目录
历史服务器的配置:
添加配置:
分发集群:
日志聚集功能的配置:
添加配置:
分发配置给集群其他服务器:
集群的启动与停止:
整体启动和停止hdfs:
整体启动/停止YARN
启动与停止某个服务组件:
常用脚本:
脚本1-实现集群的启动和停止:
脚本2-实现查看集群上所有服务器java进程脚本:
历史服务器的配置:
为了查看程序的历史运行情况,需要配置一下历史服务器
添加配置:
在mapred-site.xml问就按下添加配置
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop102:10020</value>
</property>
<!-- 历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop102:19888</value>
</property>hadoop102:10020是表示历史服务器配置在那台服务器上,并且内部端口为10020(集群内部所用的访问端口)
hadoop102:19888是web端对外暴露的接口(外部用户访问的端口)
分发集群:
配置完成后需要分发同步到集群中其他服务器中
xsync $HADOOP_HOME/etc/hadoop/mapred-site.xml在hadoop102启动历史服务器
mapred --daemon start historyservemapred --daemon 启动守护进程(或者是在后台启动)
start historyserve 是启动历史服务器
(启动历史服务器之前可以先关闭所有服务,在重启Hadoop服务,在启动历史服务器)
启动后 查看进程

我们在mapred-site.xml中设置的对外端口号用于web访问
附加知识:
如何删除Hadoop HDFS中的目录:
hadoop fs -rm -r -skipTrash /目录名日志聚集功能的配置:
日志聚集概念:应用运行完成后,将程序运行日志信息上传hdfs系统上
每个服务器上都有一个日志,你想看集群上的日志就需要对他进行聚集到hdfs上
日志聚集功能好处:可以方便的查看到程序运行详情,方便开发调试
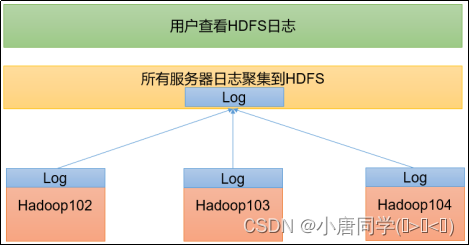
注意:开启日志聚集功能,需要重新启动NodeManager 、ResourceManager和HistoryServer。
添加配置:
在yarn-site.xml中添加
<!-- 开启日志聚集功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置日志聚集服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop102:19888/jobhistory/logs</value>
</property>
<!-- 设置日志保留时间为7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>分发配置给集群其他服务器:
xsync $HADOOP_HOME/etc/hadoop/yarn-site.xml关闭yarn服务和历史服务
stop-yarn.shmapred --daemon stop historyserver重新启动:
start-yarn.shmapred --daemon start historyserver注意:Hadoop中的输出目录是不能重使用的
进行验证:
执行命令:
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /input /output进入历史服务器:

进入日志(logs):
集群的启动与停止:
整体启动和停止hdfs:
start-dfs.shstop-dfs.sh整体启动/停止YARN
start-yarn.shstop-yarn.sh启动与停止某个服务组件:
分别启动/停止hdfs组件:
启动namenode组件
hdfs --daemon start namenode停止namenode组件:
hdfs --daemon stop namenode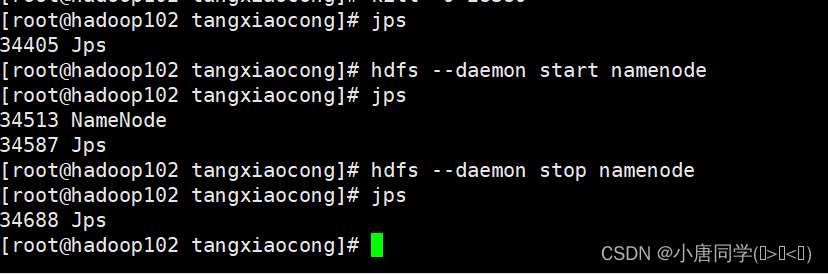
yarn组件同上
常用脚本:
脚本1-实现集群的启动和停止:
编写脚本实现集群的启动和停止
在bin目录下创建myhadoop.sh文件
输入shell脚本:
#!/bin/bash
if [ $# -lt 1 ]
then
echo "No Args Input..."
exit ;
fi
case $1 in
"start")
echo " =================== 启动 hadoop集群 ==================="
echo " --------------- 启动 hdfs ---------------"
ssh hadoop102 "/opt/module/hadoop-3.1.3/sbin/start-dfs.sh"
echo " --------------- 启动 yarn ---------------"
ssh hadoop103 "/opt/module/hadoop-3.1.3/sbin/start-yarn.sh"
echo " --------------- 启动 historyserver ---------------"
ssh hadoop102 "/opt/module/hadoop-3.1.3/bin/mapred --daemon start historyserver"
;;
"stop")
echo " =================== 关闭 hadoop集群 ==================="
echo " --------------- 关闭 historyserver ---------------"
ssh hadoop102 "/opt/module/hadoop-3.1.3/bin/mapred --daemon stop historyserver"
echo " --------------- 关闭 yarn ---------------"
ssh hadoop103 "/opt/module/hadoop-3.1.3/sbin/stop-yarn.sh"
echo " --------------- 关闭 hdfs ---------------"
ssh hadoop102 "/opt/module/hadoop-3.1.3/sbin/stop-dfs.sh"
;;
*)
echo "Input Args Error..."
;;
esac创建完毕后要对他的权限进行修改(赋予脚本执行权限),不然权限不足,不是可执行脚本
chmod +x myhadoop.sh执行后
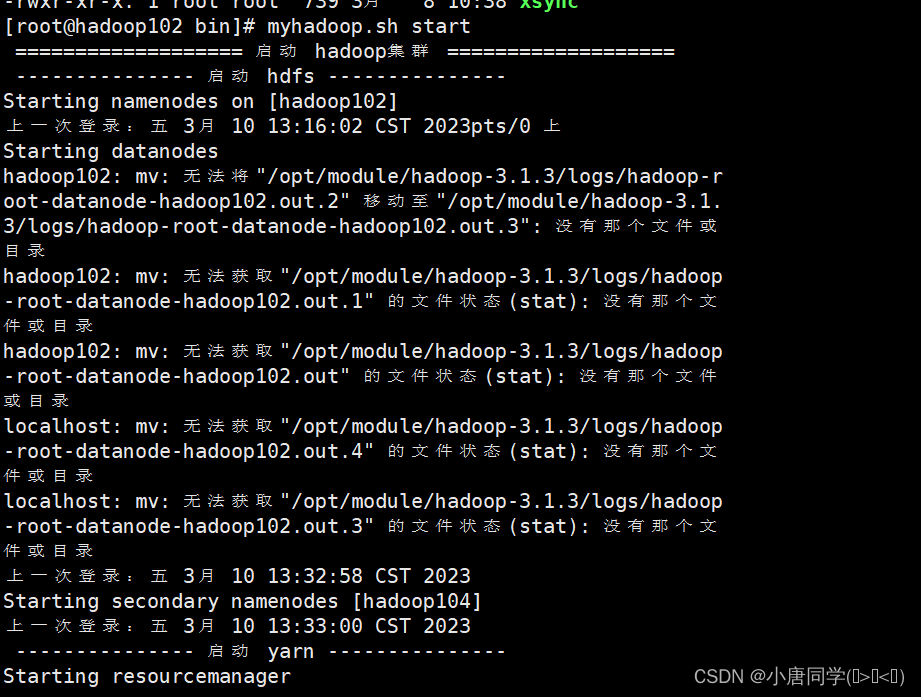

脚本2-实现查看集群上所有服务器java进程脚本:
在bin目录下创建脚本文件 jpsall
#!/bin/bash
for host in hadoop102 hadoop103 hadoop104
do
echo =============== $host ===============
ssh $host jps
done当你新建集群 直接在hadoop104上添加主机名即可
实现查看集群上所有服务器java进程脚本
直接输入jpsall就会直接执行脚本
jpsall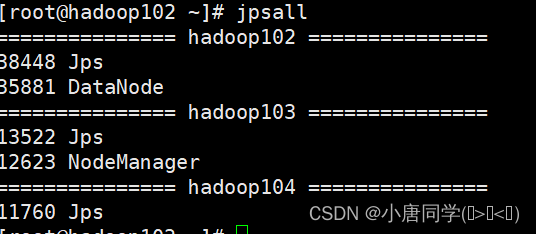
对bin目录进行分发:
xsync /home/你自己的家目录名称/bin/实现集群同步