作者介绍: 马成,慧策 JAVA高级研发工程师
慧策(原旺店通)是一家技术驱动型智能零售服务商,基于云计算 PaaS、SaaS 模式,以一体化智能零售解决方案,帮助零售企业数字化智能化升级,实现企业规模化发展。凭借技术、产品、服务优势,慧策现已成为行业影响力品牌并被零售企业广泛认可。2021年7月,慧策完成最新一轮 D 轮 3.12 亿美元的融资,累计完成四轮逾 4.52 亿美元的融资,与诸多国际一流企业、行业头部企业并列而行,被全球顶尖投资公司看好。
业务需求
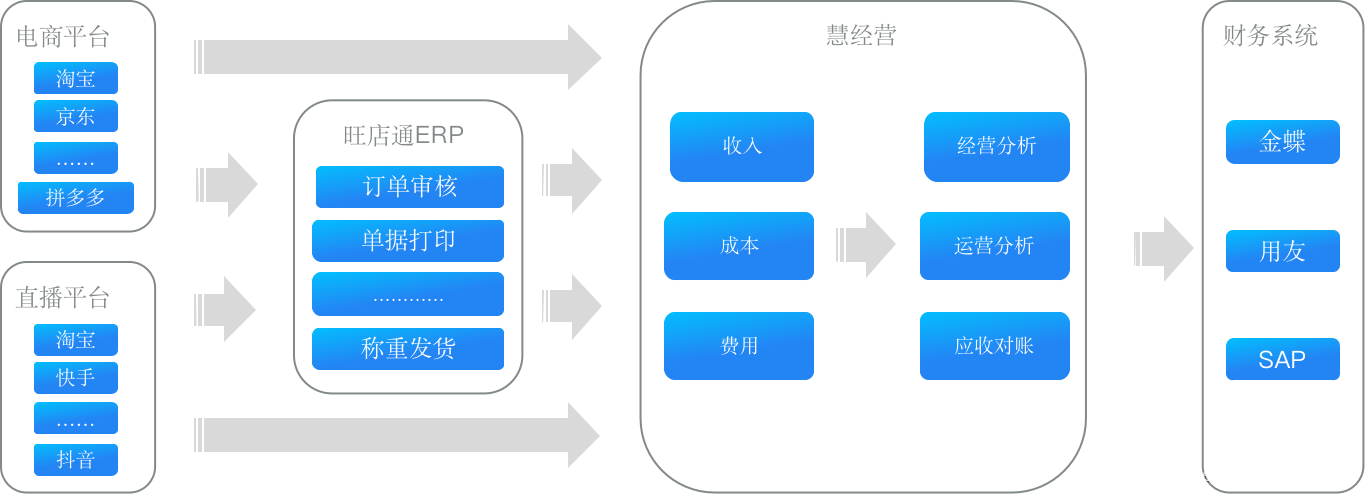
慧经营是一款数据分析产品,主要提供经营分析、运营分析、应收对账三大功能,面向企业的经营、运营、财务三个角色。如图所示,慧经营上游为常见的电商平台、直播平台以及慧策主要的产品旺店通,这些平台在交易过程中会产生大量的数据,包括收入、成本以及多种费用相关的数据。这些数据都比较分散,如果客户手动进行数据汇总和分析,过程繁琐、难度较高且展示不够直观。而慧经营可以在客户授权下获取、汇总这些数据,根据客户需求提供经营分析、报表生成、账单汇总等多项数据分析服务,以帮助客户更好地经营店铺。
为了能承载上述数据相关的服务,我们在系统架构设计之初需要考虑以下几点:
低成本:慧经营的付费模式为按需付费,这要求架构必须具有轻量化、易维护的特性。基于这点考虑,首先排除基于 Hadoop 的生态架构,虽然 Hadoop 足够成熟,但是组件依赖度较高、繁琐复杂,无论是运维成本还是使用成本都非常高。
高性能:电商数据为慧经营的主要数据来源,数据维度丰富, ETL 复杂度高;另外,在很多使用场景中明细查询与聚合查询是并存的,既需要够快速定位数据范围,又需要高效的计算能力,因此需要一个强大的 OLAP 引擎来支撑。
合理资源分配:客户规模差异较大,有月单量只有 1 万的小客户,也有月单量高达千万级别的大客户,资源合理分配在这样的场景下异常重要,因此要求 OLAP 引擎可以在不影响用户体验的前提下,可以根据客户的需求进行资源分配,避免大小查询资源抢占带来的性能问题。
高并发:能够承受上游平台多来源、高并发的大量数据的复杂 ETL,尤其在 618、双 11 这样的业务高峰期,需要具备高效查询能力的同时,能够承担大量的写入负载。
架构演进
架构 1.0

基于以上考虑,我们在架构 1.0 中引入 Clickhouse 作为 OLAP 引擎。从上图可看出该架构是一个完全基于后端 Java 以及 Spring 的技术架构,通过 Binlog 同步的方式通过 Canal 和 Kafka 将数据从 MySQL 同步至Clickhouse,来承接前端的各种经营分析报表服务。
架构 1.0 在上线不久后就遭遇了慢查询问题。在早期客户和数据量较少时,查询性能尚可满足客户需求,但是随着数据量的不断增大,受限于 MySQL 本身的特性, ETL 效率逐渐低到无法令人接受,尤其在面对大客户场景时,即使命中索引、扫描数据范围仅在百万级别,MySQL 应对该场景也已十分吃力。其次,面对激增的数据,ClikHouse 的多表 Join 也遭遇性能问题,由于其几乎不支持分布式 Join,尽管提供了 Join 语义、但在使用上对多表 Join 的支撑较弱、复杂的关联查询常常会引起 OOM。
在 ClickHouse 单机性能不能支撑业务时,我们考虑扩展搭建集群以提高性能,而 ClickHouse 分布式场景需要依赖 Zookeeper,同时需要单独维护一套分布式表,这将使运维管理的难度和成本不断升高。
除此之外,ClickHouse 还有几个较大的问题,背离了我们最初对架构的选型要求:
不支持高并发,即使一个查询也会用服务器一半的 CPU。对于三副本的集群,通常会将 QPS 控制在 100 以下。
ClickHouse 的扩容缩容复杂且繁琐,目前做不到自动在线操作,需要自研工具支持。
ClickHouse 的 ReplacingMergeTree 模型必须添加final 关键字才能保证严格的唯一性,而设置为final后性能会急剧下降。
架构 2.0
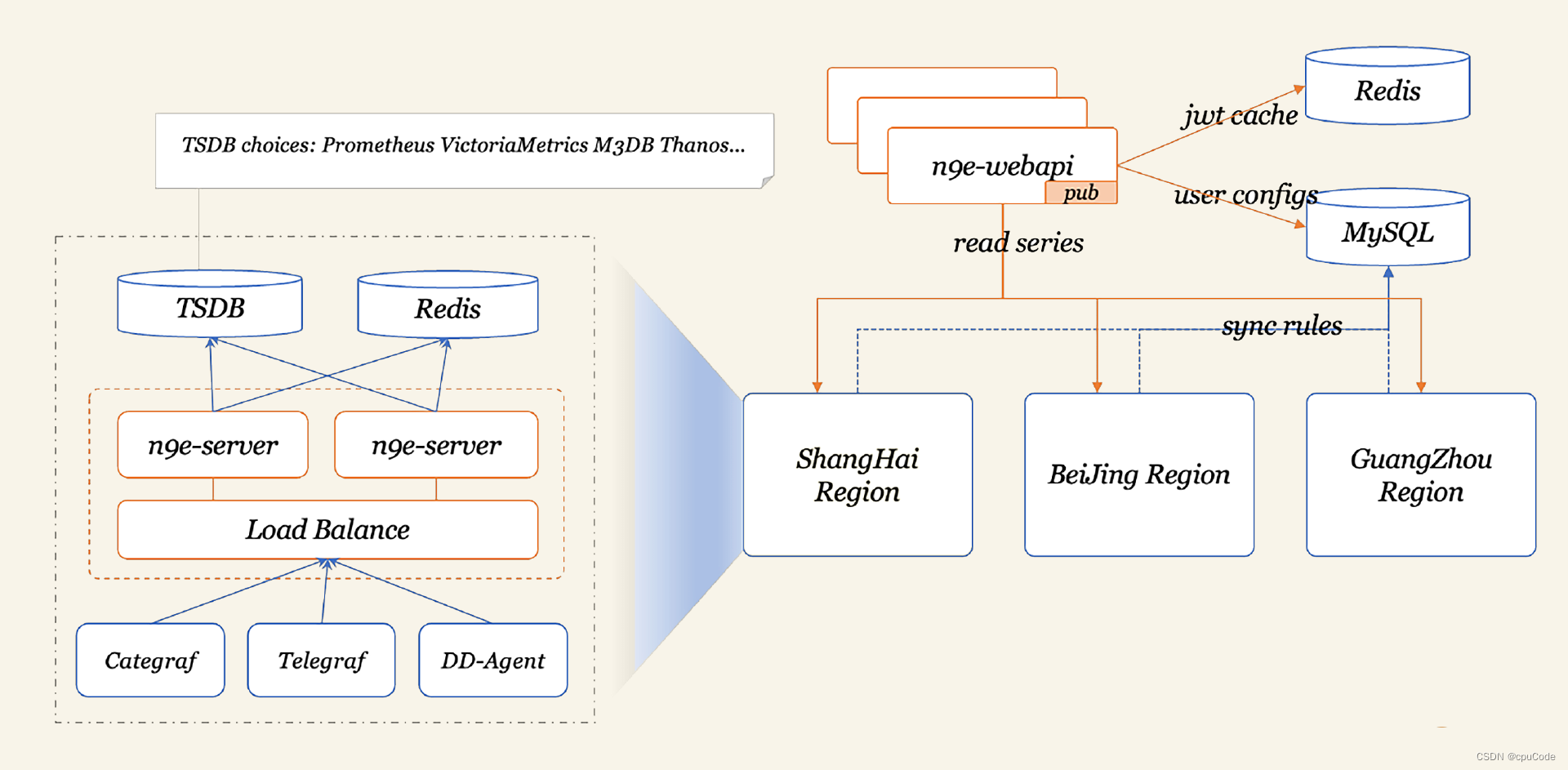
我们在架构 2.0 中引入 Apache Doris 作为 OLAP 引擎,并进行了一次整体的架构升级。选择 Apache Doris 的主要原因有如下几条:
使用成本低: 只有 FE 和 BE 两类进程,部署简单,支持弹性扩缩容,不依赖其他组件,运维成本非常低;同时兼容 MySQL协议 和标准 SQL,开发人员学习难度小,项目整体迁移使用成本也比较低。
Join 性能优异: 项目存在很多历史慢 SQL ,均为多张大表 Join,Apache Doris 良好的 Join 性能给我们提供了一段优化改造的缓冲期。
社区活跃度高: 社区技术氛围浓厚,且 SelectDB 针对社区有专职的技术支持团队,在使用过程中遇到问题均能快速得到响应解决。
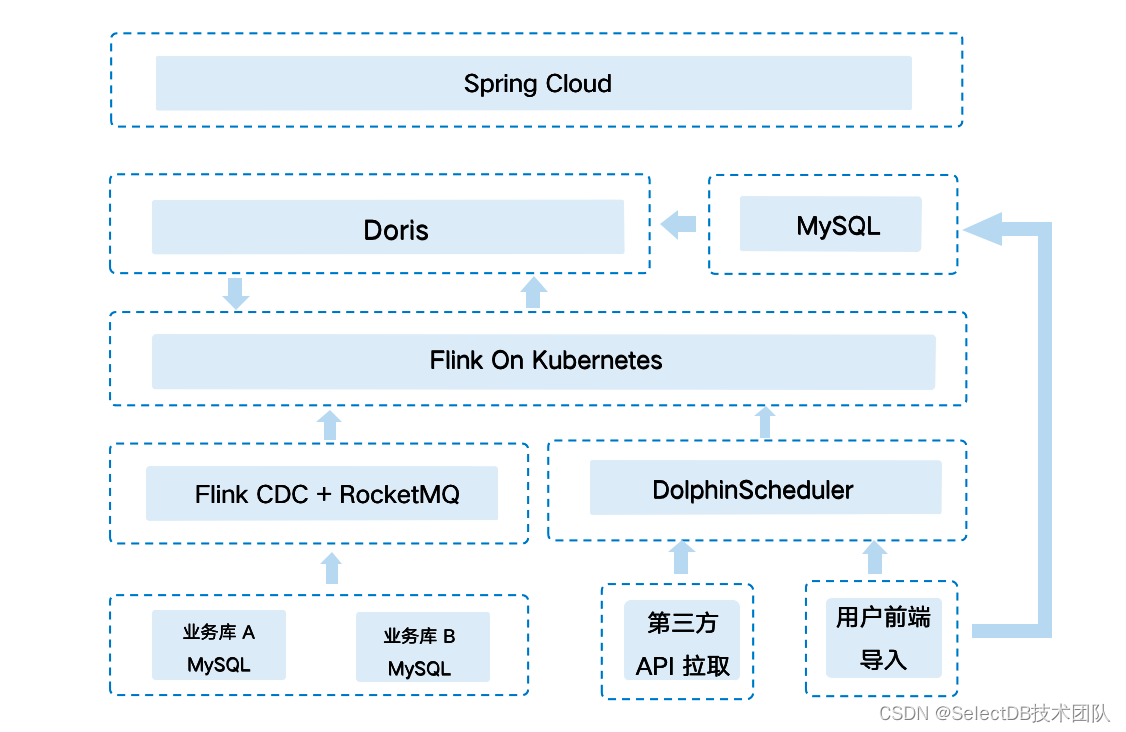
如上图所示,我们将原本基于 MySQL 的基础数据存储迁移到 Doris 中,同时将大部分的 ETL 迁移至在 Doris 内部进行,MySQL 只用于存储配置信息。同时引入了 Flink,DolphinScheduler 等组件,成功构建了一套以 Doris 为核心、架构简洁、运维简单的数据生产体系。
全新的架构也给我们带来的显著的收益:
ETL 效率极大提升:慧经营的数据维度丰富、 ETL 复杂度高,得益于 Apache Doris 强大的运算能力及丰富的数据模型,将 ETL 过程放在 Doris 内部进行后效率得到显著提升;
Join 耗时大幅降低:查询性能同样得到极大提升,在 SQL 未经过改造的情况下,多表 Join 查询耗时相较于过去有了大幅降低。
并发表现出色:在业务查询高峰期可达数千 QPS,而 Apache Doris 面对高并发查询时始终表现平稳;
存储空间节省:Apache Doris 的列式存储引擎实现了最高 1:10 的数据压缩率,使得存储成本得到有效降低。
运维便捷:Apache Doris 架构简单、运维成本低,扩容升级也非常方便,我们前后对 Doris 进行了 3 次升级扩容,基本都在很短的时间内完成。
在使用 Apache Doris 的过程中,我们对 Doris 如何更好地应用也进行了探索,在此期间总结出许多实践经验,通过本文分享给大家。
实践应用
分区分桶优化
在执行 SQL 时,SQL 的资源占用和分区分桶的大小有着密切的关系,合理的分区分桶将有效提升资源的利用率,同时避免因资源抢占带来的性能下降。
因此我们在建立事实表分区时,会根据客户的数据规模提供相匹配的分区方案,比如数据规模较小按年分区、规模大按月分区。在这种分区方式下,可以有效避免小查询占用过多资源问题,而大客户的使用体验也由于细粒度的分区方式得到了提升。
CREATE TABLE DWD_ORDER_... (
...)
...
PARTITION BY RANGE(tenant,business_date)
(
PARTITION p1_2022_01_01 VALUES [("1", '2022- 01- 01'), ("1", '2023- 01- 01')),
PARTITION p2_2022_01_01 VALUES [("2", '2022- 01- 01'), ("2", '2022- 07- 01')),
PARTITION p3_2022_01_01 VALUES [("3", '2022- 01- 01'), ("3", '2022- 04- 01')),
PARTITION p4_2022_01_01 VALUES [("4", '2022- 01- 01'), ("4", '2022- 02- 01')),
...
)而分桶的设置上我们采用了最新版本中增加的自动分桶推算功能,使用方式非常便捷,不用再去测算和预估每张表的数据量以及对应 Tablet 的增长关系,系统自动帮助我们推算出合理分桶数,提升性能的同时也使得系统资源得到更好利用。
参考文章:一文教你玩转 Apache Doris 分区分桶新功能|新版本揭秘
多租户和资源隔离方案
在 SaaS 业务场景中,多租户和资源划分是架构设计过程中必不可少的部分。多租户(Multi-Tenancy )指的是单个集群可以为多个不同租户提供服务,并且仍可确保各租户间数据隔离性。通过多租户可以保证系统共性的部分被共享,个性的部分被单独隔离。
对于我们来说,客户规模差异较大,有月单量只有 1 万的小客户,也有月单量高达千万级别的大客户,资源的合理分配与隔离在这样的场景下异常重要。如果为每个租户创建一个数据库集群,则集群规模不可控且造成资源浪费。如果多个租户共享一套数据库集群,用户的需求可以相互补偿,总体来时可以有很大的资源节约,并且计算规模越大成本越低,而在应对客户查询时,可以根据客户的数据规模和查询需求将资源池划分给各客户。
这里我们采用了 Apache Doris 的节点资源组来区分大小客户,避免了不同租户以及查询间的资源抢占问题。
节点资源组划分
节点资源划分指将一个 Doris 集群内的 BE 节点设置标签(Tag),标签相同的 BE 节点组成一个资源组(Resource Group),资源组可以看作是数据存储和计算的一个管理单元。数据入库的时候按照资源组配置将数据的副本写入到不同的资源组中,查询的时候按照资源组的划分使用对应资源组上的计算资源对数据进行计算。
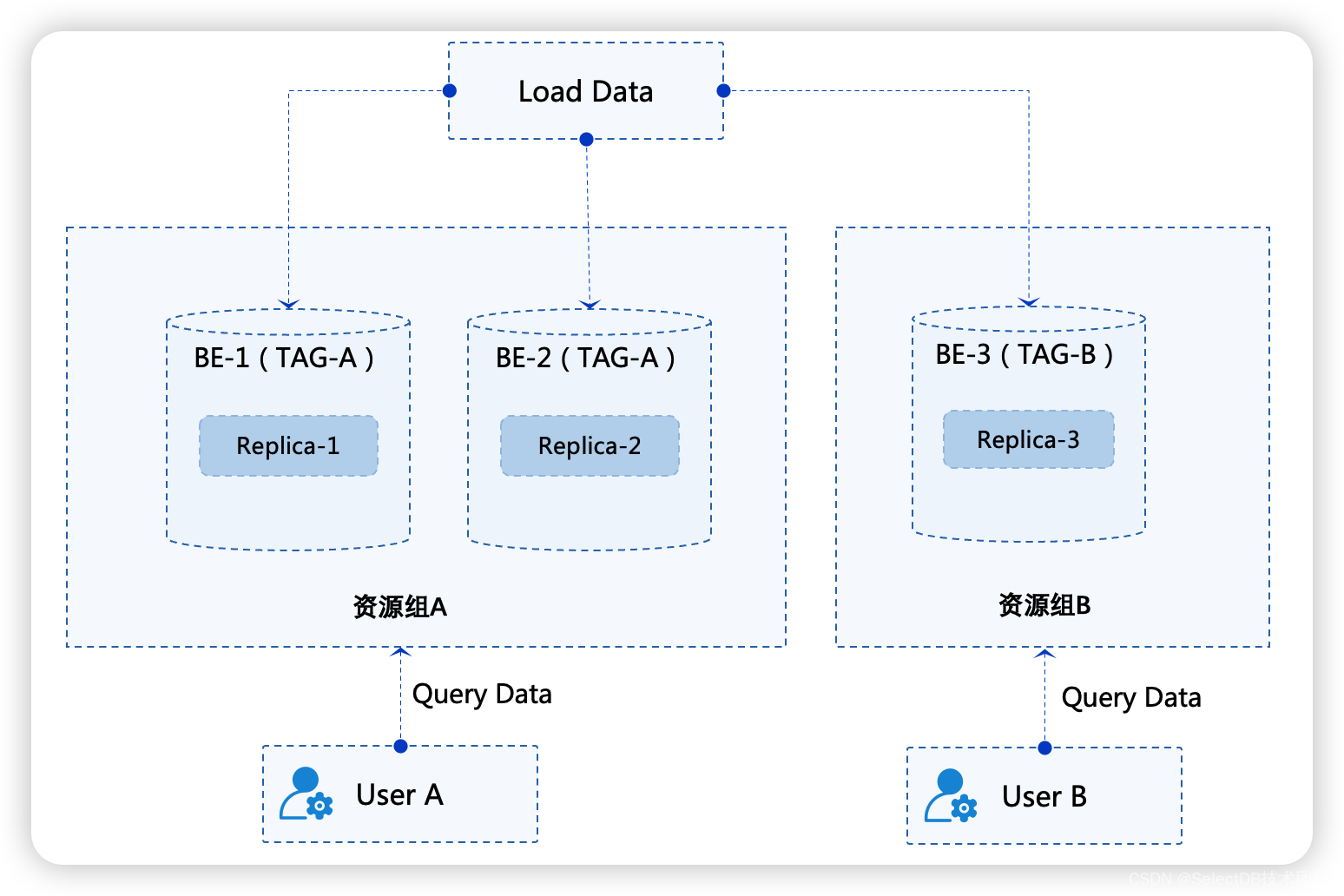
例如我们将一个集群中的 3 个 BE 节点划分为 2 个资源组,分别为资源组 A 和资源组 B,BE-1 和 BE-2 属于资源组A,BE-3 属于资源组B。资源组 A 有 2 副本的数据,资源组 B 有一个副本的数据。那么当客户 A 在写入数据和查询数据的时候会按照资源组配置使用资源组 A 上的存储和计算资源,当客户 B 写入数据和查询数据的时候会按照资源组配置使用资源组 B上 的存储和计算资源。这样便能能很好的实现同一个集群,为不同租户提供不同的负载能力。
具体操作如下:
设置标签:
为 BE 节点设置标签。假设当前 Doris 集群有 3 个 BE 节点。分别为 host[1-3]。在初始情况下,所有节点都属于一个默认资源组(Default)。
我们可以使用以下命令将这6个节点划分成3个资源组:group_a、group_b:
alter system modify backend "host1:9050" set ("tag.location" = "group_a");
alter system modify backend "host2:9050" set ("tag.location" = "group_a");
alter system modify backend "host3:9050" set ("tag.location" = "group_b");这里我们将 host[1-2] 组成资源组 group_a,host[3] 组成资源组 group_b。
设置资源组数据分配策略
副本分布策略定义:资源组划分好后,我们可以将客户数据的不同副本分布在不同资源组内。假设一张用户表 UserTable。我们希望资源组 A 内存放 2 个副本,资源组 B 存放 1 分副本
create table UserTable (k1 int, k2 int)
distributed by hash(k1) buckets 1
properties(
"replication_allocation"="tag.location.group_a:2, tag.location.group_b:1"
)资源组绑定:通过设置客户的资源组使用权限,来限制某一客户的数据导入和查询只能使用指定资源组中的节点来执行。
set property for 'user_a' 'resource_tags.location' = 'group_a';
set property for 'user_b' 'resource_tags.location' = 'group_b';这里将 user_a 和 group_a 资源绑定,user_b 和 group_b 资源绑定。绑定完成后,user_a 在发起对 UserTable 表的查询时,只会访问 group_a 资源组内节点上的数据副本,并且查询仅会使用 group_a 资源组内的节点计算资源。
通过 Apache Doris 提供多租户和资源隔离方案,能够将集群资源更合理的分配给各 客户 ,可以让多租户在同一 Doris 集群内进行数据操作时,减少相互之间的干扰,同时达到资源成本的有效降低。
高并发场景的支持
高并发也通常是 SaaS 服务场景面临的挑战,一方面是慧经营已经为众多客户提供了分析服务,需要去同时承载大规模客户的并发查询和访问,另一方面,在每日早晚业务高峰期也会面临更多客户的同时在线,通常 QPS 最高可达数千,而这也是 Apache Doris 表现得非常出色的地方。在上游 Flink 高频写入的同时,Apache Doris 表现极为平稳,随着查询并发的提升,查询耗时相较于平时几乎没有太大的波动。
应对高并发场景的关键在于利用好分区分桶裁剪、索引、缓存等系统机制来减少底层数据扫描。在 Doris 中会将数据表的前几列作为排序键来构建前缀索引,同时还有 ZoneMap 以及 Bloom Filter 等索引。在执行查询时,通过分区分桶裁剪以及索引可以快速过滤到不在查询范围内的数据,减少 CPU 和 IO 的压力。
在与社区的沟通中还了解到,即将发布的新版本还将进一步提升并发支持,引入行存储格式、短路径优化以及预处理语句等来实现上万 QPS 的超高并发,可以满足更高并发要求的 Data Serving 场景,这也是我们十分期待的功能。
数据生命周期管理
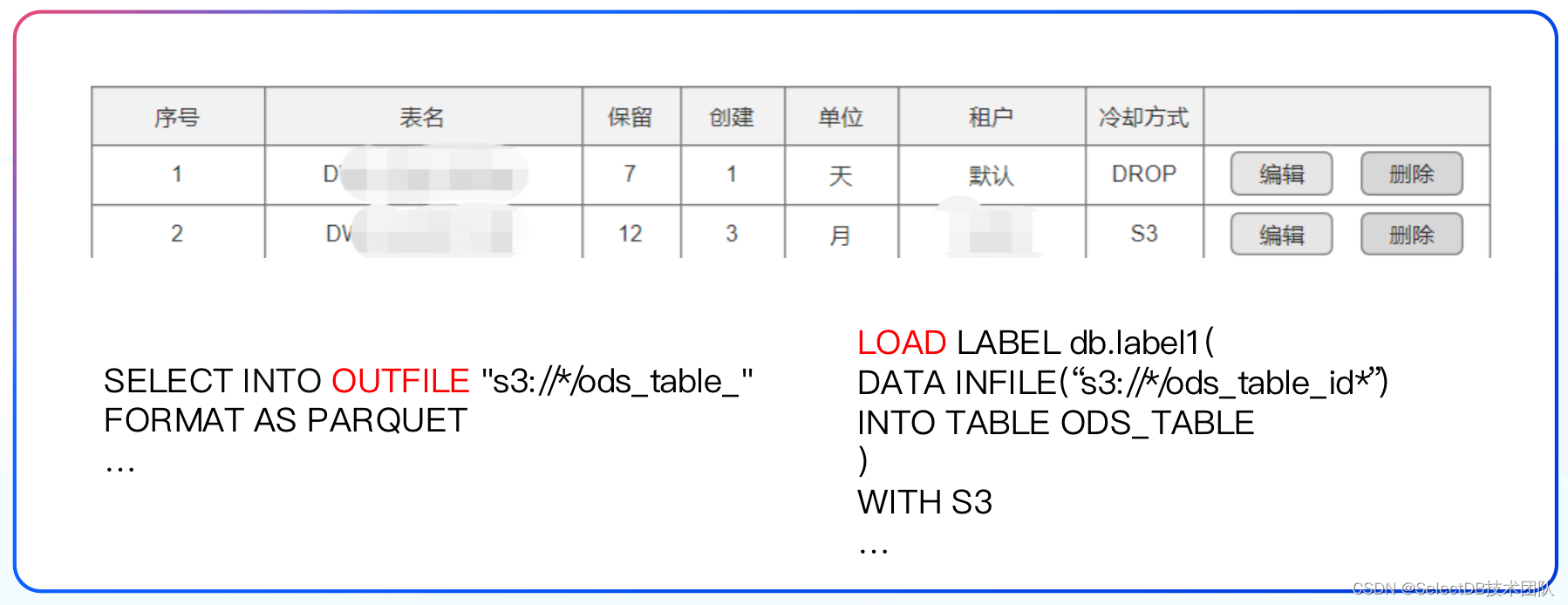
我们自研了一套生命周期管理工具,基于资源的分配,可以提供客户级定制化冷却策略。根据各个业务场景的客户需求及付费情况,提供不同长度的数据保留策略,同时得益于 Apache Doris 提供的 OutFile 功能,实现删除或者导出 S3 两种冷却方式,当我们再次需要这些数据时,可通过 Load 的方式从 S3 导回数据。
除了通过 OutFile 将数据文件导出至 S3 以外,社区在后续版本中还将提供分区级别的冷热数据分离策略。当前我们数据分区都是基于日期范围来设置,因此可以利用时间分区进行冷热数据的划分。通过配置分区级别的 Freeze Time,转冷后的历史数据可以自动下沉至成本更低的对象存储上。在面对历史冷数据的查询时,Doris 会自动拉取对象存储上的数据并在本地 Cache 以加速查询,而无需执行导入操作。通过冷热数据分离以及冷数据 Cache,既能保证最大程度的资源节省,也能保证冷数据的查询性能不受影响。
总结规划
收益
引入 Apache Doris 之后,新架构的整体查询响应速度都有了较大的提升, 存储成本显著降低,后续我们将继续探索 Doris 新特性,进一步实现降本增效。
规划
目前正在强化 Apache Doris 的元数据管理建设,我们希望通过该服务能更好的协助开发人员使用 Doris,包括数据血缘追踪等;
尝试使用更多 Apache Doris 的新功能,在 1.2.0 版本中新增的 Java UDF 功能可以极大降低数据出入库的频率,更便捷地在 Doris 内部进行数据 ETL,这一功能我们正在尝试使用中;
探索更好的资源分配方案,包括 SQL 代理以及尝试 Doris 后续提供的 Spill 功能,以更好进行资源分配应用。
最后,再次感谢 Apache Doris 社区和 SelectDB 技术团队在我们使用过程中提供的许多指导和帮助,提出问题都会及时的响应并尽快协助解决,未来我们也希望深度参与到社区建设中,为社区的发展出一份力。