文章目录
- DeepVideo
- Two-Stream
- Beyond-short-Smippets
- Convolutional Fusion
- TSN
- C3D
- I3D
- Non-local
- R(2+1)D
- SlowFast
- Timesformer
本文是对视频理解领域论文串讲的笔记记录。
一篇相关综述:Yi Zhu, Xinyu Li, Chunhui Liu, Mohammadreza Zolfaghari, Yuanjun Xiong, Chongruo Wu, Zhi Zhang, Joseph Tighe, R. Manmatha, & Mu Li (2020). A Comprehensive Study of Deep Video Action Recognition… arXiv: Computer Vision and Pattern Recognition.
包括了大部分使用deep learning方法做action recognition的论文。
DeepVideo
Andrej Karpathy, George Toderici, Sanketh Shetty, Thomas Leung, Rahul Sukthankar, & Li Fei-Fei (2014). Large-Scale Video Classification with Convolutional Neural Networks Computer Vision and Pattern Recognition.
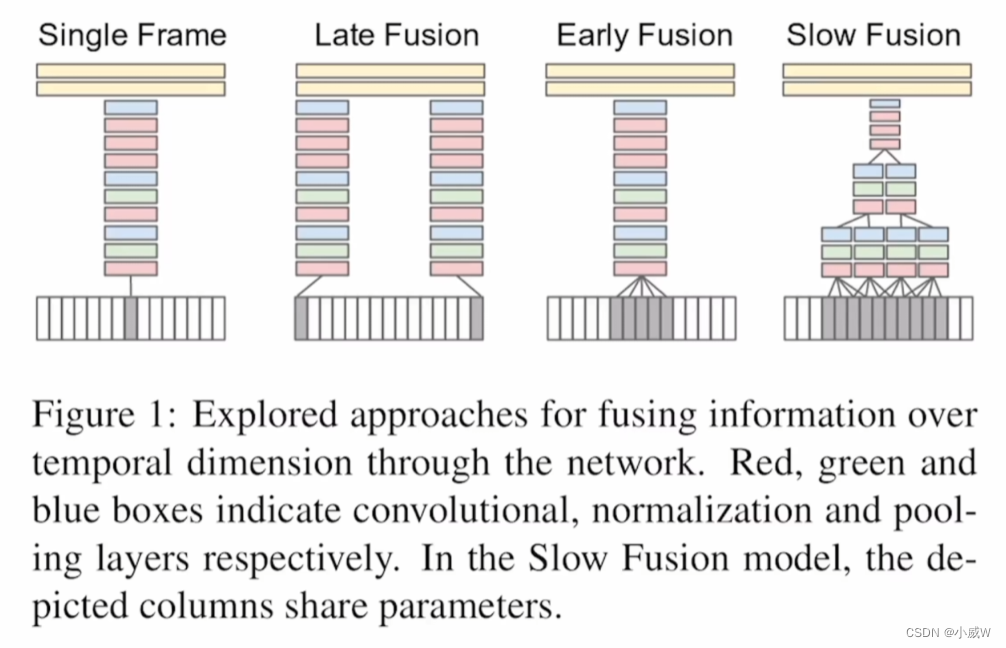
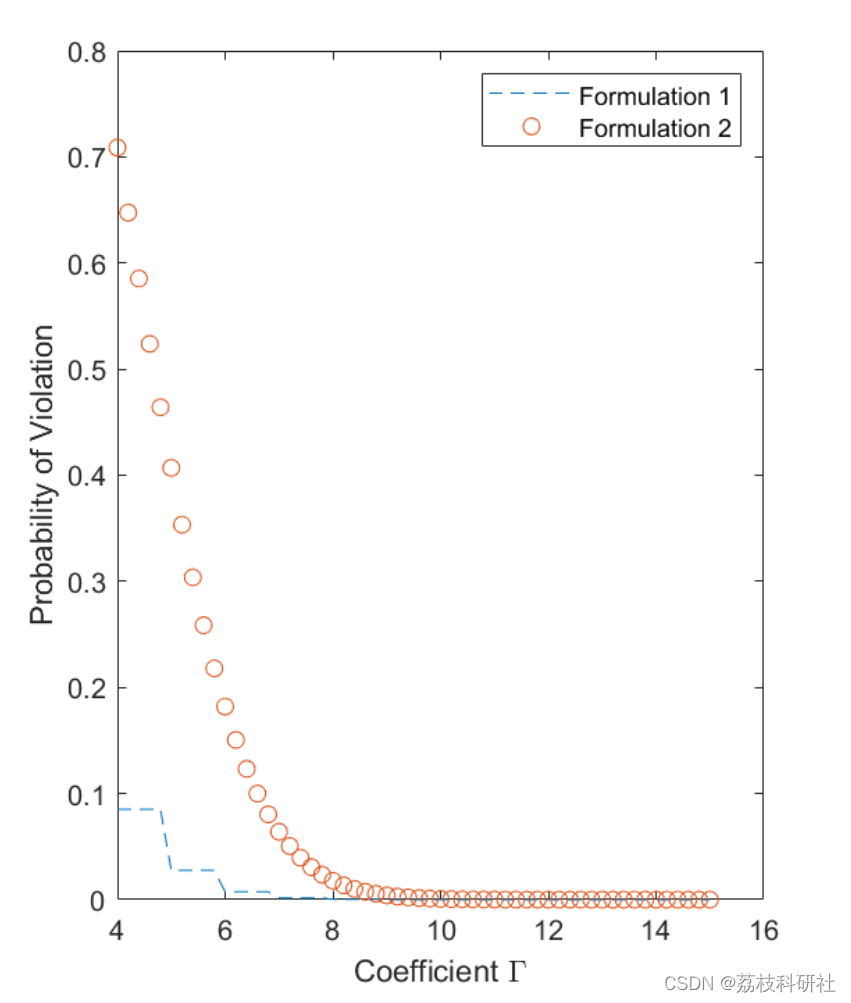
这四种方法中,最后一种方法最好,然而,还是没有之前手工提取特征的方法效果好。
因此,作者尝试寻找其它的方法:(多分辨率卷积神经网络)
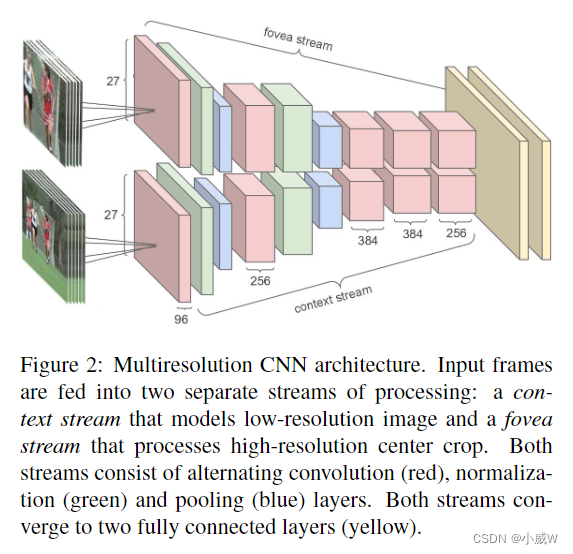
使用这样的操作,确实变好了一些,但提升相对较小。
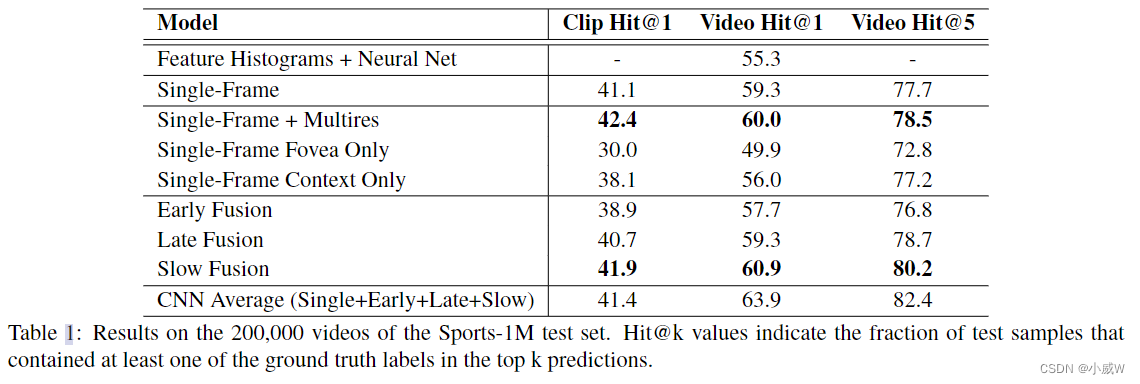
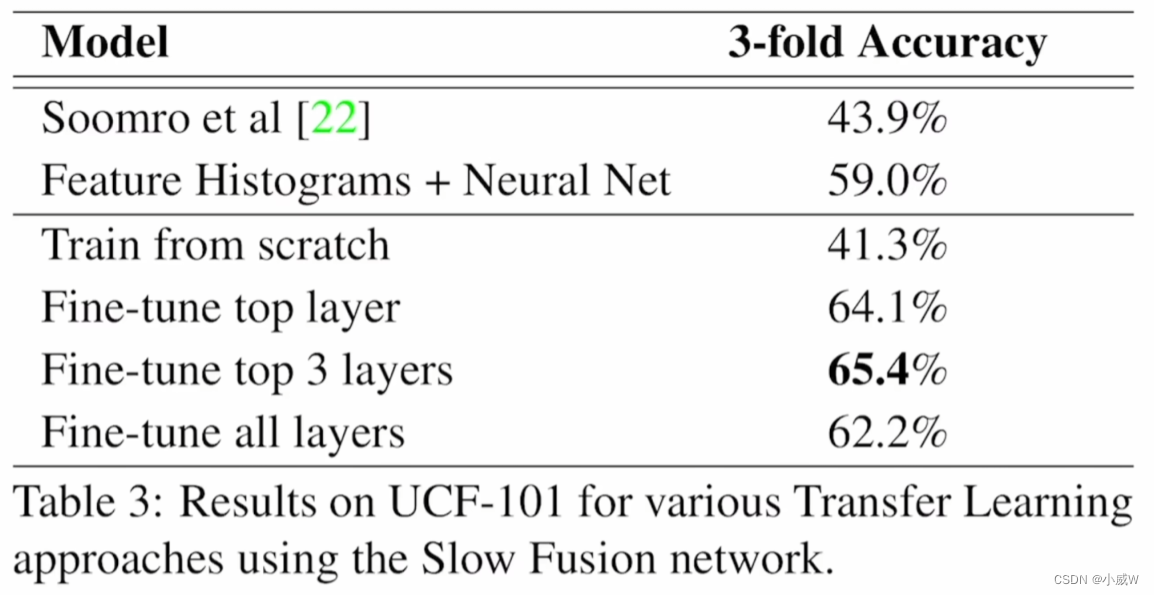
当时最好的手工特征在 UCF-101 上的 ac 已经有 87% 了。所以当时引起了大家的思考,为什么深度学习在视频理解领域不能像图像领域那样好。
Two-Stream
Karen Simonyan, & Andrew Zisserman (2014). Two-Stream Convolutional Networks for Action Recognition in Videos arXiv: Computer Vision and Pattern Recognition.
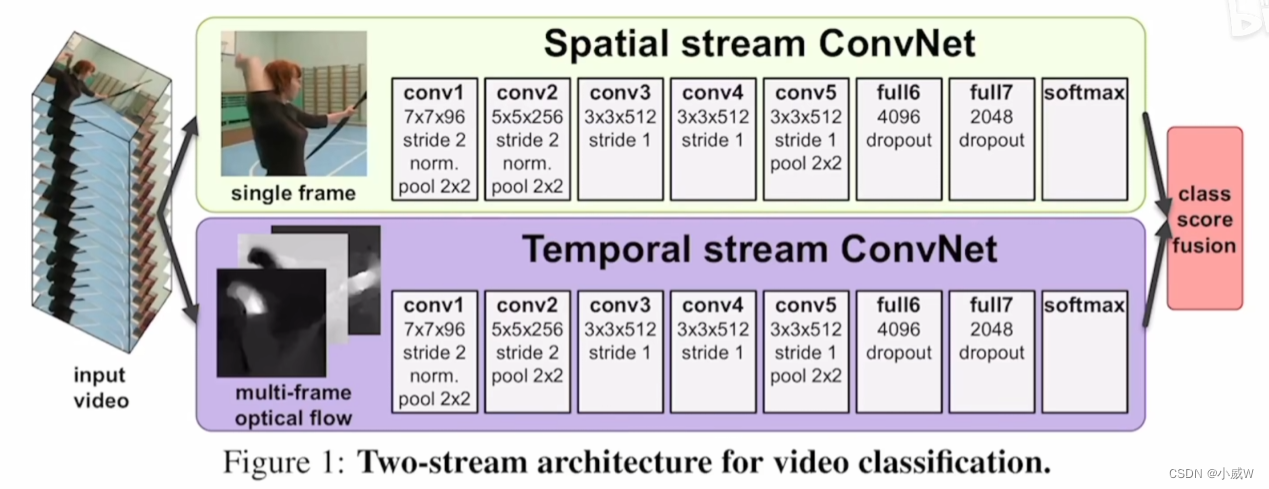
上面输入 RGB 图像;
下面输入光流图像。
最后softmax后简单加权平均。
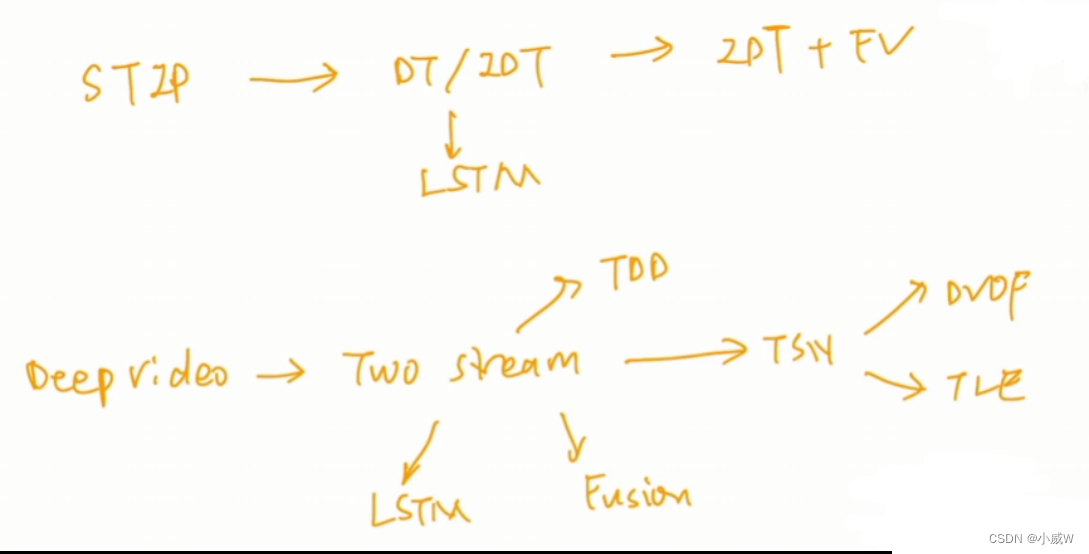
14-17年在双流网络上的发展:
Beyond-short-Smippets
Joe Yue-Hei Ng, Matthew Hausknecht, Sudheendra Vijayanarasimhan, Oriol Vinyals, Rajat Monga, & George Toderici (2015). Beyond Short Snippets: Deep Networks for Video Classification arXiv: Computer Vision and Pattern Recognition.
Convolutional Fusion
Christoph Feichtenhofer, Axel Pinz, & Andrew Zisserman (2016). Convolutional Two-Stream Network Fusion for Video Action Recognition arXiv: Computer Vision and Pattern Recognition.
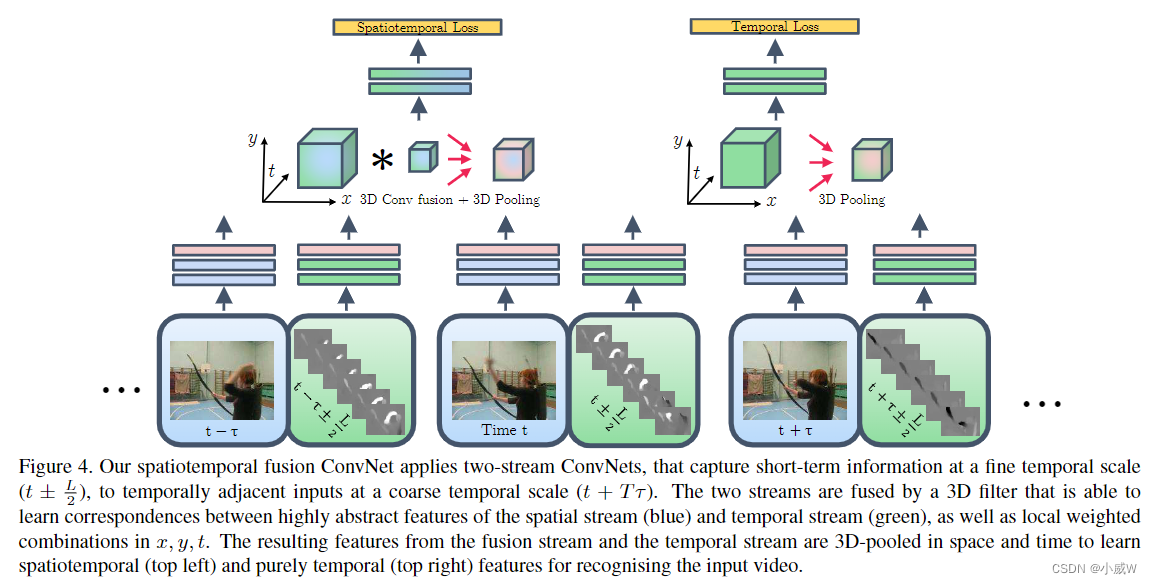
1.做了大量的消融实验,可以让大家少走很多弯路。
2.尝试了3D Conv和3D Pooling,变相地推动了 I3D 的出现。
TSN
Limin Wang, Yuanjun Xiong, Zhe Wang, Yu Qiao, Dahua Lin, Xiaoou Tang, & Luc Van Gool (2016). Temporal Segment Networks: Towards Good Practices for Deep Action Recognition
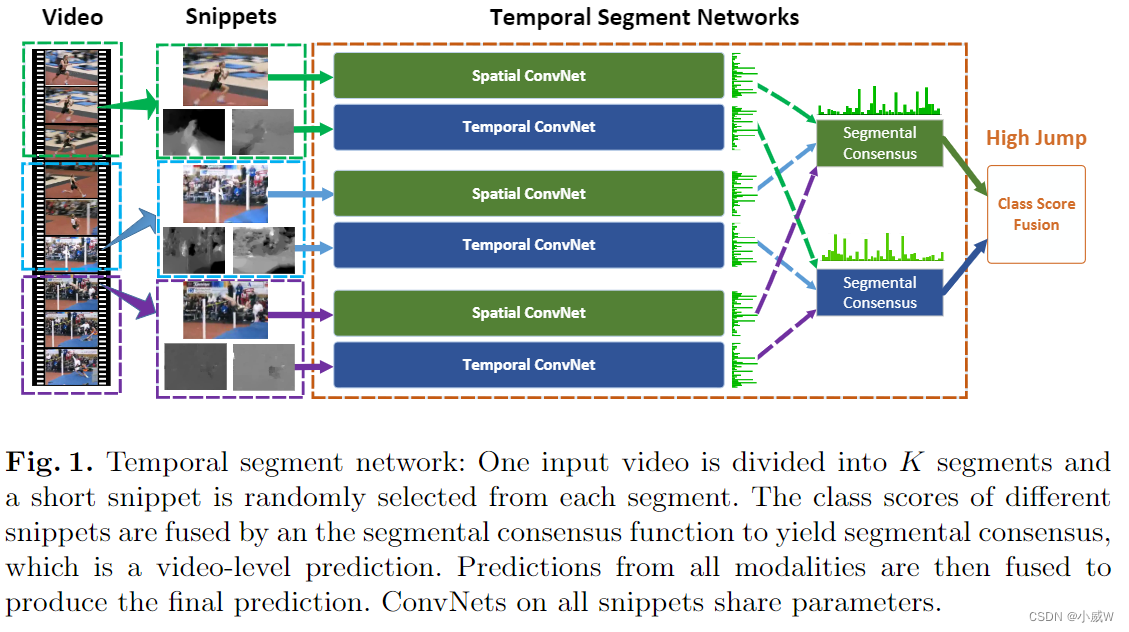
C3D
Du Tran, Lubomir Bourdev, Rob Fergus, Lorenzo Torresani, & Manohar Paluri (2014). Learning Spatiotemporal Features with 3D Convolutional Networks Cornell University - arXiv.
性能表现:

网络结构:(很像 vgg)

16:16个视频帧。
c3d特征:fc6抽出来的特征。
主要还是可以直接拿C3D来抽取特征。(因为别人训练不动)
I3D
Joao Carreira, & Andrew Zisserman (2017). Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset Computer Vision and Pattern Recognition.
- 降低了网络训练的难度
- 提出了一个很好的数据集
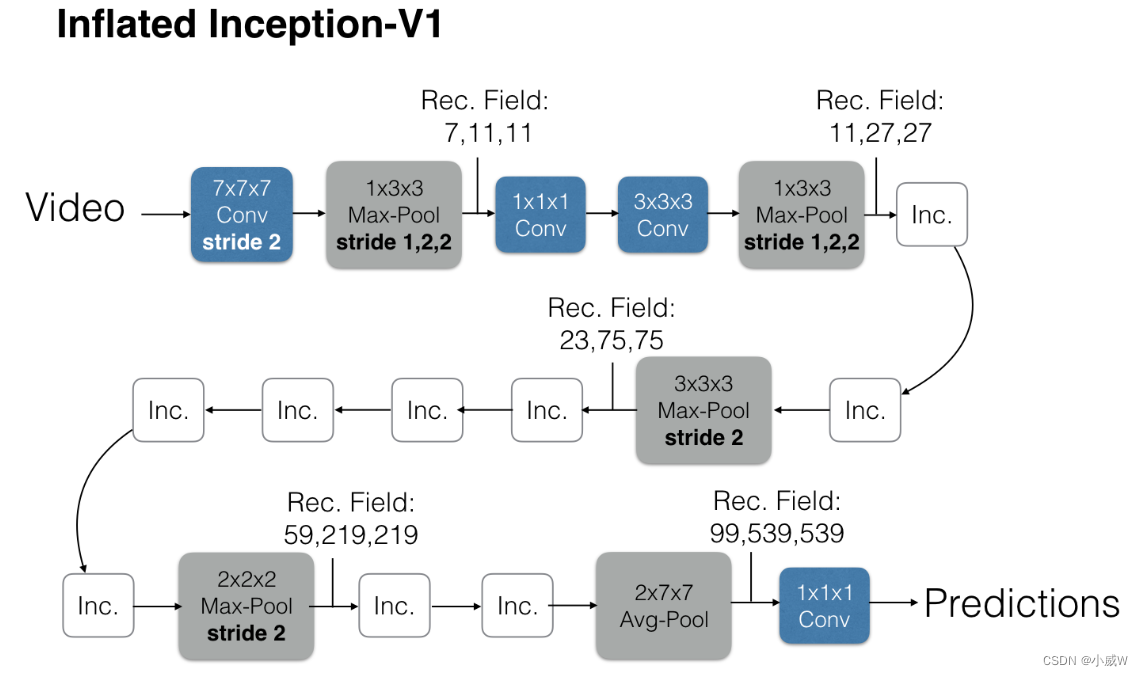
把一个2D的网络扩充成一个3D的网络。(可以很好得使用2d网络在imagenet上预训练好的参数)
证明了从2D网络到3D网络的有效性,比如后续的工作:

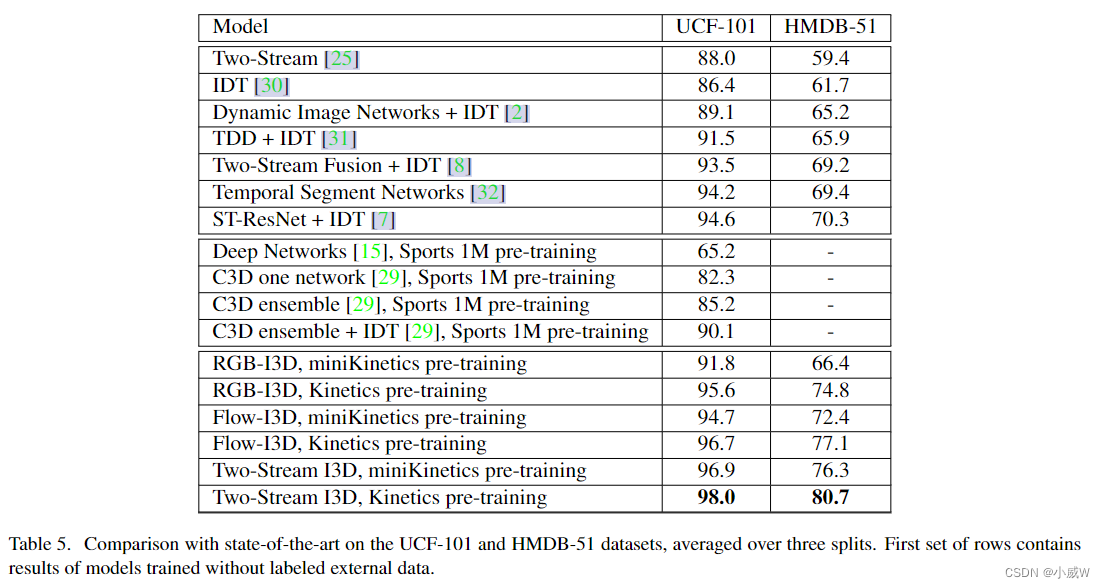
把UCF101和HMDB-51数据集刷爆了,以后就是Kinetics数据集了。
Non-local
Xiaolong Wang, Ross Girshick, Abhinav Gupta, & Kaiming He (2017). Non-local Neural Networks arXiv: Computer Vision and Pattern Recognition.
一个即插即用的模块,可以在很多任务上取得好的结果。
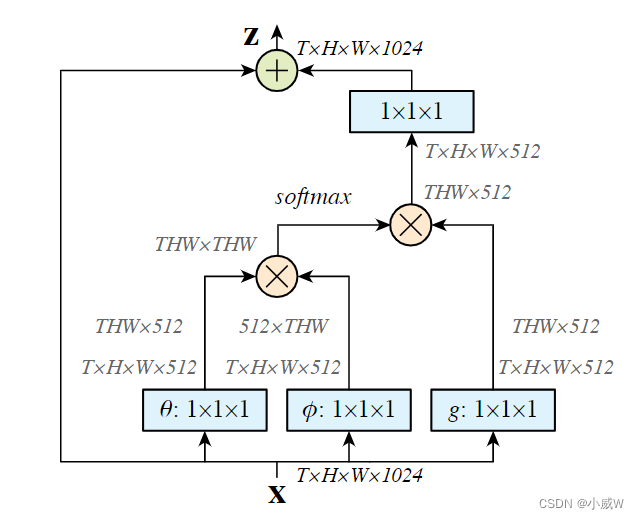
R(2+1)D
Du Tran, Heng Wang, Lorenzo Torresani, Jamie Ray, Yann LeCun, & Manohar Paluri (2017). A Closer Look at Spatiotemporal Convolutions for Action Recognition Cornell University - arXiv.
一篇非常实验性的论文。
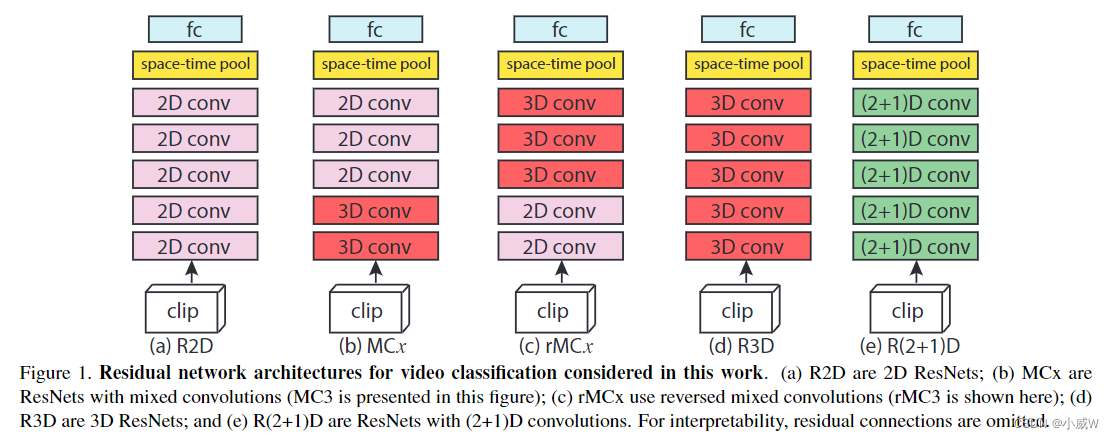
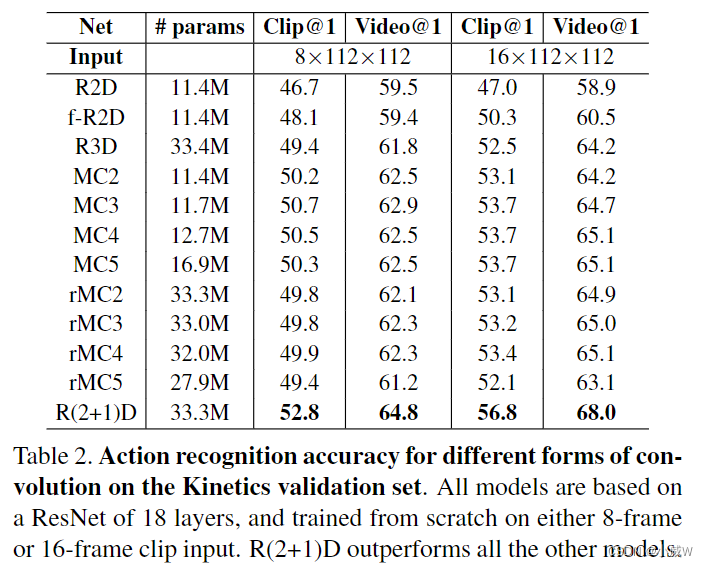
R(2+1)D这种结构的效果最好。
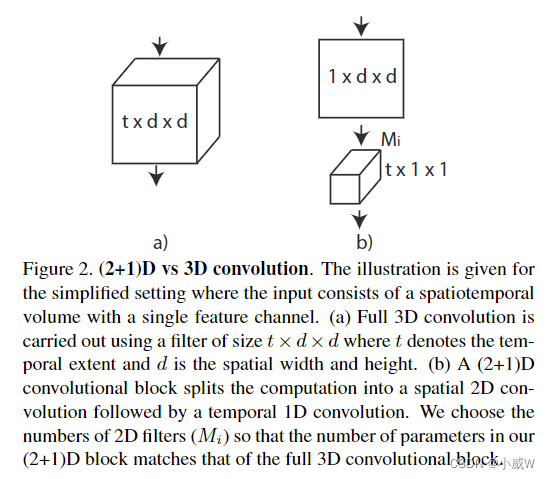
R(2+1)D的结构:
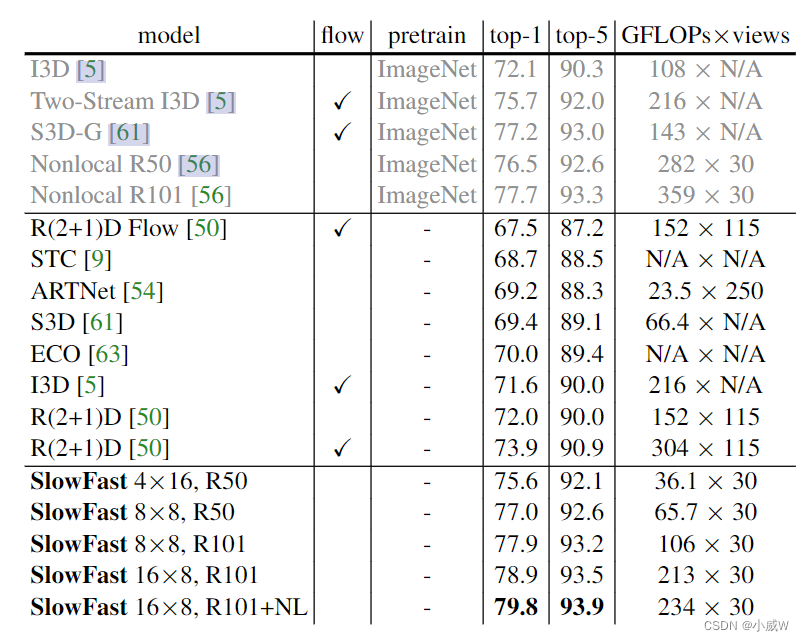
SlowFast
Christoph Feichtenhofer, Haoqi Fan, Jitendra Malik, & Kaiming He (2018). SlowFast Networks for Video Recognition International Conference on Computer Vision.
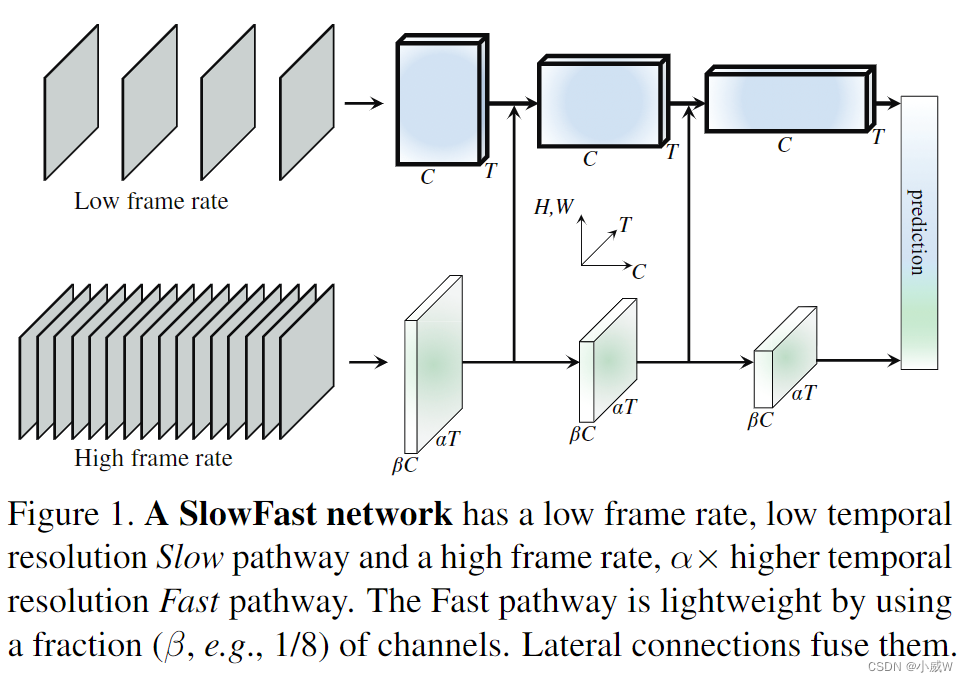
慢分支:小输入,大网络
快分支:大输入,小网络
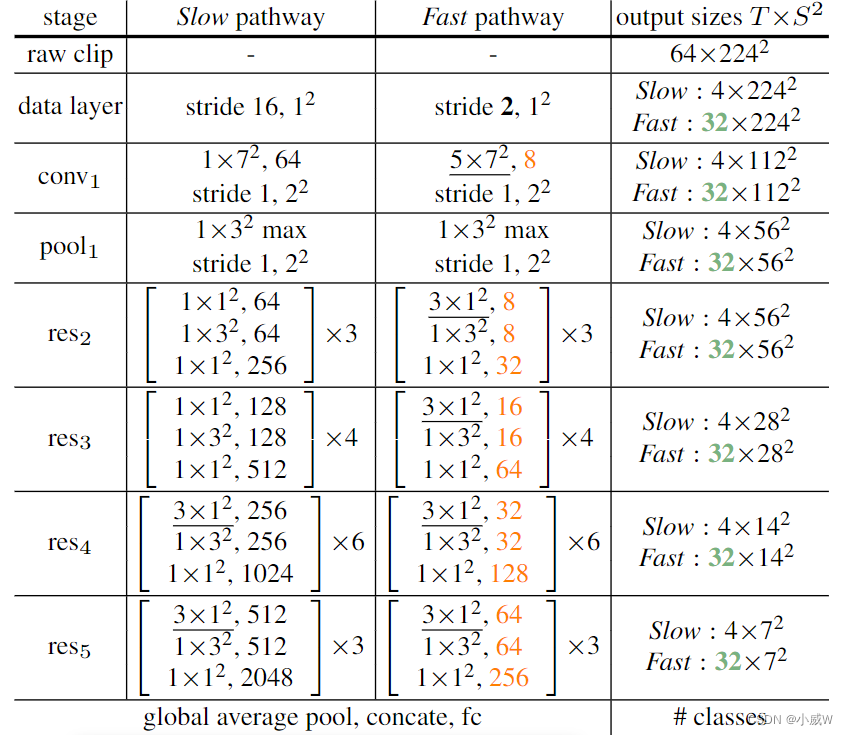
慢分支是个标准的 i3d 网络。
在时间维度上一直没有做下采样。
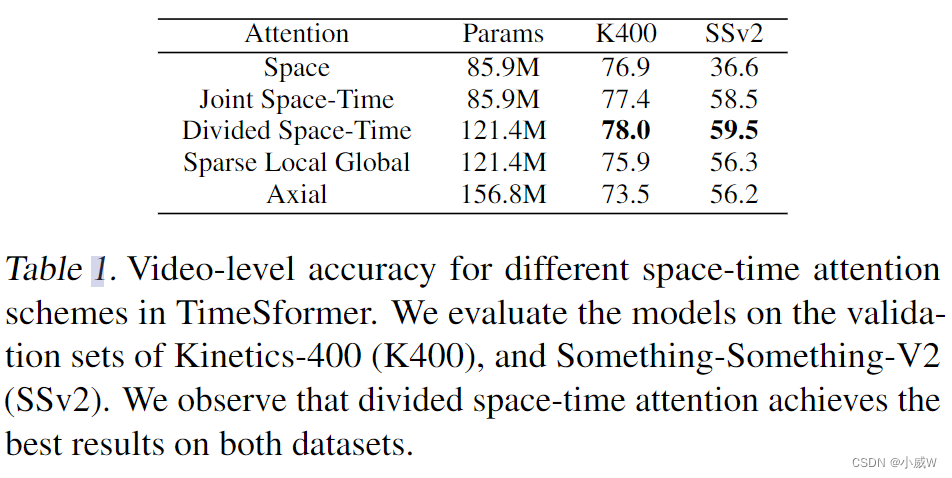
Timesformer
Gedas Bertasius, Heng Wang, & Lorenzo Torresani (2021). Is Space-Time Attention All You Need for Video Understanding?. arXiv: Computer Vision and Pattern Recognition.
通过大量实验,探索了如果将 vision transformer 从图像领域迁移到视频领域中。
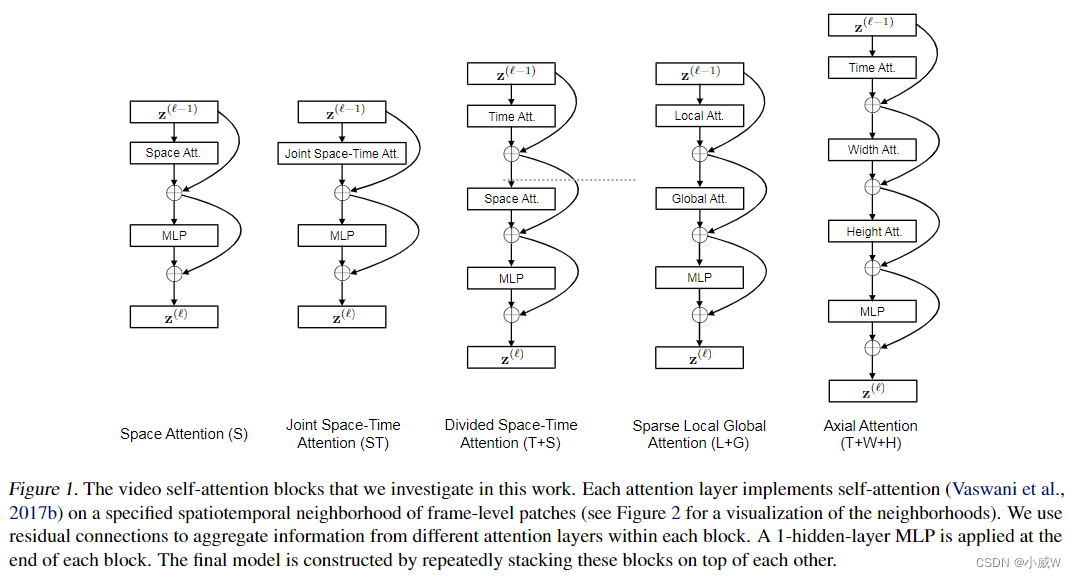
按照R(2+1)D的思路,设计了Divided Space-Time Attention。
Sparse Local Global Attentiono(L+G),类似Swim Transformer
下图是上面5种方法的可视化展示:

性能表现:
其它相关工作:
Xinyu Li, Yanyi Zhang, Chunhui Liu, Bing Shuai, Yi Zhu, Biagio Brattoli, Hao Chen, Ivan Marsic, & Joseph Tighe (2021). VidTr: Video Transformer Without Convolutions Cornell University - arXiv.
Haoqi Fan, Bo Xiong, Karttikeya Mangalam, Yanghao Li, Zhicheng Yan, Jitendra Malik, & Christoph Feichtenhofer (2021). Multiscale Vision Transformers Cornell University - arXiv.
Anurag Arnab, Mostafa Dehghani, Georg Heigold, Chen Sun, Mario Lucic, & Cordelia Schmid (2021). ViViT: A Video Vision Transformer arXiv: Computer Vision and Pattern Recognition.
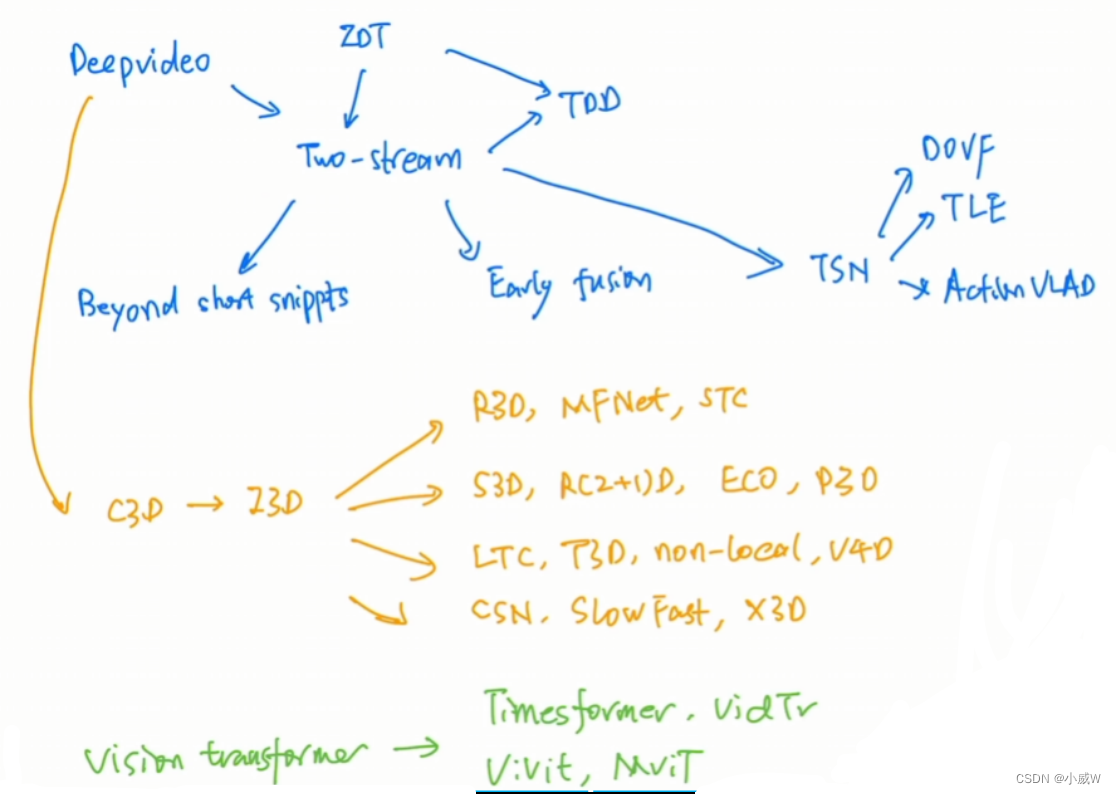
脉络总结:
参考链接:
https://www.bilibili.com/video/BV1fL4y157yA/