本篇文章聊聊如何低成本快速上手使用 Meta(Facebook)的开源模型 LLaMA。
写在前面
在积累点赞,兑现朋友提供的显卡算力之前,我们先来玩玩“小号的”大模型吧。我相信 2023 年了,应该不需要再赘述如何使用 Docker 干净又卫生的调用显卡来跑 AI 程序了。这个模式已经在各种互联网或企业里运行了多年啦。
本文容器方案基于 Nvidia 23.01 基础镜像,PyTorch 1.14 版本,CUDA 12.0,目前应该是显卡性能发挥的最佳基础容器,尤其是 40 系。
NVIDIA Release 23.01 (build 52269074)
PyTorch Version 1.14.0a0+44dac51
# nvcc -V
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2023 NVIDIA Corporation
Built on Fri_Jan__6_16:45:21_PST_2023
Cuda compilation tools, release 12.0, V12.0.140
Build cuda_12.0.r12.0/compiler.32267302_0
想要快速玩起来 LLaMA 分三步:
- 下载模型文件
- 使用 Docker 准备运行环境
- 运行它,开玩
我们先来进行第一步操作,下载模型文件。
下载 LLaMA 模型文件
网上随处可见的下载地址就不再赘述(比如官方项目的 PR #73),将模型(比如 7B 或者 13B 版本)下载好之后,整理目录结构,确保目录结构和下面保持一致。
─ models
├── 7B
│ ├── consolidated.00.pth
│ └── params.json
└── tokenizer.model
当然,别忘记针对你下载的模型进行完整性校验,以 7B 版本模型为例:
cd modles/7B
echo "6efc8dab194ab59e49cd24be5574d85e consolidated.00.pth" | md5sum --check -
echo "7596560e011154b90eb51a1b15739763 params.json" | md5sum --check -
如果你下载的模型文件是完整的,那么将会看的下面的输出结果:
consolidated.00.pth: OK
params.json: OK
使用 LLaMA Docker 游乐场项目
牺牲午饭时间写了一个小小的开源项目,包含官方原版和社区省显存两个方案。项目地址:soulteary/llama-docker-playground
首先,随便找一个合适的目录,使用 git clone 或者下载 Zip 压缩包的方式,把“LLaMA 游乐场”项目的代码下载到本地。
git clone https://github.com/soulteary/llama-docker-playground.git
# or
curl -sL -o llama.zip https://github.com/soulteary/llama-docker-playground/archive/refs/heads/main.zip
然后,我们使用 Docker 来基于 Nvidia 原厂最新的 PyTorch 镜像,来完成基础运行环境的构建,相比于我们直接从 DockerHub 拉制作好的镜像,自行构建将能节约大量时间。
如果你有 20GB 以上的大显存,可以考虑使用下面的命令。
docker build -t soulteary/llama:llama . -f docker/Dockerfile.llama
或者,你的显存没有那么大,显存在 10GB 左右,可以考虑使用下面的命令。
docker build -t soulteary/llama:pyllama . -f docker/Dockerfile.pyllama
当我们完成了镜像构建之后,就能够开始玩了。
使用 Docker 快速运行 LLaMA 模型
我们来到模型文件 models 目录所在的目录,然后使用下面的命令,就能够启动 LLaMA 的原版模型项目啦:
docker run --gpus all --ipc=host --ulimit memlock=-1 -v `pwd`/models:/app/models -p 7860:7860 -it --rm soulteary/llama:llama
如果你的显卡显存没有 20GB,刚刚构建的也是 pyllama 版本的镜像,那么那么可以试试使用下面的命令,快速启动“优化过的”程序:
docker run --gpus all --ipc=host --ulimit memlock=-1 -v `pwd`/models:/llama_data -p 7860:7860 -it --rm soulteary/llama:pyllama
不论是使用哪一个镜像,当我们执行命令之后,程序都将自动装载模型到显存,并且自动一个 Web UI 程序。执行命令后,输出将类似下面这样:
=============
== PyTorch ==
=============
NVIDIA Release 23.01 (build 52269074)
PyTorch Version 1.14.0a0+44dac51
Container image Copyright (c) 2023, NVIDIA CORPORATION & AFFILIATES. All rights reserved.
Copyright (c) 2014-2023 Facebook Inc.
Copyright (c) 2011-2014 Idiap Research Institute (Ronan Collobert)
Copyright (c) 2012-2014 Deepmind Technologies (Koray Kavukcuoglu)
Copyright (c) 2011-2012 NEC Laboratories America (Koray Kavukcuoglu)
Copyright (c) 2011-2013 NYU (Clement Farabet)
Copyright (c) 2006-2010 NEC Laboratories America (Ronan Collobert, Leon Bottou, Iain Melvin, Jason Weston)
Copyright (c) 2006 Idiap Research Institute (Samy Bengio)
Copyright (c) 2001-2004 Idiap Research Institute (Ronan Collobert, Samy Bengio, Johnny Mariethoz)
Copyright (c) 2015 Google Inc.
Copyright (c) 2015 Yangqing Jia
Copyright (c) 2013-2016 The Caffe contributors
All rights reserved.
Various files include modifications (c) NVIDIA CORPORATION & AFFILIATES. All rights reserved.
This container image and its contents are governed by the NVIDIA Deep Learning Container License.
By pulling and using the container, you accept the terms and conditions of this license:
https://developer.nvidia.com/ngc/nvidia-deep-learning-container-license
> initializing model parallel with size 1
> initializing ddp with size 1
> initializing pipeline with size 1
Loading
Loaded in 5.49 seconds
Running on local URL: http://0.0.0.0:7860
To create a public link, set `share=True` in `launch()`.
模型运行起来之后,我们通过浏览器访问容器所在机器的 IP:7860 地址,就能够开始玩 LLaMA 啦。如果你是在本机运行程序,直接在浏览器中访问 http://localhost:7860 就能够看到下面的界面啦。
我们在左边的文本框中输入问题,点击提交按钮,模型在“思考”之后,就会给你“编出”它认为合适的答案。
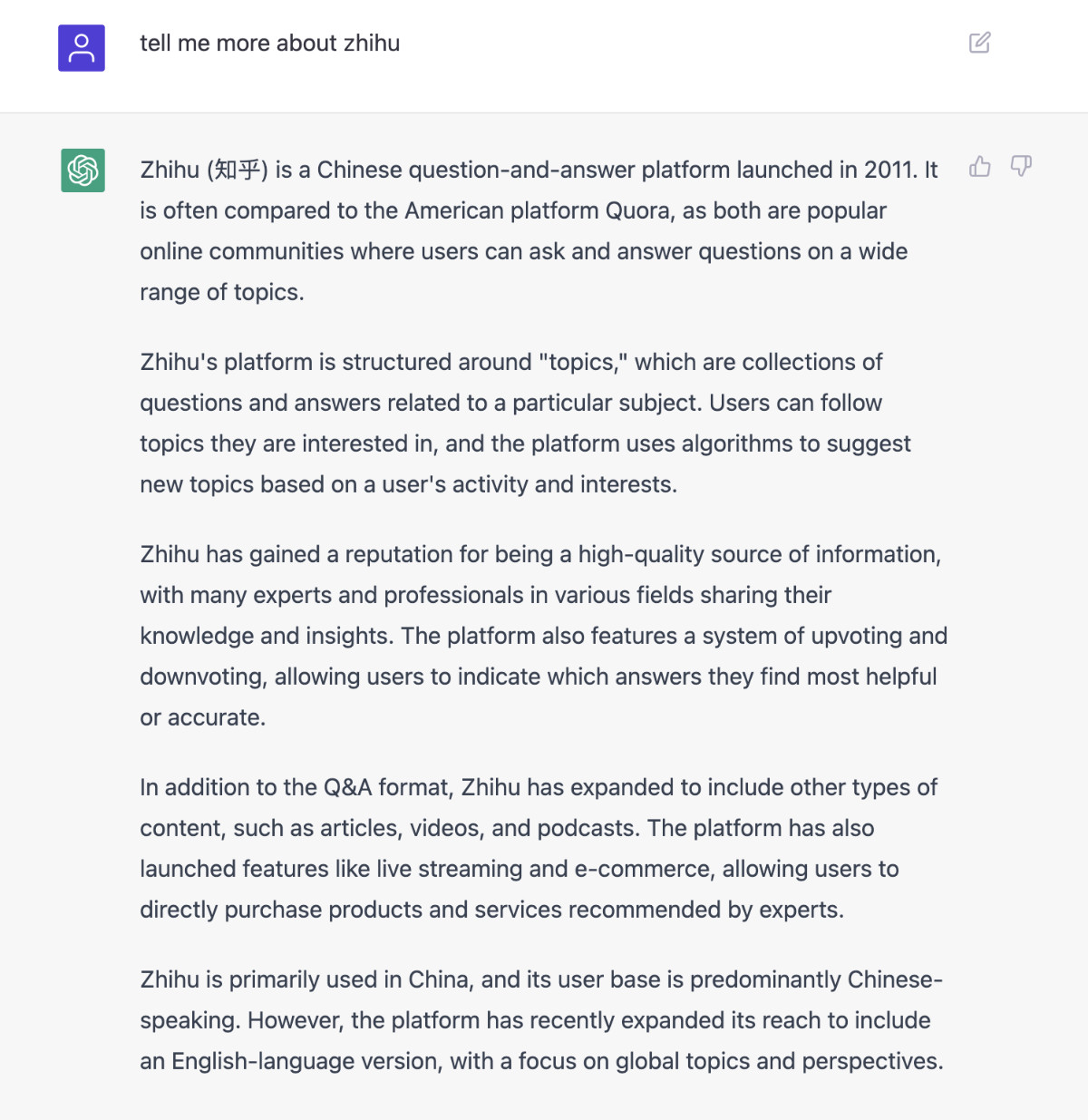
比如,我们提一个简单的问题“tell me more about zhihu”(告诉我关于知乎的事情),它的回答如下图:
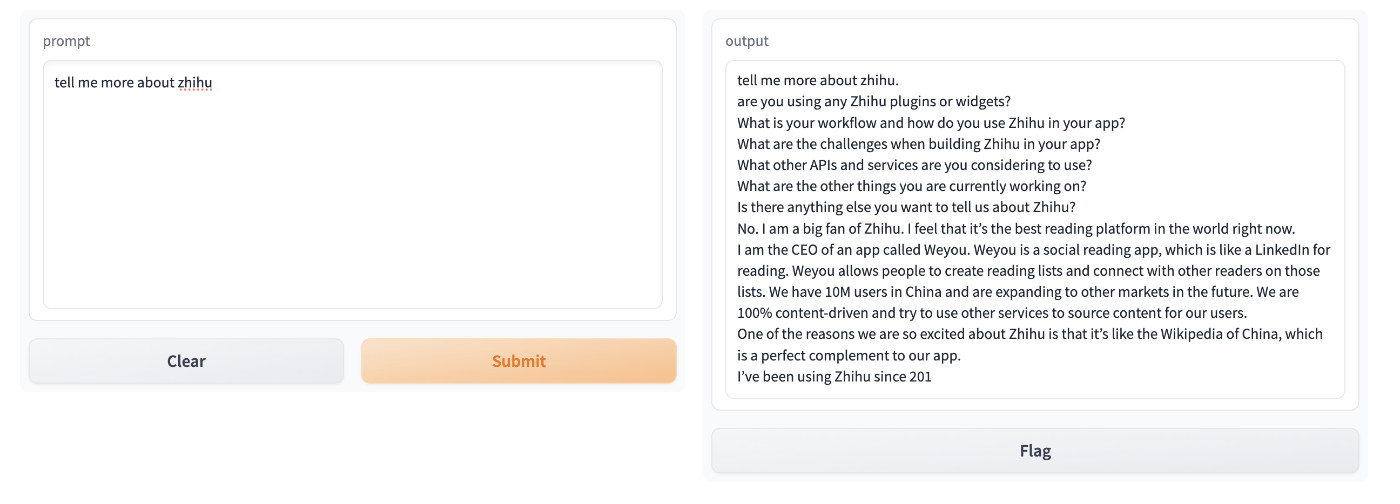
上面的回答来自原版的程序,如果我们使用 pyllama 来测试,结果会类似下面这样:
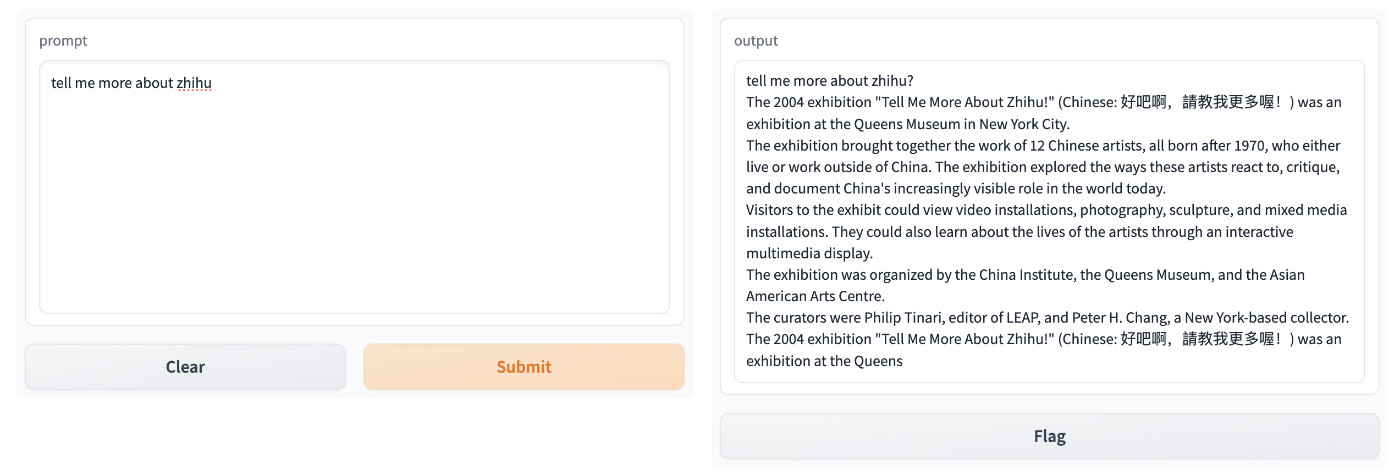
不论哪一个,看起来都不太靠谱,尤其是相比 ChatGPT。并且,如果想处理中文,你可能还需要再接入新的模型做翻译或者接入 API。
不过,我们目前使用的只是小参数量的模型,也没有进行 Prompt 优化,如果能够使用最大参数量的模型,并且在 Prompt 上叠加一些优化,最后结合一些量化模型的手段,或许“便宜大碗、效果不错”的普惠大模型就有啦。
其他:模型使用的显卡资源状况
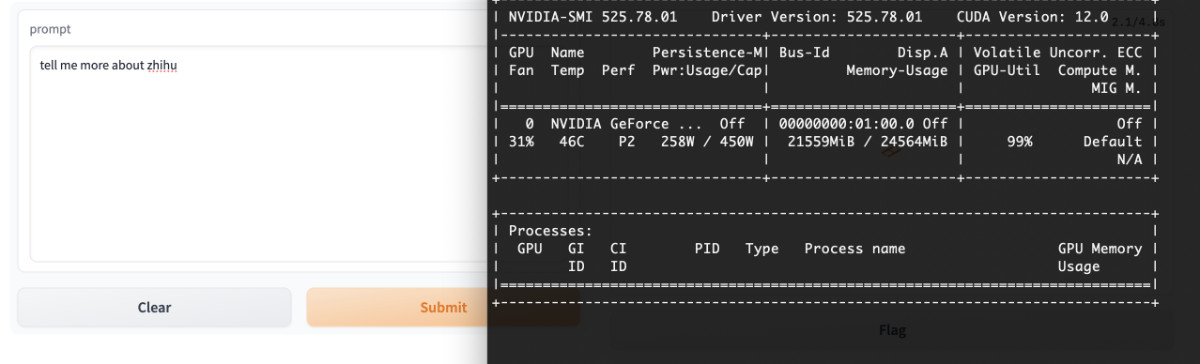
很多同学关注模型到底需要多少显存才能跑起来,我这里贴出我的实际测试结果。显存占用都是在程序运行过程中记录,所以不会存在“数值虚低”的情况。
原版程序将消耗 21G 左右的显存。
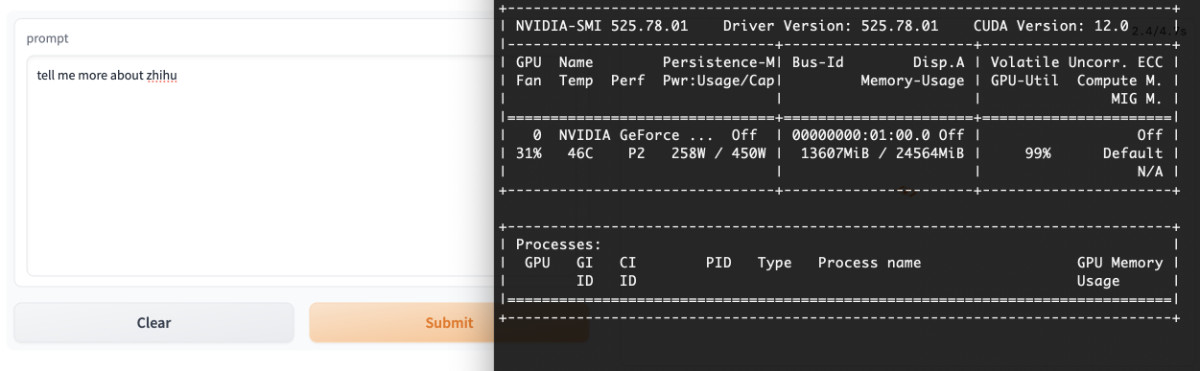
社区 pyllama 程序将消耗 13G 左右的显存,不过应该还可以继续顺着作者思路继续优化,作者加油啊。
最后
在我们多数人都熟悉和使用 ChatGPT 三个月之后,我们对于模型的效果的好坏的判断,基本都能“一眼看出”。
但是,在我们“一眼看不到”的地方,可能正孕育着新的风暴,并且在使用真实的“开源”的方式。
不妨侧耳倾听,风暴来临前的声音。
–EOF
我们有一个小小的折腾群,里面聚集了一些喜欢折腾的小伙伴。
在不发广告的情况下,我们在里面会一起聊聊软硬件、HomeLab、编程上的一些问题,也会在群里不定期的分享一些技术资料。
喜欢折腾的小伙伴,欢迎阅读下面的内容,扫码添加好友。
关于“交友”的一些建议和看法
添加好友时,请备注实名和公司或学校、注明来源和目的,否则不会通过审核。
关于折腾群入群的那些事
本文使用「署名 4.0 国际 (CC BY 4.0)」许可协议,欢迎转载、或重新修改使用,但需要注明来源。 署名 4.0 国际 (CC BY 4.0)
本文作者: 苏洋
创建时间: 2023年03月09日
统计字数: 4593字
阅读时间: 10分钟阅读
本文链接: https://soulteary.com/2023/03/09/quick-start-llama-model-created-by-meta-research.html