目录
论文 dragonnet
1介绍
2 Dragonnet
3定向正则化
4相关工作
5实验
6讨论
NN-Based的模型 dragonnet
如何更新参数
dragonnet的损失函数
CausalML
Dragonnet类
论文代码
论文 dragonnet
Adapting Neural Networks for the Estimation of Treatment Effects
应用神经网络估计治疗效果
摘要:文介绍了利用神经网络从观察数据中估计治疗效果。一般来说,评估分为两个阶段。首先,我们为每个单元的预期结果和治疗概率(倾向评分)拟合模型。其次,我们将这些拟合模型插入到影响的下游估计器中。神经网络是第一步模型的自然选择。我们要解决的问题是:我们如何调整第一步中使用的神经网络的设计和训练,以提高对治疗效果的最终估计的质量?我们根据统计文献中关于估计治疗效果的见解,提出了两种适应方法。第一个是一个新的架构,Dragonnet,它利用倾向分数的充分性进行估计调整。第二种是正则化过程,有针对性的正则化,它会对具有非参数最优渐近特性的模型产生偏差。对因果推断基准数据集的研究表明,这些适应优于现有方法。代码可从github.com/claudiashi57/dragonnet获得。
1介绍
我们从观察数据中考虑因果效应的估计。在随机对照试验(RCT)昂贵或不可能进行的情况下,观察数据往往很容易获得。然而,从观察数据得出的因果推断必须解决(可能的)影响治疗和结果的混杂因素。未能对混杂因素进行调整可能导致不正确的结论。为了解决这个问题,医生除了收集治疗和结果状态外,还收集协变量信息。如果协变量包含所有混杂变量,则可以确定因果效应。我们将在“无隐藏混淆”的背景下贯穿全文。我们考虑的任务是估计治疗T(例如,患者接受药物治疗)对结果Y(是否康复)的影响,并对协变量X(例如,疾病严重程度或社会经济地位)进行调整。
我们考虑如何使用神经网络来估计治疗效果。对处理效果的估计分两个阶段进行。首先,我们拟合条件结果Q(t, x) = E[Y | t, x]和倾向得分g(x) = P (t = 1|x)的模型。然后,我们将这些拟合模型插入下游估计器。神经网络强大的预测性能促使它们用于效果估计。我们将使用神经网络作为条件结果和倾向评分的模型。
原则上,将神经网络用于条件结果和倾向评分模型是简单的。我们可以使用一个标准网络来从治疗和协变量中预测结果Y,并使用另一个标准网络来从协变量中预测治疗。通过选择合适的训练目标,训练后的模型将产生条件结果和倾向分数的一致估计。然而,神经网络研究主要集中在预测性能上。是什么对因果推断来说,重要的是下游估计的质量。
这就引出了我们的主要问题:我们如何修改神经网络的设计和训练,以提高治疗效果估计的质量?我们通过对治疗效果估计的统计文献的结果进行调整来解决这个问题。
本文的贡献有:
1.一种基于倾向分数的因果估计充分性的神经网络结构——dragonnet。
2.一种基于非参数估计理论的定向正则化方法。
3.这些方法在已建立的基准数据集上的实证研究。我们发现,与现有的神经网络相比,该方法大大提高了估计质量。
2 Dragonnet
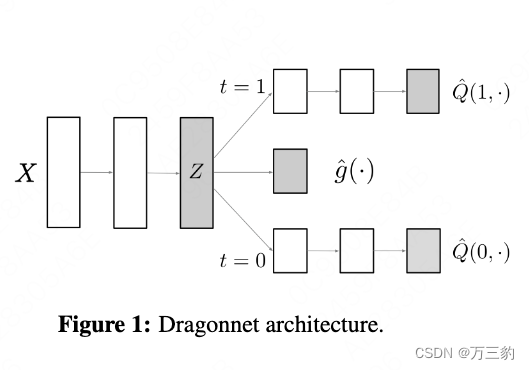
3定向正则化
现在我们转向目标正则化,这是对用于神经网络训练的目标函数的一种修改。该修正目标基于非参数估计理论。它产生了一个拟合的模型,具有合适的下游估计量,保证了理想的渐近性质。我们回顾了半参数估计理论的一些必要结果,然后解释了目标正则化。本节的摘要如下:

4相关工作
这些方法与因果推断和估计理论的不同领域相联系。
因果推断的表示。Dragonnet与使用表示学习思想进行治疗效果估计的论文有关。Dragonnet架构与TARNET类似,TARNET是Shalit等人[SJS16]使用的双头结果模型作为基线。文献中的一种方法强调学习在治疗和结果之间具有平衡分布的协变量表示;例如,BNNs [JSS16]和CFRNET [SJS16]。其他工作将深度生成模型与标准因果识别结果结合起来。CEVEA [Lou+17]、GANITE [YJS18]和CMPGP [AS17]分别使用vae、GANs和多任务高斯过程来估计处理效果。另一种方法是将(预训练的)倾向评分与神经网络结合起来;例如,倾向下降[AWS17]和完美匹配[SLK18]。Dragonnet补充了这些方法。利用倾向分数的充分性是一种独特的方法,它可能与其他策略相结合。
非参数估计和机器学习。目标正则化涉及到将机器学习方法与半参数估计理论相结合的一系列工作。如上所述,该方法的主要灵感来自于目标最小损失估计[vR11]。Chernozhukov等[Che+17a;Che+17b]开发了“双机器学习”理论,表明如果某些估计方程得到满足,那么治疗估计将以参数(O(1/√n))速度收敛,即使条件结果和倾向模型收敛得更慢。Farrell等人[FLM18]证明神经网络以足够快的速度收敛,以调用双重机器学习结果。这为使用神经网络来模拟倾向评分和条件预期结果提供了理论依据。目标正则化是互补的:我们依赖于渐近结果的动机,并解决有限样本方法。
5实验
在实践中,Dragonnet和目标正则化是否改善了治疗效果评估?Dragonnet是一个端到端训练的大容量模型:它真的会丢弃与倾向分数无关的信息吗?tmaple已经提供了一种平衡渐近保证和有限样本性能的方法:目标正则化是否会在此基础上得到改善?
我们使用两种半合成基准测试工具对这些方法进行了实证研究。我们发现Dragonnet和目标正则化极大地提高了估计质量。此外,我们发现Dragonnet利用了倾向分数充分性,并且目标正则化改善了TMLE。
6讨论
未来的工作有几个方向。首先,尽管TMLE和目标正则化在概念上是相似的,但在我们的实验中,这两种方法有不同的性能。理解这种行为的根本原因可能有助于深入了解非参数估计方法的实际使用。与此相关,另一个有希望的方向是改编关于TMLE的成熟文献[例如,vR11;LG16]到更高级的目标正则化方法。例如,有许多TMLE方法用于估计被治疗者的平均治疗效果(ATT)。目前尚不清楚,如果有的话,其中哪一种将产生良好的目标正则化类型过程。一般来说,将这里的方法扩展到其他因果估计和中介分析是一个重要的问题。
关于dragonnet类型的架构还有一些有趣的问题。我们的直觉是,我们应该只使用与治疗分配和结果相关的协变量信息。我们的实证结果支持了这种直觉。然而,在其他情况下,这种直觉就不成立了。例如,在RCT中,协变量只影响结果,调整可以增加效力[SSI13]。这是因为调整可能会减少结果的有效方差,并且可以使用双稳健方法来确保一致性(治疗分配模型是众所周知的)。我们的激励直觉在我们考虑的大数据、未知倾向评分模型案例中得到了很好的支持。对所涉及的权衡和为因果调整选择协变量的实际指导方针有明确的阐述是很有价值的。作为一个例子,最近的论文使用了dragonnet类型的模型,使用黑盒嵌入方法进行因果调整[VWB19;VSB19]。它们实现了良好的估计精度,但仍不清楚可能做出哪些权衡。
在另一个方向上,我们的实验不支持在效果估计中常规使用数据分割。现有的方法通常将数据分割为训练集和测试集,并使用测试集上的预测来计算下游估计量。这种技术在理论上有一定的合理性[Che+17b](在K-fold变体中),但在我们的实验中显著降低了性能。我们注意到,在我们初步的(未报告的)K-fold数据分割实验中也是如此。更清楚地理解为什么以及什么时候数据拆分是合适的将会产生很大的影响。我们注意到Farrell等人[FLM18]证明了在使用神经网络时,数据重用不会使估计失效。
NN-Based的模型 dragonnet
基于神经网络的方法比较新,这里简单举一个例子——DragonNet。该方法主要工作是将propensity score估计和uplift score估计合并到一个网络实现。
首先,引述了可用倾向性得分代替X做ATE估计
然后,为了准确预测ATE而非关注到Y预测上,我们应尽可能使用 X中与 T 相关的部分特征。
其中一种方法就是首先训练一个网络用X预测T,然后移除最后一层并接上Y的预测,则可以实现将X中与T相关的部分提取出来(即倾向性得分 e ee 相关),并用于Y的预测。

如何更新参数
可以去看看源码里面的loss ,在loss里面设置t和1-t就可以实现 实验组时对t=1那头更新参数 t=0那头由于1-t=0就不会更新参数
传入[T,Y]进行损失函数的计算,根据模型的得到的函数,构建损失函数,一对多的训练方式。
使用一个label,可以对应多个任务,损失函数的不同而已,实现多任务的学习。
dragonnet的损失函数
def make_tarreg_loss(ratio=1.0, dragonnet_loss=dragonnet_loss_binarycross):
"""
Given a specified loss function, returns the same loss function with targeted regularization.
Args:
ratio (float): weight assigned to the targeted regularization loss component
dragonnet_loss (function): a loss function
Returns:
(function): loss function with targeted regularization, weighted by specified ratio
"""
def tarreg_ATE_unbounded_domain_loss(concat_true, concat_pred):
"""
Returns the loss function (specified in outer function) with targeted regularization.
"""
vanilla_loss = dragonnet_loss(concat_true, concat_pred)
y_true = concat_true[:, 0]
t_true = concat_true[:, 1]
y0_pred = concat_pred[:, 0]
y1_pred = concat_pred[:, 1]
t_pred = concat_pred[:, 2]
epsilons = concat_pred[:, 3]
t_pred = (t_pred + 0.01) / 1.02
# t_pred = tf.clip_by_value(t_pred,0.01, 0.99,name='t_pred')
y_pred = t_true * y1_pred + (1 - t_true) * y0_pred
h = t_true / t_pred - (1 - t_true) / (1 - t_pred)
y_pert = y_pred + epsilons * h
targeted_regularization = tf.reduce_sum(tf.square(y_true - y_pert))
# final
loss = vanilla_loss + ratio * targeted_regularization
return loss
return tarreg_ATE_unbounded_domain_loss
CausalML
dragon = DragonNet(neurons_per_layer=200, targeted_reg=True)
dragon_ite = dragon.fit_predict(X, treatment, y, return_components=False)
dragon_ate = dragon_ite.mean()

Dragonnet类
convert_pd_to_np
def convert_pd_to_np(*args):
output = [obj.to_numpy() if hasattr(obj, "to_numpy") else obj for obj in args]
return output if len(output) > 1 else output[0]如果你的数据只有一个特征,可以用reshape(-1,1)改变你的数据形状;或者如果你的数据只包含一个样本,可以使用reshape(1,-1)来改变。
只需要y,t 和pre(concat)进行loss预测
怎么多treatment:
- 如果要扩展成为多分类怎么改(直接拓展output header),需要修改loss
"""
This module implements the Dragonnet [1], which adapts the design and training of neural networks to improve
the quality of treatment effect estimates. The authors propose two adaptations:
- A new architecture, the Dragonnet, that exploits the sufficiency of the propensity score for estimation adjustment.
- A regularization procedure, targeted regularization, that induces a bias towards models that have non-parametrically
optimal asymptotic properties ‘out-of-the-box’. Studies on benchmark datasets for causal inference show these
adaptations outperform existing methods. Code is available at github.com/claudiashi57/dragonnet
**References**
[1] C. Shi, D. Blei, V. Veitch (2019).
| Adapting Neural Networks for the Estimation of Treatment Effects.
| https://arxiv.org/pdf/1906.02120.pdf
| https://github.com/claudiashi57/dragonnet
"""
import numpy as np
from tensorflow.keras import Input, Model
from tensorflow.keras.callbacks import EarlyStopping, ReduceLROnPlateau, TerminateOnNaN
from tensorflow.keras.layers import Dense, Concatenate
from tensorflow.keras.optimizers import SGD, Adam
from tensorflow.keras.regularizers import l2
from causalml.inference.tf.utils import (
dragonnet_loss_binarycross,
EpsilonLayer,
regression_loss,
binary_classification_loss,
treatment_accuracy,
track_epsilon,
make_tarreg_loss,
)
from causalml.inference.meta.utils import convert_pd_to_np
class DragonNet:
def __init__(
self,
neurons_per_layer=200,
targeted_reg=True,
ratio=1.0,
val_split=0.2,
batch_size=64,
epochs=30,
learning_rate=1e-3,
reg_l2=0.01,
loss_func=dragonnet_loss_binarycross,
verbose=True,
):
"""
Initializes a Dragonnet.
"""
self.neurons_per_layer = neurons_per_layer
self.targeted_reg = targeted_reg
self.ratio = ratio
self.val_split = val_split
self.batch_size = batch_size
self.epochs = epochs
self.learning_rate = learning_rate
self.loss_func = loss_func
self.reg_l2 = reg_l2
self.verbose = verbose
def make_dragonnet(self, input_dim):
"""
Neural net predictive model. The dragon has three heads.
Args:
input_dim (int): number of rows in input
Returns:
model (keras.models.Model): DragonNet model
"""
inputs = Input(shape=(input_dim,), name="input")
# representation
x = Dense(
units=self.neurons_per_layer,
activation="elu",
kernel_initializer="RandomNormal",
)(inputs)
x = Dense(
units=self.neurons_per_layer,
activation="elu",
kernel_initializer="RandomNormal",
)(x)
x = Dense(
units=self.neurons_per_layer,
activation="elu",
kernel_initializer="RandomNormal",
)(x)
t_predictions = Dense(units=1, activation="sigmoid")(x)
# HYPOTHESIS
y0_hidden = Dense(
units=int(self.neurons_per_layer / 2),
activation="elu",
kernel_regularizer=l2(self.reg_l2),
)(x)
y1_hidden = Dense(
units=int(self.neurons_per_layer / 2),
activation="elu",
kernel_regularizer=l2(self.reg_l2),
)(x)
# second layer
y0_hidden = Dense(
units=int(self.neurons_per_layer / 2),
activation="elu",
kernel_regularizer=l2(self.reg_l2),
)(y0_hidden)
y1_hidden = Dense(
units=int(self.neurons_per_layer / 2),
activation="elu",
kernel_regularizer=l2(self.reg_l2),
)(y1_hidden)
# third
y0_predictions = Dense(
units=1,
activation=None,
kernel_regularizer=l2(self.reg_l2),
name="y0_predictions",
)(y0_hidden)
y1_predictions = Dense(
units=1,
activation=None,
kernel_regularizer=l2(self.reg_l2),
name="y1_predictions",
)(y1_hidden)
dl = EpsilonLayer()
epsilons = dl(t_predictions, name="epsilon")
concat_pred = Concatenate(1)(
[y0_predictions, y1_predictions, t_predictions, epsilons]
)
model = Model(inputs=inputs, outputs=concat_pred)
return model
def fit(self, X, treatment, y, p=None):
"""
Fits the DragonNet model.
Args:
X (np.matrix or np.array or pd.Dataframe): a feature matrix
treatment (np.array or pd.Series): a treatment vector
y (np.array or pd.Series): an outcome vector
"""
X, treatment, y = convert_pd_to_np(X, treatment, y)
y = np.hstack((y.reshape(-1, 1), treatment.reshape(-1, 1)))
self.dragonnet = self.make_dragonnet(X.shape[1])
metrics = [
regression_loss,
binary_classification_loss,
treatment_accuracy,
track_epsilon,
]
if self.targeted_reg:
loss = make_tarreg_loss(ratio=self.ratio, dragonnet_loss=self.loss_func)
else:
loss = self.loss_func
self.dragonnet.compile(
optimizer=Adam(lr=self.learning_rate), loss=loss, metrics=metrics
)
adam_callbacks = [
TerminateOnNaN(),
EarlyStopping(monitor="val_loss", patience=2, min_delta=0.0),
ReduceLROnPlateau(
monitor="loss",
factor=0.5,
patience=5,
verbose=self.verbose,
mode="auto",
min_delta=1e-8,
cooldown=0,
min_lr=0,
),
]
self.dragonnet.fit(
X,
y,
callbacks=adam_callbacks,
validation_split=self.val_split,
epochs=self.epochs,
batch_size=self.batch_size,
verbose=self.verbose,
)
sgd_callbacks = [
TerminateOnNaN(),
EarlyStopping(monitor="val_loss", patience=40, min_delta=0.0),
ReduceLROnPlateau(
monitor="loss",
factor=0.5,
patience=5,
verbose=self.verbose,
mode="auto",
min_delta=0.0,
cooldown=0,
min_lr=0,
),
]
sgd_lr = 1e-5
momentum = 0.9
self.dragonnet.compile(
optimizer=SGD(lr=sgd_lr, momentum=momentum, nesterov=True),
loss=loss,
metrics=metrics,
)
self.dragonnet.fit(
X,
y,
callbacks=sgd_callbacks,
validation_split=self.val_split,
epochs=300,
batch_size=self.batch_size,
verbose=self.verbose,
)
def predict(self, X, treatment=None, y=None, p=None):
"""
Calls predict on fitted DragonNet.
Args:
X (np.matrix or np.array or pd.Dataframe): a feature matrix
Returns:
(np.array): a 2D array with shape (X.shape[0], 4),
where each row takes the form of (outcome do(t=0), outcome do(t=1), propensity, epsilon)
"""
return self.dragonnet.predict(X)
def predict_propensity(self, X):
"""
Predicts the individual propensity scores.
Args:
X (np.matrix or np.array or pd.Dataframe): a feature matrix
Returns:
(np.array): propensity score vector
"""
preds = self.predict(X)
return preds[:, 2]
def predict_tau(self, X):
"""
Predicts the individual treatment effect (tau / "ITE").
Args:
X (np.matrix or np.array or pd.Dataframe): a feature matrix
Returns:
(np.array): treatment effect vector
"""
preds = self.predict(X)
return (preds[:, 1] - preds[:, 0]).reshape(-1, 1)
def fit_predict(self, X, treatment, y, p=None, return_components=False):
"""
Fits the DragonNet model and then predicts.
Args:
X (np.matrix or np.array or pd.Dataframe): a feature matrix
treatment (np.array or pd.Series): a treatment vector
y (np.array or pd.Series): an outcome vector
return_components (bool, optional): whether to return
Returns:
(np.array): predictions based on return_components flag
if return_components=False (default), each row is treatment effect
if return_components=True, each row is (outcome do(t=0), outcome do(t=1), propensity, epsilon)
"""
self.fit(X, treatment, y)
return self.predict_tau(X)
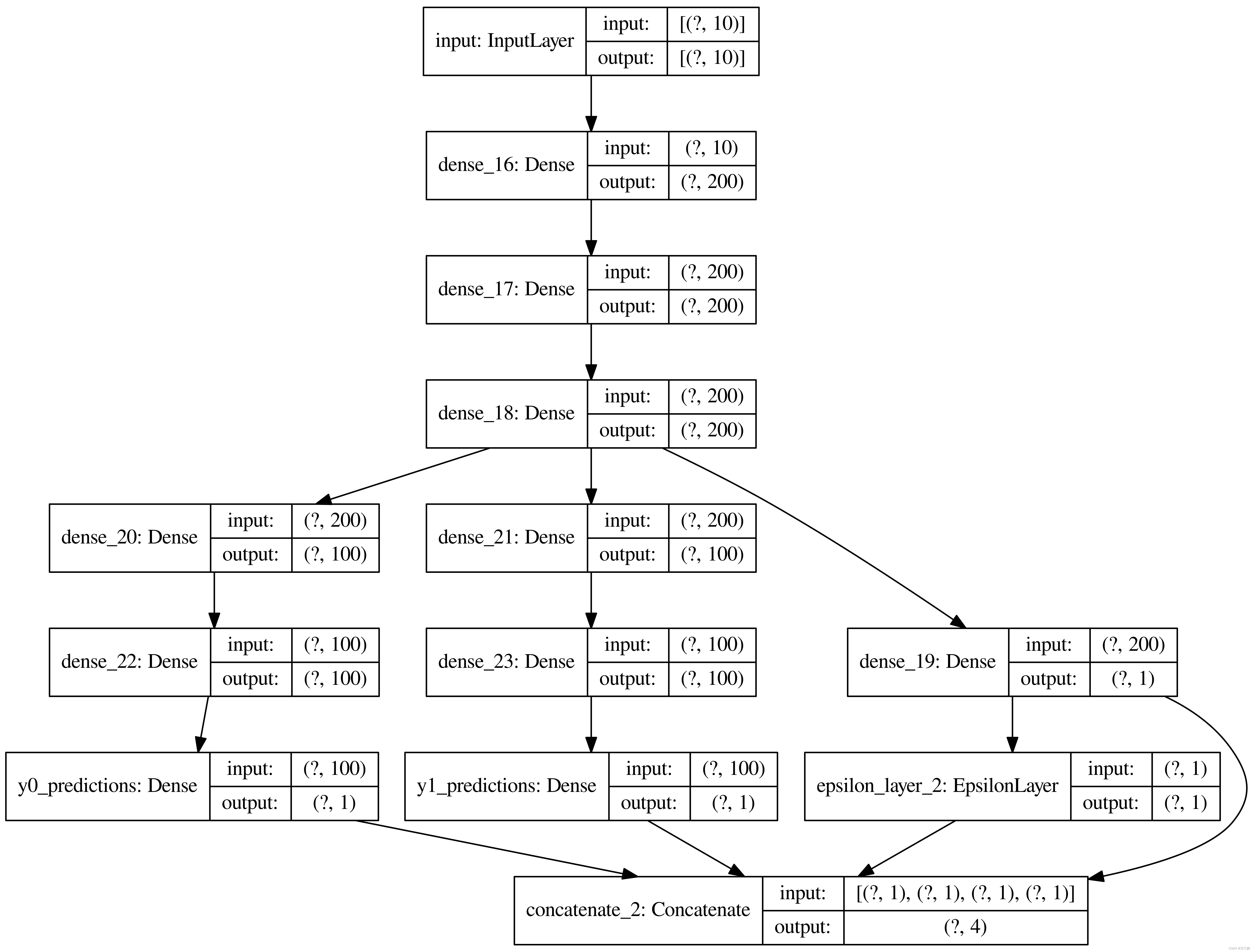
tf.keras.utils.plot_model(model, to_file='model_DCN.png',show_shapes=True,dpi=500)
论文代码
简介
该存储库包含“应用神经网络评估治疗效果”的软件和数据。
本文描述了使用神经网络估计观测数据因果效应的方法。高层次的想法是修改标准的神经网络设计和训练,以诱导对准确估计的偏见。
需求和设置
你需要安装tensorflow 1.13, sklearn, numpy 1.15, keras 2.2.4和pandas 0.24.1
数据
IHDP数据集基于一项随机实验,该实验调查了专家家访对未来认知评分的影响。它是通过npci包https://github.com/vdorie/npci生成的(设置A)为了方便,我们还在dat文件夹中上传了一部分模拟数据。这可以用于测试代码。
ACIC是由关联出生和婴儿死亡数据(LBIDD)衍生的半合成数据集的集合
以下是完整的数据集描述https://www.researchgate.net/publication/11523952_Infant_Mortality_Statistics_from_the_1999_Period_Linked_BirthInfant_Death_Data_Set
这是与比赛相关的GitHub回购https://github.com/IBM-HRL-MLHLS/IBM-Causal-Inference-Benchmarking-Framework/blob/master/data/LBIDD/scaling_params.csv
访问ACIC 2018比赛数据:请访问这里https://www.synapse.org/#!突触:syn11294478 / wiki / 486304
再现IHDP实验的神经网络训练
默认设置将允许您在目标正则化和默认模式下运行Dragonnet、TARNET和NEDnet
在这样做之前,你需要编辑run_ihdp.sh并更改以下内容:data_base_dir=你存储数据的位置output_base_dir=你想要的结果所在的位置
如果您只想运行其中一个框架,请删除run_ihdp.sh中的其余选项
为ACIC实验重现神经网络训练
和上面一样,不同的是你以。/experiment/run_acic.sh的形式运行from src代码
计算ATE
所有的估计器函数都在semi_parameter_estimate.ate中
再现文中表格:i)得到神经网络预测;Ii)更新ihdp_ate.py中的输出文件位置。make_table函数应该为每个框架生成平均绝对误差。
注:默认代码使用所有数据进行预测和估计。如果你想获得样本内或样本外错误:i)改变ihdp_main.py中的train_test_split标准;Ii)重新运行神经网络训练;Iii)使用相应的样本内数据和样本外数据运行ihdp_ate.py。
#!/usr/bin/env bash
# script should be run from 'src'
list=(
tarnet
nednet
dragonnet
)
folders=(
a
b
c
d
)
for i in ${list[@]}; do
for folder in ${folders[@]}; do
echo $i
echo $folder
python -m experiment.acic_main --data_base_dir /Users/claudiashi/data/ACIC_2018/\
--knob $i\
--folder $folder\
--output_base_dir /Users/claudiashi/ml/dragonnet/result/acic\
done
done
Footer
© 2023 GitHub, Inc.
Footer navigation
Terms
Privacy
Security
SSkip to content
Product
Solutions
Open Source
Pricing
Search
Sign in
Sign up
claudiashi57
/
dragonnet
Public
Code
Issues
2
Pull requests
Actions
Projects
Security
Insights
dragonnet/src/experiment/acic_main.py /
@claudiashi57
claudiashi57 adding table code
Latest commit 3168b7e on Dec 3, 2019
History
1 contributor
312 lines (243 sloc) 12.8 KB
from experiment.models import *
import os
import glob
import argparse
import tensorflow as tf
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
import keras.backend as K
from keras.optimizers import rmsprop, SGD, Adam
from keras.callbacks import EarlyStopping, ModelCheckpoint, TensorBoard, ReduceLROnPlateau, TerminateOnNaN
from experiment.data import load_treatment_and_outcome, load_and_format_covariates
import numpy as np
def _split_output(yt_hat, t, y, y_scaler, x, index):
q_t0 = y_scaler.inverse_transform(yt_hat[:, 0].copy())
q_t1 = y_scaler.inverse_transform(yt_hat[:, 1].copy())
g = yt_hat[:, 2].copy()
if yt_hat.shape[1] == 4:
eps = yt_hat[:, 3][0]
else:
eps = np.zeros_like(yt_hat[:, 2])
y = y_scaler.inverse_transform(y.copy())
var = "average propensity for treated: {} and untreated: {}".format(g[t.squeeze() == 1.].mean(),
g[t.squeeze() == 0.].mean())
print(var)
return {'q_t0': q_t0, 'q_t1': q_t1, 'g': g, 't': t, 'y': y, 'x': x, 'index': index, 'eps': eps}
def train_and_predict_dragons(t, y_unscaled, x, targeted_regularization=True, output_dir='',
knob_loss=dragonnet_loss_binarycross, ratio=1., dragon='', val_split=0.2, batch_size=512):
verbose = 0
y_scaler = StandardScaler().fit(y_unscaled)
y = y_scaler.transform(y_unscaled)
train_outputs = []
test_outputs = []
runs = 25
for i in range(runs):
if dragon == 'tarnet':
dragonnet = make_tarnet(x.shape[1], 0.01)
elif dragon == 'dragonnet':
dragonnet = make_dragonnet(x.shape[1], 0.01)
metrics = [regression_loss, binary_classification_loss, treatment_accuracy, track_epsilon]
if targeted_regularization:
loss = make_tarreg_loss(ratio=ratio, dragonnet_loss=knob_loss)
else:
loss = knob_loss
# reproducing the acic experiment
tf.random.set_random_seed(i)
np.random.seed(i)
train_index, test_index = train_test_split(np.arange(x.shape[0]), test_size=0, random_state=1)
test_index = train_index
x_train, x_test = x[train_index], x[test_index]
y_train, y_test = y[train_index], y[test_index]
t_train, t_test = t[train_index], t[test_index]
yt_train = np.concatenate([y_train, t_train], 1)
import time;
start_time = time.time()
dragonnet.compile(
optimizer=Adam(lr=1e-3),
loss=loss, metrics=metrics)
adam_callbacks = [
TerminateOnNaN(),
EarlyStopping(monitor='val_loss', patience=2, min_delta=0.),
ReduceLROnPlateau(monitor='loss', factor=0.5, patience=5, verbose=verbose, mode='auto',
min_delta=1e-8, cooldown=0, min_lr=0)
]
dragonnet.fit(x_train, yt_train, callbacks=adam_callbacks,
validation_split=val_split,
epochs=100,
batch_size=batch_size, verbose=verbose)
sgd_callbacks = [
TerminateOnNaN(),
EarlyStopping(monitor='val_loss', patience=40, min_delta=0.),
ReduceLROnPlateau(monitor='loss', factor=0.5, patience=5, verbose=verbose, mode='auto',
min_delta=0., cooldown=0, min_lr=0)
]
# should pick something better!
sgd_lr = 1e-5
momentum = 0.9
dragonnet.compile(optimizer=SGD(lr=sgd_lr, momentum=momentum, nesterov=True), loss=loss,
metrics=metrics)
dragonnet.fit(x_train, yt_train, callbacks=sgd_callbacks,
validation_split=val_split,
epochs=300,
batch_size=batch_size, verbose=verbose)
elapsed_time = time.time() - start_time
print("***************************** elapsed_time is: ", elapsed_time)
yt_hat_test = dragonnet.predict(x_test)
yt_hat_train = dragonnet.predict(x_train)
test_outputs += [_split_output(yt_hat_test, t_test, y_test, y_scaler, x_test, test_index)]
train_outputs += [_split_output(yt_hat_train, t_train, y_train, y_scaler, x_train, train_index)]
K.clear_session()
return test_outputs, train_outputs
def train_and_predict_ned(t, y_unscaled, x, targeted_regularization=True, output_dir='',
knob_loss=dragonnet_loss_binarycross, ratio=1., val_split=0.2, batch_size=512):
verbose = 0
y_scaler = StandardScaler().fit(y_unscaled)
y = y_scaler.transform(y_unscaled)
train_outputs = []
test_outputs = []
runs = 25
for i in range(runs):
nednet = make_ned(x.shape[1], 0.01)
metrics_ned = [ned_loss]
metrics_cut = [regression_loss]
tf.random.set_random_seed(i)
np.random.seed(i)
train_index, test_index = train_test_split(np.arange(x.shape[0]), test_size=0.)
test_index = train_index
x_train, x_test = x[train_index], x[test_index]
y_train, y_test = y[train_index], y[test_index]
t_train, t_test = t[train_index], t[test_index]
yt_train = np.concatenate([y_train, t_train], 1)
import time;
start_time = time.time()
nednet.compile(
optimizer=Adam(lr=1e-3),
loss=ned_loss, metrics=metrics_ned)
adam_callbacks = [
TerminateOnNaN(),
EarlyStopping(monitor='val_loss', patience=2, min_delta=0.),
ReduceLROnPlateau(monitor='loss', factor=0.5, patience=5, verbose=verbose, mode='auto',
min_delta=1e-8, cooldown=0, min_lr=0)
]
nednet.fit(x_train, yt_train, callbacks=adam_callbacks,
validation_split=val_split,
epochs=100,
batch_size=batch_size, verbose=verbose)
sgd_callbacks = [
TerminateOnNaN(),
EarlyStopping(monitor='val_loss', patience=40, min_delta=0.),
ReduceLROnPlateau(monitor='loss', factor=0.5, patience=5, verbose=verbose, mode='auto',
min_delta=0., cooldown=0, min_lr=0)]
sgd_lr = 1e-5
momentum = 0.9
nednet.compile(optimizer=SGD(lr=sgd_lr, momentum=momentum, nesterov=True), loss=ned_loss,
metrics=metrics_ned)
# print(nednet.summary())
nednet.fit(x_train, yt_train, callbacks=sgd_callbacks,
validation_split=val_split,
epochs=300,
batch_size=batch_size, verbose=verbose)
t_hat_test = nednet.predict(x_test)[:, 1]
t_hat_train = nednet.predict(x_train)[:, 1]
cut_net = post_cut(nednet, x.shape[1], 0.01)
cut_net.compile(
optimizer=Adam(lr=1e-3),
loss=dead_loss, metrics=metrics_cut)
adam_callbacks = [
TerminateOnNaN(),
EarlyStopping(monitor='val_loss', patience=2, min_delta=0.),
ReduceLROnPlateau(monitor='loss', factor=0.5, patience=5, verbose=verbose, mode='auto',
min_delta=1e-8, cooldown=0, min_lr=0)
]
cut_net.fit(x_train, yt_train, callbacks=adam_callbacks,
validation_split=val_split,
epochs=100,
batch_size=batch_size, verbose=verbose)
sgd_callbacks = [
TerminateOnNaN(),
EarlyStopping(monitor='val_loss', patience=40, min_delta=0.),
ReduceLROnPlateau(monitor='loss', factor=0.5, patience=5, verbose=verbose, mode='auto',
min_delta=0., cooldown=0, min_lr=0)]
sgd_lr = 1e-5
momentum = 0.9
cut_net.compile(optimizer=SGD(lr=sgd_lr, momentum=momentum, nesterov=True), loss=dead_loss,
metrics=metrics_cut)
cut_net.fit(x_train, yt_train, callbacks=sgd_callbacks,
validation_split=val_split,
epochs=300,
batch_size=batch_size, verbose=verbose)
y_hat_test = cut_net.predict(x_test)
y_hat_train = cut_net.predict(x_train)
yt_hat_test = np.concatenate([y_hat_test, t_hat_test.reshape(-1, 1)], 1)
yt_hat_train = np.concatenate([y_hat_train, t_hat_train.reshape(-1, 1)], 1)
test_outputs += [_split_output(yt_hat_test, t_test, y_test, y_scaler, x_test, test_index)]
train_outputs += [_split_output(yt_hat_train, t_train, y_train, y_scaler, x_train, train_index)]
K.clear_session()
return test_outputs, train_outputs
def run_acic(data_base_dir='../../data/', output_dir='../../dragonnet/',
knob_loss=dragonnet_loss_binarycross,
ratio=1., dragon='', folder='a'):
print("************************************** the output directory is: ", output_dir)
covariate_csv = os.path.join(data_base_dir, 'x.csv')
x_raw = load_and_format_covariates(covariate_csv)
simulation_dir = os.path.join(data_base_dir, folder)
simulation_files = sorted(glob.glob("{}/*".format(simulation_dir)))
for idx, simulation_file in enumerate(simulation_files):
cf_suffix = "_cf"
file_extension = ".csv"
if simulation_file.endswith(cf_suffix + file_extension):
continue
ufid = os.path.basename(simulation_file)[:-4]
t, y, sample_id, x = load_treatment_and_outcome(x_raw, simulation_file)
ufid_output_dir = os.path.join(output_dir, str(ufid))
os.makedirs(ufid_output_dir, exist_ok=True)
np.savez_compressed(os.path.join(ufid_output_dir, "simulation_outputs.npz"),
t=t, y=y, sample_id=sample_id, x=x)
for is_targeted_regularization in [True, False]:
print("Is targeted regularization: {}".format(is_targeted_regularization))
if dragon == 'nednet':
test_outputs, train_outputs = train_and_predict_ned(t, y, x,
targeted_regularization=is_targeted_regularization,
output_dir=ufid_output_dir,
knob_loss=knob_loss, ratio=ratio,
val_split=0.2, batch_size=512)
else:
test_outputs, train_outputs = train_and_predict_dragons(t, y, x,
targeted_regularization=is_targeted_regularization,
output_dir=ufid_output_dir,
knob_loss=knob_loss, ratio=ratio, dragon=dragon,
val_split=0.2, batch_size=512)
if is_targeted_regularization:
train_output_dir = os.path.join(ufid_output_dir, "targeted_regularization")
else:
train_output_dir = os.path.join(ufid_output_dir, "baseline")
os.makedirs(train_output_dir, exist_ok=True)
for num, output in enumerate(test_outputs):
np.savez_compressed(os.path.join(train_output_dir, "{}_replication_test.npz".format(num)),
**output)
for num, output in enumerate(train_outputs):
np.savez_compressed(os.path.join(train_output_dir, "{}_replication_train.npz".format(num)),
**output)
def turn_knob(data_base_dir='/Users/claudiashi/data/test/', knob='dragonnet', folder='a',
output_base_dir=' /Users/claudiashi/result/experiment/'):
output_dir = os.path.join(output_base_dir, knob)
if knob == 'dragonnet':
run_acic(data_base_dir=data_base_dir, output_dir=output_dir, folder=folder,
knob_loss=dragonnet_loss_binarycross, dragon='dragonnet')
if knob == 'tarnet':
run_acic(data_base_dir=data_base_dir, output_dir=output_dir, folder=folder,
knob_loss=dragonnet_loss_binarycross, dragon='tarnet')
if knob == 'nednet':
run_acic(data_base_dir=data_base_dir, output_dir=output_dir, folder=folder,
knob_loss=dragonnet_loss_binarycross, dragon='nednet')
def main():
parser = argparse.ArgumentParser()
parser.add_argument('--data_base_dir', type=str, help="path to directory LBIDD")
parser.add_argument('--knob', type=str, default='dragonnet',
help="dragonnet or tarnet or nednet")
parser.add_argument('--folder', type=str, help='which datasub directory')
parser.add_argument('--output_base_dir', type=str, help="directory to save the output")
args = parser.parse_args()
turn_knob(args.data_base_dir, args.knob, args.folder, args.output_base_dir)
if __name__ == '__main__':
main()
Footer
© 2023 GitHub, Inc.
Footer navigation
Terms
Privacy
Security
Status
Docs
Contact GitHub
Pricing
API
Training
Blog
About
def make_dragonnet(input_dim, reg_l2):
"""
Neural net predictive model. The dragon has three heads.
:param input_dim:
:param reg:
:return:
"""
t_l1 = 0.
t_l2 = reg_l2
inputs = Input(shape=(input_dim,), name='input')
# representation
x = Dense(units=200, activation='elu', kernel_initializer='RandomNormal')(inputs)
x = Dense(units=200, activation='elu', kernel_initializer='RandomNormal')(x)
x = Dense(units=200, activation='elu', kernel_initializer='RandomNormal')(x)
t_predictions = Dense(units=1, activation='sigmoid')(x)
# HYPOTHESIS
y0_hidden = Dense(units=100, activation='elu', kernel_regularizer=regularizers.l2(reg_l2))(x)
y1_hidden = Dense(units=100, activation='elu', kernel_regularizer=regularizers.l2(reg_l2))(x)
# second layer
y0_hidden = Dense(units=100, activation='elu', kernel_regularizer=regularizers.l2(reg_l2))(y0_hidden)
y1_hidden = Dense(units=100, activation='elu', kernel_regularizer=regularizers.l2(reg_l2))(y1_hidden)
# third
y0_predictions = Dense(units=1, activation=None, kernel_regularizer=regularizers.l2(reg_l2), name='y0_predictions')(
y0_hidden)
y1_predictions = Dense(units=1, activation=None, kernel_regularizer=regularizers.l2(reg_l2), name='y1_predictions')(
y1_hidden)
dl = EpsilonLayer()
epsilons = dl(t_predictions, name='epsilon')
# logging.info(epsilons)
concat_pred = Concatenate(1)([y0_predictions, y1_predictions, t_predictions, epsilons])
model = Model(inputs=inputs, outputs=concat_pred)
return model
for i in range(runs):
if dragon == 'tarnet':
dragonnet = make_tarnet(x.shape[1], 0.01)
elif dragon == 'dragonnet':
dragonnet = make_dragonnet(x.shape[1], 0.01)
metrics = [regression_loss, binary_classification_loss, treatment_accuracy, track_epsilon]
if targeted_regularization:
loss = make_tarreg_loss(ratio=ratio, dragonnet_loss=knob_loss)
else:
loss = knob_loss
# reproducing the acic experiment
tf.random.set_random_seed(i)
np.random.seed(i)
train_index, test_index = train_test_split(np.arange(x.shape[0]), test_size=0, random_state=1)
test_index = train_index
x_train, x_test = x[train_index], x[test_index]
y_train, y_test = y[train_index], y[test_index]
t_train, t_test = t[train_index], t[test_index]
yt_train = np.concatenate([y_train, t_train], 1)
import time;
start_time = time.time()
dragonnet.compile(
optimizer=Adam(lr=1e-3),
loss=loss, metrics=metrics)
adam_callbacks = [
TerminateOnNaN(),
EarlyStopping(monitor='val_loss', patience=2, min_delta=0.),
ReduceLROnPlateau(monitor='loss', factor=0.5, patience=5, verbose=verbose, mode='auto',
min_delta=1e-8, cooldown=0, min_lr=0)
]
dragonnet.fit(x_train, yt_train, callbacks=adam_callbacks,
validation_split=val_split,
epochs=100,
batch_size=batch_size, verbose=verbose)
sgd_callbacks = [
TerminateOnNaN(),
EarlyStopping(monitor='val_loss', patience=40, min_delta=0.),
ReduceLROnPlateau(monitor='loss', factor=0.5, patience=5, verbose=verbose, mode='auto',
min_delta=0., cooldown=0, min_lr=0)
]
# should pick something better!
sgd_lr = 1e-5
momentum = 0.9
dragonnet.compile(optimizer=SGD(lr=sgd_lr, momentum=momentum, nesterov=True), loss=loss,
metrics=metrics)
dragonnet.fit(x_train, yt_train, callbacks=sgd_callbacks,
validation_split=val_split,
epochs=300,
batch_size=batch_size, verbose=verbose)
elapsed_time = time.time() - start_time
print("***************************** elapsed_time is: ", elapsed_time)
yt_hat_test = dragonnet.predict(x_test)
yt_hat_train = dragonnet.predict(x_train)
test_outputs += [_split_output(yt_hat_test, t_test, y_test, y_scaler, x_test, test_index)]
train_outputs += [_split_output(yt_hat_train, t_train, y_train, y_scaler, x_train, train_index)]
K.clear_session()参考:
- [Dragonet] Adapting Neural Network for the Estimation of Treatment Effects - 知乎
- 因果推断笔记 | Dragonnet - 知乎
- https://mattzheng.blog.csdn.net/article/details/120283264





![BUUCTF-[RoarCTF2019]polyre](https://img-blog.csdnimg.cn/037b4c7295a5472fab8d4b1bcbb4df30.png)