问题
3月1日监控系统监测到某子系统所在机器Cpu突然飙升。
排查系统
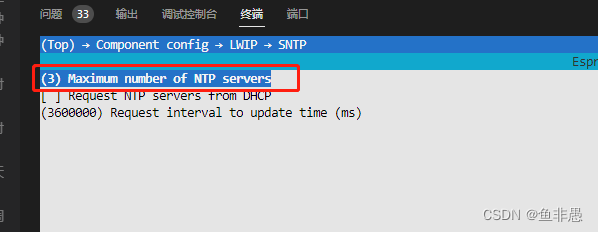
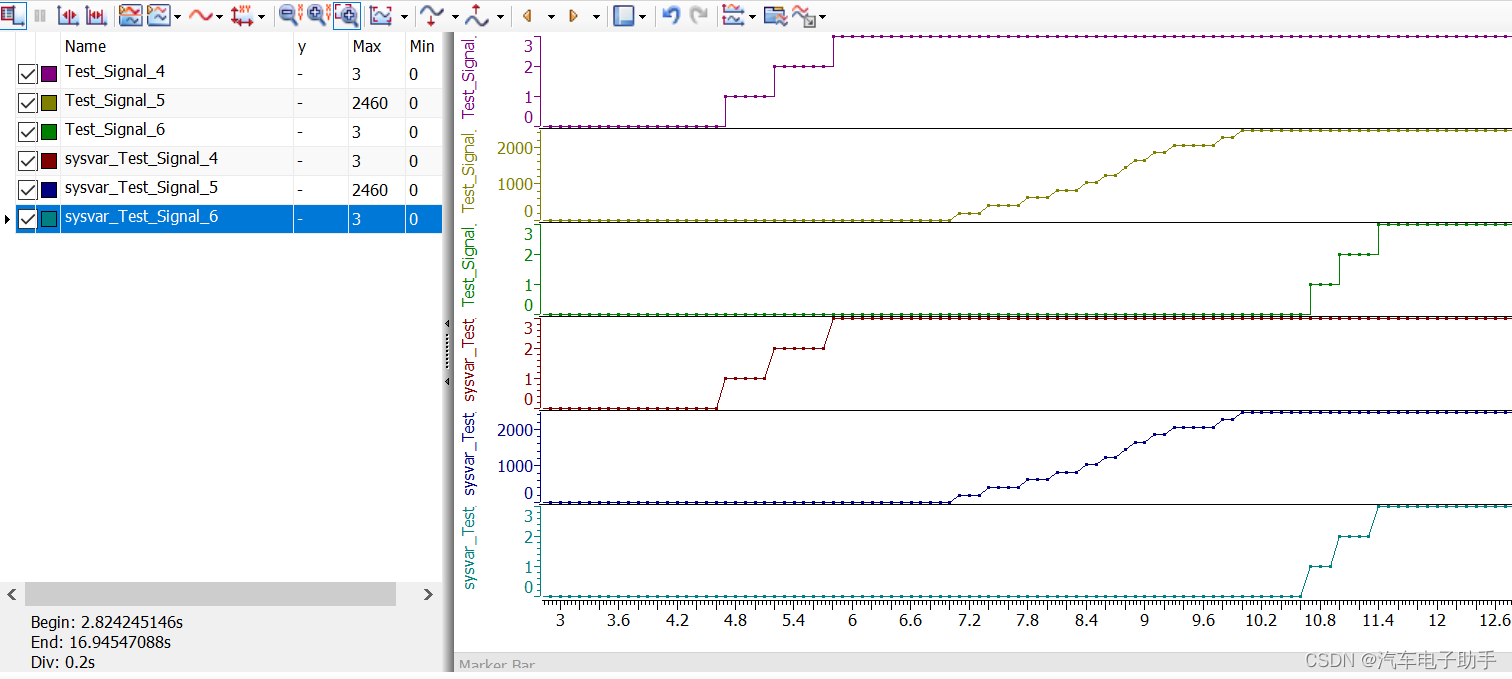
首先登录对应系统的机器,top查看机器信息,显示当前cpu已经到了800%
top 显示800%
根据top的pid查看对应服务,查看服务子进程
排查子线程,发现子线程有8个都100%了,然后查看java服务

ps-ef | grep tomcat
找到对应服务
打印服务的栈信息
jstack pid > pid.log

打印服务的主线程的Pid的栈信息,子进程的栈信息输出会有问题,输出的信息没有参考价值
sun.jvm.hotspot.debugger.DebuggerException: get_thread_regs failed for a lwp
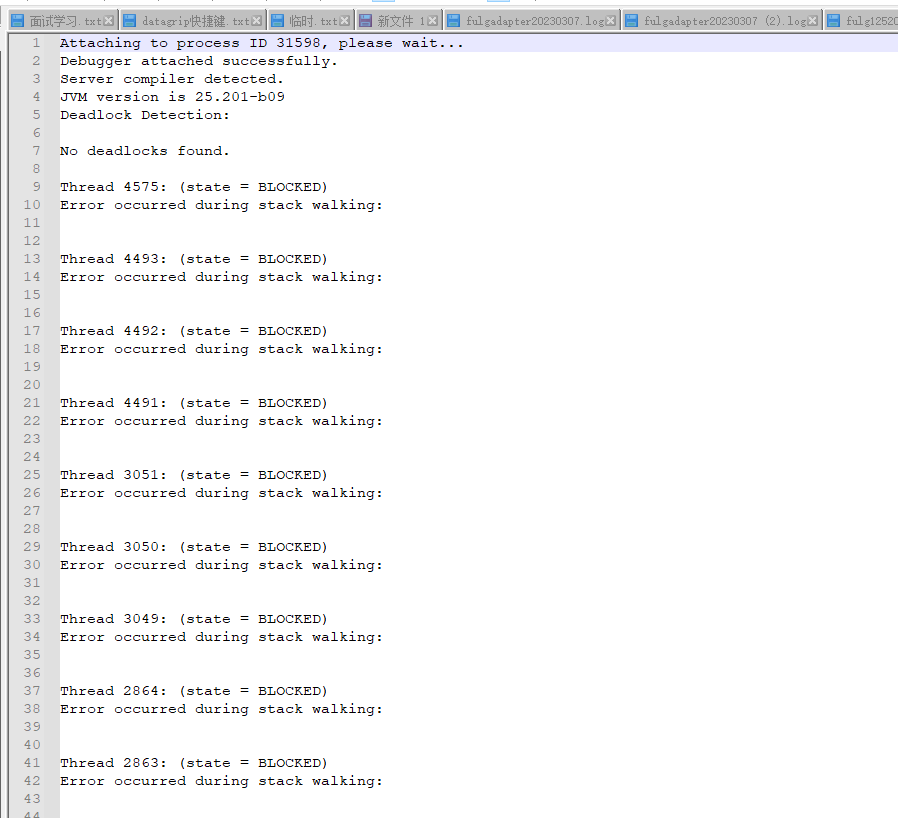
分析主线程的栈信息异常发现有一直在GC,日志中大量输出redis timeout ,初步认为是大量连接redis超时导致创建线程过多,导致最终OutOfMemoryError
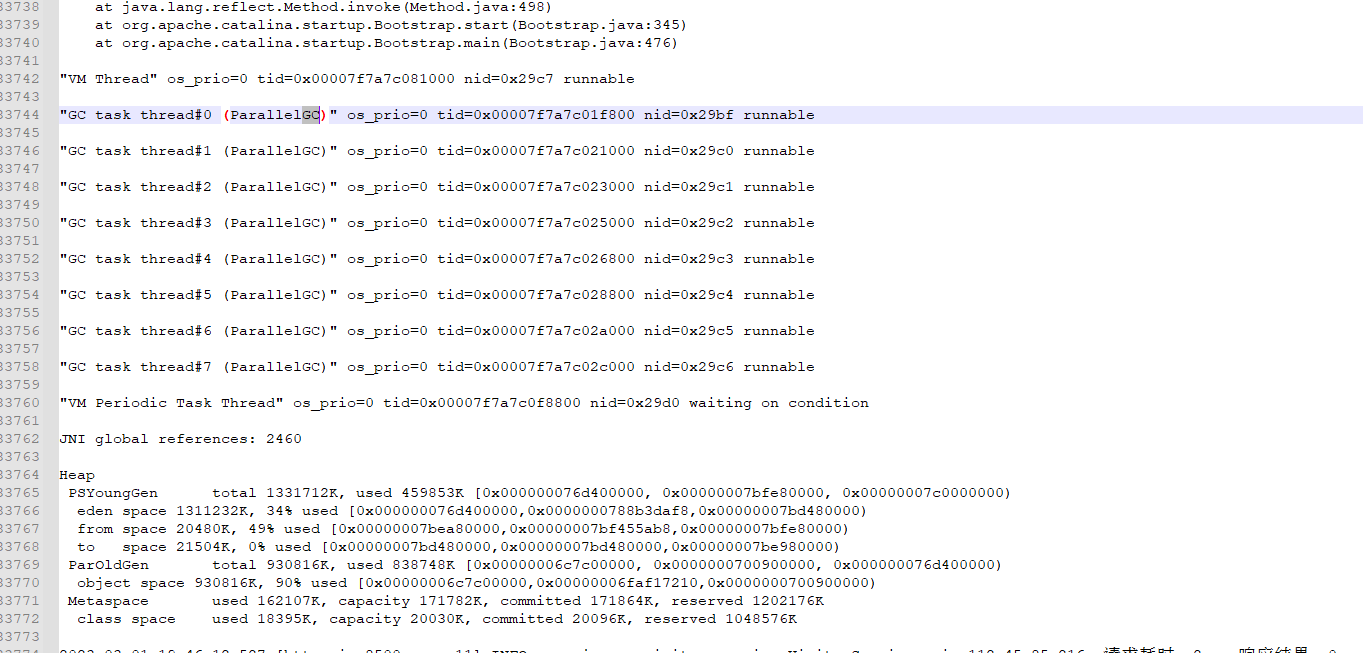
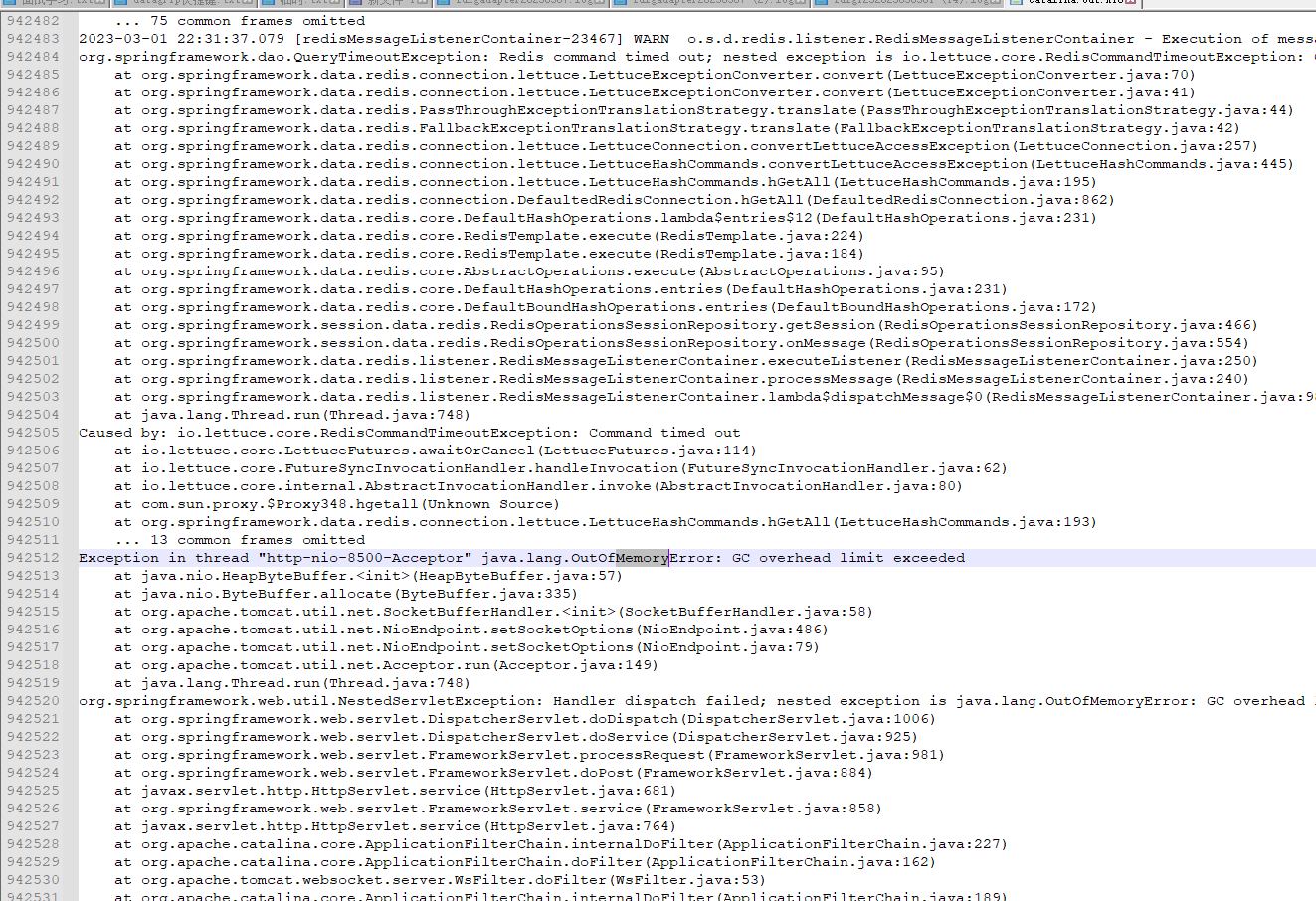
停止服务进程,重启服务,观察运行,服务正常运行,第二天中午吃饭时间,突然监控系统再次发出cpu告警,在输出栈信息,信息与之前基本相同,还是没有实质性进展,先保存现场恢复正常服务于;
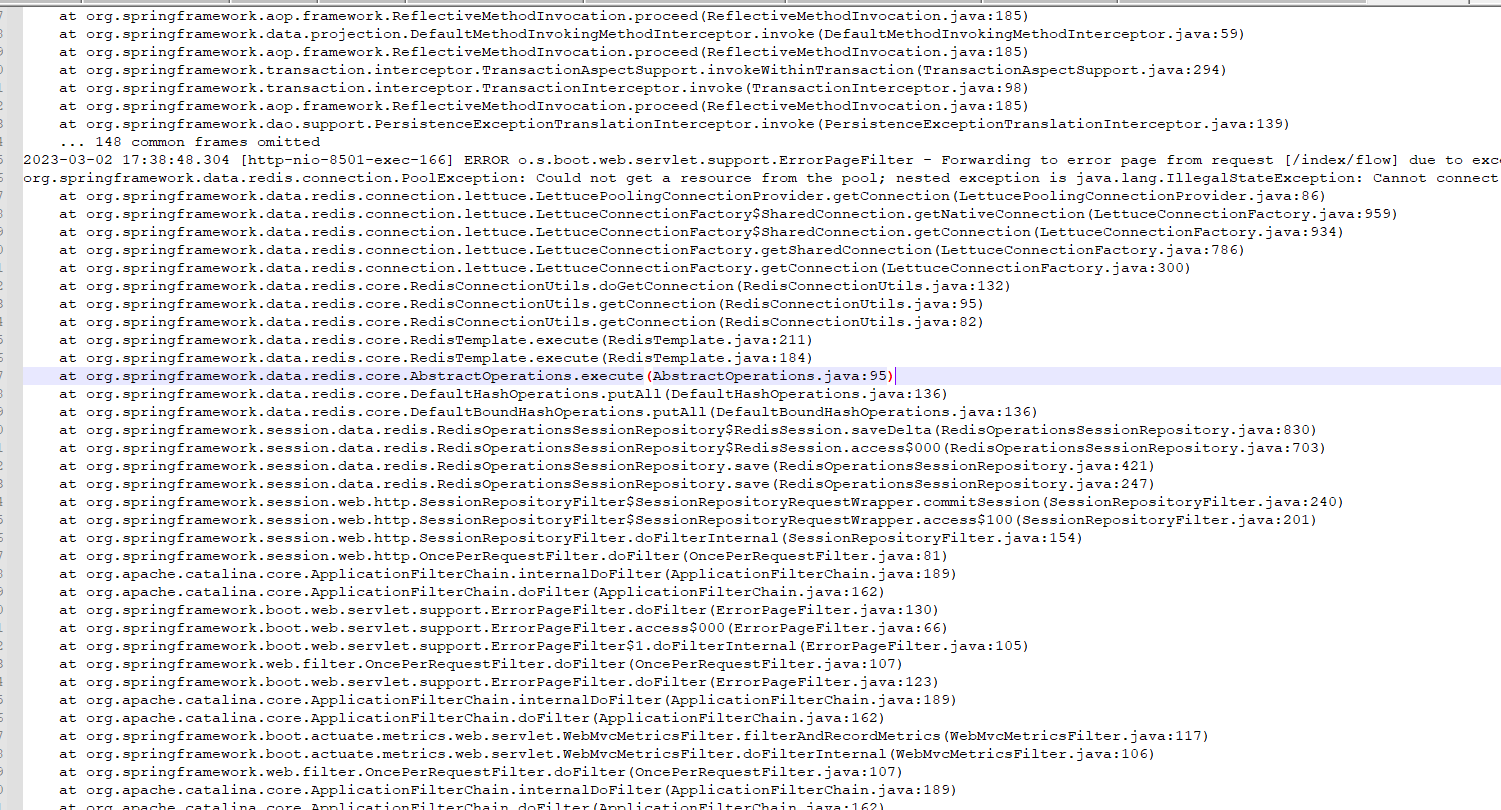
运维同时反馈有操作后导致服务宕机,联系运维同事,重新启动项一个节点服务,触发运维同事操作,发现新节点宕机,根据运维同事操作,输入详细日志信息,同时dump内存信息(服务节点dump内存信息太大),然后分析代码,发现在一处获取菜单处产生大量对象且无法回收,继续增加日志,输出菜单的详细信息,同时根据代码发现存在递归获取信息
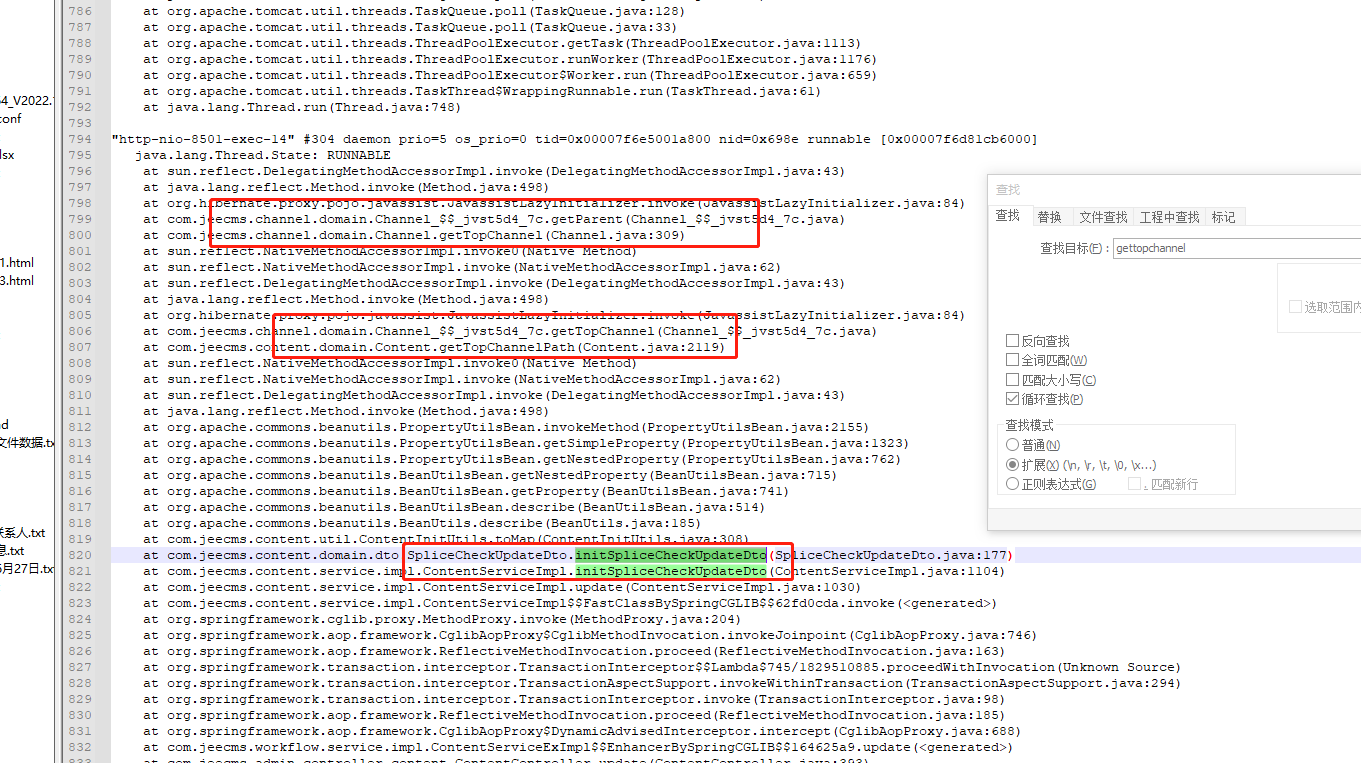
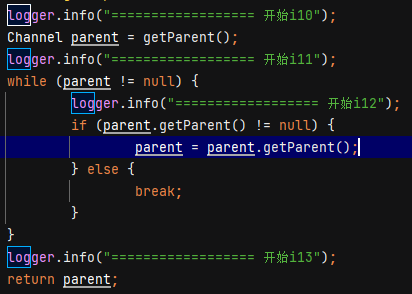
然后再根据日志数据的取查看数据库,实际菜单数据只有不到一千条,日志输出的获取i12的行数数十万行,可以确定是在获取菜单这里形成死循环了,再次增加日志输出这里获取菜单的数据,根据日志输出排查数据库,找到异常数据:第一级菜单的父级菜单应该是null,数据库的最新值是一个四级菜单,修改异常数据,等待数据库缓存刷新,再次触发操作,操作正常,服务正常。

处理遗留问题
系统恢复正常后,跟领导确认,去掉全部运维账号的菜单权限,防止此类问题以后再次出现
排查数据库接口操作记录,确定运维同学是在前一天下午的18点修改的菜单数据,至此问题解决。
复盘
代码中慎用递归,尤其是线上环境
线上环境一定要设置oom自动保存信息