本章主要内容:
1.视图管理:视图新增,修改,删除;
2.索引管理:索引目的,创建,修改,删除;
3.同义词管理:同义词的作用,创建,修改,使用及删除;
4.系列管理:系统作用,系列创建、修改、使用及删除;
什么是视图
1.
视图是一种数据库对象,它允许用户从一个或多组表中通过查询语句创建一个
“
虚表
”
。
2.
视图中并没有存放数据,而仅仅是一条
select
查询语句,查询结果以表的形式表示。
3.
视图是创建在表的基础上的,也可以在视图的基础上再创建视图。视图不能创建索引。
4.
创建视图的表称为基表
5.
视图中可含有多表联接、集合运算符、
DISTINCY
运算符、集合函数、
GROUP BY
、
CONNECT BY
等字句时,视图通常是不能修改。
视图的优点
1、安全,使用视图将用户与基表分开
2、方便,简化用户的 SQL
命令
3、一致性,视图不存储数据,操作视图的数据就是操作基表数据
SQL语句管理视图
创建语句
CREATE VIEW VIEW_NAME
AS
SELECT * FROM BASE_TABLE
[WITH READ ONLY]
[WITH CHECK OPTION]
使用视图进行操作
select column_list from VIEW_NAME
删除视图
Drop VIEW_NAME
视图举例
CREATE OR REPLACE VIEW V_EMP1
AS
SELECT * FROM EMP;
SELECT * FROM USER_VIEWS; --查看用户的视图
DESC V_EMP1 --查看视图的结构
INSERT INTO V_EMP (empno,ename,sal) VALUES (51,’HR’, 4000);
往视图插入数据,实际将数据插入到了基表
SELECT * FROM EMP; --查询看一下插入成功没
CREATE OR REPLACE VIEW V_EMP2
AS
SELECT * FROM EMP WHERE sal>2500;
INSERT INTO V_EMP2 (empno,ename,sal) values(51,’HR’, 2100); --OK
插入也能成功,可以查一下基表,但是查询该视图却看不到数据
SELECT * FROM V_EMP2 --看不到往视图插入的数据,造成错觉
CREATE OR REPLACE VIEW V_EMP2
AS
SELECT * FROM EMP WHERE sal>2500
WITH CHECK OPTION --不符合视图条件的数据不让插
INSERT INTO V_EMP2 (empno,ename,sal) VALUES (52,’HR’, 2100); --失败
CREATE OR REPLACE VIEW V_EMP_DEPT
AS
SELECT empno,ename,sal,d.deptno,d.dname
FROM EMP e INNER JOIN DEPT d
ON e.deptno = d.deptno;
INSERT INTO V_EMP_DEPT VALUES(‘1005’,’TOM’,3100,’52’, ‘SALES’);
失败,多表连接的视图不让插入和修改
CREATE OR REPLACE VIEW V_READ
AS
SELECT * FROM EMP
WITH READ ONLY; --只读的视图,不能插入、修改、删除记录
索引的管理
•
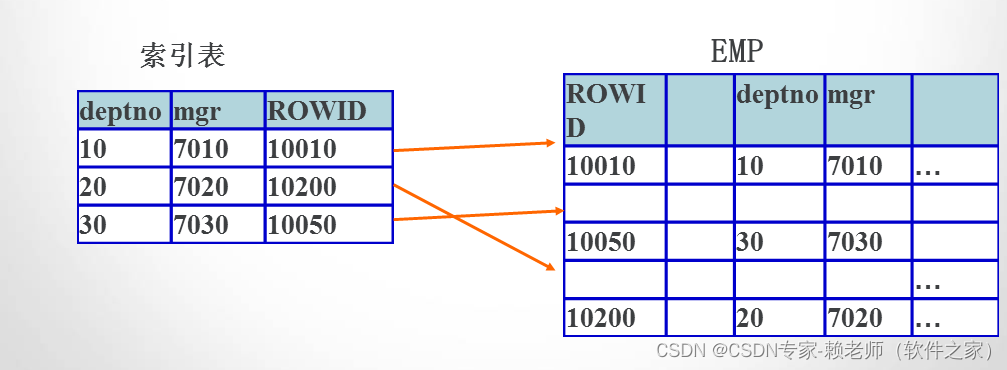
索引是基于表建立的一种数据结构,通过表中的某些字段上建立索引,可以提高系统对表的查询速度。
•
索引表中只保存索引关键字和纪录号,查询时根据索引关键字,可以从索引表中找到对应的纪录号,根据纪录号就可以快速的将纪录指针移到与关键字相对应的纪录上,从而得到查询结果。
•
支持两种索引:
B
树索引
•
用一个倒置的树状结构来加快查询表的速度
位图索引
•
只存在与
oracle
的企业版本中,适合在数据表中的列值重复较多的情况下创建索引
索引的原理
CREATE INDEX IDX_EMP on EMP (deptno,mgr);
索引的管理
•创建不唯一索引
CREATE INDEX index_name on TABLE_NAME(index_column)
TABLESPACE SYSTEM
STORAGE ( initial 20 k next 20 k pctincrease 75)
pctfree 0 ;
•创建唯一索引
CREATE UNIQUE INDEX idx_emp_ename on EMP(empno)
TABLESPACE users
STORAGE ( initial 20 k next 20 k pctincrease 75) 、pctfree 0 ;
•创建位图索引
CREATE bitmap INDEX on EMP(sex); --可能的值少,重复多
•删除索引
DROP INDEX index_ename;
索引的管理
User_indexes:存放用户所创建的索引信息
User_ind_columns:存放用户索引的字段信息
查询ida表的索引信息
select index_name,column_name,column_position from user_ind_columns where table_name=‘IDA'
同义词管理
•
同义词就是为
oracle
数据库中的对象创建一个别名,使该对象的非创建者也可以直接通过该别名来访问。
•
Oracle
同义词有两种:
公有同义词
•
由
DBA
创建,所有用户都可以访问
•
CREATE
public
SYNONYM
EMP FOR SCOTT.EMP;
私有同义词
•
只能由创建者自己使用
•
CREATE SYNONYM
EMP FOR SCOTT.EMP;
•
删除同义词:
Drop synonym
EMP
•
与同义词有关的数据字典
DBA_SYNONYMS:
是数据库中的所有同义词的描述
ALL_SYNONYMS:
是数据库中的所有同义词的描述
User_SYNONYMS
:是用户可存取的所有同义词
•
select * from DBA_SYNONYMS WHERE SYNONYM_NAME=
‘EMP
’;
同义词用途
•
应用程序应当尽量避免直接使用表名,
DBA
或设计人员改变了表名将直接影响程序,如果程序使用同义词,则只需修改同义词即可
•
方便使用,不需带上模式名
•
增强移植性
定义共有同义词,换了用户也可以使用
序列的管理
•
序列就是一个连续的数字生成器,可设置为上升或下降
•
当序列第一次被调用的时候将返回一个指定的值,然后根据规则增量增长
•
序列可以是循环的,也可以是连续增加的,直到一个限制值为止。
•
序列有两个伪列:
CurrVal
:表示当前列
NextVal
:下一个序列值
语法:
CREATE SEQUENCE sequence_name[INCREMENT BY n]
[START WITH n][{MAXVALUE n}][{MINVALUE n}]
[{CYCLE |NOCYCLE}][{CACHE n|NOCACHE}];
INCREMENT BY:指定步长 。
START WITH:指定初始值 。
MAXVALUE:指定序列可生成的最大值。
MINVALUE:指定序列的最小值。
CYCLE--配置序列在达到界限值时重复编号NOCYCLE--达到界限值时不重复编号,一直累加,不循环,这是默认值。
CACHE--定义在内存中保留的序列编号块的大小,默认值为20.NOCACHE--强制数据词典对于生成的每个序列编号进行更新,保证在生成的编号中没有空缺,但这样会降低性能.
•创建一个序列
CREATE SEQUENCE myseq
INCREMENT BY 1
START WITH 1
MAXVALUE 1.0E28
MINVALUE 1
NOCYCLE
CACHE 20
NOORDER;
CREATE TABLE AA (
id number(10,0) not null,
aa varchar2(10)
);
使用序列
insert into AA values(myseq.NEXTVAL, 'first');
insert into AA values(myseq.NEXTVAL, 'second');
SELECT * FROM AA;
SELECT myseq.CURRVAL from dual;•删除一个序列
Drop sequence myseq
•与序列有关的数据字典
DBA_SEQUENCE
:
•
存放数据库中的所有序列的描述信息
ALL_SEQUENCE
:
•
存放当前用户可存取的所有序列
USER_SEQUENCES:
•
用户序列的说明
•
SELECT SEQUENCE_NAME, MIN_VALUE , MAX_VALUE
•
FROM user_sequences where SEQUENCE_NAME ='SQ'
本人从事软件项目开发20多年,2005年开始从事Java工程师系列课程的教学工作,录制50多门精品视频课程,包含java基础,jspweb开发,SSH,SSM,SpringBoot,SpringCloud,人工智能,在线支付等众多商业项目,每门课程都包含有项目实战,上课PPT,及完整的源代码下载,有兴趣的朋友可以看看我的在线课堂
讲师课堂链接:https://edu.csdn.net/lecturer/893



![[Gin]框架底层实现理解(三)](https://img-blog.csdnimg.cn/b59c77aa52c648549416af16e6c8275d.png)