什么是单链表?
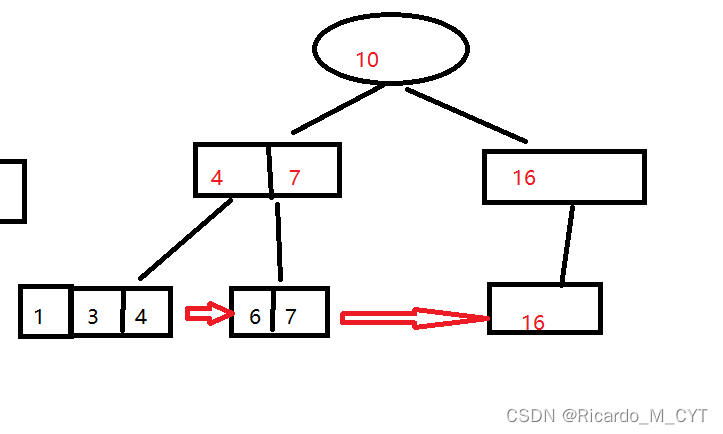
单链表就是一种线性的链式数据结构。单链表通过节点来存储线性数据的,单链表不要求连续的物理空间来存储数据。但是,单链表在逻辑结构上是连续的。通常,会有一个头指针指向单链表的首结点因为单链表的结点会存储一下个结点的地址,以便于访问后面的结点,单链表的尾结点存储的是NULL。


我们可以将单链表理解成类似于通过铁链连接在一起的火车,头结点也就是火车头,它是单链表最关键的结点,单链表的一切操作都离不开它。通常它被一个头指针或者哨兵位头结点指向。链表的尾结点是指向NULL的。
单链表的优缺点
优点
单链表不需要连续的物理空间来存放数据,可以大大的突破线性表的物理空间上的制约。单链表从头结点增删查改数据效率高。学习单链表可以提升我们对于编程语言的理解。
缺点
单链表由于需要通过当前结点内存放的下一个结点的地址才能够找到下一个结点,当我们遍历链表和对链表尾结点进行增删查改是效率一般。并且对单链表某个结点进行增删查改操作时,需要对单链表的物理结构和逻辑结构有一个清晰的理解。
单链表基本功能的实现
单链表定义
首先,我们需要知道,单链表内所需要的数据有两种,一种是数据,还有就是下一个节点的指针。所以我们需要定义一个结构体。
typedef int SLTDataType;//重命名单链表的数据
//便于不同数据类型的切换
typedef struct SLTNode
{
SLTDataType data;
struct SLTNode* next;
//SLTNode* next//错误
//改写法C语言是不支持的
//struct SLTNode//错误
}SLTNode;
单链表插入数据
想要了解一种数据结构,就要理解它的最基本的增删查改逻辑,下面我就先从插入数据先手。
开辟新节点
在插入链表新节点前,我们可以先写一个接口用于创建一个新的结点。创建后将结点初始化一下,初始化数据为我们所指定的数据,并将下一个结点初始化成NULL,以便于我们使用。
SLTNode* SLTBuyNode(SLTDataType x)
{
SLTNode* newnode = (SLTNode*)malloc(sizeof(SLTNode));
if (NULL == newnode)//判断空间是否开辟
{
perror("malloc fail");
return NULL;
}
newnode->data = x;
newnode->next = NULL;
return newnode;
}
头插数据
头部插入数据本质是将源头结点的地址,赋给头插的新节点的存放下一个结点地址的指针变量中。然后改变头指针的指向,让头指针指向新的结点。

void SLTPushFront(SLTNode** pphead, SLTDataType x)
{
assert(pphead);//防止**pphead空指针
SLTNode* newnode = SLTBuyNode(x);
newnode->next = *pphead;
*pphead = newnode;
}
尾插数据
相较于头插数据,尾插数据我们需要先找到链表的尾结点。将插入前的尾结点的下一个结点改成插入结点的地址。然后插入新的结点。需要考虑空链表情况,并且需要注意的是找到最后一个结点的条件是当该结点的下一个指向指针变量的地址为NULL。
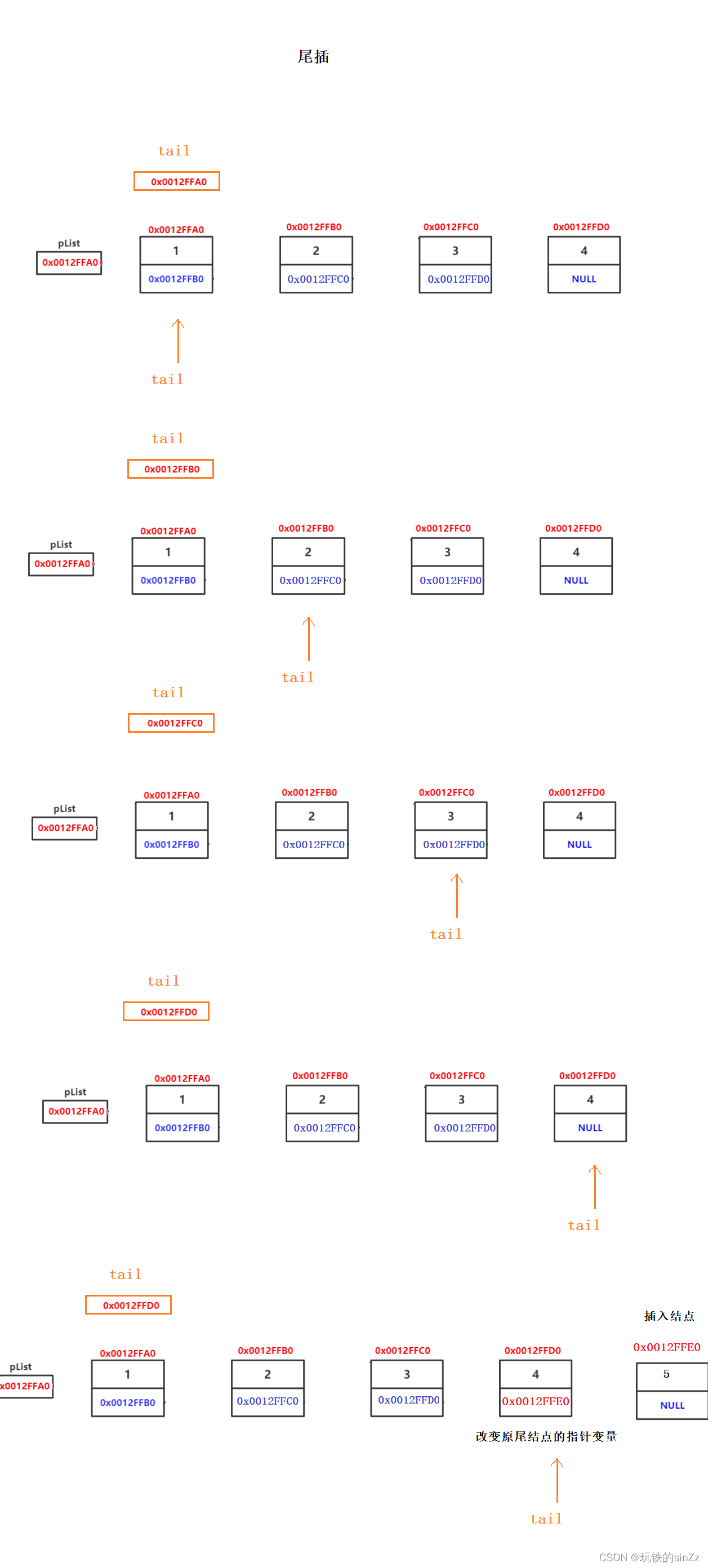
void SLTPushBack(SLTNode** pphead, SLTDataType x)
{
assert(pphead);
SLTNode* newnode = SLTBuyNode(x);
if (*pphead == NULL)//空链表直接插入
{
*pphead = newnode;
}
else
{
//链表不为空,找尾结点
SLTNode* tail = *pphead;
while (tail->next)//找尾
{
tail = tail->next;
}
tail->next = newnode;//尾插
}
}
查找单链表
在介绍单链表某个结点后插入数据前,我们要掌握单链表查找结点这个功能的实现。首先,查找单链表其实不需要二级指针,在前面的两个插入中,在参数部分采用二级指针。是希望用户传参时传一级指针变量的地址。只有传址调用,形参的修改才能够影响实参。当然将修改链表内容的结构部分的参数部分设计成二级指针不是唯一的设计参数的方法。而查找单链表结点,并不需要进行对原单链表修改,故参数部分设计成一级指针。查找功能就是遍历一遍链表,找到指定的结点后,返回这个结点的地址,找不到返回NULL
SLTNode* SLTFind(SLTNode* phead, SLTDataType x)
{
if (phead == NULL)
{
return NULL;
}
else
{
SLTNode* cur = phead;
while (cur)
{
if (cur->data == x)
return cur;
cur = cur->next;
}
return NULL;
}
}
在pos位置后插入新节点
首先,将pos->next先存起来,避免插入后找不到原来的下一个结点,然后插入结点,将pos的next指针改为新节点的地址,将新节点的next改成原来的pos位置的next指针。
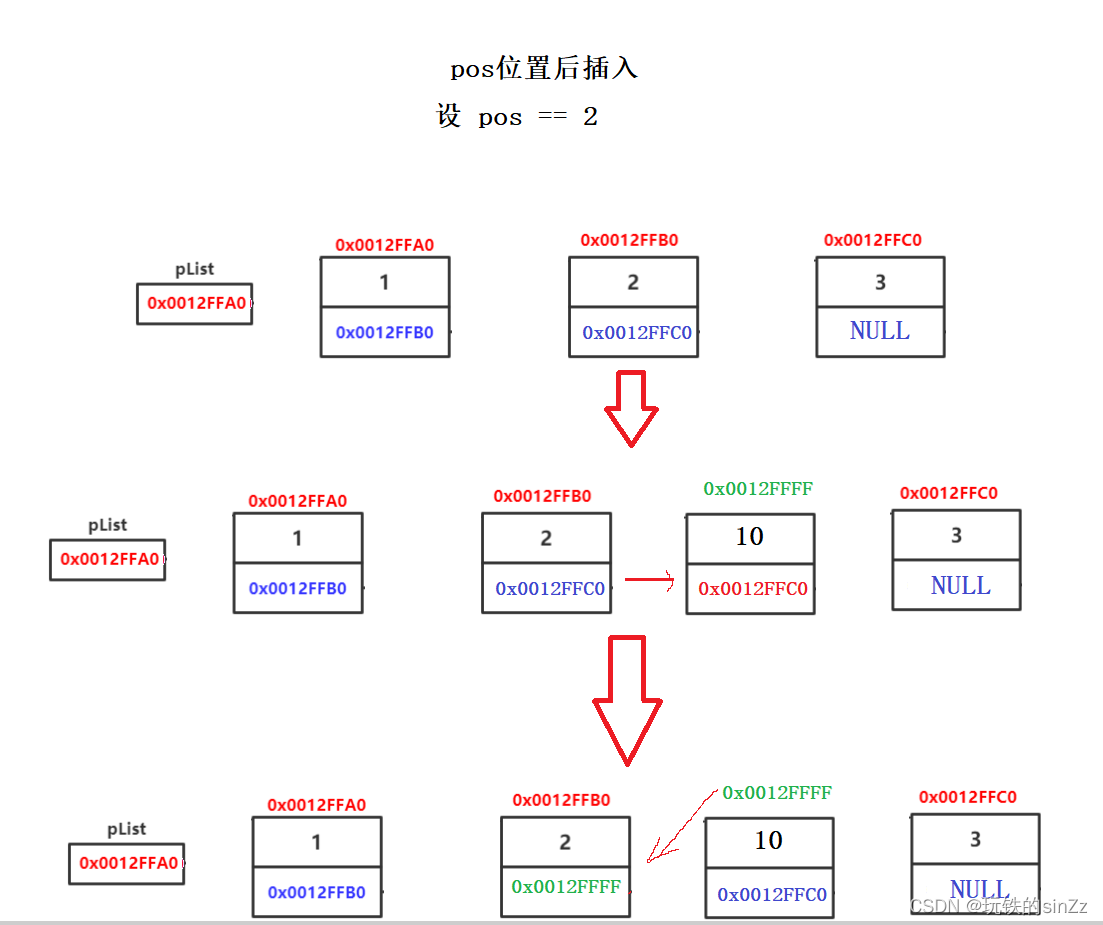
void SLTInsertAfter(SLTNode* pos, SLTDataType x)
{
assert(pos);
SLTNode* newnode = SLTBuyNode(x);
SLTNode* cur = pos->next;
pos->next = newnode;
newnode->next = cur;
}
单链表修改数据
单链表修改数据的实现类似于查找的思想,。就是遍历整个单链表,直到找到目标结点,并修改目标结点的数据。值得注意的是,这里的修改需要同上面的插入数据一样,还是进行传址调用。
void SLTModify(SLTNode** pphead, SLTNode* pos, SLTDataType x)
{
assert(pphead);
assert(*pphead);
assert(pos);
SLTNode* cur = *pphead;
while (cur)
{
if (cur == pos)
{
cur->data = x;
return;
}
cur = cur->next;
}
printf("该结点不存在,修改失败\n");
}
单链表删除数据
有插入数据自然就有删除数据,下面我将介绍三种经典的单链表删除接口。
头删数据
头删数据的思想就是将第一个结点指向的地址保存一份,将第一个结点的指针变量赋给头指针或哨兵位头结点的指针变量。然后释放我们刚刚保存的指向第一个结点的指针变量,这样就完成了头删。
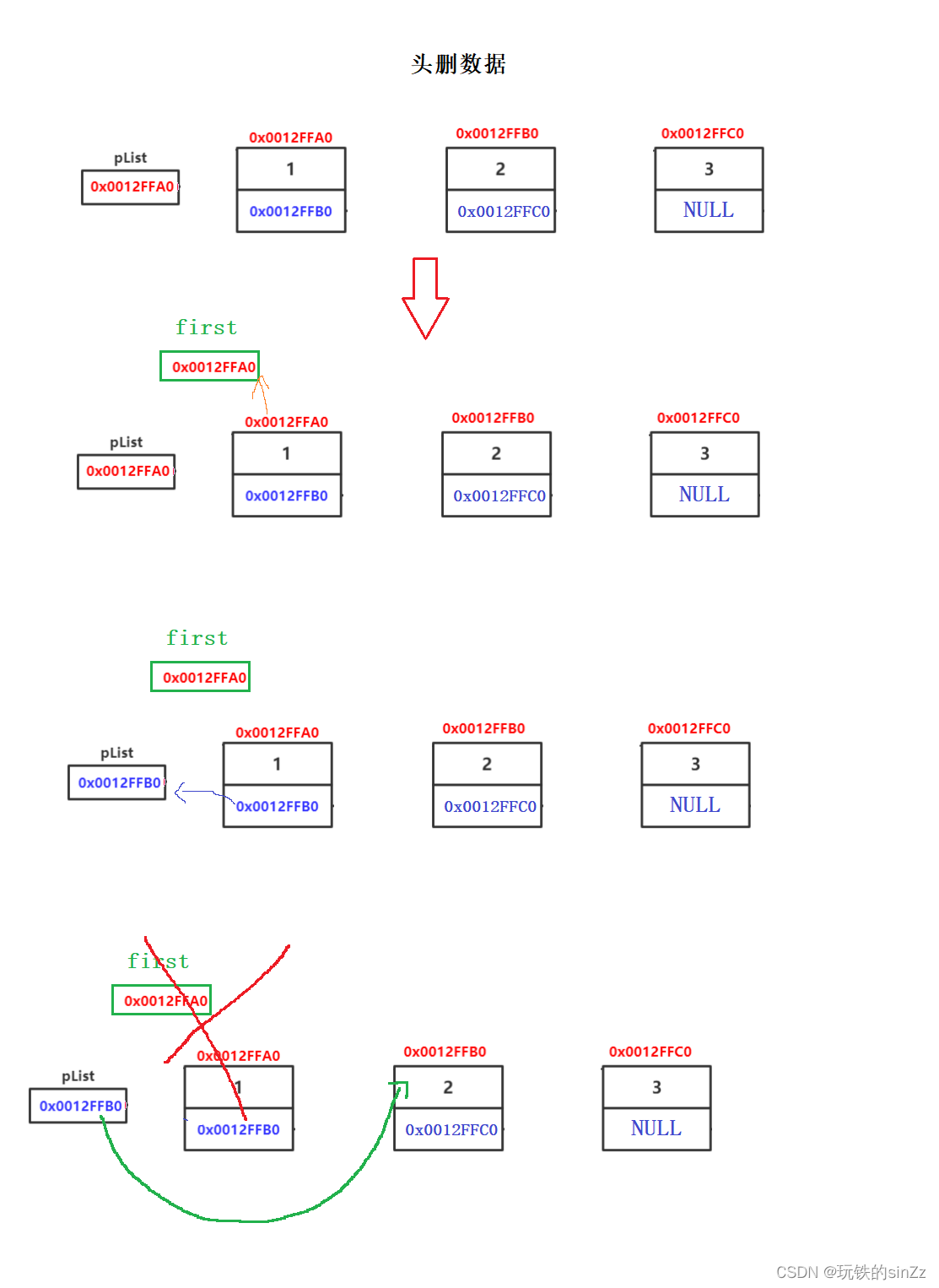
void SLTPopFront(SLTNode** pphead)
{
assert(pphead);//空指针不可传
assert(*pphead);//空表不可删
SLTNode* first = *pphead;
*pphead = first->next;
free(first);
first = NULL;
}
尾删数据
尾删数据需要先找到尾结点前的一个接节点,将尾结点前一个结点的指针变量置空,让后释放尾结点即可。需要注意区分单个节点尾删和多个结点尾删的区别。
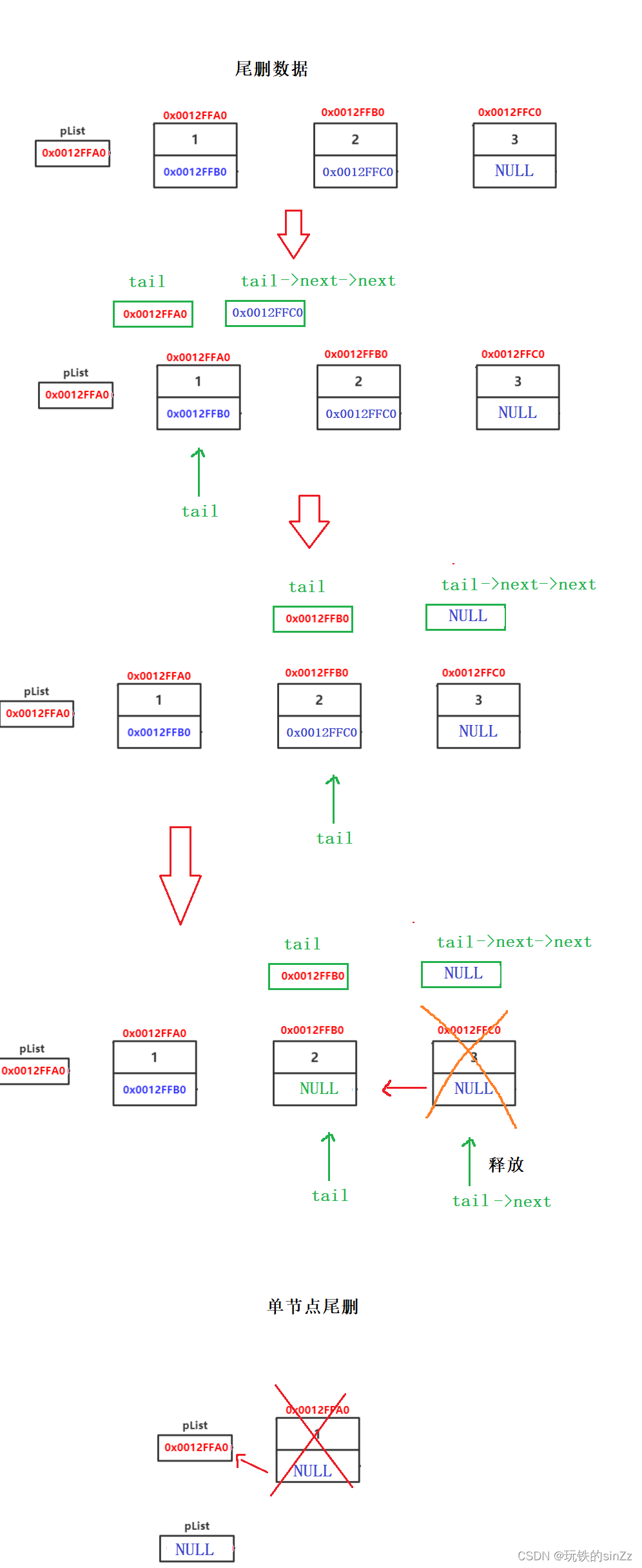
void SLTPopBack(SLTNode** pphead)
{
assert(pphead);
assert(*pphead);//空链表不可删除
if ((*pphead)->next == NULL)
{
//单个结点
free(*pphead);//删除
*pphead = NULL;
}
else
{
//多个结点
SLTNode* tail = *pphead;
while (tail->next->next)
{
tail = tail->next;
}
free(tail->next);//删除
tail->next = NULL;
}
}
删除pos位置后数据
删除pos位置后的思想就先保存pos下一个结点的指针变量,即pos->next->next。然后释放pos的下一个结点,将pos的指针变量改成被删除结点的下一个结点的地址。
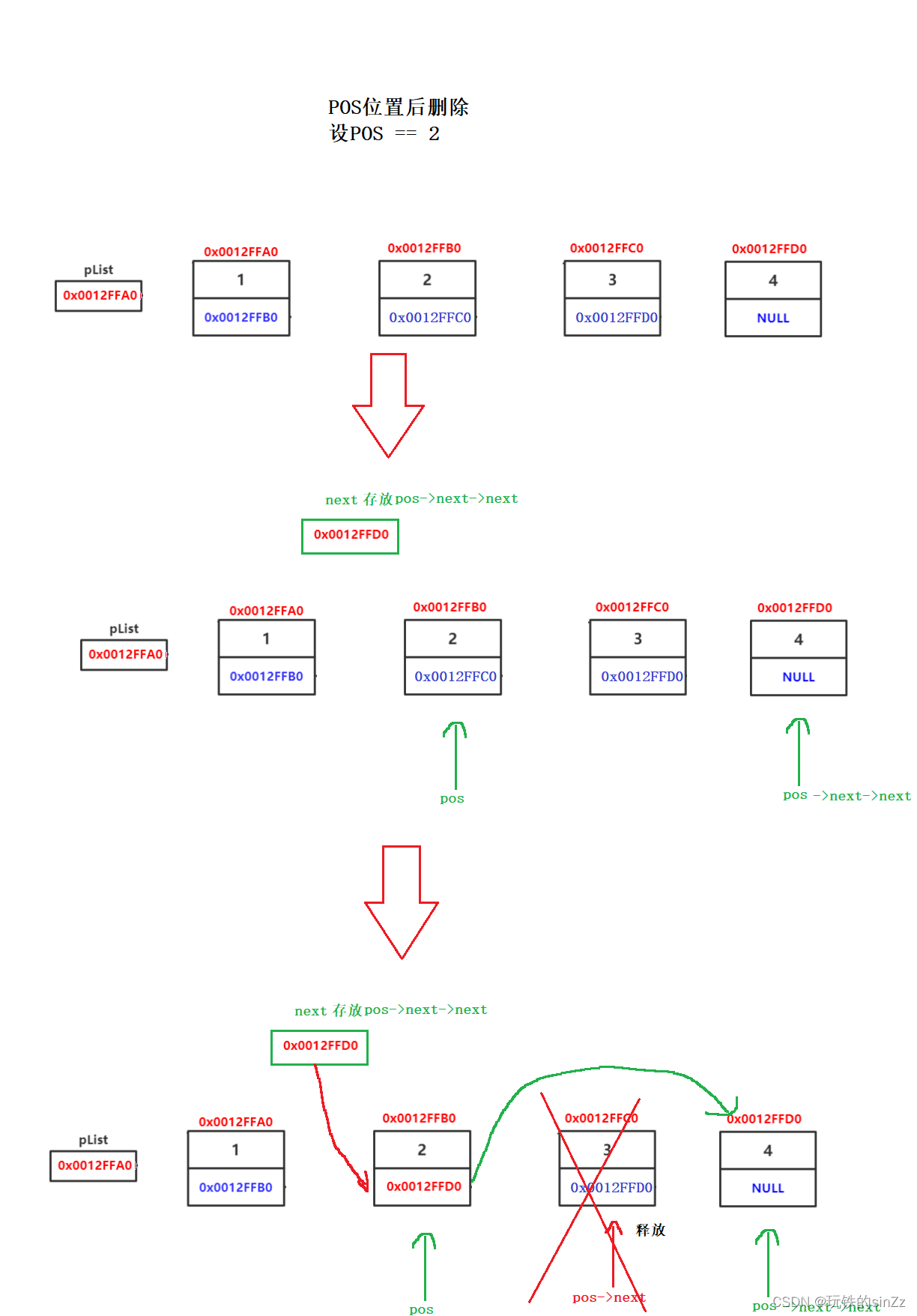
void SLTEraseAfter(SLTNode* pos)
{
assert(pos);
assert(pos->next);//不为单个结点
SLTNode* next = pos->next->next;
free(pos->next);
pos->next = next;
}
单链表打印
前面的增删查改是正餐,打印功能就是一道饭后甜点了。话不多说我就直接上代码了
void SLTPrint(SLTNode* phead)
{
SLTNode* cur = phead;
while (cur)
{
printf("%d->",cur->data);
cur = cur->next;
}
printf("NULL\n");
}