作者:niceperf 团队 (李扬, 郭琳)
大家好,我们是 niceperf 团队,在天池 DeepRec CTR 模型性能优化大赛中,很荣幸取得了冠军的成绩 (Top 1/3802)。这篇文章复盘一下我们的参赛经验,希望对大家有所启发。
1.背景介绍
我们团队包括两名成员:李扬、郭琳,现就职于国内知名互联网公司,担任广告算法工程师。本次比赛的赛题,是在给定的深度学习框架 DeepRec 下,优化 WDL、DeepFM、DLRM、DIN、DIEN、MMoE 六大经典模型的单机 CPU 训练速度。
赛题具有一定的挑战性,我们在日常工作中经常使用的训练性能优化手段主要是分布式训练和数据IO 优化,而本次比赛限定了是单机条件,而且在数据 IO 方面的性能提升空间很有限。这就要求我们结合模型结构与训练框架,做出更细致深入的优化。
好在赛题涉及的技术栈与我们是较为契合的,比赛初期短暂适应后就可以上手优化了。首先,DeepRec的底层框架是 TensorFlow 1.15,我们在日常工作中已对其核心代码非常熟悉;此外,比赛所涉及的模型,团队成员在实际业务中已使用多年,能够结合对模型结构的理解,更快定位训练性能瓶颈所在之处,便于合理分配比赛精力,在优势方向重点发力。
2.优化内容
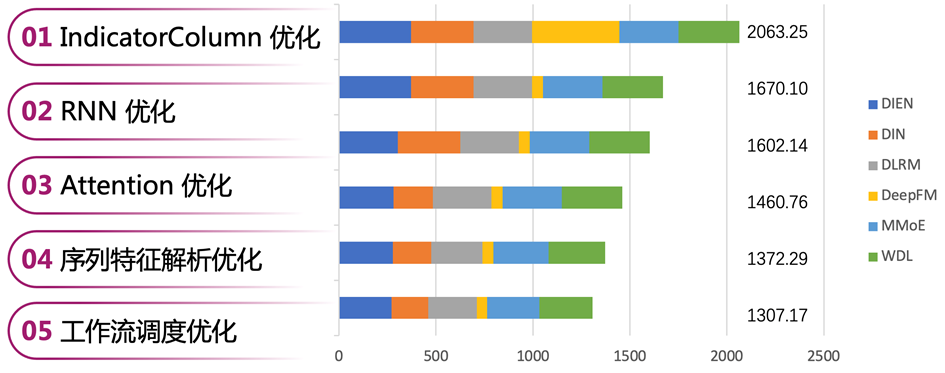
在做优化之前,要先确定优化的切入点,先把 low-hanging fruit 拿到,再做更深入的优化,有利于比赛的推进。我们逐模型分析了单步耗时,统计结果如下图所示:
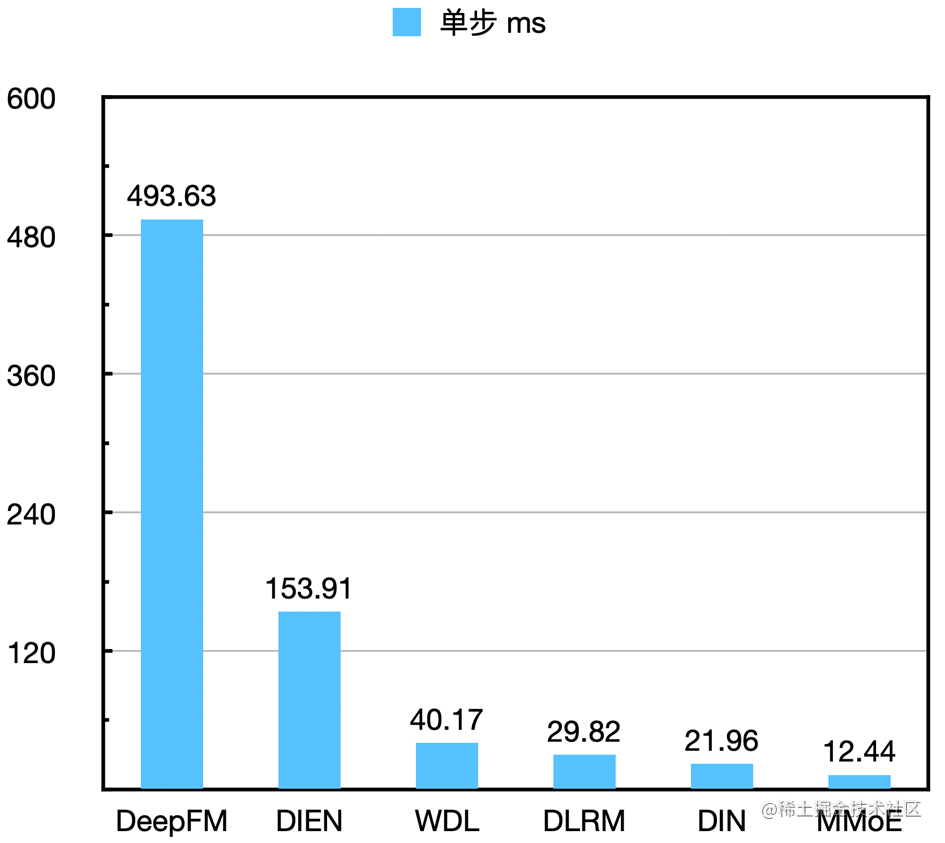
从数据来看,DeepFM 耗时如此之高是不符合预期的,因此我们将该模型作为切入点,展开后续的优化。
(1) IndicatorColumn 算子优选 (DeepFM)
DeepFM 的单步训练timeline 如下图所示:

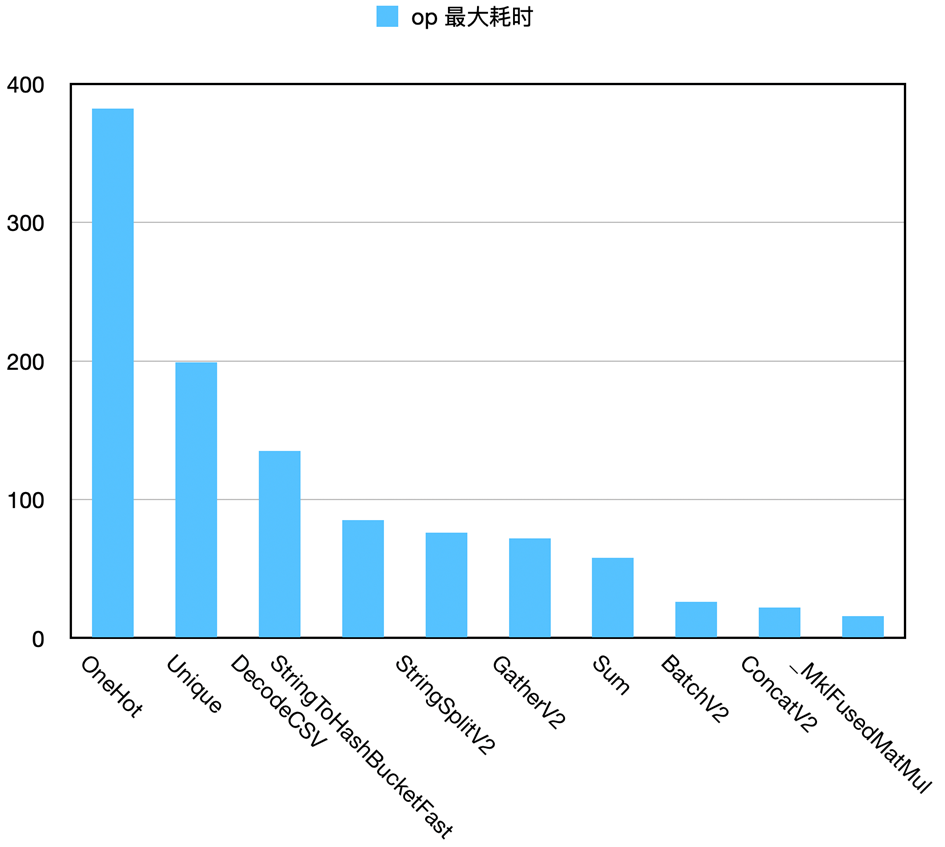
对上图数据做 op 粒度的下钻分析后发现,OneHot 为耗时头部算子,而该算子来自于 IndicatorColumn,这里可能存在较大优化空间。
进一步,我们精读了 IndicatorColumn 的源码。为了兼容定长 & 非定长的特征,其输入类型为 SparseTensor,输出类型为 Tensor,为该特征的 multi-hot 表达。具体处理过程分为三步:
Step 1:调用sparse_tensor_to_dense,将 SparseTensor 转为 Tensor;Step 2:调用 one_hot,得到每个子特征的 one-hot 表达;Step 3:调用reduce_sum,将属于同样本的子特征 one-hot 求和,得到 multi-hot 表达。
针对部分高度稀疏的特征,sparse_tensor_to_dense 带来了额外的 padding,引入了无效计算。针对这一问题,我们创建了子类IndicatorColumnV2,改变原有的 multi-hot 生成方式,采用 scatter_nd 代替 sparse_tensor_to_dense + one_hot + reduce_sum。代码示意如下:
tf.scatter_nd(indices=multi-hot 非零值坐标,updates=全 1 向量,shape=原输入 sparse tensor 的 dense shape)
优化后单步训练耗时从 500 ms 降低至 75 ms,前后性能对比如下两表所示,其中红框中的 ConcatV2 算子是用来将多个特征向量拼接送入后续 MLP 使用的。
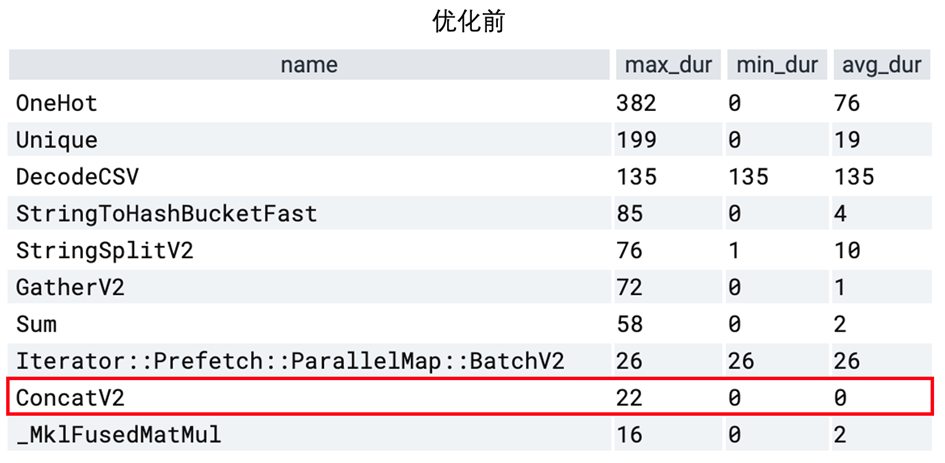
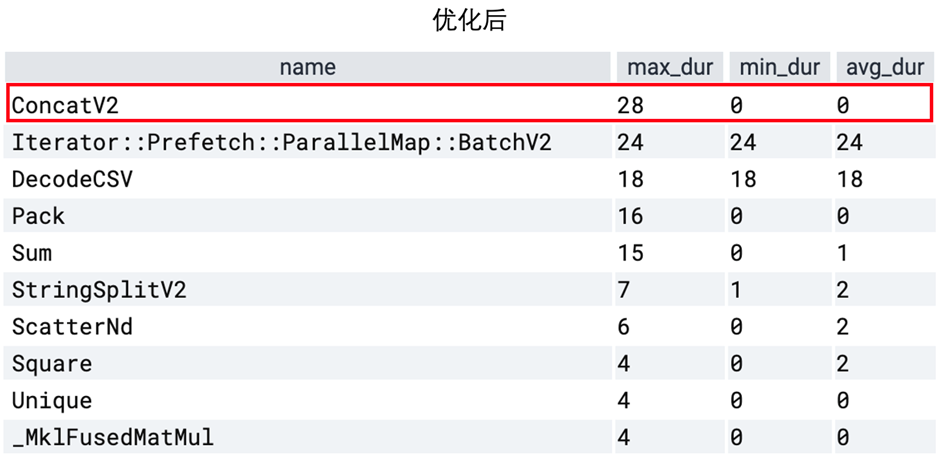
ConcatV2 算子是 “并行特征处理” 与 “串行MLP 多层计算” 的分界点,它的耗时排名从第 9 名变为了第 1 名,可见特征处理阶段的 op 并行效率得到大幅提升。这一提升一方面来自于 IndicatorColumn 本身的性能优化,另一方面来自于有限硬件资源下,优化后的IndicatorColumn 让出了更多线程供其他算子使用,从而带来了更显著的性能提升。
(2) RNN cell 算子融合 (DIEN)
针对 DeepFM 的优化告一段落,我们将关注点转向单步耗时第二高的 DIEN。其整体结构如下图所示:
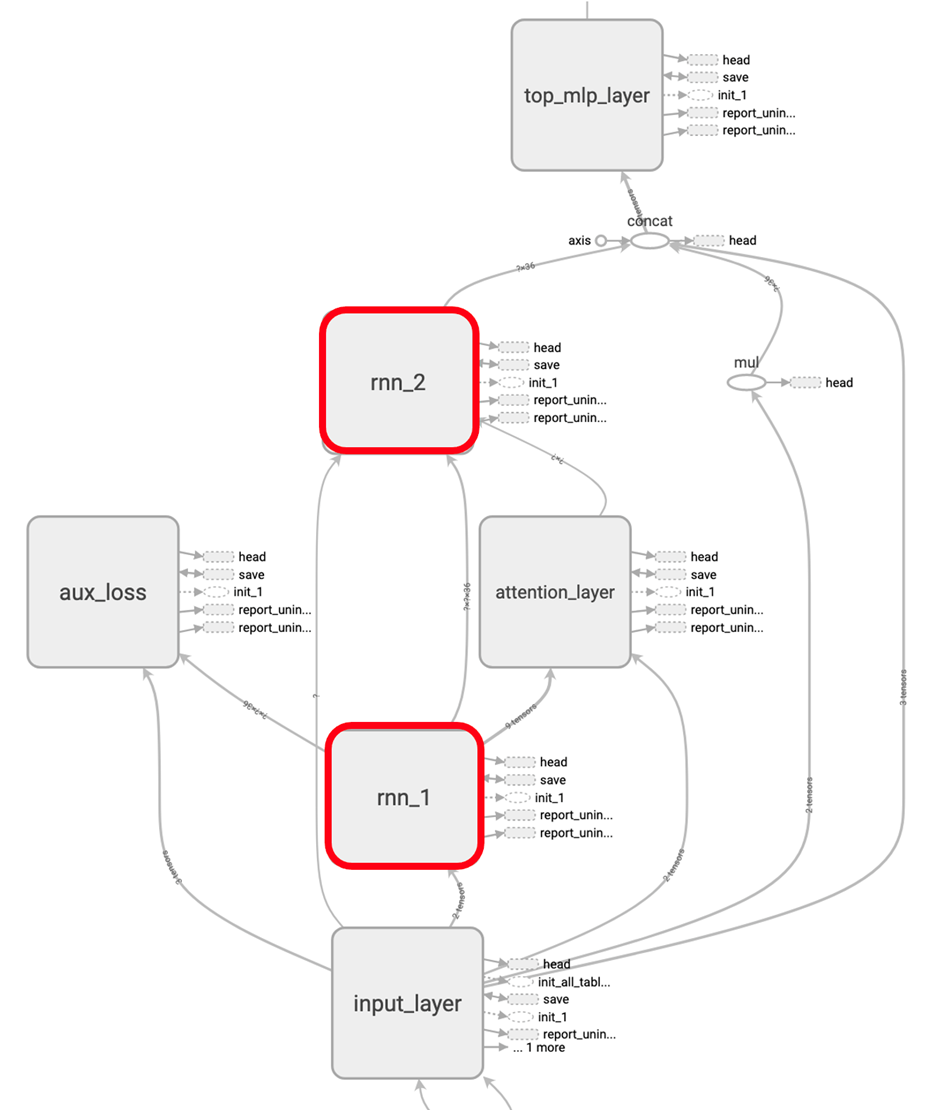
在 DIEN 中有两个 RNN 层,即 GRU 与 VecAttGRU,分别对应上图中两个红框内的结构。由于 RNN 采用循环结构,所以很自然的想法是针对单步 cell 做优化,提升单步执行性能从而带动整体性能提升。
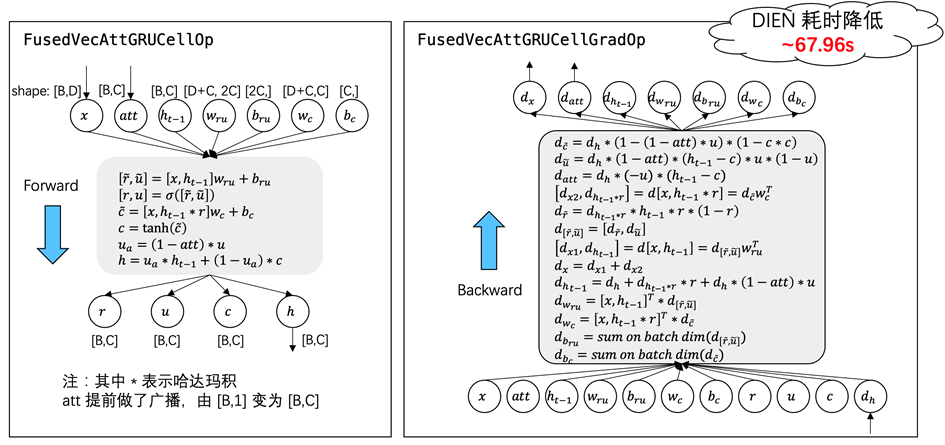
比赛中我们分别针对 GRU cell 与 VecAttGRU cell 编写了前向计算与梯度计算的 c++ 算子,以替代原有的多个算子构成的子图,DIEN 整体耗时降低 ~67.96 秒。以 VecAttGRUCell 为例,前向 op、梯度 op 执行逻辑如下图所示:
(3) Attention layer 算子优选 (DIN & DIEN)
DIN 与 DIEN 中都用到了 Attention layer,在它们的原始实现中,存在大量无效 padding。这是因为不同用户的历史行为序列长度不一,当多个样本 batching 在一起时,容易出现部分样本序列短、部分样本序列长的现象。
在原始实现中,会将各个样本的 query padding 到统一长度,与 facts 交互后生成三维张量送入后续 MLP 计算。由于引入了无效 padding,导致 MLP 计算过程存在额外计算量,效率较低。
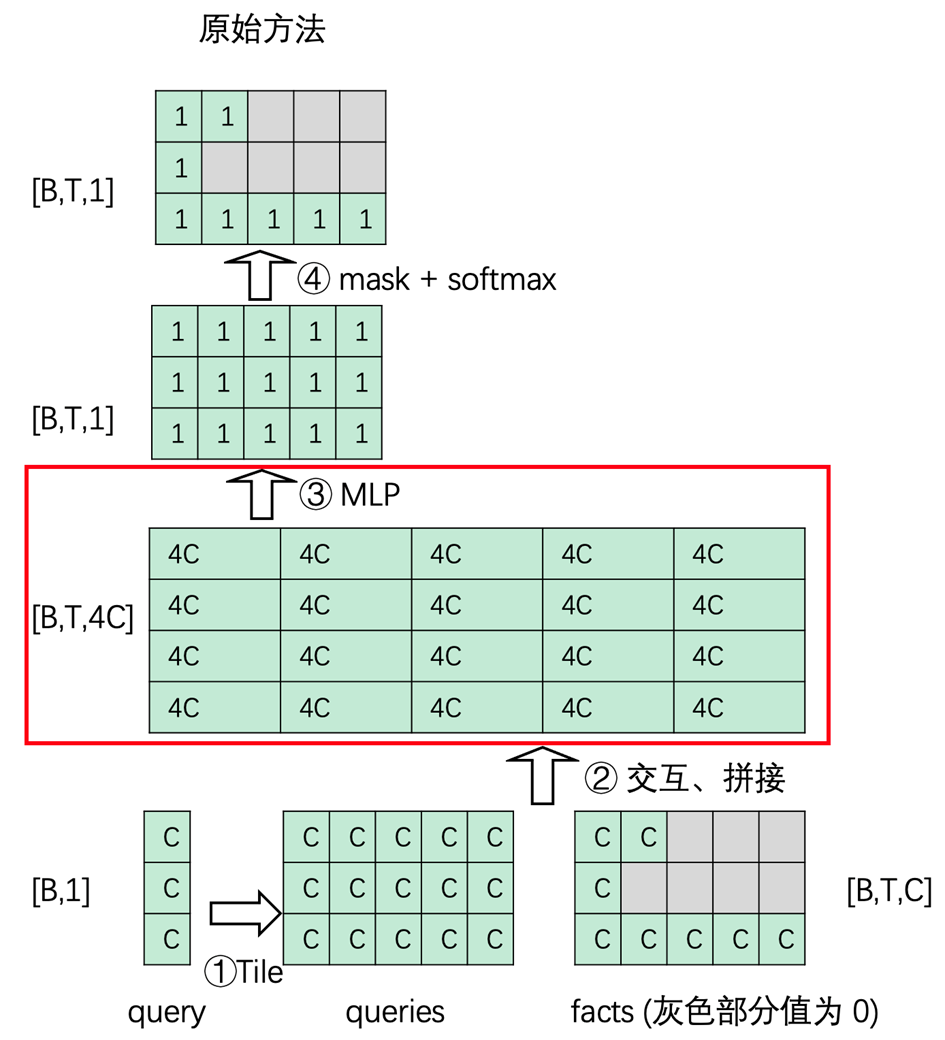
优化方法就是通过组合合适的算子,去除 padding 部分,具体过程如下图所示。
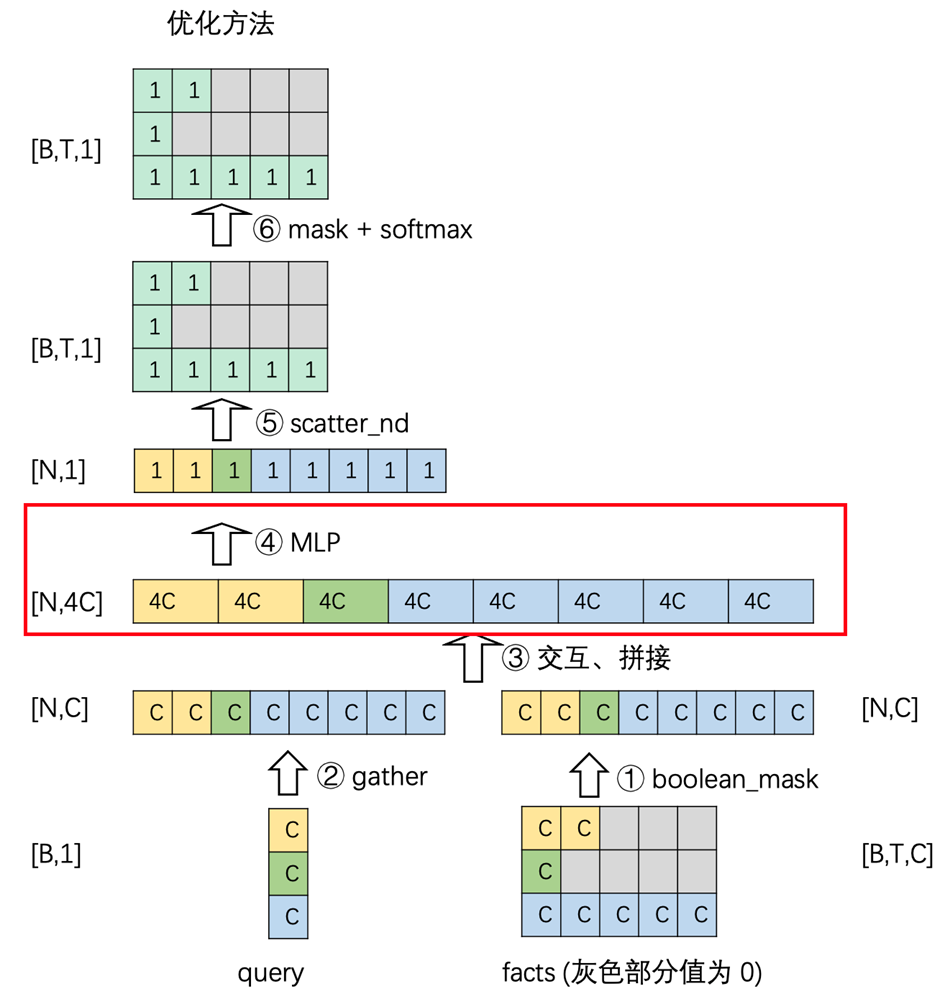
对比两张图的红框部分,进入 MLP 的张量 shape 从 [B,T,4C] 变为[N,4C]。训练过程中 BT >= N 恒成立,通常一个 batch 内的序列长度不均衡,BT/N 越大,性能收益越大,最终 DIN 与 DIEN 合计耗时降低约 141.38 秒。
(4) 序列特征解析算子融合
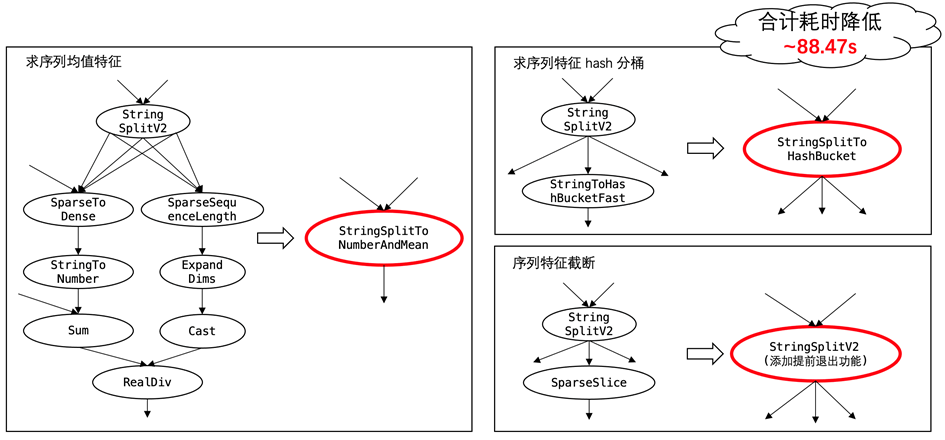
在模型输入特征解析环节,存在诸多琐碎的小算子构成的子图,比如求序列均值特征的子图,典型案例如 history_price,原始数据为数值序列通过某个分隔符拼接构成的字符串,构建模型输入时需要将该字符串 split 后转成数值再通过多个步骤求均值,本次比赛中我们编写了两个 c++ 算子 (SparseSequenceLength、StringSplitToNumberAndMean)替换掉了整个繁杂的过程。其他被替换的还有:求序列特征 hash 分桶的子图、序列特征截断的子图,累积耗时降低约 88.47 秒。
(5) 工作流调度优化
对工作流的优化也是我们的一项重点工作。
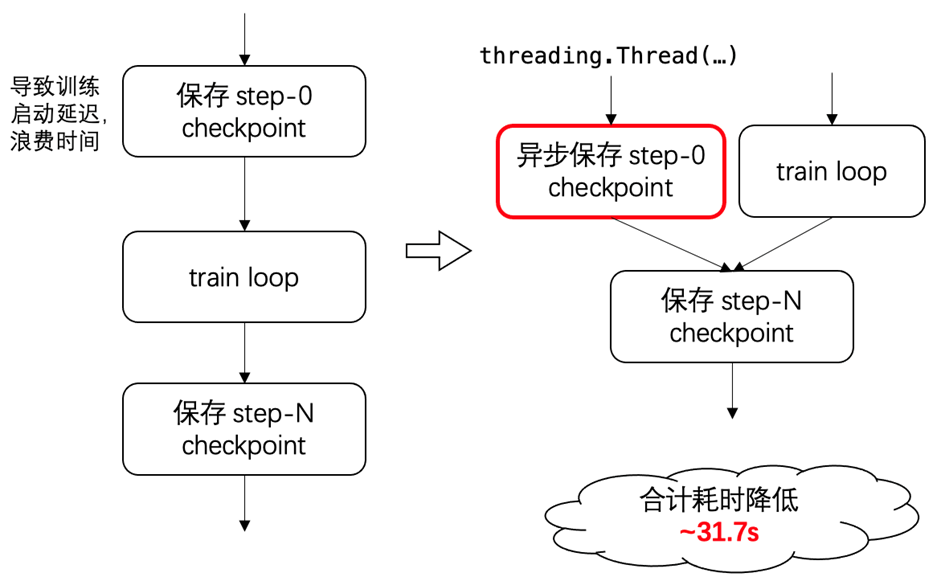
第一个优化点是 “异步检查点”,思路是将 checkpoint (即检查点) 的保存过程异步化,减少对模型训练过程的干扰。具体的优化方法是开发了 AsynchronousCheckpointSaverHook 替代原有的CheckpointSaverHook,开辟新的线程专门用来保存 checkpoint,合计耗时降低约 31.7 秒。
另一项优化是多线程配置超参优化。如:针对 elm 数据集的相关模型开启 smart stage;stage prefetch 使用独立线程池,算子并行度 intra_op 与 inter_op 均设为 8 (主线程池的配置也一致);stage prefetch threads 设为 1,capacity 设为 2;dataset map threads 设为 1 等等。
配置相关的超参优化暂无放之四海而皆准的规则,是我们结合给定的硬件资源、数据集,在多个模型整体效果上的粗调结果,调参思路是尝试降低数据 parsing 占用的线程资源,观察是否有性能提升。最终多个版本优化后,整体耗时降低约 33.4 秒。
3.优化效果与总结
各优化点的效果汇总如下图所示,整体训练耗时降低 36.65% (2063.25 秒 → 1307.17 秒)。
主要优化方法分为算子优选与算子融合。两者在思路上是一致的,都是选择性能更好的算子 (组合) 来替换原来的算子 (组合),在本文中的区别只在于是否开发了新的 macro op 替换原有的子图。
一些其他的优化措施包括:异步检查点、多线程超参优化,也对性能提升有较大帮助。此外,其他尝试过但没有取得全局稳定收益的措施还有很多,本文不做详尽探讨。
最后感谢主办方提供的这次比赛机会,过程中主办方技术团队与我们多次沟通协作,不断升级比赛评测系统,使评测结果更加稳定,为我们提供了卓越的竞技环境。通过参加 DeepRec CTR 模型性能优化大赛,对深度学习框架性能优化加深了理解,期待DeepRec 框架继续推出更多性能优化新特性。
DeepRec开源地址: https://github.com/alibaba/DeepRec