IOC
前面体验了spring,不过其运用了IOC,至于IOC( Inverse Of Controll—控制反转 )
看一下百度百科解释:
控制反转(Inversion of Control,缩写为IoC),是面向对象编程中的一种设计原则,可以用来减低计算机代码之间的耦合度。其中最常见的方式叫做依赖注入(Dependency Injection,简称DI),还有一种方式叫“依赖查找”(Dependency Lookup)。通过控制反转,对象在被创建的时候,由一个调控系统内所有对象的外界实体将其所依赖的对象的引用传递给它。也可以说,依赖被注入到对象中。
从这个里面可以看出三个重要的词汇:控制,反转,依赖注入。
-
控制:既然提到控制,那么就是谁控制谁,也就行前提需要有两个对象,不然哪里来的控制。
一般创建对象的时候,通过new来创建一个对象。但是现在又有个问题了,IOC既然是控制,那么其如何生成对象呢?既然是解耦减少new来创建对象。前面对于例子初体验的时候,看出控制对象的时候没有通过new来创建对象。
-
反转: 既然叫做反转,那自然就有转了,不然就没有反转一说了。当然没有正转这个词汇,简单说就是一般用法就是正转。
比如一个对象控制另一个对象的时候,会在这个类中创建这个被调用的对象。
class A{ } class B{ public static void main(String[] args) { // 所谓的正转调用 因为需要调用A的方法所以需要创建一个A的对象 A a=new A(); } }而反转却没有看见通过new来创建对象。详情看初体验的例子
可以看出没有通过new来创建对象,那么如何创建对象呢?肯定是Spring帮我们创建了对象。其通过配置文件就创建了对象,而这个帮忙创建对象的好人就是被称为IOC容器。而IOC容器帮我们查找以及注入依赖对象,而作为操作者的对象只能被动的接受依赖对象。 所以可以看出不是手动去创建对象,而根据配置文件Spring通过IOC容器进行依赖注入,然后对对象进行创建,销毁。所以是说控制对象生存周期的不再是引用它的对象,而是 Spring。对于某个具体的对象而言,以前是它控制其他对象,现在是所有对象都被 Spring 控制,所以这叫控制反转。
-
依赖注入(DI):依赖注入和IOC两者其实可以说IOC是一种编程思维,而依赖注入是具体实现这个编程思维的方式。
其实最常用的两种注入方法是:set注入,构造注入,当然这个在spring中听过xml或者注解进行体现。
通过依赖注入机制 只需要通过简单的配置,而无需任何代码就可指定目标需要的资源,完成自身的业务逻辑,而不需要关心具体的资源来自何处,由谁实现。
当然组件之间依赖关系由容器在运行期决定,形象的说,即由容器动态的将某个依赖关系注入到组件之中。
当然依赖注入的目的并非为软件系统带来更多功能,而是为了提升组件重用的频率,并为系统搭建一个灵活、可扩展的平台。
其实在Spring中的IOC容器使用了工厂模式,以及反射,如果没有反射也就没有必要进行配置信息。
现在有两个问题了,Spring中是通过那个类进行处理这个配置信息的,毕竟配置信息可以是xml或者注解,而这个类必然要进行判断之后才能处理的。
创建bean容器
Spring的IOC容器就是IOC思想的一种实现,而在IOC容器(IOC容器存放着bean 所以被叫做 Spring bean容器)的创建,需要看一个接口BeanFactory,这个是创建Spring bean容器的根接口,这个不是我说的而是源码:

但是BeanFactory这个是Spring内部使用的接口,面向Spring本身,不是给开发人员用的。一般使用其子接口ApplicationContext,而这个接口在前面例子中很多体现,现在可以看下其关系:

常用的ApplicationContext实现类或接口:
| 类/接口 | 描述 |
|---|---|
| ClassPathXmlApplicationContext | 通过读取类路径下的XML格式配置文件创建的IOC容器对象 |
| FileSystemXmlApplicationContext | 通过文件系统路径下XML格式配置文件创建的IOC容器对象 |
| ConfigurableApplicationContext | ApplicationContext的子接口,包含了一些扩展方法比如close(),refresh等。 |
| AnnotationConfigApplicationContext | 完全注解的时候,用来加载带有配置注解的类。 |
| WebApplicationContext | 为web应用准备,是基于web环境开发创建IOC容器对象,并将对象存入ServletContext域中。 |
得到bean信息
其实这个需要一个接口:BeanDefinition (Definition的英文意思是解释,释义。 不得说母语英语真是友好,看名知其意,还是需要学英语的。)
然后看一下其源码是如果解释的:

翻译如下:
BeanDefinition 描述了一个实例信息,其拥有的属性只,构造方法中带有的参数以及具体实现去其它更多信息。
当然这个类加载信息,需要通过配置文件或者注解才可以,而这个配置文件或者注解也有一定的标准,不然呈现也不能读取这些配置的信息。具体源码就不再此篇聊了。
还有在spring中也不可能只有一个bean的信息,所以在spring中用一个BeanDefinitionMap进行保存信息。
可以用一个图来看一下这个IOC创建容器的大概过程:

图中还有缓存这个概念,毕竟生存的bean有的时候会被重复使用,如果调用某个bean的时候先判断是否被保存,如果有就直接调用,如果没有就在返回查看BeanDefinitionMap中需要的bean的配置信息。图中既然写了一级缓存那就是spring有多级缓存了,这个后面有机会再聊吧。
自己写一个依注释实现IOC注入的代码
代码的结构如下:

代码直接能用,可以复制在自己环境内就可以运行。而且每步带有注解。
-
首先实现两个接口:Di和Bean
@Target(ElementType.TYPE) @Retention(RetentionPolicy.RUNTIME) public @interface Bean { } @Target(ElementType.FIELD) @Retention(RetentionPolicy.RUNTIME) public @interface Di { // 无法使用Object作为注解参数 String value(); } -
自己定义一个容器接口:MyApplicationContext
//创建一个自己Spring容器的接口 这个将BeanFactory和ApplicationContext融为一个方便写不然需要写父接口和子接口
public interface MyApplicationContext {
Object getBean(Class clazz);
}
-
实现容器接口的类:MyAnnotionAoolicationContext
public class MyAnnotionAoolicationContext implements MyApplicationContext { private static Annotation beanAnnotation; // 用一个map存储bean的信息 模仿 BeanDefinitionMap private static Map<Class, Object> MyBeanDefinitionMap = new HashMap<Class, Object>(); // 作为一个加载扫描其下包或者类的根目录 private static String rootFile; @Override public Object getBean(Class clazz) { return MyBeanDefinitionMap.get(clazz); } // 创建构造方法,加载配置文件或者带有自定义注解的 // 这个直接使用的是通过注解进行创建容器,不是通过xml配置文件进行配置 public MyAnnotionAoolicationContext(String packagename) { try { // 因为传递过来包名路径是. 转换为路径符合 String packageFile = packagename.replace(".", File.separator); // 得到绝对路径 因为会部署在不同的电脑上,目的是遍历其下的文件中是否都有注解 URL url = Thread.currentThread().getContextClassLoader().getResource(packageFile); String fileString = URLDecoder.decode(url.getFile(), "utf-8"); rootFile = fileString.substring(1, fileString.length() - packageFile.length()); // System.out.println(fileString); loadFile(fileString); } catch (Exception e) { System.out.println(e); throw new RuntimeException(e); } loadDi(); } // 遍历根路径下的文件中带有注解的文件 private static void loadFile(String fileString) { try { File file = new File(fileString); // 首先判断是否是文件夹 if (file.isDirectory()) { File[] childFileArr = file.listFiles(); // 判断文件夹是否为空,如果为空就直接跳出即可 if (childFileArr.length == 0 || childFileArr == null) { return; } else { // 遍历所有的文件判断是文件还是文件夹 for (File childFile : childFileArr) { if (childFile.isFile()) { // System.out.println(childFile); // 通过路径得到反射所需要的包路径+类名 // 这样得到的文件不是以.java 结束,而是以.class String childFileString = childFile.toString(); String forName = childFileString.substring(rootFile.length(), childFileString.length() - ".class".length()).replace("\\","."); Class clazz= Class.forName(forName); // 自己写的注解一般作用在类上而不是接口上,所以将接口,和注解类排除 if(!clazz.isAnnotation() && !clazz.isInterface()){ // 判断类上是否有bean注解,如果有就实例化 getAnnotation针对的是类上的注解 // 不过一般如果类的实例化上都没有注解,那么方法上带注解实现ioc 也就没有多少意义了 Annotation beanAnnotation= clazz.getAnnotation(Bean.class); // Class s=Class.forName("com.xzd.myannotion.Bean"); // System.out.println(s.getFields()); if(beanAnnotation!=null){ // 为了方便暂时使用空构造方法 Object bean= clazz.newInstance(); System.out.println(forName); System.out.println(clazz); // 因为一般针对的是接口,所以保存MyBeanDefinitionMap中如果有接口就以接口作为主键 if(clazz.getInterfaces().length>0) { // 默认使用第一个接口吧 MyBeanDefinitionMap.put(clazz.getInterfaces()[0], bean); }else { MyBeanDefinitionMap.put(clazz, bean); } } } } else { loadFile(String.valueOf(childFile)); } } } } } catch ( Exception e) { System.out.println(e); throw new RuntimeException(e); } } // 前面的实例对象,还可以为属性进行注入值 private void loadDi(){ try { // 一般类上带有注解的才会在属性上带有ioc注入,所以就不便利所有的类,直接从MyBeanDefinitionMap获取即可 Set<Map.Entry<Class, Object>> set= MyBeanDefinitionMap.entrySet(); Iterator<Map.Entry<Class, Object>> iterator= set.iterator(); while(iterator.hasNext()){ Map.Entry<Class, Object> entry =iterator.next(); Class clazz= entry.getKey(); Object bean= entry.getValue(); // System.out.println(bean+"111"); // 得到属性,从属性判断是否有注入数据 Field[] fields= clazz.getDeclaredFields(); System.out.println(fields.length); for(Field field:fields){ Annotation annotation= field.getAnnotation(Di.class); if(annotation!=null){ Class fieldClass= field.getType(); fieldClass.getName(); System.out.println(fieldClass.getName()+"111"); String fieldName= field.getName(); Object value= ((Di) annotation).value(); Constructor fieldconstructor=fieldClass.getConstructor(String.class); field.setAccessible(true); field.set(bean, fieldconstructor.newInstance(value)); }; } } } catch (Exception e) { throw new RuntimeException(e); } } } -
为了方便直接在一个bean上进行注解
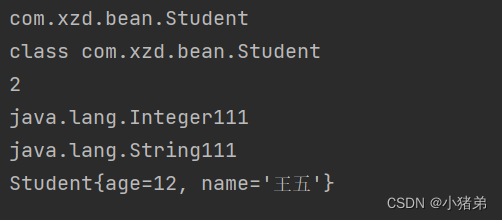
@Bean public class Student { @Di("12") Integer age; @Di("王五") String name; @Override public String toString() { return "Student{" + "age=" + age + ", name='" + name + '\'' + '}'; } } -
测试方便调用:test
public class testSpring { public static void main(String[] args) { // 直接从目录上开始加载 MyApplicationContext myApplicationContext= new MyAnnotionAoolicationContext("com.xzd"); Student student= (Student) myApplicationContext.getBean(Student.class); System.out.println(student); } }