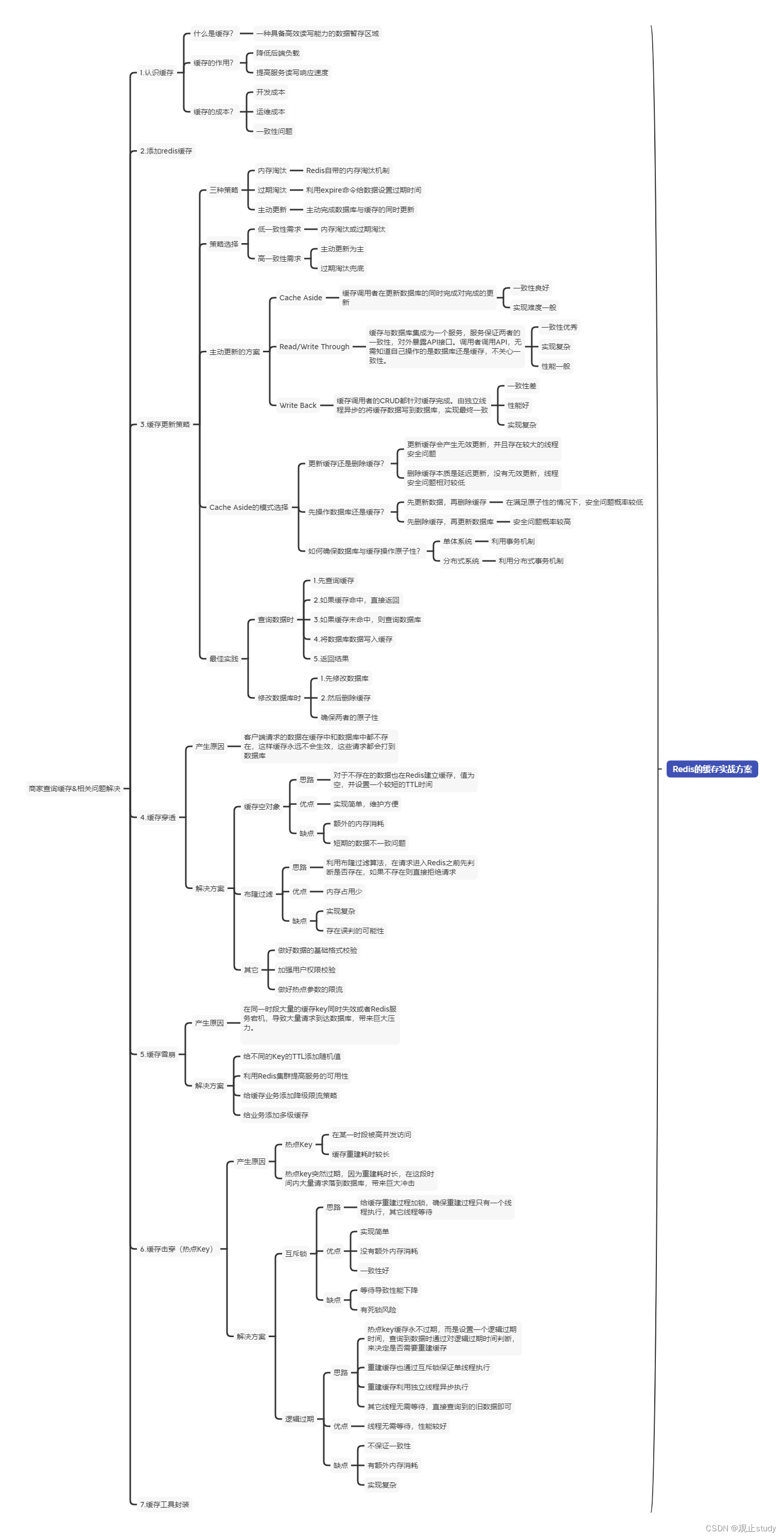
MySQL索引背后的数据结构
- 前言
- MySQL
- MySQL背后的数据结构
- B树
- B+树
前言
好久不见,困扰了我许久的阴霾终于散去了,但是随之而来的是学校堆积如山的任务考试,这段时间不可否认我的学习效率和学习效果不是很佳,但是我之前就说过学习是需要贯穿程序猿一生的事情,流水不争先,争的是滔滔不绝,如果屏幕前的您真的遇到了不如意,不妨放慢脚步,放松自己,然后再投入到自己的事业中.
MySQL
我们日后工作大部分时间可能就是在对各种各样的数据库进行CURD,但是我们要掌握的却远远不止于此,这部分我没有写博客,是因为这部分的知识,不太好用文字的形式讲解,希望大家 可以多去使用使用,几遍下来就可以记住了.
MySQL背后的数据结构
前面都是引子,这才是我想通过这篇博客分享给大家的东西.
先说好,我现在默认兄弟们是了解MySQL的,所以新手看不懂不要骂阿涛!!
在日常使用中,我们使用查询的频率是要远远高于其他操作的,因此我们创建了索引,这样我们在查询数据的时候,就避免了每次都要遍历数据的尴尬,但是与此同时可能会拖慢增删改的步伐,但是正是因为我们查找的频率要远高于其他操作,所以总体上索引是利大于弊的.
在开始讲解数据结构的时候,我们就说过了,数据结构是组织数据的形式,那么我们想一想可以用什么数据结构来组织数据库中的庞大的数据呢?
Hash表?Hash表固然可以达到O(1)的时间复杂度,但是,数据表的结构注定了它没有办法返回一个范围内的数据.
二叉树?我们之前在使用二叉树的时候,有不少时候是可以感觉到,当数据量非常之大的时候,是有可能导致那个stack overflow错误的,因此我们可以使用B+树这个为数据库索引量身定做的数据结构,在了解B+树之前,我们先来了解一下B树.
B树
B树也可以叫做B-树,注意这里不是叫B减数,就是叫做B数.
B数可以认为是一棵N叉搜索树,二叉搜索树的概念之前我有专门的博客,二叉搜索树就是根的左子树的值比根小,右子树的值比根大,不存在两个一样的值.
那么根据名字我们可以想象到N叉搜索树的模样,现在根节点下面就不仅仅是挂着两两个子树了,可以挂好多棵子树,这样子在数据量相同的情况下,是不是总体树的高度就降低下来了?
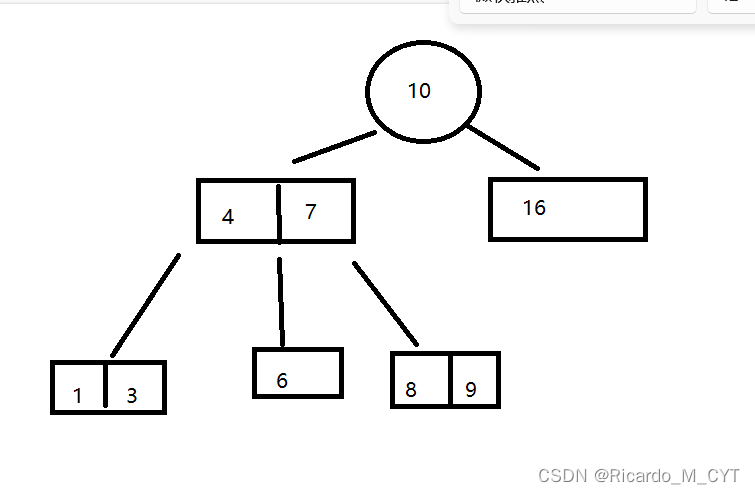
我们可以看到B树与普通树的不同还远远不止与上述特点.
首先我们的每个节点现在可以存储多个值了,然后就比如我们节点中的值有两个,那么这棵子树就可以有它的三棵子树,左边是小的区间的,中间的树介于两个值之间,右边的值大的区间,
但是我们还是要抓住搜索树的本质特点,左子树的值永远要小于根节点的值,右子树的值永远要大于根节点的值.
B+树
B+树又在B树的基础上进行了优化.
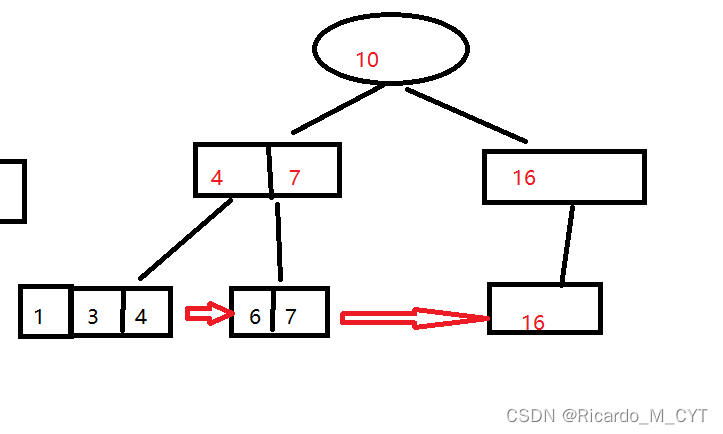
可以看到总体上还是能看出这是一个N叉搜索树的样子的,但是其中还是有一点玄机的.
首先现在如果一个节点中有两个值,那么就只有两个子节点了,我们可以看到的是,子节点会把父亲节点给加上去,然后在B+树的最底层会以一种类似于链表的形式把所有的数据给连接起来.
B+树的特点:
1.一个节点可以存储N个key,N个key划分出了N个区间,而不是B树的N+1区间
2.每个节点中的key值,都会在子结点中存在,同时该key也是子节点的最大值
3.B+树的叶子节点,是首尾相连,类似于一个链表
4.整棵树的所有数据都是包含在叶子节点中的,由于叶子节点是完整的数据集合,所以我们只在叶子节点这里存储数据表的每一行的数据,而非叶子节点,只存key值即可
B+树的优势:
1.当前一个节点保存更多的key,最终树的高度是相对更矮的,查询的时候减少了IO访问次数,和B一样的效果
2.所有的查询最终都会落实在叶子节点上,查询任何一个数据最终的IO访问次数是一样的,即使提前找到了最终还是需要一直往下找到叶子节点为止,那里才是one piece.
B+树的这个稳定查询是很重要的,这个稳定是很关键的,稳定能够让程序猿对于程序的执行效率有一个更准确的评估
input-output:显示数据到显示屏上,从键盘输入数据,把数据写到硬盘上,从硬盘读数据,把数据写到网卡上,从网卡读数据,我们这里的IO特指访问硬盘
3.B+树的所有的叶子节点构成链表,比较方便进行范围查询:
查询学号>5并且<11的人,只需要先找到5所在的位置,再找到11所在的位置,从5沿着链表遍历到11,中间结果既是所求.
4.由于数据都在叶子节点上,非叶子节点只存储key,所以非叶子节点占用空间十分小,这里的非叶子节点就有可能在内存中缓存部分,又进一步减少了IO次数
刚才的B+树就是MySOL组织数据的方式,当你看到一张"表"的时候,实际上不一定就是按照"表格"的结构在硬盘上组织的,也有可能是按照这样树形结构组织,具体是哪种结构,取决于你的表里有没有索引,以及数据库使用了哪种存储引擎.
上面的树形结构就是"索引",如果这一列不能比较,就没有办法创建索引,幸运的是,MySOL里面的各种类型,都能比较,数字,字符串,时间日期,MySOL是不可以自定义类型的,上述结构默认Id是表的主键了,如果表里面有多个索引,表的数据还是按照id为主键,构建出B+树,通过叶子节点组织所有的数据行,其次针对name这一列,会构建另一个B+树,但是这个B+树的叶子节点就不再存储这一行的完整数据,而是存主键ID,此时根据mane来查询,查到叶子节点得到的只是主键id,还需要再通过主键id去主键的B+树里面再查询一次,一共查询两次B+树,上述过程称之为"回表",这个过程都是MySOL自动完成的,用户感知不到.
希望我的这篇博客对兄弟们能有所帮助,还是那句话,百年大道,你我共勉!





![[ROC-RK3568-PC] [Firefly-Android] 10min带你了解RTC的使用](https://img-blog.csdnimg.cn/344014cfa99d41488c461e7d480bb3da.png)