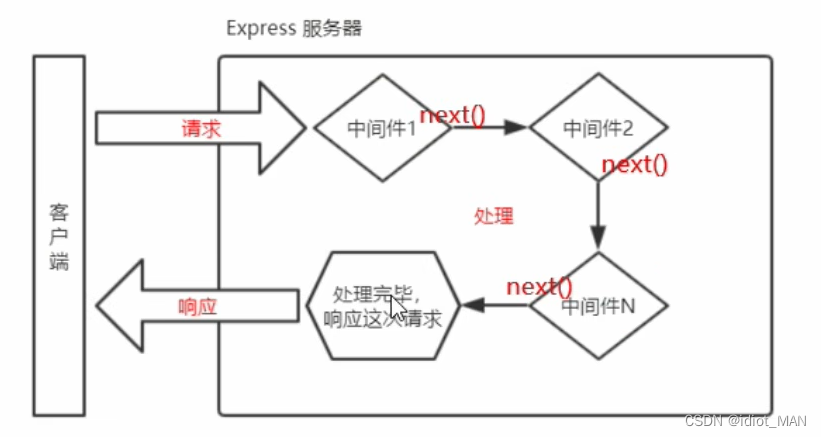
AIGC(AI Generated Content),即通过人工智能方法生成内容,是当前深度学习最热门的方向之一。其在绘画、写作等场景的应用也一直层出不穷,其中,AI绘画是大家关注和体验较多的方向。
Diffusion系列文生图模型可以实现AI绘画应用,其一经推出就受到广泛关注,开启了一波“全民调教AI作画”的潮流,激起了大量的应用需求。与此同时,百度推出的知识增强跨模态大模型——文心ERNIE-ViLG 2.0在 AI 作画领域取得新突破。该模型在文本生成图像公开权威评测集MS-COCO和人工盲评上均超越了Stable Diffusion、DALL-E 2等模型,当前在该领域取得了最好的效果,在语义可控性、图像清晰度、中国文化理解等方面均展现出了显著的优势。
开发者和科技爱好者可以将文心 ERNIE-ViLG 2.0 API (wenxin.baidu.com/ernie-vilg)灵活方便地集成到产品中。同时,基于文心ERNIE-ViLG 2.0大模型,百度也推出AI艺术与创意辅助平台——文心一格(yige.baidu.com),以满足更多的人在AI作画方面的需求。

文心一格模型效果图~
AI绘画模型推理算力及显存需求随图像分辨率增大而指数级增加,同时图像生成需要循环采样数十次,产业落地动辄需要高昂成本的部署集群,严重阻碍了AIGC模型大规模商业化落地。为此,百度飞桨一直致力于大模型的训练、压缩、推理端到端优化,实现低成本的模型部署上线,助力AIGC模型快速产业落地。
飞桨深度优化的Stable Diffusion模型,在单卡NVIDIA A100(80G) 上推理速度和显存利用率全面超越同类产品,取得业界第一的领先优势。百度自研中文AI绘画ERNIE-ViLG模型,在昆仑芯 R200(32GB) 卡上推理,全面超越同系列主流推理卡,并已成功批量部署于文心一格创意平台。
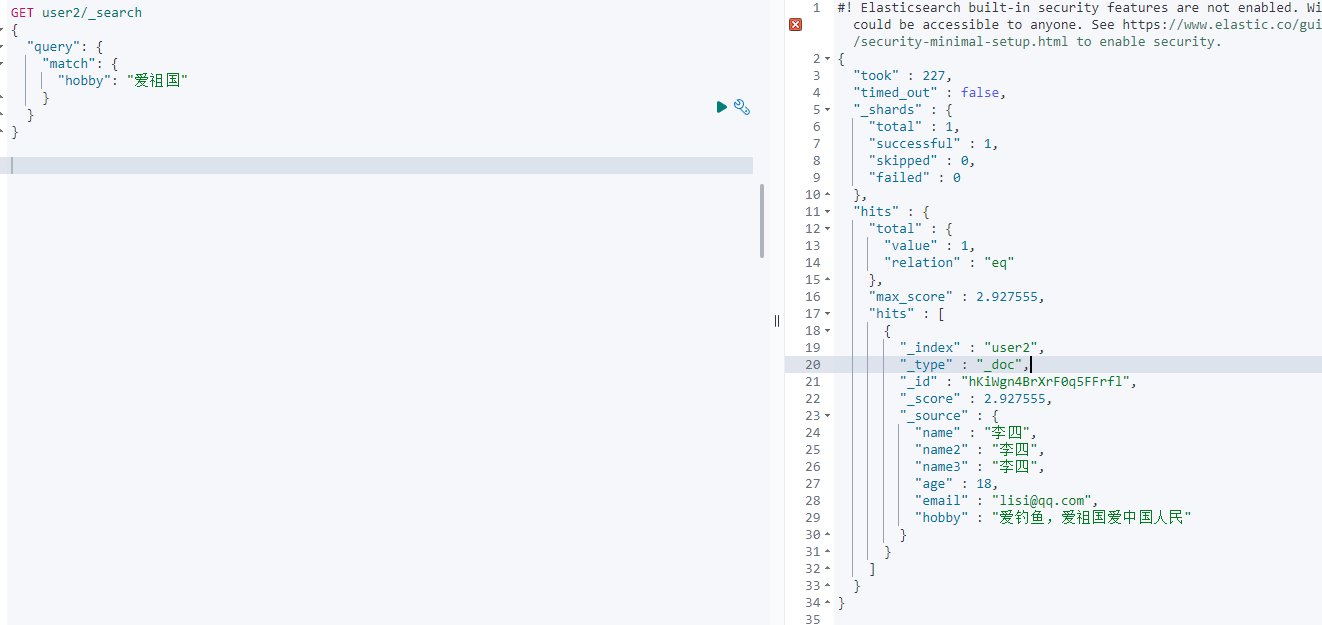
GPU推理性能数据
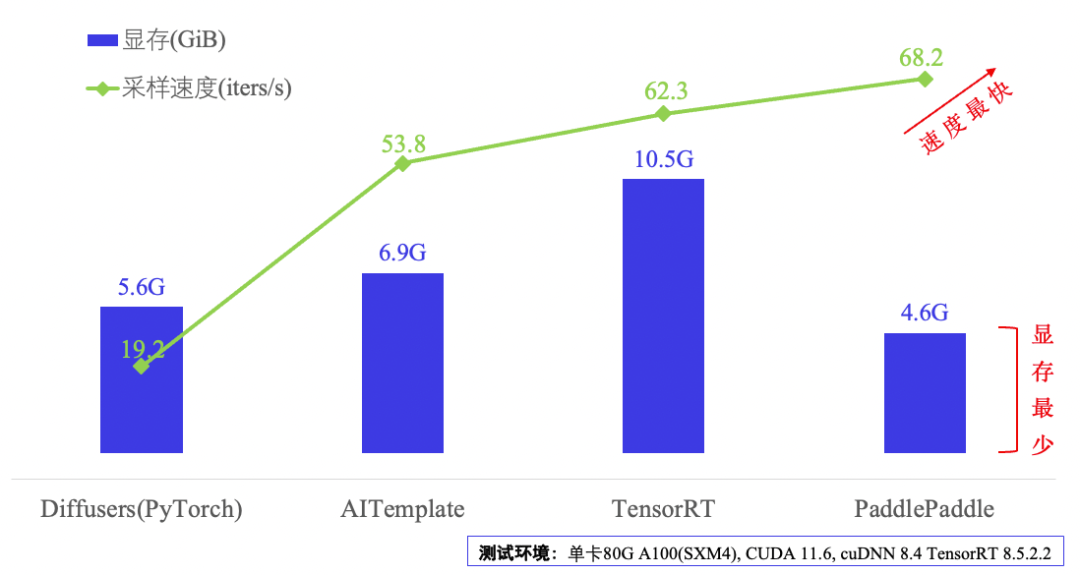
下图展示了分别使用PaddlePaddle、TensorRT、AITemplate和Diffusers(PyTorch)4种深度学习框架或推理引擎对Stable Diffusion进行推理时的性能表现。可以看出,基于PaddlePaddle对Stable Diffusion进行推理时,512*512图像生成速度68.2 iters/s,实现 0.76s 出图。其推理速度是 Diffusers(PyTorch)的4倍,比TensorRT最优速度快7.9%,同时显存占用仅为TensorRT的43%。

昆仑芯 R200 性能数据
昆仑芯 R200 性能数据在dpm-25steps算法下,生成1024*1024图像时的推理速度相比同能力的主流推理卡快20%。同时,R200拥有32G显存,能够生成更高分辨率的图片,可以推理更大的模型,为用户带了高性价比的选择。

不同硬件跑ERNIE-ViLG的推理速度及显存占用对比

向左滑动查看飞桨Stable Diffusion 模型效果图~
快速体验
Stable Diffusion训练推理全流程已在飞桨扩散模型工具箱中开源
- 参考链接
https://github.com/PaddlePaddle/PaddleNLP/tree/develop/ppdiffusers
同时,对于飞桨Stable Diffusion在GPU和 昆仑芯上的高性能部署,FastDeploy部署工具已经提供了开箱即用的部署体验
- 参考链接
https://github.com/PaddlePaddle/FastDeploy/tree/develop/examples/multimodal/stable_diffusion
与此同时,随着大模型应用的不断出圈,AIGC相关的应用落地需求也不断激增,因此,百度百舸联合飞桨团队将飞桨训推大模型的能力优势与AI加速组件AIAK(AI Accelerate Kit)完美融合,形成全新产品“飞桨云原生大模型开发工具”,显著提升了云用户大模型任务的开发和部署效率,并加速了生成式AI的工程化落地。作为业界首个经过全流程验证的大模型开发工具,飞桨云原生大模型开发工具不仅拥有更极致的性能,还可以让开发者体验到千亿大模型的的分布式训练和推理功能。
备注说明
- 百度百舸
AI异构计算平台,包含AI计算、AI存储、AI加速、AI容器四大核心套件,具有高性能、高弹性、高速互联、高性价比等特性。充分汲取了百度异构计算平台多年的技术积累,深度融合推荐、无人驾驶、生命科学、NLP等场景的实践经验,能为AI场景提供软硬一体解决方案,加速AI工程化落地。
- AIAK
结合飞桨与百度云百舸整体方案优势联合推出的AI加速套件,用来加速基于飞桨等深度学习框架开发的AI应用,能极大提升分布式训练和推理的性能,大幅增加异构资源使用效率。
- 飞桨云原生大模型开发工具
业界首个经过全流程完整验证的大模型开发工具,支撑GPT-3、Bloom、Stable Diffusion等多个大模型训练、微调、压缩、推理的流畅开发体验。
01 性能优化核心解读
飞桨原生推理库Paddle Inference的领先效果、基于飞桨框架领先的架构设计和针对Stable Diffsuion模型的深度优化,主要体现在如下几个方面:
Flash Attention
飞桨一直致力于大模型推理优化,支持多种通用Transformer类结构的高性能推理优化。在Stable Diffusion模型推理中,飞桨集成的高性能的Flash Attention kernel,通过将attention中的softmax计算进行拆解、分片计算,大量减少推理过程中self-attention和cross-attention计算对显存的访问次数,同时实现了推理加速和显存优化。
Norm融合
Norm是Stable Diffusion中U-Net常用算子,主要分为LayerNorm和GroupNorm。LayerNorm和GroupNorm算子作为批规约运算,能够很好地和前后的elementwise类型、激活类型算子进行融合,消除算子间的显存访问。飞桨对LayerNorm和GroupNorm与前后算子的4种不同pattern进行了融合,共融合了93个Norm结构,提升了3%的推理性能。

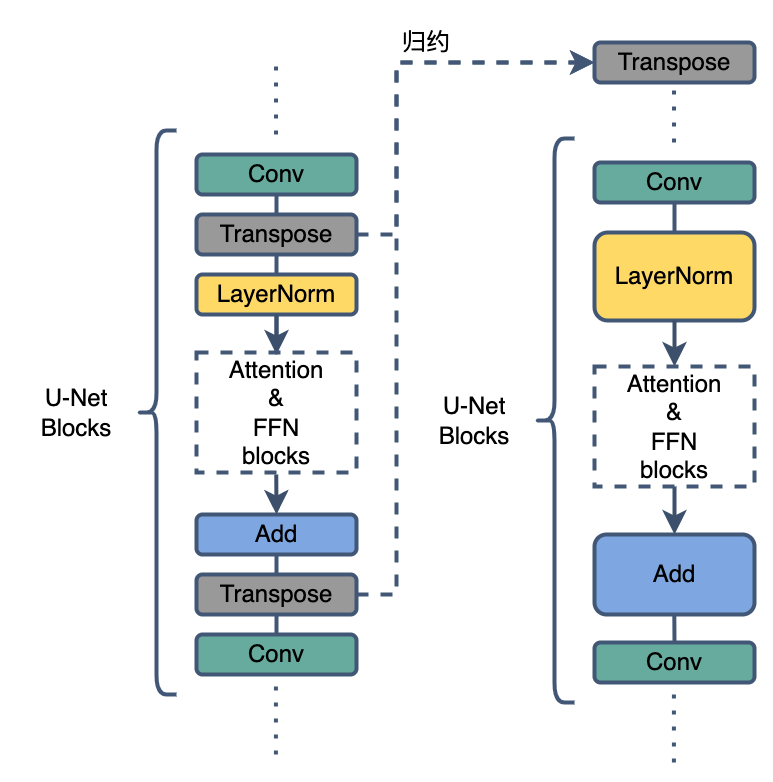
混合Layout计算
通过对模型张量排布匹配优化,支持不同的Layout消除和合并U-Net中的转置操作,提高了推理速度同时也能降低了运行显存占用,共减少了32次转置操作,带来了3~4%的推理性能提升。
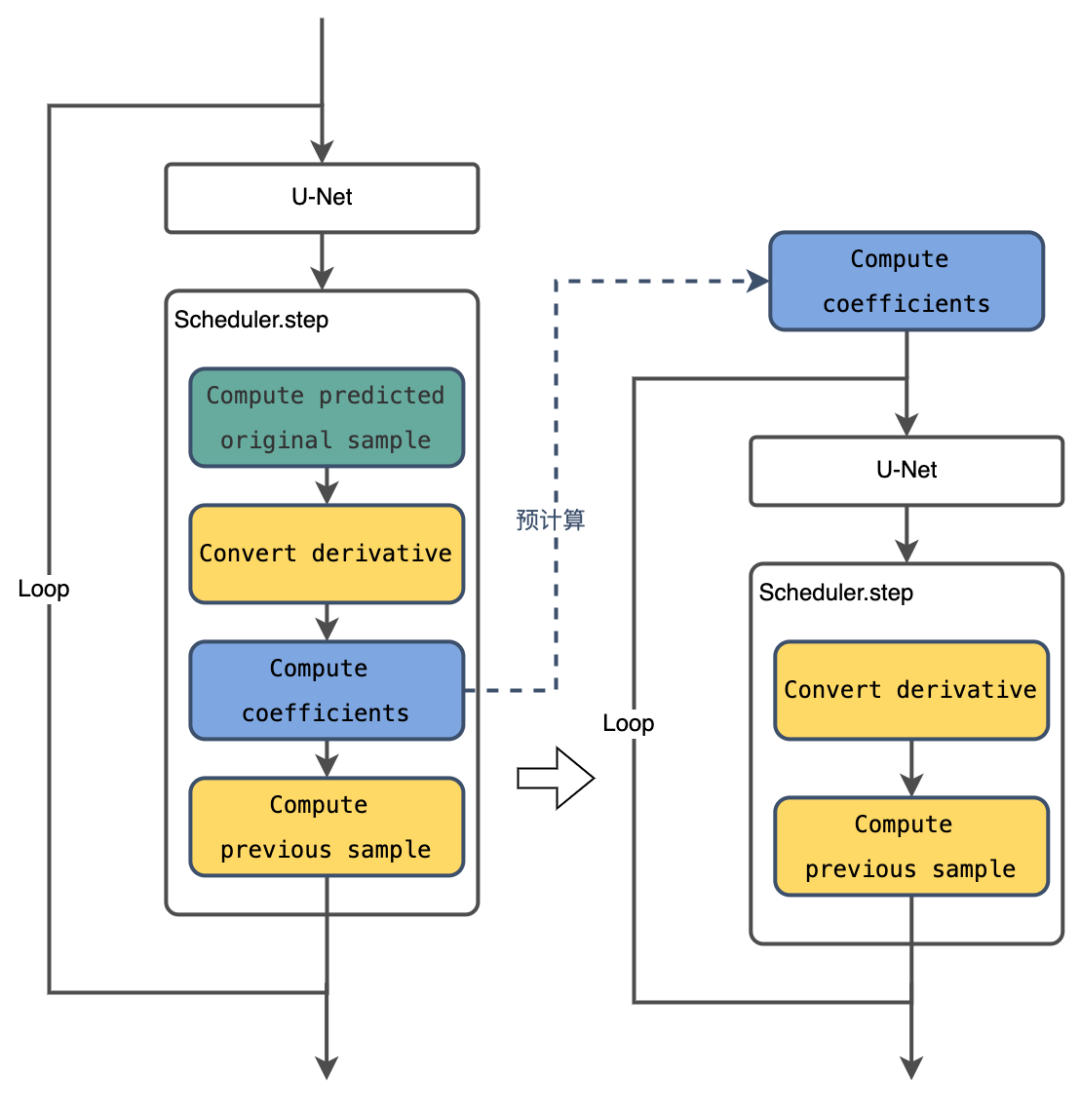
Scheduler优化
对PPDiffusers库中的scheduler运算逻辑进行了重新整合梳理,将scheduler.step中的GPU算子发射数量由约12个减小至7个,同时通过参数预计算的方法,消除了采样循环中scheduler运算的CPU计算以及GPU同步开销。
推理显存优化
经过飞桨框架的算子融合引擎处理,Stable Diffusion模型中U-Net模型的独立算子数量减少60%,显存占用下降27%。针对U-Net模型的Layout优化消除了转置变换带来的额外显存消耗,能够使整体显存占用降低约19%。同时,针对ERNIE-ViLG 2.0文心AI作画大模型,飞桨框架提供了推理workspace复用技术,使ERNIE-ViLG 2.0模型显存占用下降37%,极大降低了ERNIE-ViLG 2.0文心AI作画大模型的部署成本。
基于飞桨原生推理库Paddle Inference的高性能架构设计,结合上述优化点,飞桨Stable Diffusion模型能实现在单卡80G A100(SXM4)上,512*512分辨率生成图像(50 iters)推理时延0.76s,推理速度达到68.2 iters/s,显存占用4.6G,显存占用方面和速度方面均为当前业界最优效果。
02 后续工作
飞桨在持续推进AIGC模型、AI对话模型等大模型的优化,结合飞桨框架训推一体的核心能力,发布更多训练、压缩、推理端到端优化的高性能产业级大模型,并持续打磨部署端到端方案,助力大模型更全面产业化,欢迎各位开发者持续关注或反馈需求和建议。