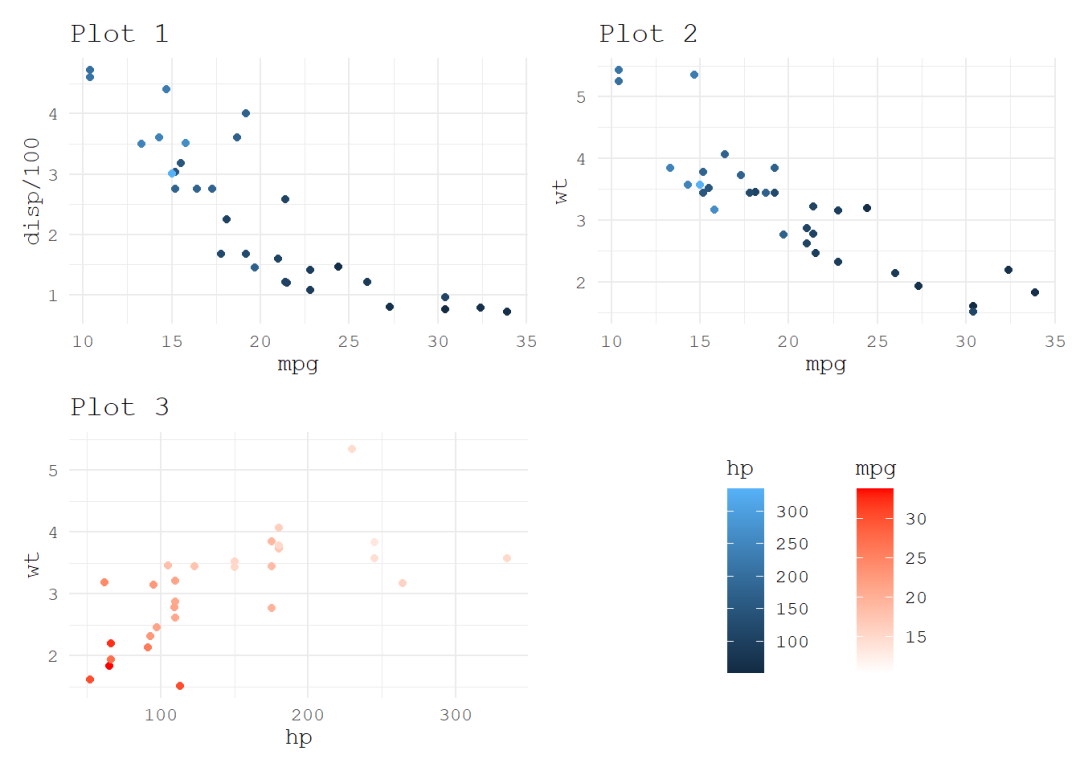
弱监督参考图像分割:Learning From Box Annotations for Referring Image Segmentation论文阅读笔记
- 一、Abstract
- 二、引言
- 三、相关工作
- A、全监督参考图像分割
- B、基于 Box 的实例分割
- C、带有噪声标签的学习
- 四、提出的方法
- A、概述
- B、伪标签生成
- 目标轮廓预测
- Proposal 选择
- 对抗边界损失 L adv \mathcal{L}_{\text{adv}} Ladv 和MIL损失
- C、从噪声标签中学习
- 五、实验
- A、数据集和评估指标
- B、实施细节
- C、性能比较
- 定量评估
- 定性评估
- D、消融实验
- L t i g h t \mathcal{L}_{\text tight} Ltight 和 L c e \mathcal{L}_{\text ce} Lce
- 对抗边界损失的有效性:
- 自训练策略 Self-T 和共同训练策略 Co-T:
- N 1 + N 2 N_1 + N_2 N1+N2 的结果:
- 与全监督算法的比较:
- 参数敏感性:
- Bounding box 没有严格标注限制的结果:
- 目标到 Box 区域的保留比例分析:
- E、失败的案例
- 六、结论
写在前面
最近一直在找论文看咩,奈何很多都是“花里胡哨”,嗯,就是结构设计的挺巧妙,没法通用呀~
这是一篇弱监督 Box 监督下的参考图像分割论文,最主要是提出了一个边界损失函数~
- 论文地址:Learning From Box Annotations for Referring Image Segmentation
- 代码地址:https://github.com/fengguang94/Weakly-Supervised-RIS,尚未完全发布
- 收录于 TNNLS 2022
一、Abstract
参考图像分割 Referring image segmentation (RIS) 的方法需要大量像素级别的标注数据,而本文提出一种基于 Box 标注的弱监督 RIS 方法。首先,设计一个边界对抗损失来提取 Bounding Box (BB) 中的目标轮廓;而这些轮廓用于选择合适的区域 Proposal 来生成 Pseudoground-truth (PGT);其次,设计一种共同训练 (Co-T) 策略来对伪标签进行过滤,具体来说,训练两个网络并迭代的引导彼此挑选出干净的标签,目的是弱化噪声标签对模型训练的影响,实验结果表明能以 63 帧/秒的速度来产生高质量的 masks。
二、引言

首先讲一下参考图像分割的定义,接下来指出之前基于全监督的 RIS 方法耗时且费力,因此提及弱监督实例分割方法,但是 RIS 的弱监督方法还未被考虑,因此本文着手解决这一任务。
接下来是对一些弱监督实例分割方法的介绍,有基于 BB 的,基于伪标签的,但是基于伪标签的方法并不能捕捉目标区域的一般形状,只能确保所选择的 Proposal 尽可能属于 BB。但由于目标尺寸、外观的不同,因此很难选择类似 GT 的 BB。有一些基于全局限定的端到端模型缺乏对目标轮廓的描述,因此可能会存在混淆的边界像素点。
好的 Proposals 能够提供重要的目标级别先验,但是不能感知前景的具体形状。一个合理的假设是如果前景轮廓可以从 BB 中推理得出,那么就能使用其作为一个强先验信息来滤除区域 Proposal。于是本文根据这一思想提出一种对抗边界损失,其包含两个构件,一个用于促进目标主干区域有着高度的激活值,另外一个用于抑制高度激活值。在这种对抗作用下,目标的主体部分被抑制,而轮廓被突出,接下来利用学习到的轮廓来挑选出少量的 Proposal 来生成 PGT (伪标签)。
伪标签包含有噪声信息,会损坏模型的泛化能力,因此本文设计一种基于共同训练 Co-T 策略来过滤噪声标签。具体来说,使用 Cross-entropy 损失作为偏置来决定伪标签的置信度,之后选择小损失的像素用于反向传播,并且同时采用两个网络来相互引导彼此间的反向传播。本文主要贡献如下:
- 设计了一种基于 Box 标注的对抗边界损失来捕捉前景目标轮廓,这些轮廓用于过滤proposal从而获得精确的伪标签;
- 引入一种 Co-T 策略来过滤伪标签,促进两个网络来引导彼此,这能减小错误标签像素在反向传播中的影响;
- 实验效果很好,速度很快。
三、相关工作
A、全监督参考图像分割
介绍下概念,指出其难点,列举之前的方法,指出缺点:获得像素级别的 masks 费时费力,相比之下,本文提出的方法只依赖 BB 的标注。
B、基于 Box 的实例分割
弱监督方法一般分为两类,一类是采用无监督的方法生成伪标签,然后来训练分割网络;一类是利用 BB 来得出全局限制并直接建立一个新的损失函数。
接下来是举例。指出缺点:所有的方法没有确切考虑目标的边界信息。相比之下,本文提出的方法定义了一个对抗边界损失来预测粗糙的目标轮廓,然后结合 BB 以及预测的轮廓作为先验来滤除候选的 Proposal,这使得剩下的 Proposals 能够和目标有着高度的重合。
C、带有噪声标签的学习
一些基于 box 监督的方法将分割任务作为一个噪声标签的学习任务,缺点:由样本选择时的偏置导致的误差会一直积累下去。本文采用两个网络来迭代地挖掘出有用的标签来训练彼此,能够提供不同的视角,过滤不同类别的噪声及避免误差的积累。
四、提出的方法

A、概述
本文提出的框架建立在 BRINet 之上,核心为 BCAM,由一个视觉引导的语言注意力模块 VLAM 和一个语言引导的视觉注意力模块 LVAM 构成。
采用编码器融合策略,以一种残差连接的方式将 BCAM 嵌入到 ResNet101 内,解码器采用 FPN 结构。本文提出的方法主要分成两个阶段:第一阶段采用对抗边界损失来捕捉目标轮廓,之后联合 BB 选择合适的 Proposals 作为伪标签用于接下来的训练。第二阶段同时训练两个新的分割网络,彼此间引导着来阻止虚假标签的反向传播,从而缓解噪声伪标签的影响。
BRINet: Z. Hu, G. Feng, J. Sun, L. Zhang, and H. Lu, “Bi-directional relationship inferring network for referring image segmentation,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., Jun. 2020, pp. 4424–4433.
B、伪标签生成
讲述一下动机:对于弱监督 RIS,常规做法是利用无监督的区域提议方法和网格式的目标提议来生成一系列的分割 masks,然后采用 box 级别的标注作为先验来选择高质量的候选 mask。然而 BB 仅仅能提供目标的位置信息,而不能用来描述目标。因此对于目标边界来说,目标 mask 和选择的 proposal 之间的匹配概率不能保证,从而影响模型的训练。于是本文尝试捕捉目标的轮廓并将其作为先验从而选出高质量的 Proposal。步骤如下:
目标轮廓预测
首先,轮廓先验假设:目标区域充分靠近 Box 标注的边缘,因此至少 BB mask 的每一行或者每一列属于前景。对于 RIS 的前景/背景分类器来说,设
C
∈
[
0
,
1
]
H
×
W
C\in{[0,1]^{H\times W}}
C∈[0,1]H×W 为模型在第一阶段的输出特征图,其中 0,1 分别表示非轮廓点和轮廓点,
C
r
o
w
i
C_{row}^{i}
Crowi 和
C
c
o
l
j
C_{col}^{j}
Ccolj 为预测特征图的第
i
i
i 行和第
j
j
j 列。定义
P
r
o
w
(
i
)
=
max
(
C
r
o
w
i
)
P_{row}(i)=\max(C_{row}^{i})
Prow(i)=max(Crowi),
P
c
o
l
(
j
)
=
max
(
C
c
o
l
j
)
P_{col}(j)=\max(C_{col}^{j})
Pcol(j)=max(Ccolj) 分别计算
C
C
C 上第
i
i
i 行和第
j
j
j 列的最大值。
当 box 跨越第
i
i
i 行或者第
j
j
j 列时,这一行或列穿过了前景区域,于是
P
r
o
w
(
i
)
P_{row}(i)
Prow(i) 或者
P
c
o
l
(
j
)
P_{col}(j)
Pcol(j) 的预测值应该接近 1,反之接近 0。基于这一先决条件,定义损失函数如下:
L
tight
=
∑
C
row
i
,
C
col
j
∩
B
∉
∅
−
[
log
(
P
r
o
w
(
i
)
)
+
log
(
P
c
o
l
(
j
)
)
]
+
∑
C
fow
i
,
C
col
j
∩
B
∈
∅
−
[
log
(
1
−
P
r
o
w
(
i
)
)
+
log
(
1
−
P
c
o
l
(
j
)
)
]
\mathcal{L}_{\text {tight }}= \sum_{C_{\text {row }}^{i}, C_{\text {col }}^{j} \cap \mathcal{B} \notin \varnothing}-\left[\log \left(P_{\mathrm{row}}(i)\right)+\log \left(P_{\mathrm{col}}(j)\right)\right] +\sum_{C_{\text {fow }}^{i}, C_{\text {col }}^{j} \cap \mathcal{B} \in \varnothing}-\left[\log \left(1-P_{\mathrm{row}}(i)\right)+\log \left(1-P_{\mathrm{col}}(j)\right)\right]
Ltight =Crow i,Ccol j∩B∈/∅∑−[log(Prow(i))+log(Pcol(j))]+Cfow i,Ccol j∩B∈∅∑−[log(1−Prow(i))+log(1−Pcol(j))]其中
B
\mathcal{B}
B 为 BB 包围的矩形区域,上式右边第一项和第二项确保了最大激活区域能够定位到与 BB 相交的行或列。因此这一损失函数
L
tight
\mathcal{L}_{\text {tight }}
Ltight 能够驱动网络去预测 BB 内的前景。之后定义一个 0 限制条件,目的是使得预测的特征图倾向于全为0:
L
aro
=
∑
i
=
1
H
∑
j
=
1
W
−
log
(
1
−
C
i
,
j
)
\mathcal{L}_{\text {aro }}=\sum_{i=1}^{H} \sum_{j=1}^{W}-\log \left(1-C_{i, j}\right)
Laro =i=1∑Hj=1∑W−log(1−Ci,j)于是结合这两个损失来构成对抗边界损失:
L
adv
=
L
tight
+
λ
⋅
L
zero
\mathcal{L}_{\text{adv}}=\mathcal{L}_{\text{tight}}+\lambda\cdot\mathcal{L}_{\text{zero}}
Ladv=Ltight+λ⋅Lzero其中
λ
\lambda
λ 设为 0.05,目的是缩小比重,
L
tight
\mathcal{L}_{\text{tight}}
Ltight 为全局限制,
L
zero
\mathcal{L}_{\text{zero}}
Lzero 为局部限制。
下图展示了这些损失函数的可视化:

Proposal 选择
首先选择一种无监督 proposal 方法来生成一些区域 proposals,之后预测的轮廓 mask 可以用来选择一些合适的 proposals。定义目标函数如下:
arg
max
y
{
C
∩
b
(
⋃
p
i
∈
P
y
i
⋅
p
i
)
}
s.t.
y
i
=
0
or
1
,
P
⊆
box
\arg \max _{y}\left\{\mathcal{C} \cap b\left(\bigcup_{p_{i} \in \mathcal{P}} y_{i} \cdot p_{i}\right)\right\} \text { s.t. } y_{i}=0 \quad \text { or } \quad 1, \mathcal{P} \subseteq \text { box }
argymax⎩
⎨
⎧C∩b
pi∈P⋃yi⋅pi
⎭
⎬
⎫ s.t. yi=0 or 1,P⊆ box 其中
C
\mathcal{C}
C 为轮廓点像素的集合,可以通过对预测的特征图
C
C
C 二值化获得。
P
\mathcal{P}
P 为 proposals 的集合,
b
b
b 为边界提取器。
接下来利用膨胀和腐蚀操作分别处理得到的 mask,然后就可以从膨胀后 mask 中抽取出腐蚀的 mask,从而得到边界框。如果 proposal
p
i
p_i
pi 被选择上,那么设置其标签
y
i
=
1
y_i=1
yi=1,否则
y
i
=
0
y_i=0
yi=0。所有被选择出的 proposal 都作为 PGT mask,而 NP 难样本的构建可以通过下面的贪婪算法获得:

首先以一个种子 proposal sp 开始,其边界和目标轮廓
C
\mathcal{C}
C 有着最大的交集。接下来利用 sp 作为偏置来添加或移除集合
S
S
S 中的 proposal,直到
S
S
S 中的边界有着和目标轮廓最大的交集。
对抗边界损失 L adv \mathcal{L}_{\text{adv}} Ladv 和MIL损失
MIL 损失建立在局部交集之上,并不会捕捉区域之外的信息,而 L adv \mathcal{L}_{\text{adv}} Ladv 建立在全局预测特征图之上,从而避免采样正负样本的过程。MIL 损失直接用于训练分割网络,而 L adv \mathcal{L}_{\text{adv}} Ladv, L tight \mathcal{L}_{\text{tight}} Ltight 和 L zero \mathcal{L}_{\text{zero}} Lzero 损失一起来强制捕捉目标的轮廓信息。之后利用这些学习到的轮廓来得到一个更加精确的伪标签。
C、从噪声标签中学习
为了减轻伪标签中噪声对训练的影响,本文提出选择高置信度的像素级标签来参与监督。思路来源:一个模型容易积累误差,而两个模型可以彼此监督从而减小误差。于是本文建立两个网络来迭代地决定哪些标签是有用的。

算法流程:首先对于两个网络
N
1
N_1
N1 和
N
2
N_2
N2,基于伪标签
M
M
M 来计算一个 batch 内每个像素的 cross-entropy 损失,然后基于损失值对这些像素进行排序。于是有着最小损失的像素很有可能是正确的标签。之后记录每个网络中最小
R
(
t
)
%
R(t)\%
R(t)% 比率损失的像素点索引,最后根据这些索引来控制反向传播过程中彼此网络的对应位置。(注意,两个网络仅仅在初始化参数上不同。)
保留比例:模型一开始学习简单且通用的数据类型,然后逐渐地拟合噪声数据。因此在训练开始时采用一个更大的保留比例
R
(
t
)
%
R(t)\%
R(t)%,实际设置为:
R
(
t
)
=
1
−
η
⋅
(
t
/
T
)
R(t)=1-\eta\cdot(t/T)
R(t)=1−η⋅(t/T),其中
t
t
t 为迭代步,最大迭代次数
T
T
T 设置为 50K,噪声水平
η
\eta
η 设置为 0.1。
五、实验
A、数据集和评估指标
数据集:UNC、UNC+、Google-Ref、ReferIt;
评估指标:IoU、Prec@X。
B、实施细节
SGD 优化器,初始学习率 0.002,50K 次迭代之后 × 10 % \times 10\% ×10%,最大迭代 90K,batch_size 16,权重衰减 0.0005,输入图像尺寸 320 × 320 320\times 320 320×320,最大句子词数 20,
C、性能比较
定量评估


定性评估

D、消融实验
消融实验在 UNC 数据集上进行。
L t i g h t \mathcal{L}_{\text tight} Ltight 和 L c e \mathcal{L}_{\text ce} Lce

对抗边界损失的有效性:
同表 Ⅲ。
自训练策略 Self-T 和共同训练策略 Co-T:
同表 Ⅲ。
N 1 + N 2 N_1 + N_2 N1+N2 的结果:
同表 Ⅲ。
与全监督算法的比较:
同表 Ⅲ。
参数敏感性:
同表 Ⅲ 及表 Ⅳ。

Bounding box 没有严格标注限制的结果:
同表 Ⅲ。
目标到 Box 区域的保留比例分析:
同表 Ⅲ。
E、失败的案例

六、结论
本文提出一种两阶段训练方法用于 box 级别的 RIS 弱监督分割。第一阶段用对抗边界损失捕捉前景区域的轮廓,然后利用这些轮廓作为先验挑选出合适的 proposal 作为伪标签。第二阶段采用 Co-T 策略来促进两个网络过滤包含噪声的伪标签以及避免误差积累。实验效果牛批。
写在后面
感觉下吧,相比于三大顶会确实差了点意思,而且作者的写作水平不敢恭维,只能说可以做个 Baseline,mark 一下 😁。