1. 运行环境
windows11 和 Ubuntu20.04(建议使用 Linux 系统)
首先切换到自己建立的虚拟环境安装 pytorch
torch 1.12.0+cu116(根据自身设备而定)
torchvision 0.13.0+cu116(根据自身设备而定)
安装完成后,使用 git 命令将源码克隆下来
git clone https://github.com/ultralytics/ultralytics.git
参照官网,直接使用以下语句即可导入项目所需要的库
pip install ultralytics
根据官方的解释,pip 的 ultralytics 库包含了 requirements.txt中的所有库
2. 自定义数据集
我自己准备了一批 熊猫、老虎的图片作为实验数据集,文件夹命名为 data (文件路径:/home/mango/ultralytics/data),文件夹的整体目录结构如下
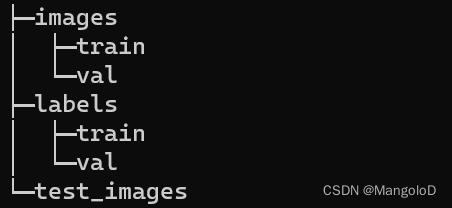
images 下包含 train、val 文件夹,这两个文件夹下包含此次需要的 图片信息
labels 下包含 train、val 文件夹,这两个文件夹下包含此次需要的 对应图片的标注信息
test_images 下包含的是提供测试的数据集
3. 模型训练(四种方式)
首先在 data 文件夹下新建一个 animal.yaml 文件
train: /home/mango/ultralytics/data//images/train
val: /home/mango/ultralytics/data/images/val
# number of classes
nc: 2
# class names
names: ['panda', 'tiger']
接下来就可以准备开始训练了
打开终端,进入虚拟环境,进入yolov8的文件夹,
考虑到命令行模式下下载模型可能有点慢,所以先在官方仓库下载好模型,并放入新建的 weights (文件路径:/home/mango/ultralytics/weights)目录下,
(1) 第一种方式(参数重写)
参数很多,建议查看 官网文档
下面是yolov8官方给定的命令行训练/预测/验证/导出方式:
yolo task=detect mode=train model=yolov8n.pt args...
classify predict yolov8n-cls.yaml args...
segment val yolov8n-seg.yaml args...
export yolov8n.pt format=onnx args...
最后输入以下命令即可开始训练(参数很多可以修改,建议查看官网文档,或者查看/home/mango/ultralytics/ultralytics/yolo/cfg下的 default.yaml 文件)
yolo task=detect mode=train model=weights/yolov8n.pt data=data/animal.yaml batch=16 epochs=50 imgsz=640 workers=16 device=0
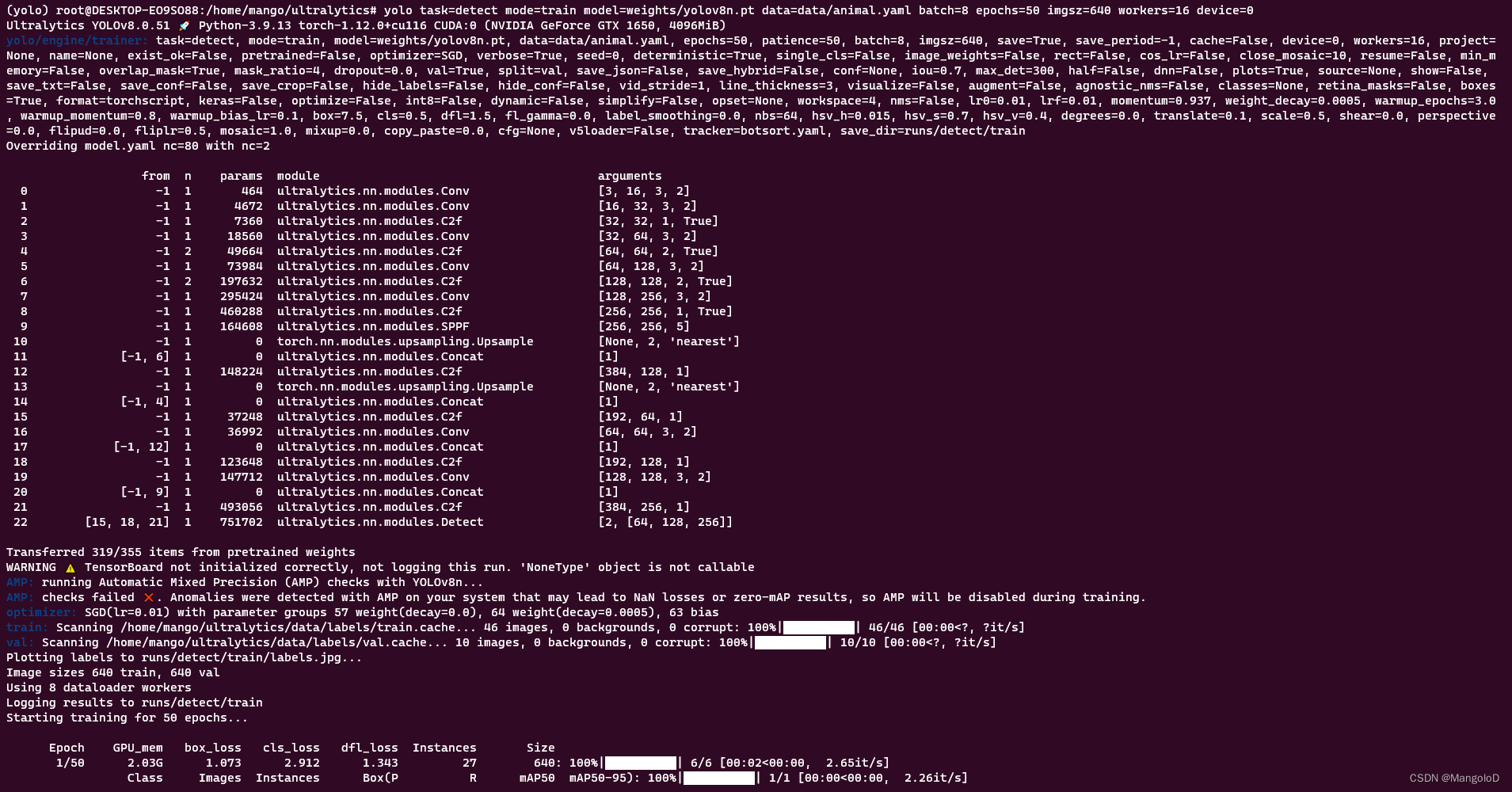
可以看到已经成功开始训练,运行生成的权重、混淆矩阵等信息存在于/home/mango/ultralytics/runs 下面
(2) 第二种方式(重写配置文件)
可以新建一个配置文件,例如:demo.yaml,参数配置内容从 /home/mango/ultralytics/ultralytics/yolo/cfg/default.yaml 复制即可
或者使用命令行
yolo copy-cfg
它会自动生成一个 default_copy.yaml (目录地址:/home/mango/ultralytics/default_copy.yaml)
截取的部分参数信息如下:
# Ultralytics YOLO 🚀, GPL-3.0 license
# Default training settings and hyperparameters for medium-augmentation COCO training
task: detect # inference task, i.e. detect, segment, classify
mode: train # YOLO mode, i.e. train, val, predict, export
# Train settings -------------------------------------------------------------------------------------------------------
model: # path to model file, i.e. yolov8n.pt, yolov8n.yaml
data: # path to data file, i.e. coco128.yaml
epochs: 100 # number of epochs to train for
patience: 50 # epochs to wait for no observable improvement for early stopping of training
batch: 16 # number of images per batch (-1 for AutoBatch)
imgsz: 640 # size of input images as integer or w,h
save: True # save train checkpoints and predict results
save_period: -1 # Save checkpoint every x epochs (disabled if < 1)
cache: False # True/ram, disk or False. Use cache for data loading
device: # device to run on, i.e. cuda device=0 or device=0,1,2,3 or device=cpu
workers: 8 # number of worker threads for data loading (per RANK if DDP)
project: # project name
name: # experiment name
...
...
根据自身需求,修改相应参数,例如:修改 model、data、epochs、batch
model: weights/yolov8n.pt # path to model file, i.e. yolov8n.pt, yolov8n.yaml
data: data/animal.yaml # path to data file, i.e. coco128.yaml
epochs: 20 # number of epochs to train for
batch: 8 # number of images per batch (-1 for AutoBatch)
然后在终端输入下列代码行命令即可开始训练
yolo cfg=default_copy.yaml
ps: 还可以使用 yolo cfg=default_copy.yaml imgsz=320 batch=8 的方式修改 imgz、batch 等参数信息
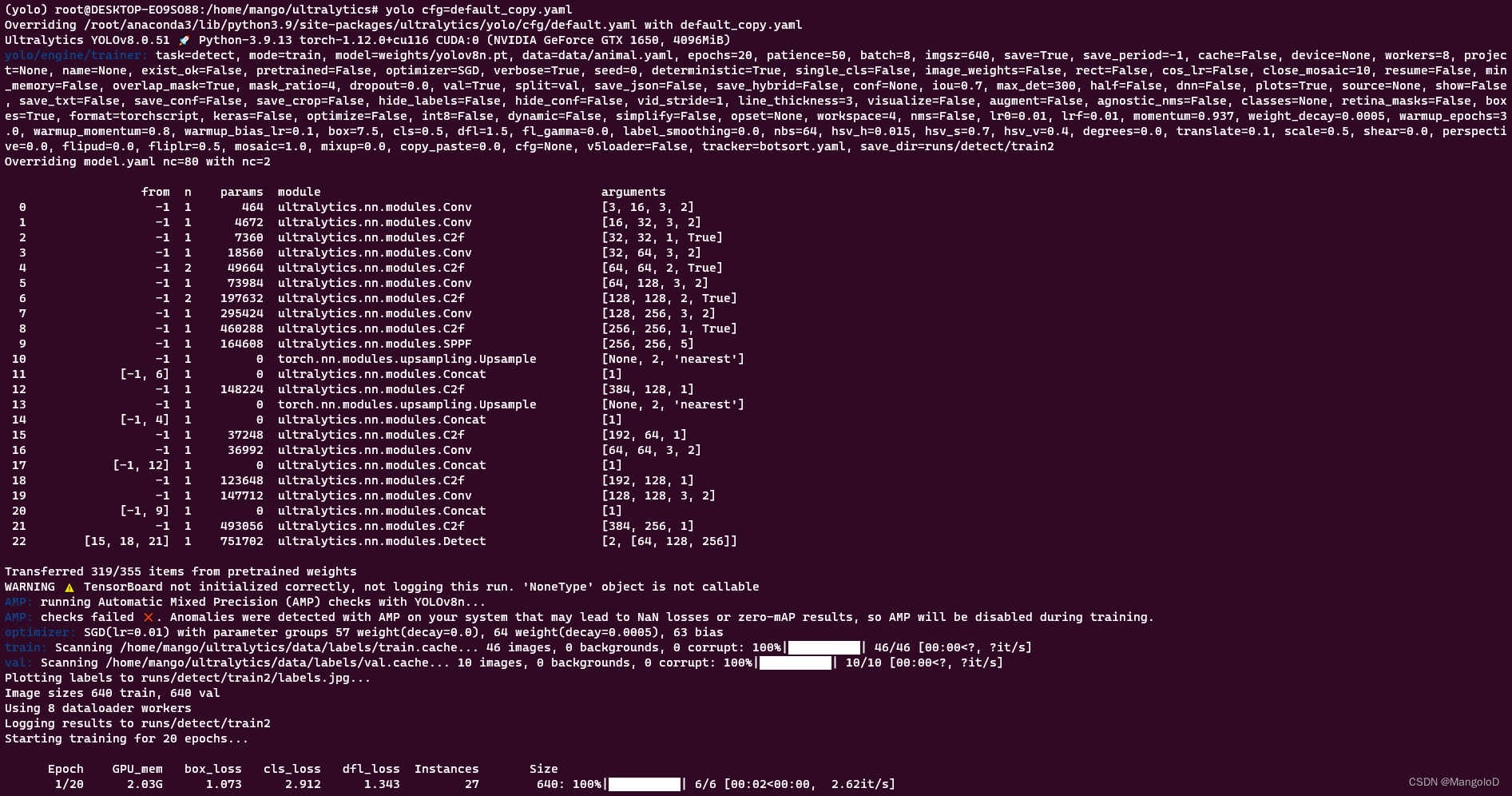
可以看到也已经成功开始训练,运行生成的权重、混淆矩阵等信息存在于/home/mango/ultralytics/runs 下面
(3) 第三种方式(python命令)
在 Python 环境中直接使用
from ultralytics import YOLO
# 加载模型
# model = YOLO("yolov8n.yaml") # 从头开始构建新模型
model = YOLO("weights/yolov8n.pt") # 加载预训练模型(推荐用于训练)
# Use the model
results = model.train(data="data/animal.yaml", epochs=20, batch=8) # 训练模型
或者创建一个 demo.py, 将上述代码拷贝到 demo.py,然后调用 python demo.py 即可
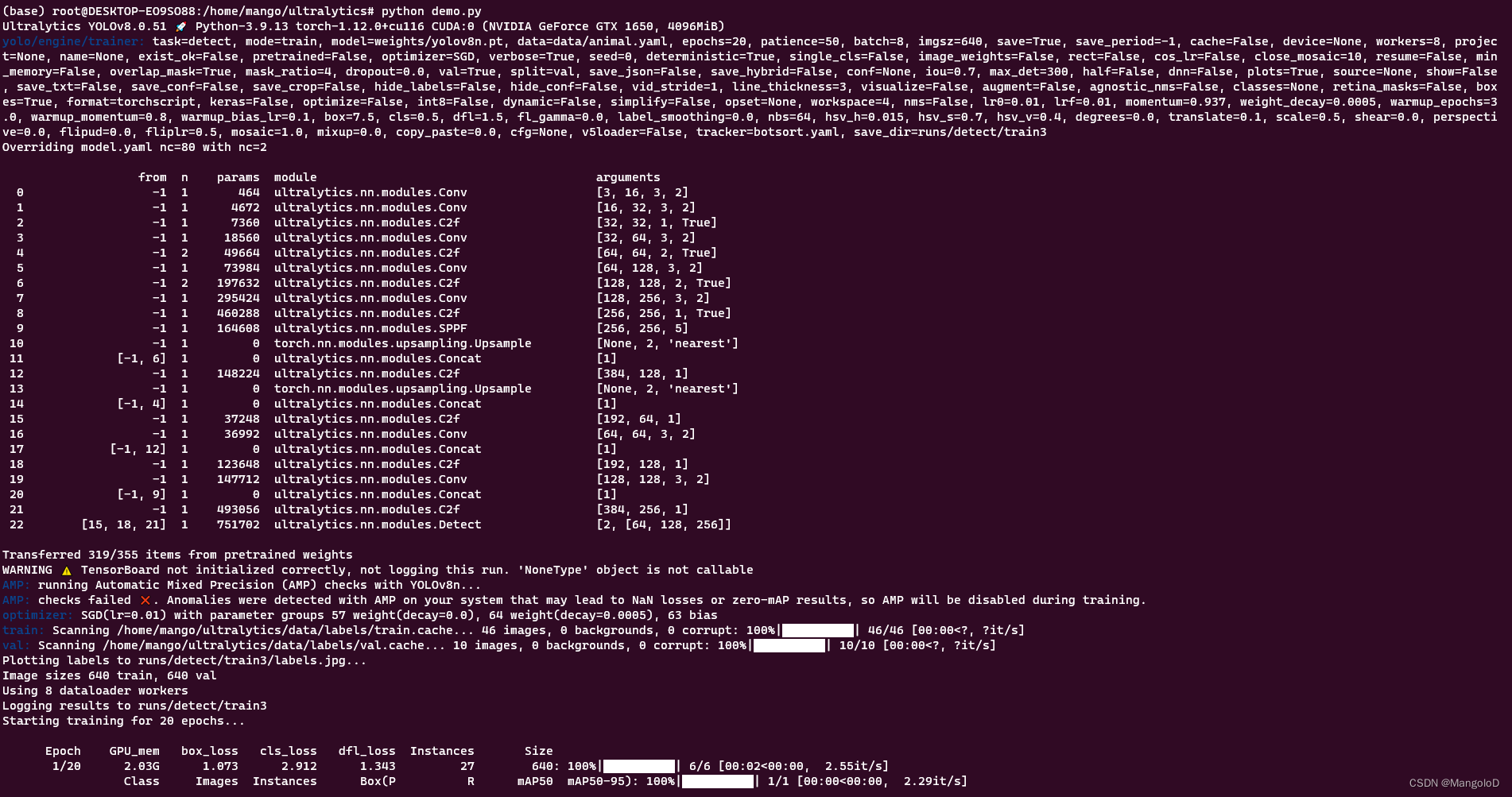
可以看到也已经成功开始训练,运行生成的权重、混淆矩阵等信息存在于/home/mango/ultralytics/runs 下面
(4) 第四种方式(python文件调用)
进入 /home/mango/ultralytics/ultralytics/yolo 目录下,复制 animal.yaml、yolov8n.pt 到 /home/mango/ultralytics/ultralytics/yolo/v8/detect 目录,
修改 /home/mango/ultralytics/ultralytics/yolo/cfg/default.yaml 的 model、data 路径及其他参数信息
# Ultralytics YOLO 🚀, GPL-3.0 license
# Default training settings and hyperparameters for medium-augmentation COCO training
task: detect # inference task, i.e. detect, segment, classify
mode: train # YOLO mode, i.e. train, val, predict, export
# Train settings -------------------------------------------------------------------------------------------------------
model: yolov8n.pt # path to model file, i.e. yolov8n.pt, yolov8n.yaml
data: animal.yaml # path to data file, i.e. coco128.yaml
epochs: 100 # number of epochs to train for
patience: 50 # epochs to wait for no observable improvement for early stopping of training
batch: 16 # number of images per batch (-1 for AutoBatch)
imgsz: 640 # size of input images as integer or w,h
save: True # save train checkpoints and predict results
save_period: -1 # Save checkpoint every x epochs (disabled if < 1)
cache: False # True/ram, disk or False. Use cache for data loading
device: # device to run on, i.e. cuda device=0 or device=0,1,2,3 or device=cpu
workers: 8 # number of worker threads for data loading (per RANK if DDP)
运行 train.py
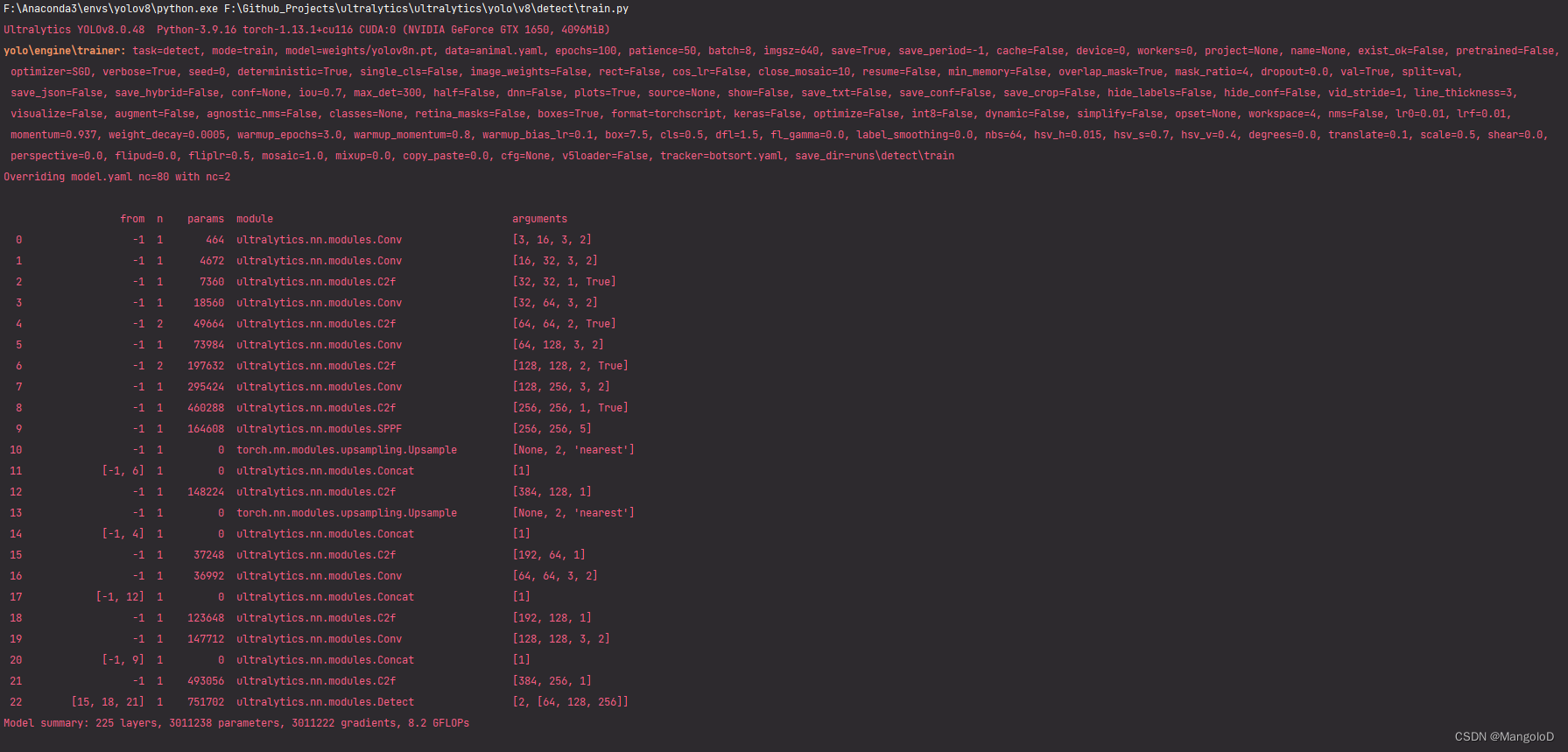
可以看到也已经成功开始训练,运行生成的权重、混淆矩阵等信息存在于/home/mango/ultralytics/yolo/v8/detect/runs 下面
4. 模型预测
可修改的参数很多,建议查看 官网文档
和模型训练一样,预测同样可以采用不同的方式去实现,这里展示其中一种方法,主要目前还是看看模型效果
将训练得到的 best.pt 复制到 /home/mango/ultralytics/weights 下,执行如下指令
yolo detect predict model=weights/best.pt source=data/test_images save=True
结果如下:





最后一张图没有检测好,估计是跟我训练数据集数量有关系(总共40+张),还有一个就是训练轮次(50轮,花了不到2分钟时间😂)
👍 但总体来说,效果还是可以的,速度精度都不低 🔥
5. 最后
🚀 接下来准备试试 onnx、和 TensorRT 的部署 ❗️