集合(内存)中创建 RDD
外部存储(文件)创建 RDD
并行与分区
分区的设定
集合(内存)中创建 RDD
从集合中创建 RDD,Spark 主要提供了两个方法:parallelize 和 makeRDD,从底层代码实现来讲,makeRDD 方法其实就是 parallelize 方法
parallelize方法代表并行处理
def main(args: Array[String]): Unit = {
//准备环境
//"*"代表线程的核数 应用程序名称"RDD"
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD")
val sc = new SparkContext(sparkConf)
//创建RDD
//从内存中创建RDD 将内存中集合的数据最为处理的数据源
//定义一个集合
val seq = Seq[Int](1,2,3,4,5,6,7)
//val rdd: RDD[Int] = sc.parallelize(seq)
val rdd: RDD[Int] = sc.makeRDD(seq)
rdd.collect().foreach(println)
//关闭环境
sc.stop()
}外部存储(文件)创建 RDD
def main(args: Array[String]): Unit = {
//准备环境
//"*"代表线程的核数 应用程序名称"RDD"
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD")
val sc = new SparkContext(sparkConf)
//创建RDD
//从文件中创建RDD 将文件中的数据最为处理的数据源
//path路径默认以当前环境的根路径为基准。可以写绝对路径也可以写相对路径
//也可以是目录名
//也可以是分布式路径HDFS
//sc.textFile("D:\\spark.test\\datas")
val rdd: RDD[String] = sc.textFile("datas\\a.txt")
rdd.collect().foreach(println)
//关闭环境
sc.stop()
}读取目录是如果想知道具体文件来源于哪个文件用wholeTextFiles方法
def main(args: Array[String]): Unit = {
//准备环境
//"*"代表线程的核数 应用程序名称"RDD"
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD")
val sc = new SparkContext(sparkConf)
//创建RDD
//从文件中创建RDD 将文件中的数据最为处理的数据源
//wholeTextFiles方法读取的内容为元组 第一个参数表路径 第二个参数为文件内容
val rdd: RDD[(String, String)] = sc.wholeTextFiles("datas")//以文件为单位读取数据
rdd.collect().foreach(println)
//关闭环境
sc.stop()
}
并行与分区
默认情况下,Spark 可以将一个作业切分多个任务后,发送给 Executor 节点并行计算,而能 够并行计算的任务数量我们称之为并行度。这个数量可以在构建 RDD 时指定。记住,这里 的并行执行的任务数量,并不是指的切分任务的数量,不要混淆了。
def main(args: Array[String]): Unit = {
//准备环境
//"*"代表线程的核数 应用程序名称"RDD"
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD")
val sc = new SparkContext(sparkConf)
//创建RDD
//RDD并行度&分区 makeRDD(集合,切片数量)
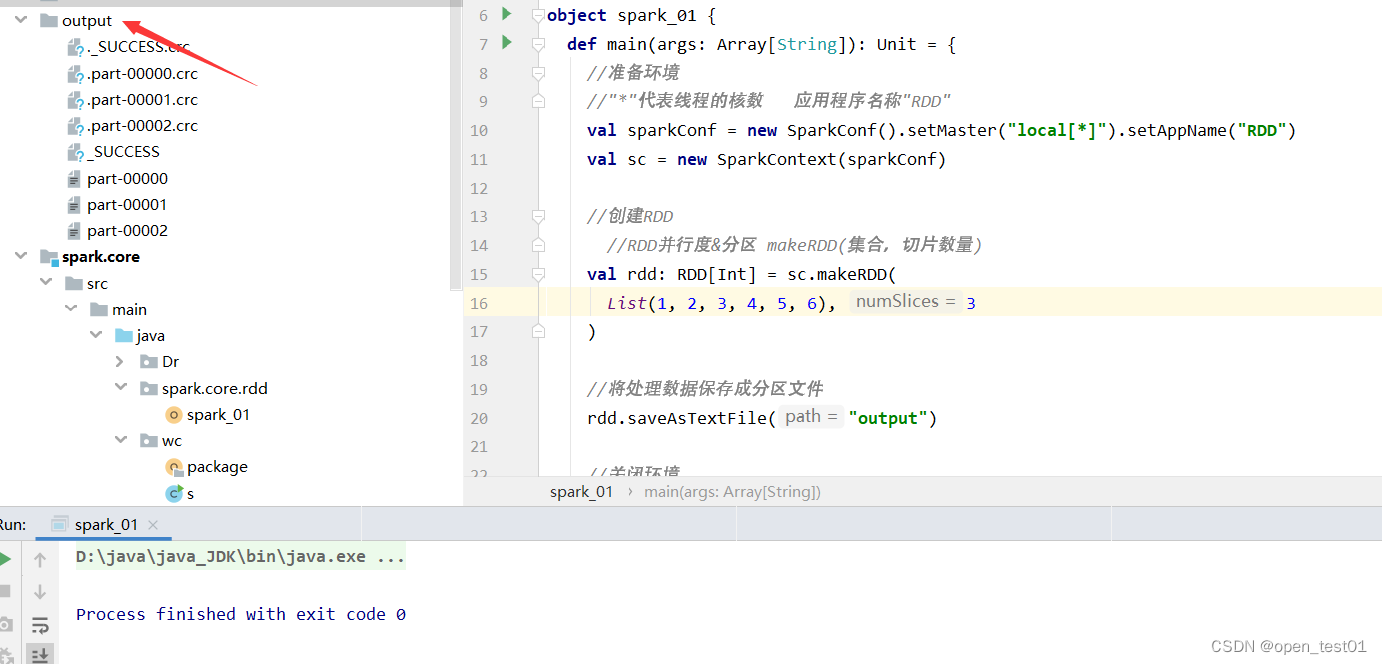
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4, 5, 6), 3)
//将处理数据保存成分区文件
rdd.saveAsTextFile("output")
//关闭环境
sc.stop()运行结束后产生的分区文件在output目录 中
分区的设定
def main(args: Array[String]): Unit = {
//准备环境
//"*"代表线程的核数 应用程序名称"RDD"
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD")
val sc = new SparkContext(sparkConf)
//创建RDD
//textFile可以将文件作为数据处理的数据源,默认也可以设定分区 textFile(路径,分区数量)
//minPartitions:最小分区数量 默认分区为2
val rdd: RDD[String] = sc.textFile("datas\\a.txt",3)
rdd.saveAsTextFile("output")
//关闭环境
sc.stop()
}分区数据的分配
- 数据以行为单位进行读取 spark采用hadoop的方式读取数据
- 数据读取时以偏移量为单位 偏移量不会被重复读取
- 数据分区的偏移量范围的计算 行=>[行第一个元素偏移量,结尾不包含元素的偏移量 ]