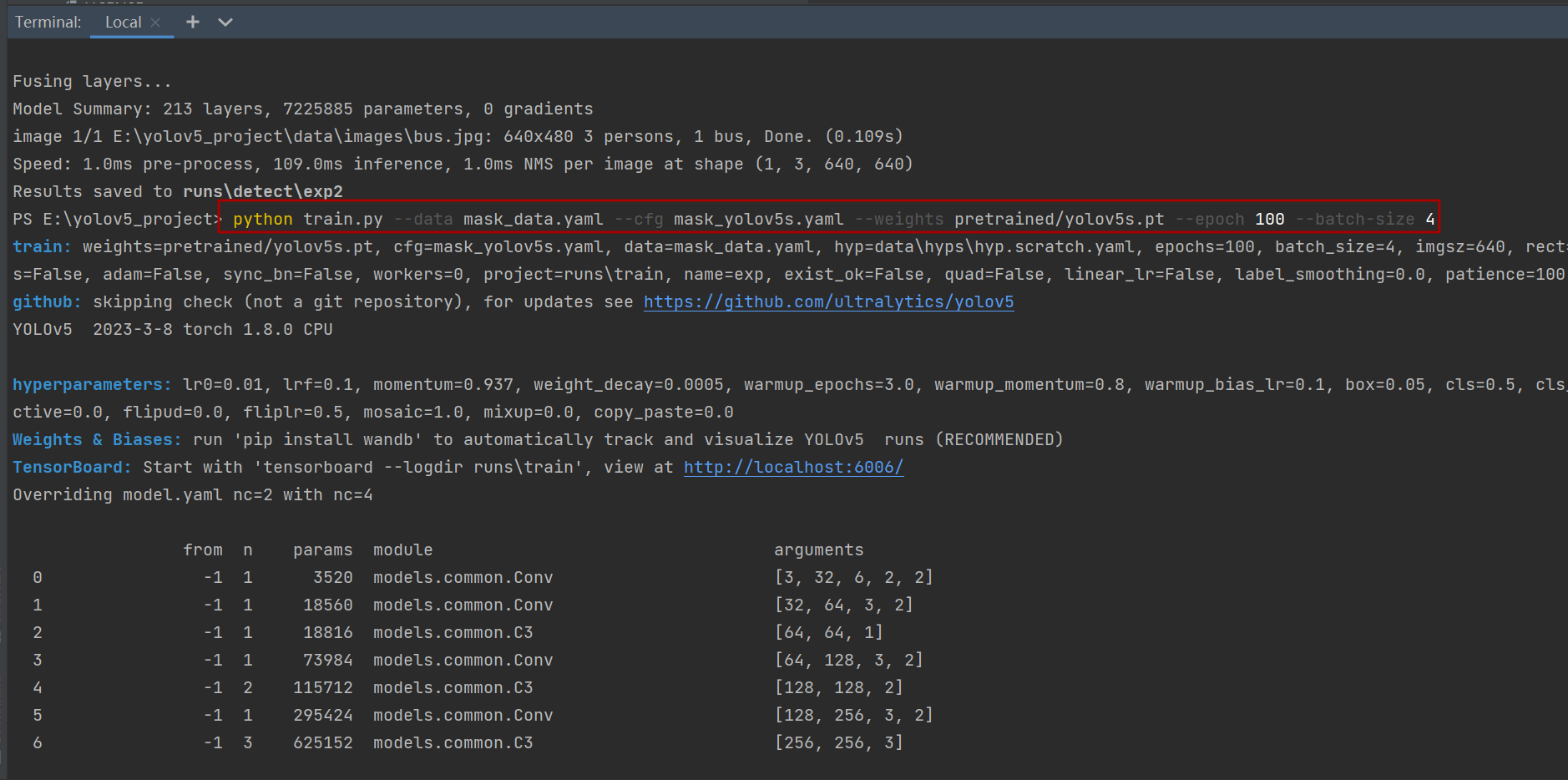
训练完成后模型评估结果:在模型训练完成后会在runs/train目录下生成一个exp文件里面包含了训练结果,以及一些评估指标。


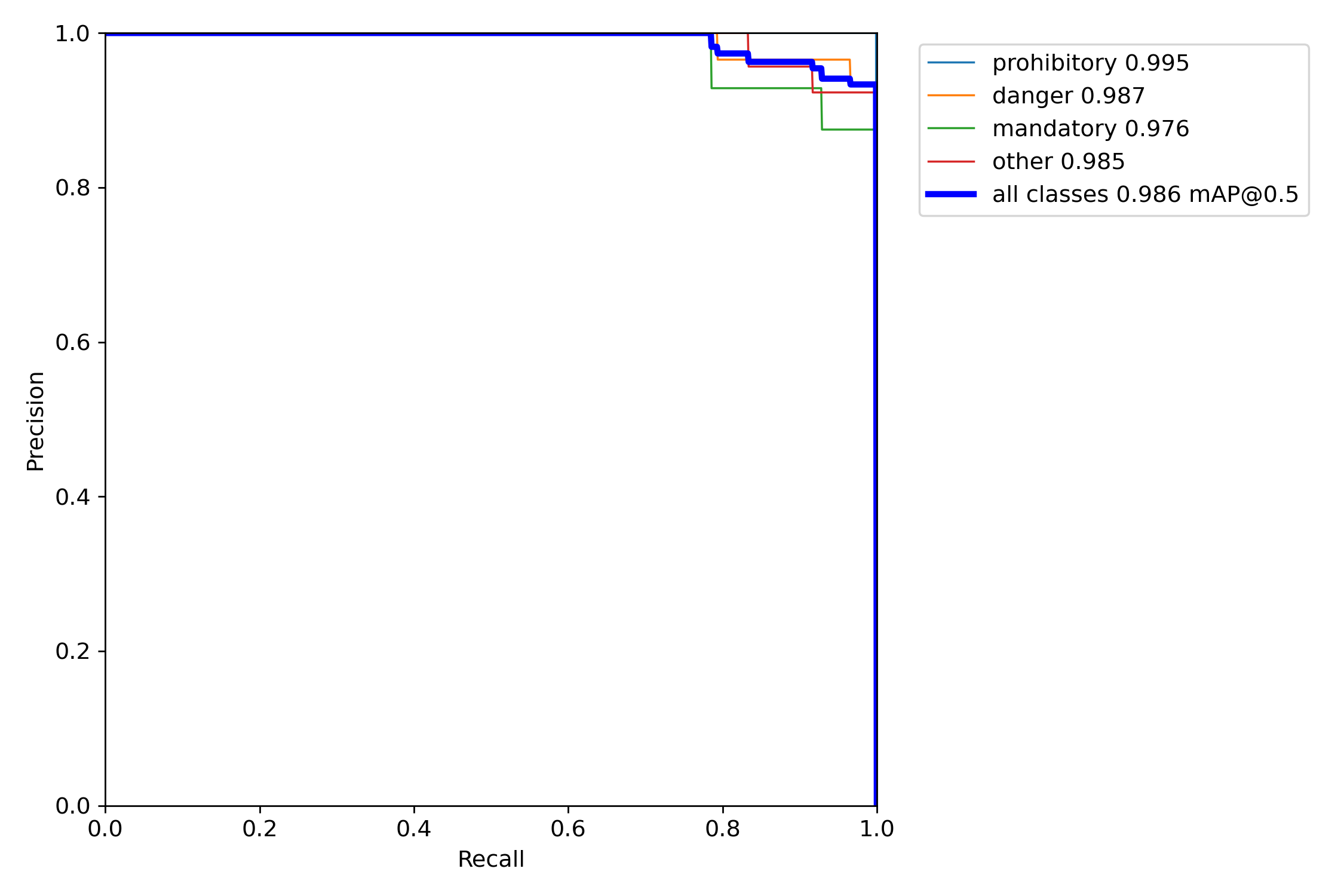
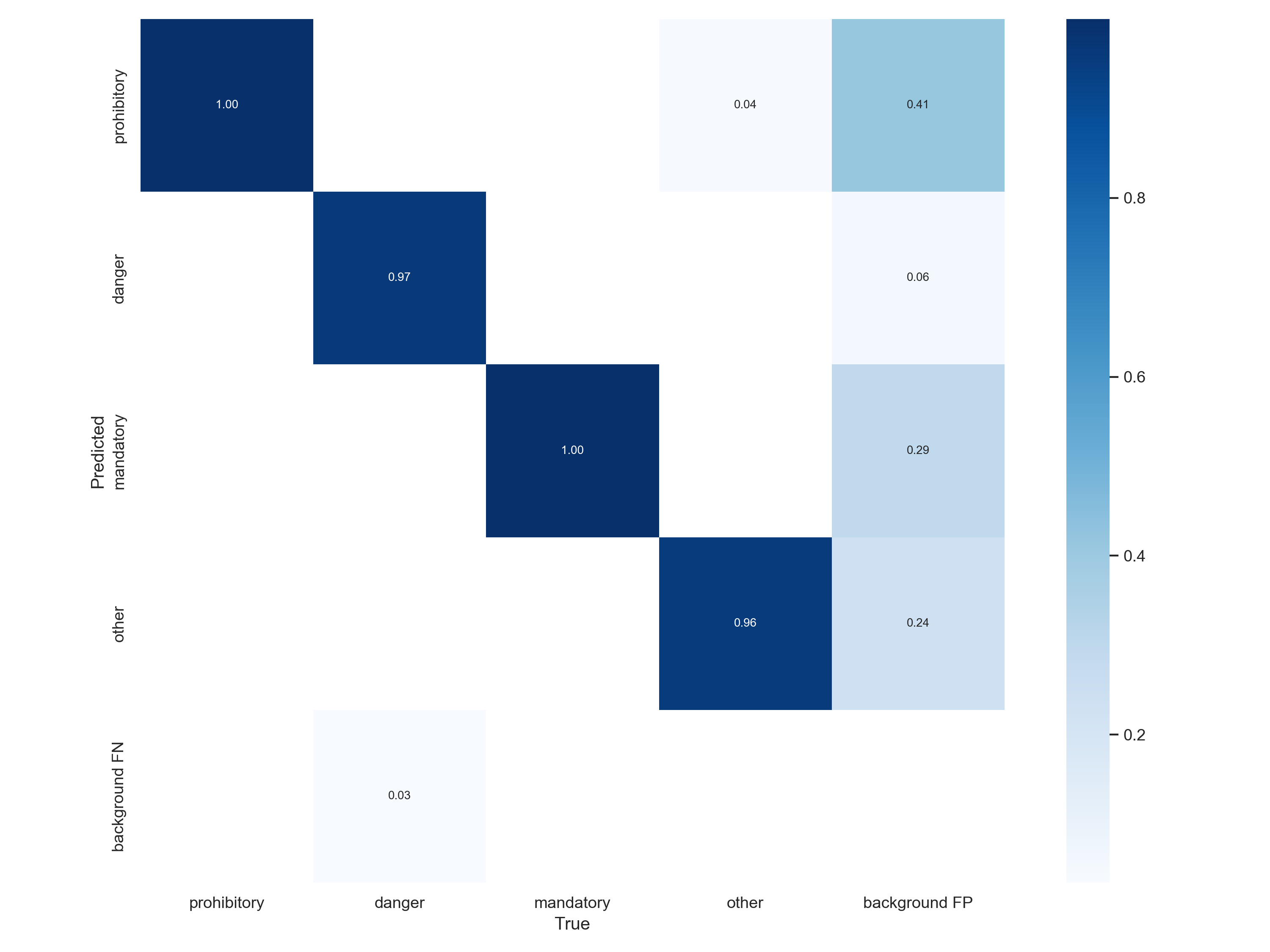
根据输出的识别结果可以知道,模型的准确率是非常的高!!!
运行GUI界面
在经过训练之后,打开"windows.py"这个代码,直接点击运行,结果如下所示: