1. 导读
你们是否也有过下面的想法?
- 重构一个项目还不如新开发一个项目…
- 这代码是谁写的,我真想…
你们的项目中是否也存在下面的问题?
- 单个项目也越来越庞大,团队成员代码风格不一致,无法对整体的代码质量做全面的掌控
- 没有一个准确的标准去衡量代码结构复杂的程度,无法量化一个项目的代码质量
- 重构代码后无法立即量化重构后代码质量是否提升
针对上面的问题,本文的主角 圈复杂度 重磅登场,本文将从圈复杂度原理出发,介绍圈复杂度的计算方法、如何降低代码的圈复杂度,如何获取圈复杂度,以及圈复杂度在公司项目的实践应用。
2. 圈复杂度
2.1 定义
圈复杂度 (Cyclomatic complexity) 是一种代码复杂度的衡量标准,也称为条件复杂度或循环复杂度,它可以用来衡量一个模块判定结构的复杂程度,数量上表现为独立现行路径条数,也可理解为覆盖所有的可能情况最少使用的测试用例数。简称 CC 。其符号为 VG 或是 M 。
圈复杂度 在 1976 年由 Thomas J. McCabe, Sr. 提出。
圈复杂度大说明程序代码的判断逻辑复杂,可能质量低且难于测试和维护。程序的可能错误和高的圈复杂度有着很大关系。
2.2 衡量标准
代码复杂度低,代码不一定好,但代码复杂度高,代码一定不好。
| 圈复杂度 | 代码状况 | 可测性 | 维护成本 |
|---|---|---|---|
| 1 - 10 | 清晰、结构化 | 高 | 低 |
| 10 - 20 | 复杂 | 中 | 中 |
| 20 - 30 | 非常复杂 | 低 | 高 |
| >30 | 不可读 | 不可测 | 非常高 |
3. 计算方法
3.1 控制流程图
控制流程图,是一个过程或程序的抽象表现,是用在编译器中的一个抽象数据结构,由编译器在内部维护,代表了一个程序执行过程中会遍历到的所有路径。它用图的形式表示一个过程内所有基本块执行的可能流向, 也能反映一个过程的实时执行过程。
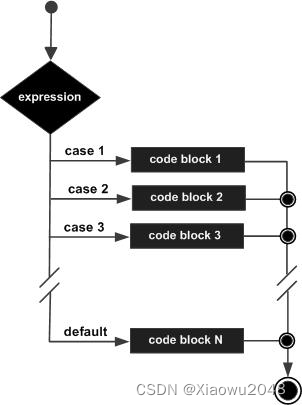
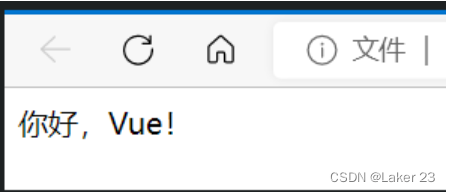
下面是一些常见的控制流程:
3.2 节点判定法
有一个简单的计算方法,圈复杂度实际上就是等于判定节点的数量再加上1。向上面提到的:if else 、switch case 、 for循环、三元运算符等等,都属于一个判定节点,例如下面的代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | function testComplexity(*param*) {
let result = 1;
if (param > 0) {
result--;
}
for (let i = 0; i < 10; i++) {
result += Math.random();
}
switch (parseInt(result)) {
case 1:
result += 20;
break;
case 2:
result += 30;
break;
default:
result += 10;
break;
}
return result > 20 ? result : result;
}
|
上面的代码中一共有1个if语句,一个for循环,两个case语句,一个三元运算符,所以代码复杂度为 1+2+1+1+1=6。另外,需要注意的是 || 和 && 语句也会被算作一个判定节点,例如下面代码的代码复杂为3:
1 2 3 4 5 6 7 | function testComplexity(*param*) {
let result = 1;
if (param > 0 && param < 10) {
result--;
}
return result;
}
|
3.3 点边计算法
1 | M = E − N + 2P |
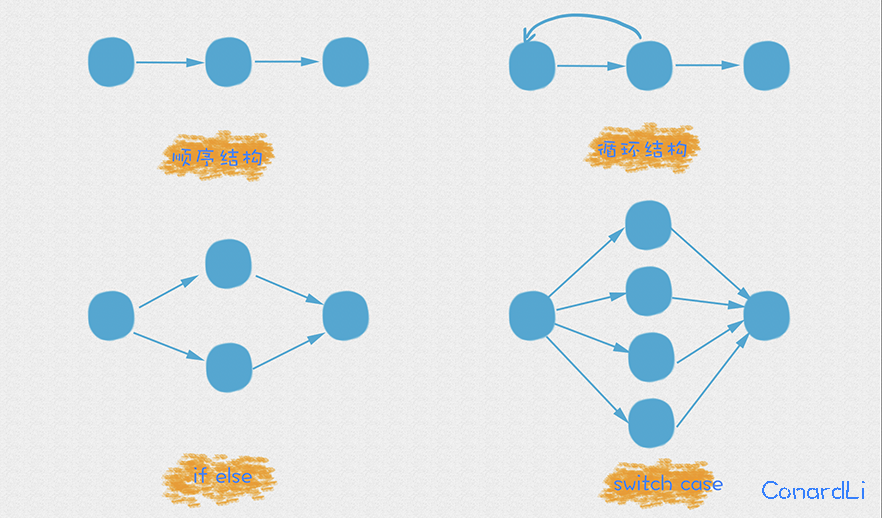
- E:控制流图中边的数量
- N:控制流图中的节点数量
- P:独立组件的数目
前两个,边和节点都是数据结构图中最基本的概念:
P代表图中独立组件的数目,独立组件是什么意思呢?来看看下面两个图,左侧为连通图,右侧为非连通图:
- 连通图:对于图中任意两个顶点都是连通的
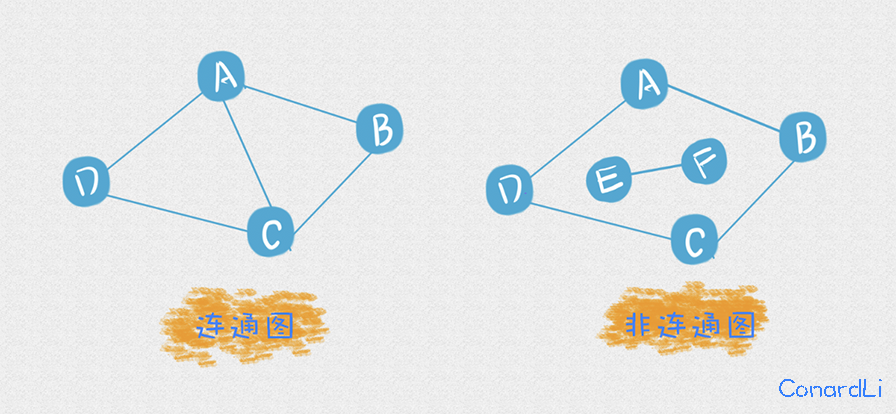
一个连通图即为图中的一个独立组件,所以左侧图中独立组件的数目为1,右侧则有两个独立组件。
对于我们的代码转化而来的控制流程图,正常情况下所有节点都应该是连通的,除非你在某些节点之前执行了 return,显然这样的代码是错误的。所以每个程序流程图的独立组件的数目都为1,所以上面的公式还可以简化为 M = E − N + 2 。
4. 降低代码的圈复杂度
我们可以通过一些代码重构手段来降低代码的圈复杂度。
重构需谨慎,示例代码仅仅代表一种思想,实际代码要远远比示例代码复杂的多。
4.1 抽象配置
通过抽象配置将复杂的逻辑判断进行简化。例如下面的代码,根据用户的选择项执行相应的操作,重构后降低了代码复杂度,并且如果之后有新的选项,直接加入配置即可,而不需要再去深入代码逻辑中进行改动:

4.2 单一职责 - 提炼函数
单一职责原则(SRP):每个类都应该有一个单一的功能,一个类应该只有一个发生变化的原因。
在 JavaScript 中,需要用到的类的场景并不太多,单一职责原则则是更多地运用在对象或者方法级别上面。
函数应该做一件事,做好这件事,只做这一件事。 — 代码整洁之道
关键是如何定义这 “一件事” ,如何将代码中的逻辑进行抽象,有效的提炼函数有利于降低代码复杂度和降低维护成本。

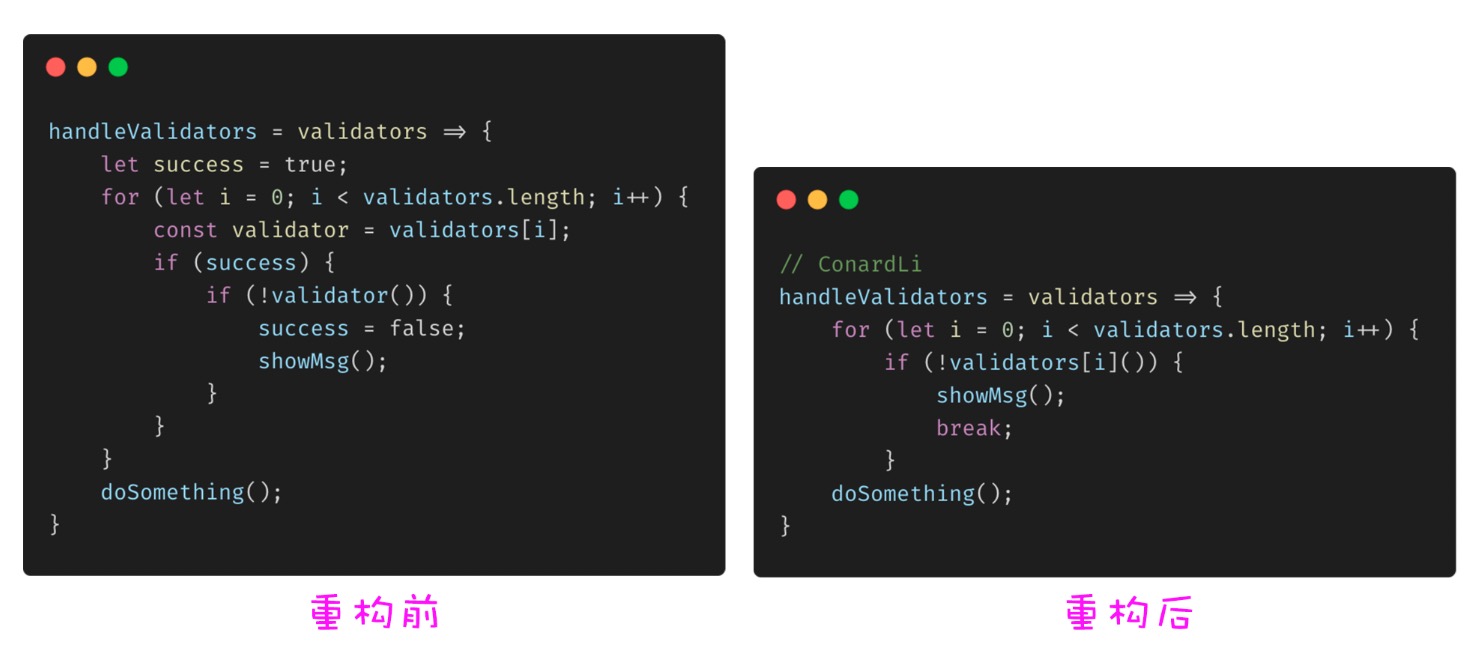
4.3 使用 break 和 return 代替控制标记
我们经常会使用一个控制标记来标示当前程序运行到某一状态,很多场景下,使用 break 和 return 可以代替这些标记并降低代码复杂度。
4.4 用函数取代参数
setField 和 getField 函数就是典型的函数取代参数,如果么有 setField、getField 函数,我们可能需要一个很复杂的 setValue、getValue 来完成属性赋值操作:

4.5 简化条件判断 - 逆向条件
某些复杂的条件判断可能逆向思考后会变的更简单。

4.6 简化条件判断 -合并条件
将复杂冗余的条件判断进行合并。

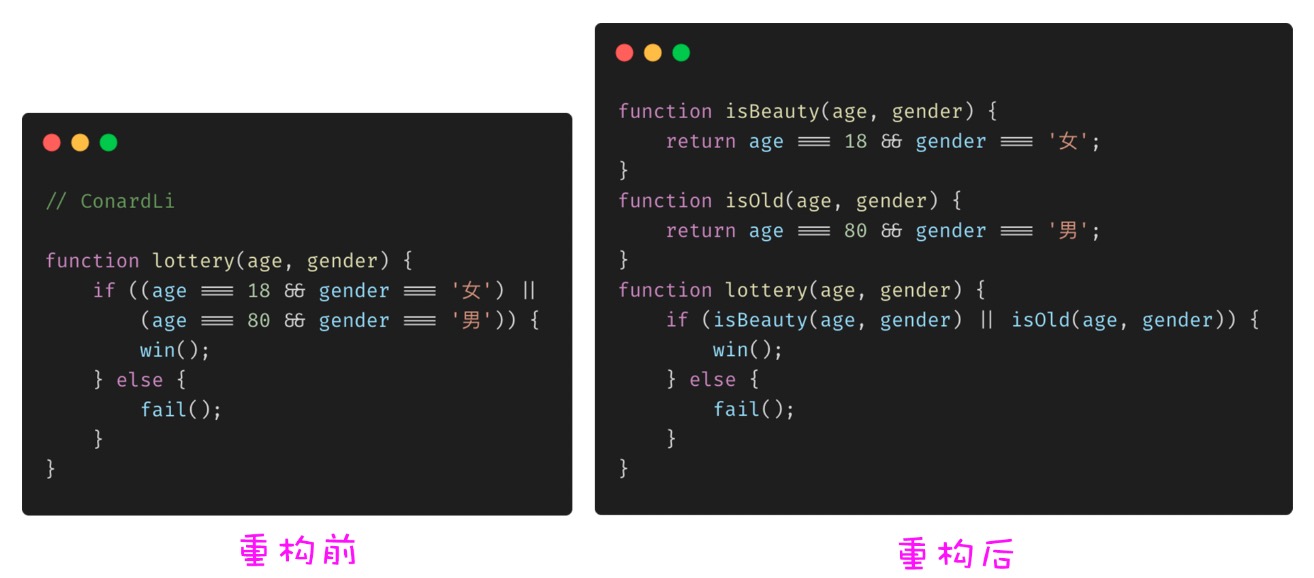
4.7 简化条件判断 - 提取条件
将复杂难懂的条件进行语义化提取。
5. 圈复杂度检测方法
5.1 eslint规则
eslint提供了检测代码圈复杂度的rules:
我们将开启 rules 中的 complexity 规则,并将圈复杂度大于 0 的代码的 rule severity 设置为 warn 或 error 。
1 2 3 4 5 6 | rules: {
complexity: [
'warn',
{ max: 0 }
]
}
|
这样 eslint 就会自动检测出所有函数的代码复杂度,并输出一个类似下面的 message。
1 2 3 4 | Method 'testFunc' has a complexity of 12. Maximum allowed is 0 Async function has a complexity of 6. Maximum allowed is 0. ... |
5.2 CLIEngine
我们可以借助 eslint 的 CLIEngine ,在本地使用自定义的 eslint 规则扫描代码,并获取扫描结果输出。
初始化 CLIEngine :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | const eslint = require('eslint');
const { CLIEngine } = eslint;
const cli = new CLIEngine({
parserOptions: {
ecmaVersion: 2018,
},
rules: {
complexity: [
'error',
{ max: 0 }
]
}
});
|
使用 executeOnFiles 对指定文件进行扫描,并获取结果,过滤出所有 complexity 的 message 信息。
1 2 3 4 5 6 7 8 9 10 11 | const reports = cli.executeOnFiles(['.']).results;
for (let i = 0; i < reports.length; i++) {
const { messages } = reports[i];
for (let j = 0; j < messages.length; j++) {
const { message, ruleId } = messages[j];
if (ruleId === 'complexity') {
console.log(message);
}
}
}
|
5.3 提取message
通过 eslint 的检测结果将有用的信息提取出来,先测试几个不同类型的函数,看看 eslint 的检测结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | function func1() {
console.log(1);
}
const func2 = () => {
console.log(2);
};
class TestClass {
func3() {
console.log(3);
}
}
async function func4() {
console.log(1);
}
|
执行结果:
1 2 3 4 | Function 'func1' has a complexity of 1. Maximum allowed is 0. Arrow function has a complexity of 1. Maximum allowed is 0. Method 'func3' has a complexity of 1. Maximum allowed is 0. Async function 'func4' has a complexity of 1. Maximum allowed is 0. |
可以发现,除了前面的函数类型,以及后面的复杂度,其他都是相同的。
函数类型:
Function:普通函数Arrow function: 箭头函数Method: 类方法Async function: 异步函数
截取方法类型:
1 2 3 4 5 6 | const REG_FUNC_TYPE = /^(Method |Async function |Arrow function |Function )/g;
function getFunctionType(message) {
let hasFuncType = REG_FUNC_TYPE.test(message);
return hasFuncType && RegExp.$1;
}
|
将有用的部分提取出来:
1 2 3 4 5 6 7 | const MESSAGE_PREFIX = 'Maximum allowed is 1.';
const MESSAGE_SUFFIX = 'has a complexity of ';
function getMain(message) {
return message.replace(MESSAGE_PREFIX, '').replace(MESSAGE_SUFFIX, '');
}
|
提取方法名称:
1 2 3 4 5 | function getFunctionName(message) {
const main = getMain(message);
let test = /'([a-zA-Z0-9_$]+)'/g.test(main);
return test ? RegExp.$1 : '*';
}
|
截取代码复杂度:
1 2 3 4 5 | function getComplexity(message) {
const main = getMain(message);
(/(\d+)\./g).test(main);
return +RegExp.$1;
}
|
除了 message ,还有其他的有用信息:
- 函数位置:获取
messages中的line、column即函数的行、列位置 - 当前文件名称:
reports结果中可以获取当前扫描文件的绝对路径filePath,通过下面的操作获取真实文件名:
1 | filePath.replace(process.cwd(), '').trim() |
- 复杂度等级,根据函数的复杂度等级给出重构建议:
| 圈复杂度 | 代码状况 | 可测性 | 维护成本 |
|---|---|---|---|
| 1 - 10 | 清晰、结构化 | 高 | 低 |
| 10 - 20 | 复杂 | 中 | 中 |
| 20 - 30 | 非常复杂 | 低 | 高 |
| >30 | 不可读 | 不可测 | 非常高 |
| 圈复杂度 | 代码状况 |
|---|---|
| 1 - 10 | 无需重构 |
| 11 - 15 | 建议重构 |
| >15 | 强烈建议重构 |
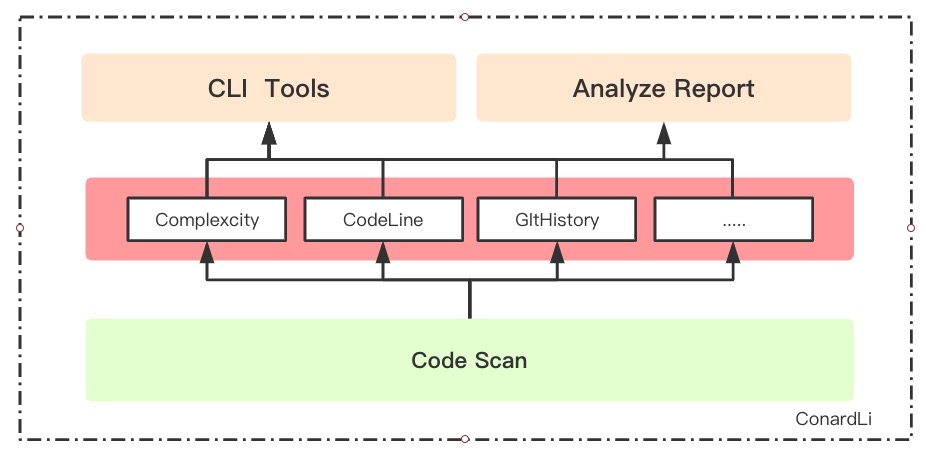
6.架构设计
将代码复杂度检测封装成基础包,根据自定义配置输出检测数据,供其他应用调用。
上面的展示了使用 eslint 获取代码复杂度的思路,下面我们要把它封装为一个通用的工具,考虑到工具可能在不同场景下使用,例如:网页版的分析报告、cli版的命令行工具,我们把通用的能力抽象出来以 npm包 的形式供其他应用使用。
在计算项目代码复杂度之前,我们首先要具备一项基础能力,代码扫描,即我们要知道我们要对项目里的哪些文件做分析,首先 eslint 是具备这样的能力的,我们也可以直接用 glob 来遍历文件。但是他们都有一个缺点,就是 ignore 规则是不同的,这对于用户来讲是有一定学习成本的,因此我这里把手动封装代码扫描,使用通用的 npm ignore 规则,这样代码扫描就可以直接使用 .gitignore这样的配置文件。另外,代码扫描作为代码分析的基础能力,其他代码分析也是可以公用的。
- 基础能力
- 代码扫描能力
- 复杂度检测能力
- …
- 应用
- 命令行工具
- 代码分析报告
- …
7. 基础能力 - 代码扫描
本文涉及的 npm 包和 cli命令源码均可在我的开源项目 awesome-cli中查看。
awesome-cli 是我新建的一个开源项目:有趣又实用的命令行工具,后面会持续维护,敬请关注,欢迎 star。
代码扫描(c-scan)源码:awesome-cli/conard at master · ConardLi/awesome-cli · GitHub
代码扫描是代码分析的底层能力,它主要帮助我们拿到我们想要的文件路径,应该满足我们以下两个需求:
- 我要得到什么类型的文件
- 我不想要哪些文件
7.1 使用
1 2 3 4 5 6 7 8 9 10 | npm i c-scan --save
const scan = require('c-scan');
scan({
extensions:'**/*.js',
rootPath:'src',
defalutIgnore:'true',
ignoreRules:[],
ignoreFileName:'.gitignore'
});
|
7.2 返回值
符合规则的文件路径数组:

7.3 参数
-
extensions
- 扫描文件扩展名
- 默认值:
**/*.js
-
rootPath
- 扫描文件路径
- 默认值:
.
-
defalutIgnore
- 是否开启默认忽略(
glob规则) glob ignore规则为内部使用,为了统一ignore规则,自定义规则使用gitignore规则- 默认值:
true - 默认开启的
glob ignore规则:
- 是否开启默认忽略(
1 2 3 4 5 6 7 | const DEFAULT_IGNORE_PATTERNS = [
'node_modules/**',
'build/**',
'dist/**',
'output/**',
'common_build/**'
];
|
-
ignoreRules
- 自定义忽略规则(
gitignore规则) - 默认值:
[]
- 自定义忽略规则(
-
ignoreFileName
- 自定义忽略规则配置文件路径(
gitignore规则) - 默认值:
.gitignore - 指定为
null则不启用ignore配置文件
- 自定义忽略规则配置文件路径(
7.4 核心实现
基于 glob ,自定义 ignore 规则进行二次封装。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 | /**
* 获取glob扫描的文件列表
* @param {*} rootPath 跟路径
* @param {*} extensions 扩展
* @param {*} defalutIgnore 是否开启默认忽略
*/
function getGlobScan(rootPath, extensions, defalutIgnore) {
return new Promise(resolve => {
glob(`${rootPath}${extensions}`,
{ dot: true, ignore: defalutIgnore ? DEFAULT_IGNORE_PATTERNS : [] },
(err, files) => {
if (err) {
console.log(err);
process.exit(1);
}
resolve(files);
});
});
}
/**
* 加载ignore配置文件,并处理成数组
* @param {*} ignoreFileName
*/
async function loadIgnorePatterns(ignoreFileName) {
const ignorePath = path.resolve(process.cwd(), ignoreFileName);
try {
const ignores = fs.readFileSync(ignorePath, 'utf8');
return ignores.split(/[\n\r]|\n\r/).filter(pattern => Boolean(pattern));
} catch (e) {
return [];
}
}
/**
* 根据ignore配置过滤文件列表
* @param {*} files
* @param {*} ignorePatterns
* @param {*} cwd
*/
function filterFilesByIgnore(files, ignorePatterns, ignoreRules, cwd = process.cwd()) {
const ig = ignore().add([...ignorePatterns, ...ignoreRules]);
const filtered = files
.map(raw => (path.isAbsolute(raw) ? raw : path.resolve(cwd, raw)))
.map(raw => path.relative(cwd, raw))
.filter(filePath => !ig.ignores(filePath))
.map(raw => path.resolve(cwd, raw));
return filtered;
}
|
8. 基础能力 - 代码复杂度检测
代码复杂度检测(c-complexity)源码:awesome-cli/code-complexity at master · ConardLi/awesome-cli · GitHub
代码检测基础包应该具备以下几个能力:
- 自定义扫描文件夹和类型
- 支持忽略文件
- 定义最小提醒代码复杂度
8.1 使用
1 2 3 4 | npm i c-complexity --save
const cc = require('c-complexity');
cc({},10);
|
8.2 返回值
- fileCount:文件数量
- funcCount:函数数量
- result:详细结果
- funcType:函数类型
- funcName;函数名称
- position:详细位置(行列号)
- fileName:文件相对路径
- complexity:代码复杂度
- advice:重构建议
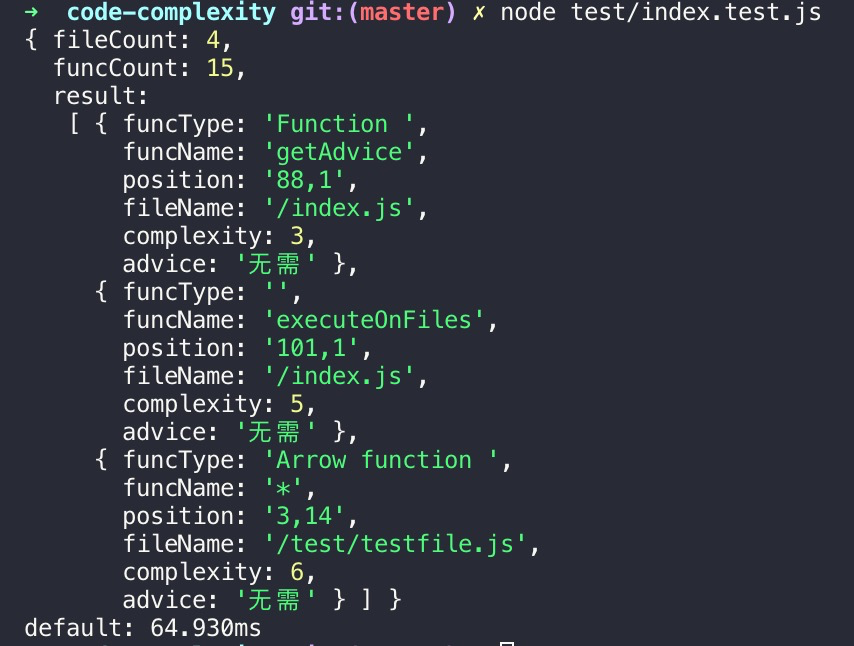
8.3 参数
scanParam- 继承自上面代码扫描的参数
min- 最小提醒代码复杂度,默认为1
9. 应用 - 代码复杂度检测工具
代码复杂度检测(conard cc)源码:awesome-cli/conard at master · ConardLi/awesome-cli · GitHub
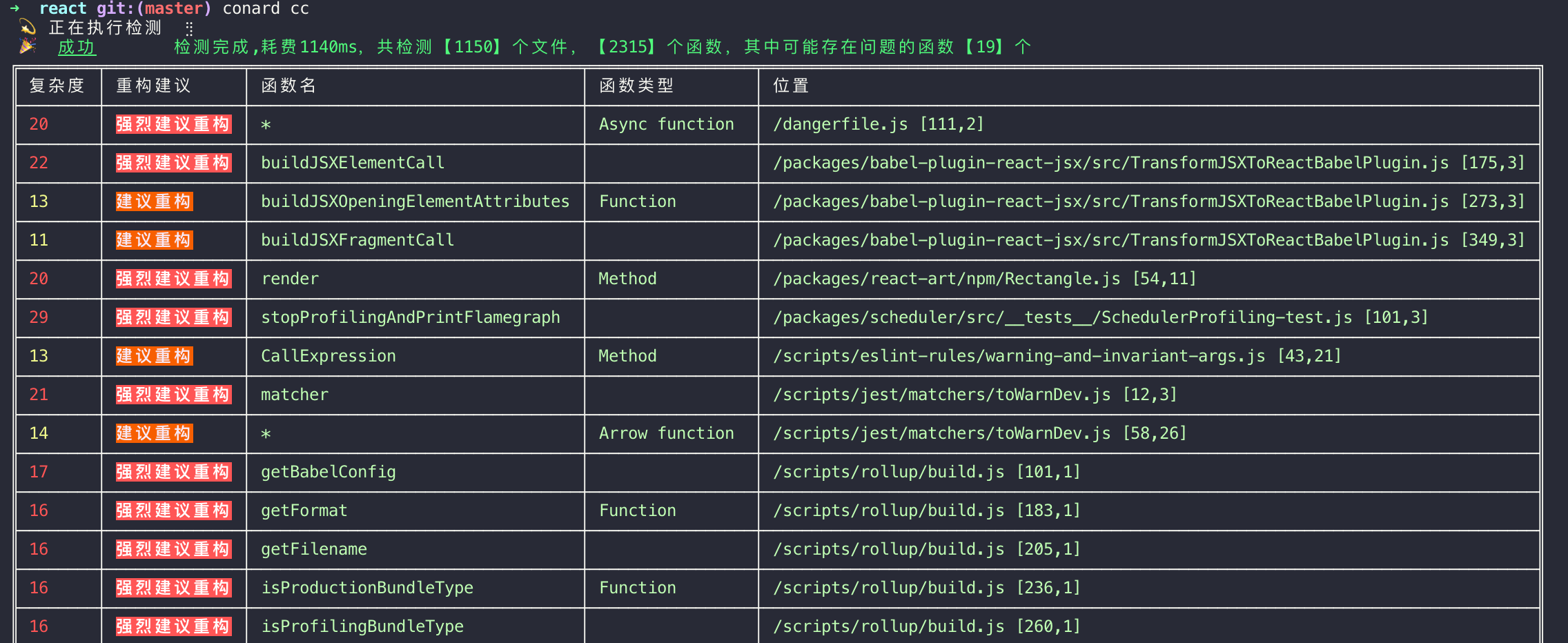
9.1 指定最小提醒复杂度
可以触发提醒的最小复杂度。
- 默认为
10 - 通过命令
conard cc --min=5自定义
9.2 指定扫描参数
自定义扫描规则
- 扫描参数继承自上面的
scan param - 例如:
conard cc --defalutIgnore=false
10. 应用 - 代码复杂度报告
部分截图来源于我们内部的项目质量监控平台,圈复杂度作为一项重要的指标,对于衡量项目代码质量起着至关重要的作用。
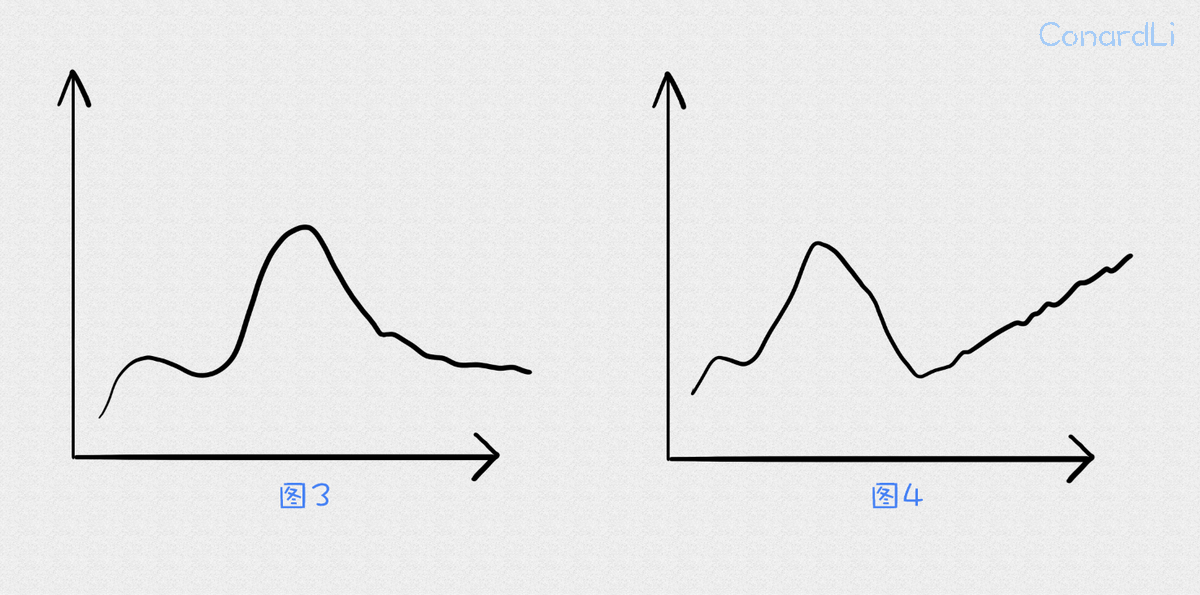
代码复杂复杂度变化趋势
定时任务爬取代码每日的代码复杂度、代码行数、函数个数,通过每日数据绘制代码复杂度和代码行数变化趋势折线图。
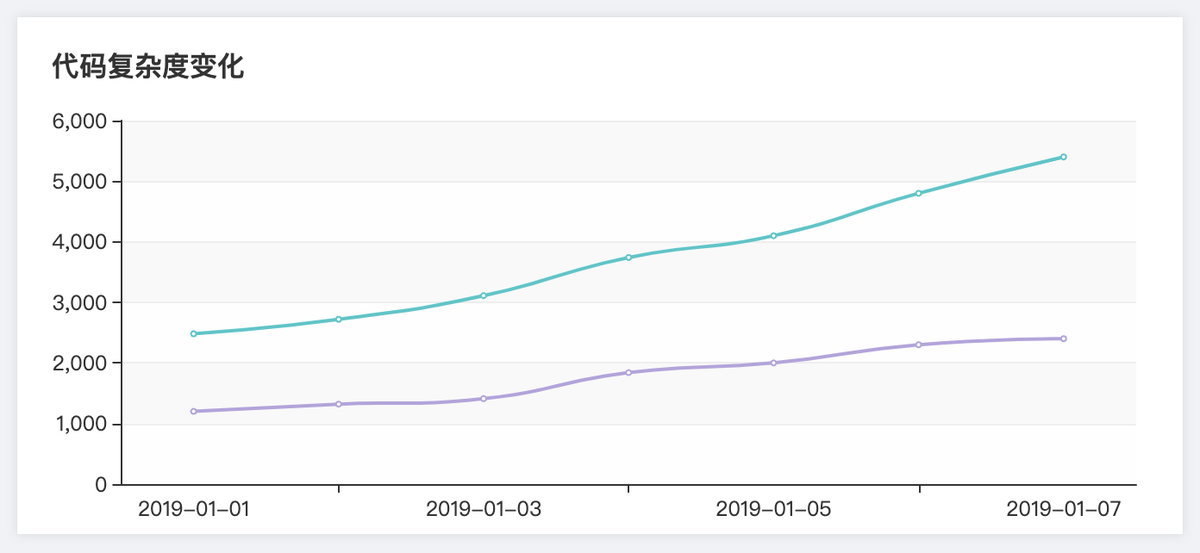
通过 [ 复杂度 / 代码行数 ] 或 [ 复杂度 / 函数个数 ] 的变化趋势,判断项目发展是否健康。
-
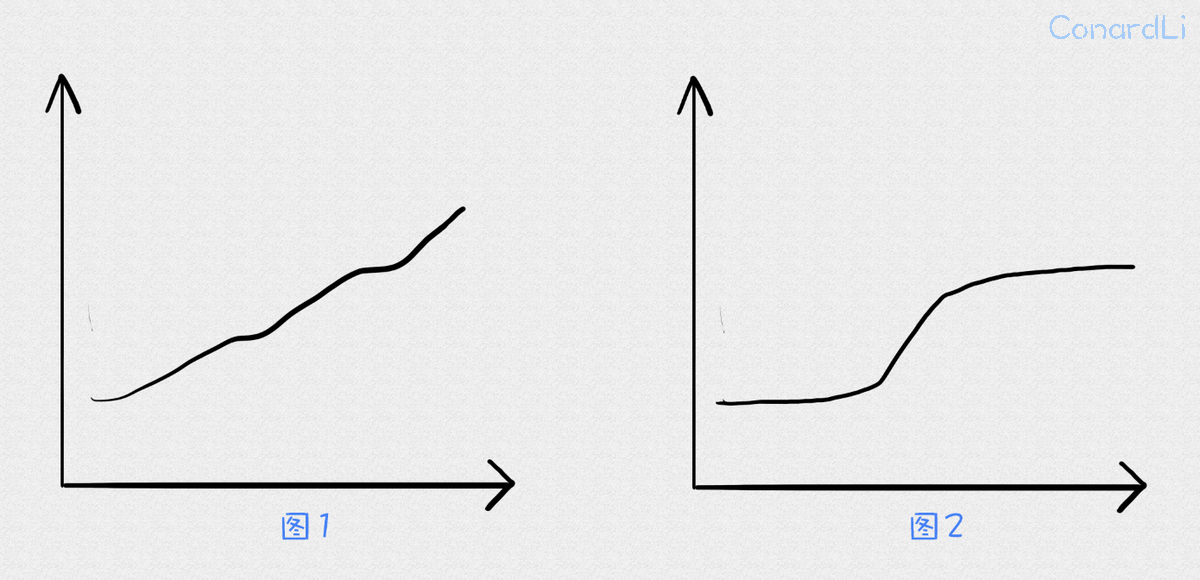
比值若一直在上涨,说明你的代码在变得越来越难以理解。这不仅使我们面临意外的功能交互和缺陷的风险,由于我们在具有或多或少相关功能的模块中所面临的过多认知负担,也很难重用代码并进行修改和测试。(下图1)
-
若比值在某个阶段发生突变,说明这段期间迭代质量很差。(下图2)
-
复杂度曲线图可以很快的帮你更早的发现上面这两个问题,发现它们后,你可能需要重构代码。复杂性趋势对于跟踪你的代码重构也很有用。复杂性趋势的下降趋势是一个好兆头。这要么意味着您的代码变得更简单(例如,把 if-else 被重构为多态解决方案),要么代码更少(将不相关的部分提取到了其他模块中)。(下图3)
-
代码重构后,你还需要继续探索复杂度变化趋势。经常发生的事情是,我们花费大量的时间和精力来重构,无法解决根本原因,很快复杂度又滑回了原处。(下图4)你可能觉得这是个例,但是有研究标明,在分析了数百个代码库后,发现出现这种情况的频率很高。因此,时刻观察代码复杂度变化趋势是有必要的。
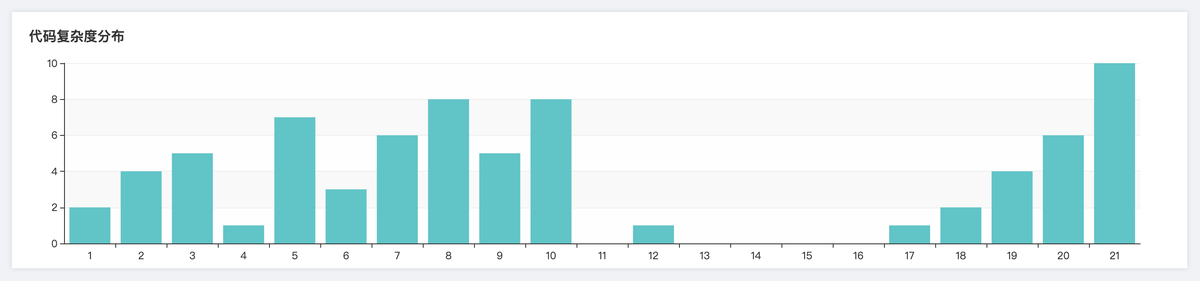
代码复杂度文件分布
统计各复杂度分布的函数数量。
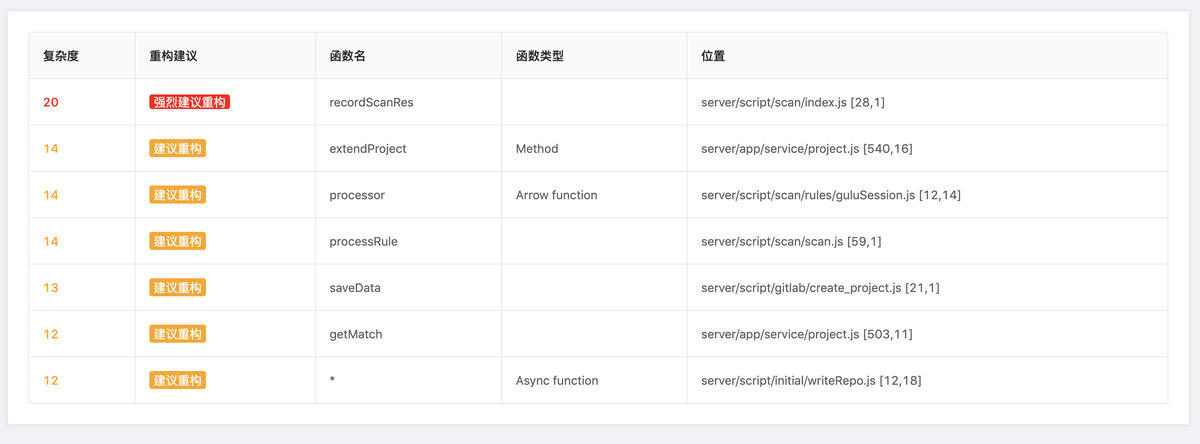
代码复杂度文件详情
计算每个函数的代码复杂度,从高到低依次列出高复杂度的文件分布,并给出重构建议。
实际开发中并不一定所有的代码都需要被分析,例如打包产物、静态资源文件等等,这些文件往往会误导我们的分析结果,现在分析工具会默认忽略一些规则,例如:.gitignore文件、static目录等等,实际这些规则还需要根据实际项目的情况去不断完善,使分析结果变得更准确。
参考
- 加推研发质量与规范实战
- codescene
- 圈复杂度那些事儿-前端代码质量系列文章(二)
- 代码质量管控 – 复杂度检测
- 详解圈复杂度


![[曾经沧海难为水]两数求和](https://img-blog.csdnimg.cn/img_convert/694de670f35d2adebf111c7f32fae7c1.png)