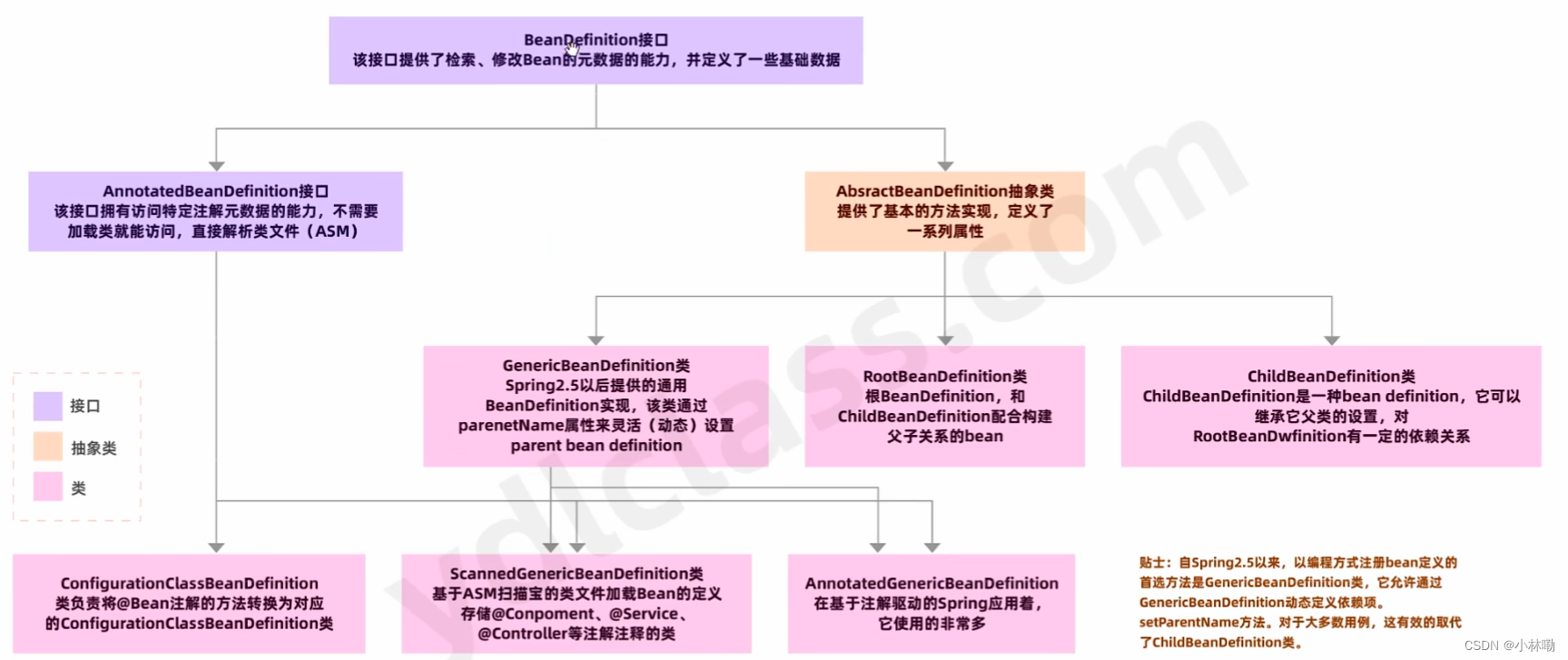
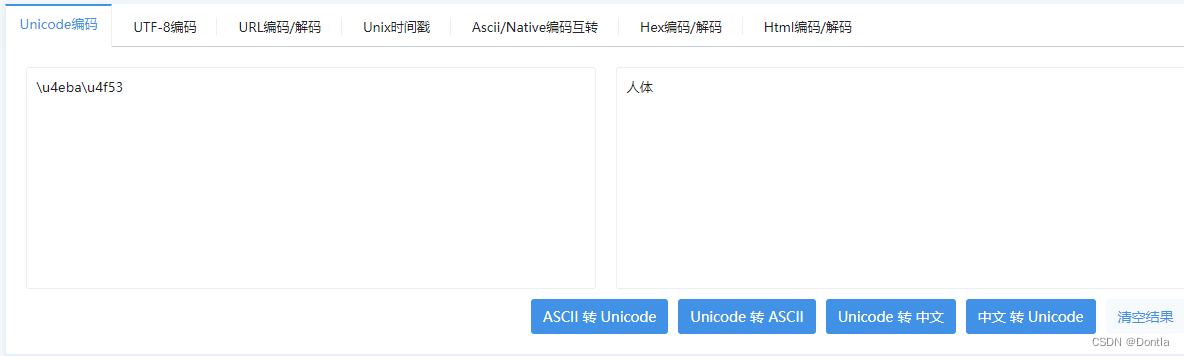
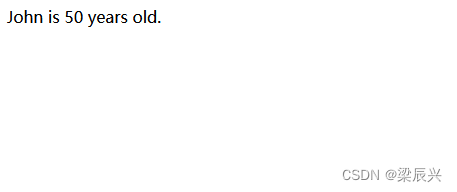在cw上报的报警信息中,有一个name字段的值是\u4eba\u4f53
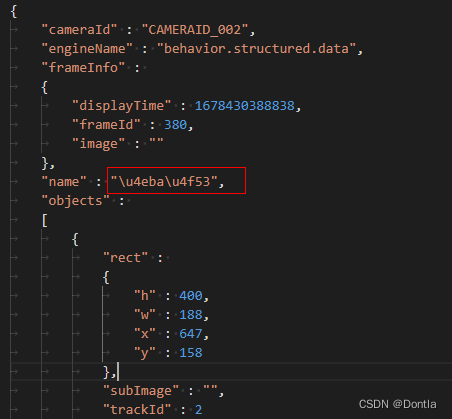
不知道是啥,查了一下,是unicode编码,用下面工具转换成汉字就是“人体”
参考文章:https://tool.chinaz.com/tools/unicode.aspx
那么我很好奇,unicode字符集与utf-8编码有何区别?
查了一下:
Unicode和UTF-8都是用于字符编码的标准。Unicode是一个字符集,它为每个字符分配了一个唯一的数字,被称为“码位”(code point)。UTF-8是一种变长的字符编码方案,它将Unicode码位编码成一个或多个字节。
简而言之,Unicode是一个字符集,而UTF-8是Unicode字符集的一种编码方式。
下面是它们之间的区别:
- Unicode是一个字符集,它包含了所有世界上的字符,每个字符都有一个唯一的码位。UTF-8是一种将Unicode码位编码成字节序列的编码方式。
- Unicode编码可以使用多种编码方式,如UTF-8、UTF-16、UTF-32等。UTF-8是一种使用变长字节的编码方式,其中每个字符可以使用1到4个字节表示。
- 在UTF-8编码中,ASCII字符(0到127之间的字符)仍然使用一个字节表示,这意味着它是向后兼容的。这使得UTF-8成为Web应用程序和互联网上的首选字符编码方式。
总之,Unicode是一个字符集,它定义了每个字符的唯一码位。UTF-8是一种变长字节编码方式,它可以将Unicode码位编码成字节序列。