MySQL性能调优

存储数据类型优化
- 尽量避免使用 NULL
- 尽量使用可以的最小数据类型。但也要确保没有低估需要存储的范围
- 整型比字符串操作代价更低
- 使用 MySQL 内建的数据类型(比如date、time、datetime),比用字符串更快
基本数据类型
-
数字
-
整数 - TINYINT (8) - SMALLINT (16) - MEDIUMINT (24) - INT (32) - BIGINT (64)
- 整数类型有可选的 unsigned 属性
- int(1)与int(11),对于存储和计算来说,这两者本质是没有区别的
-
实数(存储小数、存储比 BIGINT 更大的数)
-
float
-
double
float 和 double支持使用标准的浮点运算进行近似的计算。
-
decimal
decimal 类型用于存储精确的小数,支持精确的计算。
因为在进行精确计算时需要额外的空间和计算开销,所以尽量只对小数才使用decimal。比如,财务数据。另外如果数据量大的话,可以考虑使用bigint代替decimal,只需将存储的货币单位根据小数的位数乘以相应的倍数即可。
-
-
字符串
-
CHAR
1、char 类型是定长的;2、适合存储很短的字符串,例如:密码的 md5 值;3、适合存储经常进行变更的值。
-
VARCHAR
1、字符串列的长度比平均长度大很多;2、列的更新很少,所以碎片不是问题;3、使用了像 UTF-8 这样复杂的字符集,因为该字符集中每个字符可能使用不同的字节来进行存储;4、存储可变长的字符串。
-
-
BLOB 和 TEXT
两者都是为存储很大的数据而设计的字符串数据类型,不同的是两者分别采用二进制和字符方式存储。
MySQL 在处理两个类型的值时,处理基本相同,仅有的不同是 BLOB 类型是以二进制格式来存储的,所以没有排序规则和字符集,而 text 类型有排序规则和字符集。
-
枚举
枚举可以把一些不重复的字符串存储成一个预定义的集合。
MySQL 会在存储枚举类型时粉肠紧凑,会根据列的值的数量压缩到一个或者两个字节中。
MySQL 会在内部将每个值在列表中的位置保存成整数,而这些『数字–字符串』的对应关系,会保存在 .frm 文件中。
所以当该列需要新添加一个新的枚举值时,必须添加在之前枚举列表的最后面,否则就会出现数据错乱的问题。切记。 -
日期类型
-
DATETIME
该类型能保存大范围的值,从 1001 年到 9999 年,精度为秒。他会把时间封装到 YYYYMMDDHHIISS 的整数中,没有时区概念。使用 8 个字节的存储空间。
-
TIMESTAMP
该类型保存了从 1970-01-01 00:00:00(格林威治时间)以来的秒数。该类型使用 4 个字节的存储空间,所以只能表示 1970 到 2023 年,其值还具有时区的概念。
-
-
BIT
存储更紧凑。但所有这些位类型,不管底层存储格式和存储方式,从技术上来说都是字符串类型。虽然用它存储数据更紧凑,但是对于大部分应用来说,最好避免使用该类型。
-
SET
特殊类型的数据
某些数据的类型并不直接和内置的类型一致。所以需要一定的转换进行存储。
低于秒级的时间戳
低于秒级的时间需要在引用层做处理,一般可以通过存储两个或者多个列来存储(一个存储秒级的时间戳,另外的存储秒级以下的)
ipv4 地址
我们常见到有人会用 varchar (15) 来存错一个 IP 地址,IP 地址实际是一个 32 位的无符号整数,所以应该用无符号整数来存储 IP 地址。MySQL 提供了 INET_ATON () 和 INET_NTOA () 函数在这两表示方法之间转换。
IP地址存储
通过在应用程序中进行 字符型 到 无符号整型 的转换,而不是使用MySQL的 INET_ATON() 函数,插入整数IP时MySQL的负载可能会稍微降低。
https://bafford.com/2009/03/09/mysql-performance-benefits-of-storing-integer-ip-addresses/
三层架构说明
- 第一层,用于连接处理、授权认证、安全认证等等。大多数基于客户端 / 服务器端的工具或者服务器都有类似架构。
- 第二层,是 MySQL 架构的核心部分。MySQL 的大部分核心服务功能大都在这一层。包括查询解析、分析、优化、缓存以及所有的内置函数的实现,还有所有的跨存储引擎的功能都在这一层实现:存储过程、触发器、试图等。
- 第三层,存储引擎层。存储引擎负责 MySQL 中数据的存储和读取。每个存储引擎都有自己的优势和劣势。MySQL 服务器层通过 API 与存储引擎进行通信。存储引擎本身是不会解析 SQL,且不同的存储引擎之间也是不会相互通信。
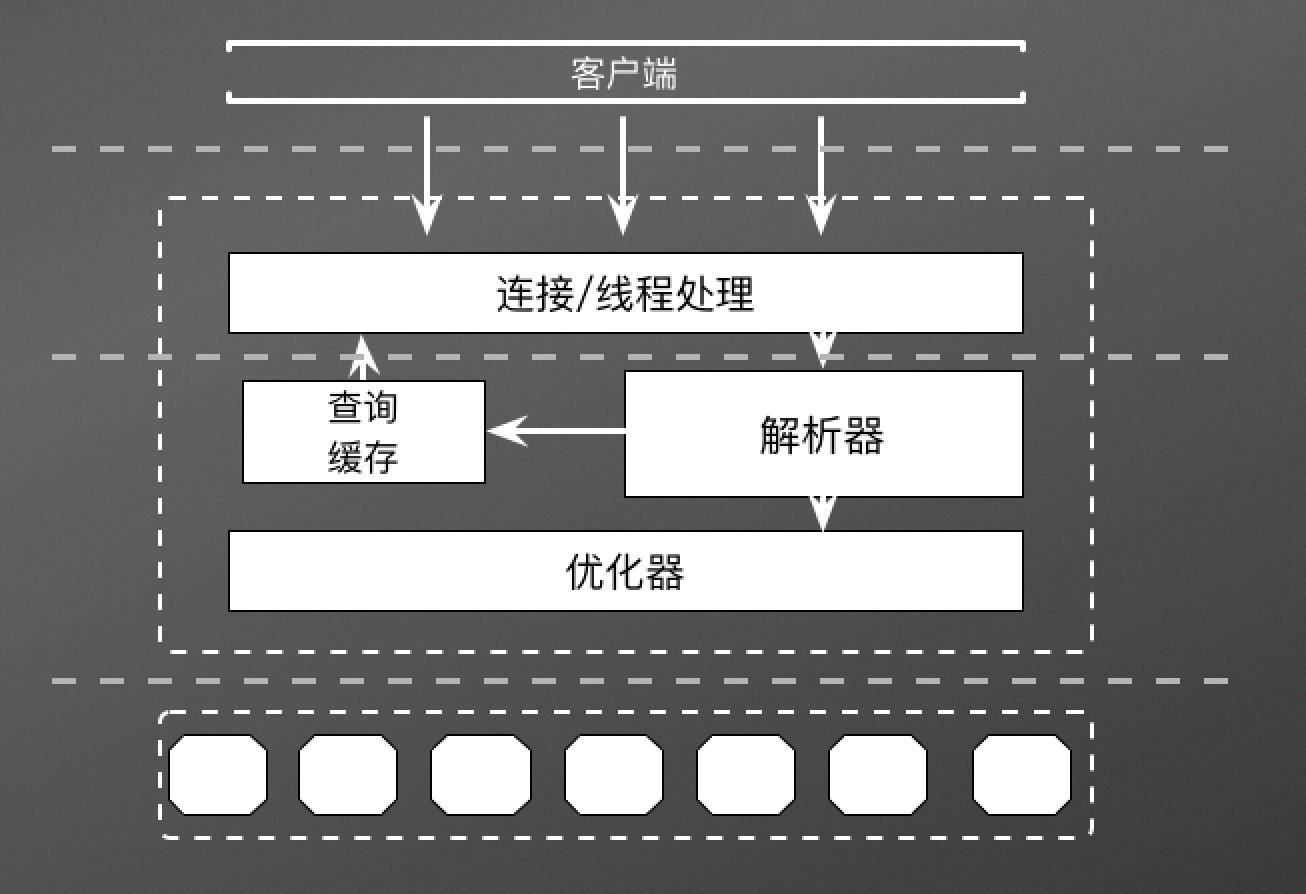
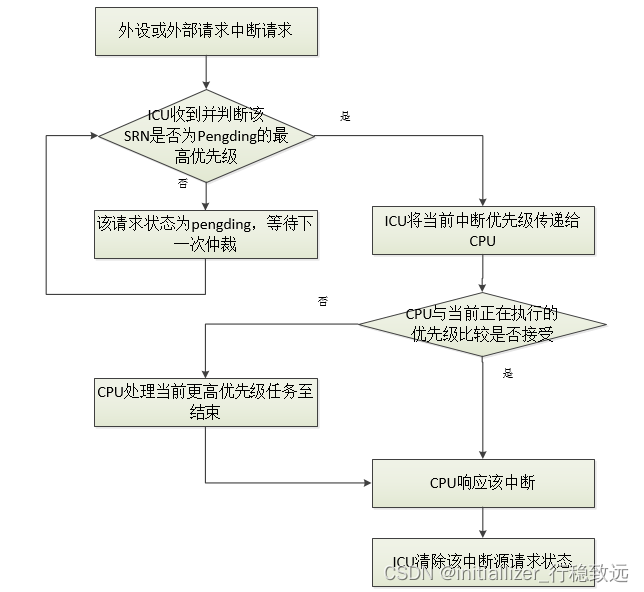
MySQL 服务器接收 / 处理一个查询请求的过程
- 当 MySQL 服务器接收到一个查询请求,首先会对当前的连接请求进行认证,认证其用户名和密码信息。
- 连接成功之后,会继续验证该连接是否具有执行某个特定查询的权限。
- 所有的验证都通过,如果是 select 操作,MySQL 会先检查查询缓存中是否存在该缓存,如果存在直接返回结果。不存在继续下一步。
- 解析查询,并创建内部数据结构(生成 解析树),然后对解析树进行各种优化(包括,重写查询,决定表的读取顺序、选择合适的索引等等)。
- 通过存储引擎存储或者提取结果。
- 如果是 select 操作,生成查询缓存。
- 返回结果。
根据控制的不同层次,MySQL 的并发控制可以分为:
- 服务器层
- 存储引擎层
实现并发控制的方法策略:锁机制
- 共享锁(shared lock)<======> 读锁(read lock)
- 排它锁(exclusive lock) <======> 写锁(write lock)
如何选择适合的锁?锁策略
-
锁的粒度越小,系统的并发性越高
-
所得操作越多,系统的开销越大
所以所谓的锁策略,就是在锁的开销和数据的安全性之间寻求平衡。
MySQL并发控制
MySQL 中锁策略类型
MySQL 不同的存储引擎中用到的锁策略基本有两种。一种是表级锁,另一种是行级锁。
-
表锁,一种开销最小的锁策略。
一个用户对表进行写操作时,需要先获得写锁,这是其他用户读该表进行的读写操作都会进行阻塞。只有当前写操作被释放之后,其他人才能活的读锁。当当前表有读锁时,其他人也可以继续获得读锁。读锁是共享性的不同的读锁之间是互相不阻塞的。
另外,写锁的优先级高于读锁。所以当有多个锁请求存在是,读锁的请求会被优先插入到锁队列的前边。 -
行锁,最大程度支持并发处理,同时也是锁开销最大的锁策略。
顾名思义,行级锁只在将要修改的记录行上进行锁操作,对其他的行的操作没有影响。
尽管我们一般提到的锁,都处于存储引擎这一层,但是 MySQL 本身在某些情况下,也会对锁策略进行控制。比如表的 alter table 操作,会对表本身使用表锁,而直接忽略存储引擎的锁机制。
MySQL 中死锁问题解决方法
死锁,即两个或者多个事务在同一资源上相互占用,并请求占用对方已经占用的资源的情况。
既然有锁存在,当然就会有死锁的情况发生。那么 MySQL 中是如何处理死锁问题的呢?
死锁的通常解决方案有两种,即:
- 死锁检测机制
- 超时机制
InnoDB 存储引擎在检测到有死锁发生的处理方法是,将当前持有最少的行级锁的事务进行回滚。待打破死锁后,重新执行因为死锁而回滚的事务。



![[数据结构]栈的深入学习-java实现](https://img-blog.csdnimg.cn/bec4322e33dd46e78ca00edfb2654de6.png)