主要目的 为 快速爬虫入门
参考:https://blog.csdn.net/c406495762/article/details/72597755
注意编写日期:2023-3-9
如果时间过久,则代码可能会失效,如果失效,可以根据下面的解析过程,手动更新代码。
页面解析
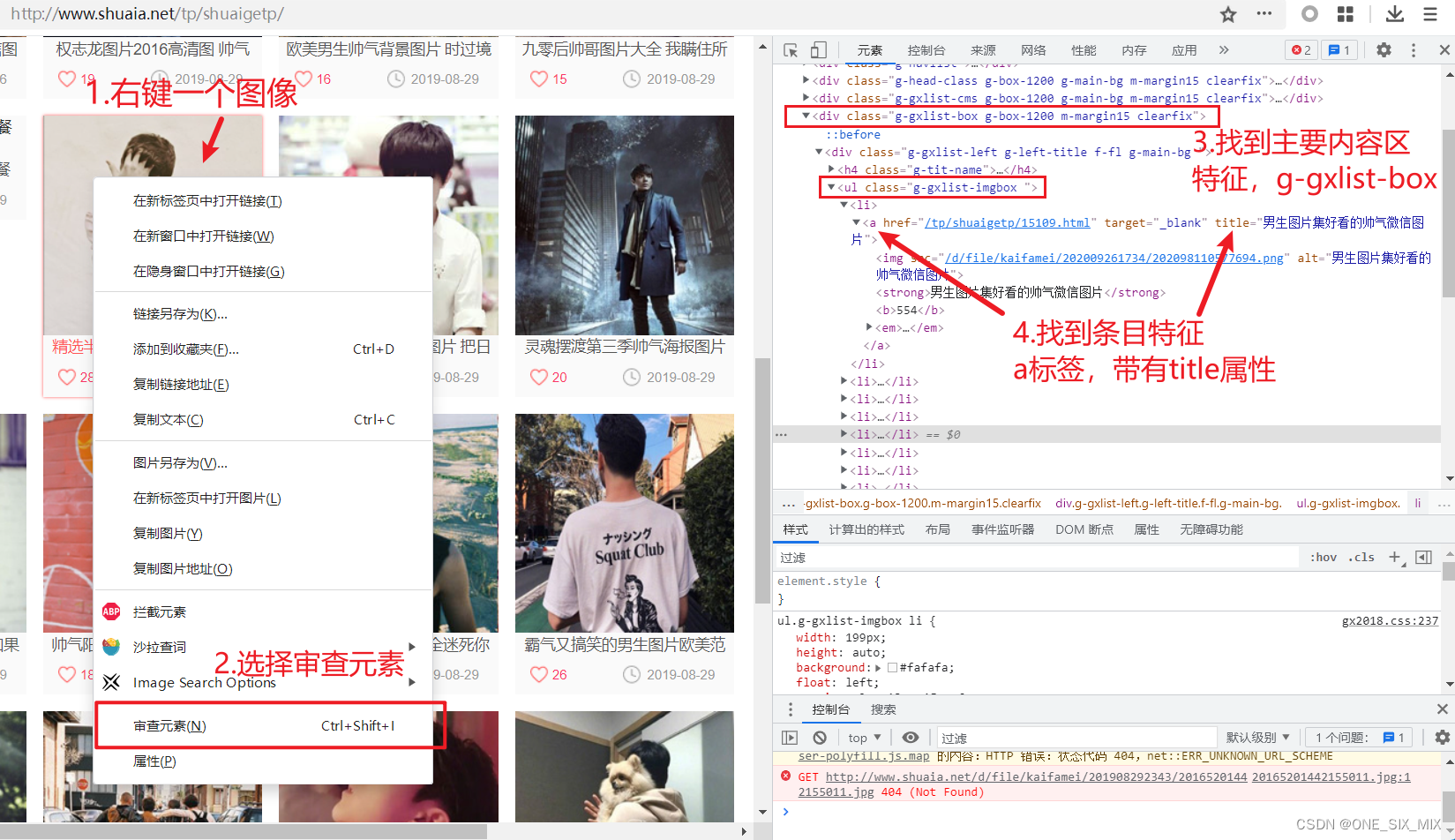
1.主页面解析,进入网站,往下滚动,找到有很多图像的区域,该区域为主要内容区;
2.任意右键一个主要图像打开菜单,选中审查元素,打开 DOM树分析器。
3.观察DOM树,找到需要的标签的位置,记下它的特征,如本文:ul 标签 和 属性class="g-gxlist-imgbox " 就是主要内容区的特征
4.继续右键其他主要图像,选中审查元素,观察规律,可知:a 标签,带有 title 属性的即为入口区的特征
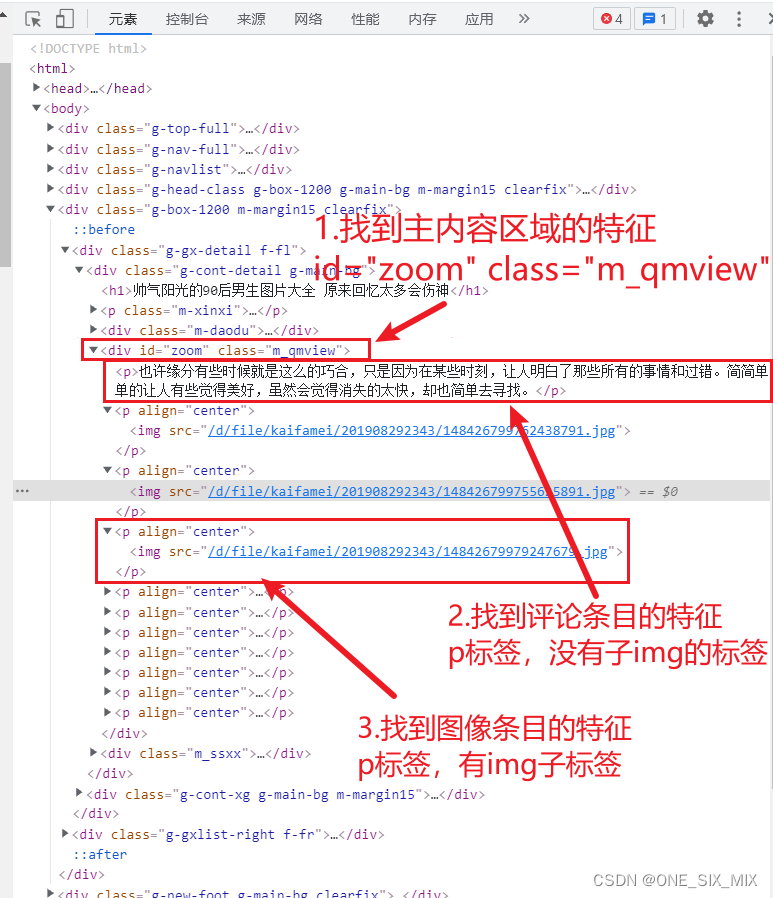
5.任意选一个图像进入子页面
6.往下滚动,随便右键一张大图,使用审查元素,打开DOM树解析器。
7.观察DOM树,找到主内容区域的特征:div 标签,包含属性 id=“zoom” class=“m_qmview”
8.往下看,找到评论标签的特征:p 标签,它的子标签不包含任何 img 标签
9.继续看,找到图像标签的特征:p 标签,子标签里面有一个 img 标签
10.根据以上特征,把链接提取出来,与站点链接拼接在一起,使用requests下载和保存/
完整代码和使用方法
首次安装python3后,使用请使用以下命令安装依赖库
pip install -U beautifulsoup4 requests
以下为完整代码,保存以下代码 到一个记事本文件中。
例如保存到 get.txt 里面
然后改名 get.txt 到 get.py
然后执行 python get.py 即可启动程序
#导入需要的库
import os
import time
import requests
from bs4 import BeautifulSoup
import urllib.parse
# 切换到当前文件夹
os.chdir(os.path.dirname(__file__))
# 要爬取的页面
url = 'http://www.shuaia.net/tp/shuaigetp/'
print('要爬取的链接:' + url)
# 获得页面的主站链接
url_parse = urllib.parse.urlparse(url)
base_url = url_parse.scheme + '://' + url_parse.netloc
print('主站链接:' + base_url)
# 设定请求头
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36"
}
# 下载主页面
req = requests.get(url=url, headers=headers)
req.encoding = 'utf8'
# 解析主页面
soup = BeautifulSoup(req.text, 'lxml')
# 通过 class 属性获得主要内容区域
main_page = soup.find_all(class_='g-gxlist-imgbox')[0]
# 获得每一个子页面入口的url
sub_pages = []
# 通过 a 标签搜索入口标签
for sub_page_entry in main_page.find_all('a'):
# 如果入口标签有 title 属性,则认为是有效入口点
if 'title' in sub_page_entry.attrs:
# 获得子页面的标题
new_title = sub_page_entry['title']
# 获得子页面的url,并组装起来
new_url = base_url + sub_page_entry['href']
# 保存子页面的标题和链接到 sub_pages 列表中
sub_pages.append([new_title, new_url])
# 循环下载解析每一个子页面,同时下载图像
for sub_title, sub_url in sub_pages:
print('正在扫描子页面', sub_title, sub_url)
print('子页面标题:'+sub_title)
print('子页面链接:'+sub_url)
# 生成一个文件夹
os.makedirs(sub_title, exist_ok=True)
# 打开一个文本文件,用来记录评论
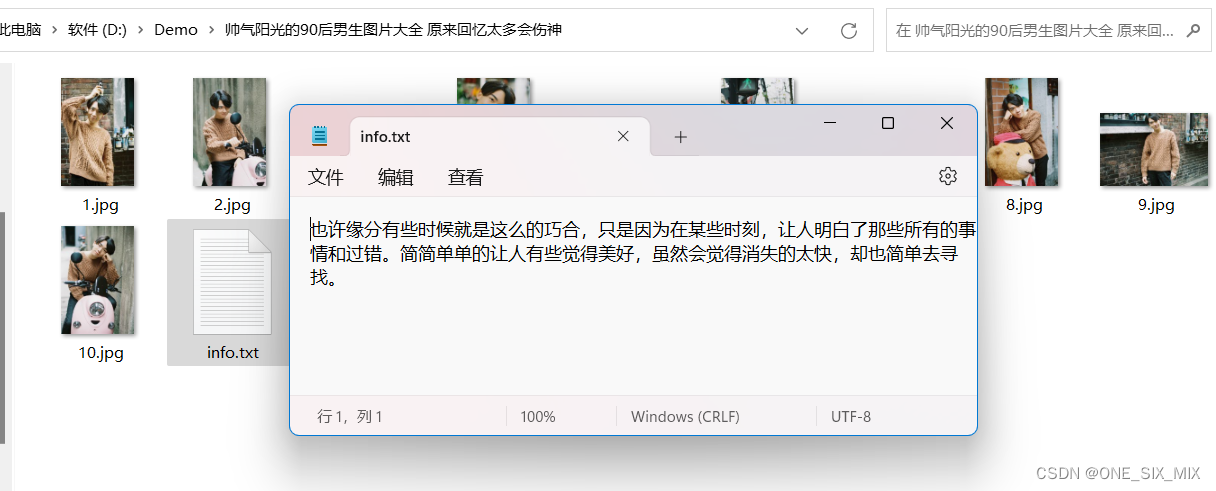
info_file = open(sub_title+'/info.txt', 'w', encoding='utf8')
# 下载子页面
sub_req = requests.get(url=sub_url, headers=headers)
sub_req.encoding = 'utf8'
# 解析子页面
sub_soup = BeautifulSoup(sub_req.text, 'lxml')
# 获得子页面主要内容区域
sub_img_list = sub_soup.find_all('div', id='zoom', class_="m_qmview")[0]
# 使用 p 标签搜索主要内容区域的图像
for each_idx, each_img in enumerate(sub_img_list.find_all('p')):
img_contents = each_img.find_all('img')
# 如果该标签没有图像,那么该标签是一个评论标签
if len(img_contents) == 0:
info_file.write(each_img.text)
else:
# 获得子图像部分链接
image_url = img_contents[0]['src']
# 拼接为完整的子图像链接
image_url = base_url + image_url
# 拼接输出图像的路径
out_image_path = f'{sub_title}/{each_idx}.jpg'
if os.path.isfile(out_image_path):
print('目标图像已下载,跳过')
continue
# 下载目标图像
im_req = requests.get(url=image_url, headers=headers)
if im_req.status_code != 200:
print('下载失败,跳过')
continue
else:
print('下载成功')
open(out_image_path, 'wb').write(im_req.content)
# 避免服务器过载
time.sleep(2)
# 关闭评论文件
info_file.close()
效果演示
终端输出

文件夹视图
内容+评论