第一章 多表关系实战
1.1 实战1:省和市
方案1:多张表,一对多
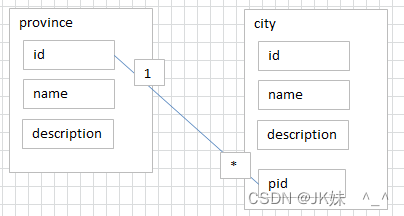
方案2:一张表,自关联一对多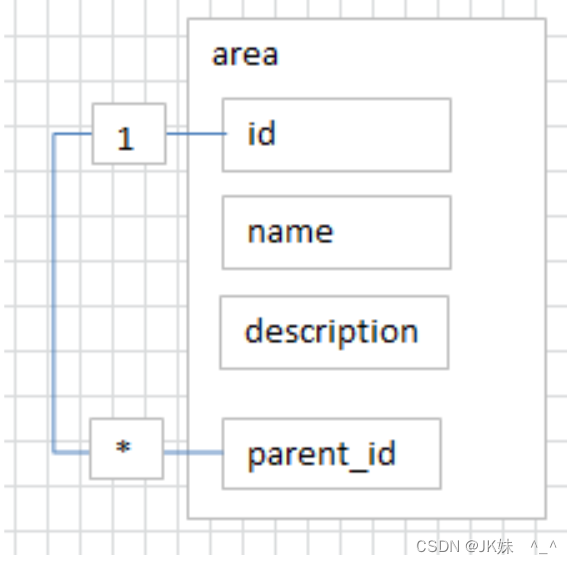
id=1
name=‘北京’
p_id = null;
id=2
name=‘昌平’
p_id=1
id=3
name=‘大兴’
p_id=1
id=3
name=‘上海’
p_id=null
id=4
name=‘浦东’
p_id=3
1.2 实战2:用户和角色
多对多关系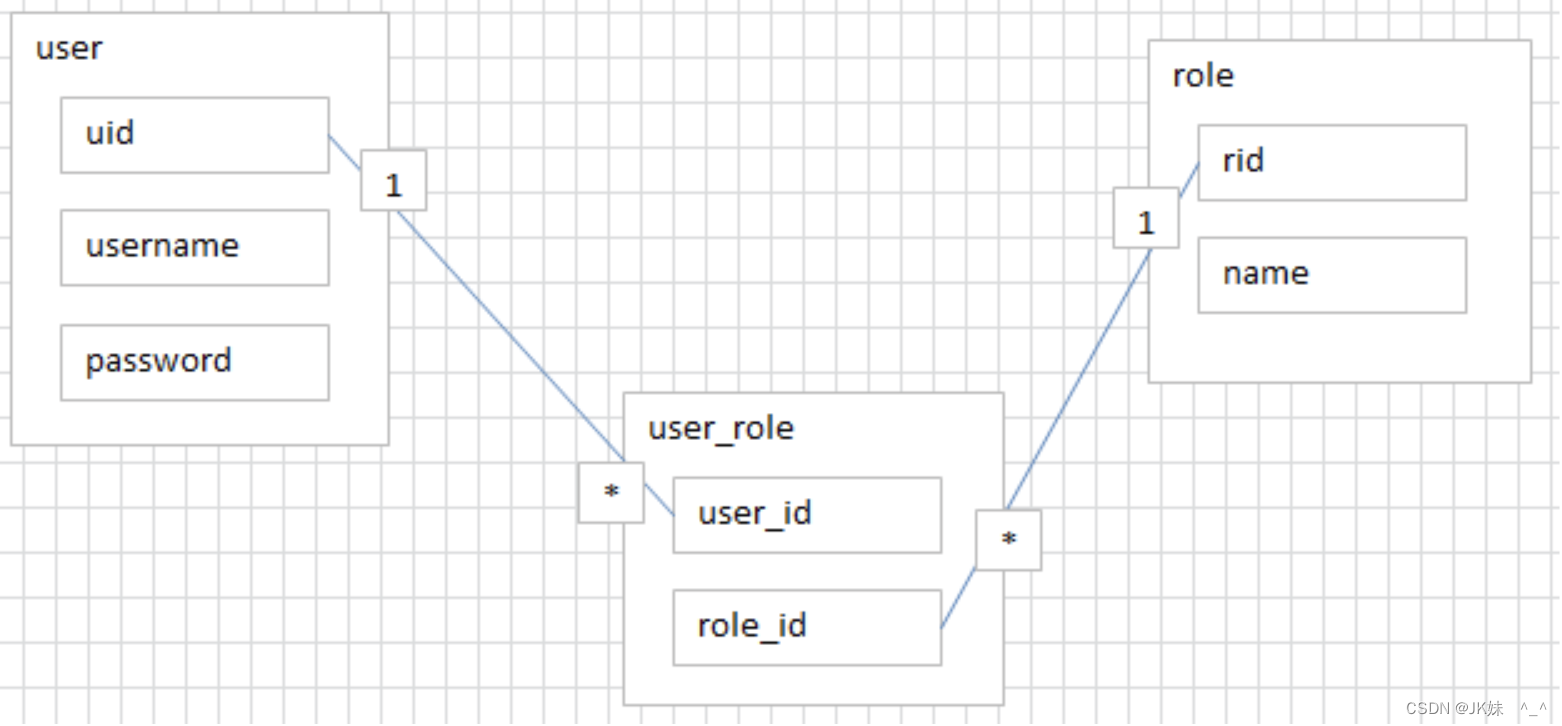
第二章 多表查询之子查询
提供表结构如下:
-- 部门表
create table department (
id int primary key auto_increment,
name varchar(50)
);
-- 员工表
create table worker (
id int primary key auto_increment,
name varchar(50), -- 名字
sex char(2), -- 性别
money double, -- 工资
inWork_date date, -- 入职时间
depart_id int, -- 部门
foreign key(depart_id) references department(id)
);
2.1 初始化数据
-- 插入部门数据
insert into department(name)
values('技术研发'), ('市场营销'), ('行政财务');
-- 插入员工数据
insert into worker(name, sex, money, inWork_date,depart_id)
values('cuihua', '女', 10000, '2019-5-5', 1);
insert into worker(name, sex, money, inWork_date,depart_id)
values('guoqing', '男', 20000, '2018-5-5', 2);
insert into worker(name, sex, money, inWork_date,depart_id)
values('qiangge', '男', 30000, '2018-7-5', 3);
insert into worker(name, sex, money, inWork_date,depart_id)
values('huahua', '女', 10000, '2019-5-5', 1);
2.2 什么是子查询?
一个查询的结果作为另一个查询的条件。
有查询的嵌套,内部的查询就是子查询。
子查询,需要使用小括号包含起来。
-- 查询技术研发部门有哪些员工
-- 1. 先查询所有的员工
select * from worker where depart_id = 1;
-- 2. 查询部门
select id from department where name = '技术研发';
-- 使用子查询的方式,来统一查询对应的数据
select * from worker where depart_id = (select id from department where name
= '技术研发');
2.3 常见三种做法
1)单行单列
也就是结果只有一个
select 指定的字段 from 表 where 字段 = (子查询)
-- 谁的工资最高?
-- 1. 先把最高工资找出来
select MAX(money) from worker;
-- 2. 再去员工表中,把对应的员工信息查出来
select * from worker where money = (select MAX(money) from worker);
-- 谁的工资少于平均工资?
-- 1. 先把平均工资算出来
select AVG(money) from worker;
-- 2. 再去员工表中,把对应的员工信息查出来
select * from worker where money < (select AVG(money) from worker);
2)多行单列
当我们在处理多行单列的时候,有可能会出现多个值,这时候可以类似数组或集合一样处理,在 SQL中,使用 in 关键字即可。
-- 查询那些工资大于 12000 的人都来自哪些部门
-- 1. 先查大于 5000 的员工对应的部门 id
select depart_id from worker where money > 12000;
-- 2. 根据部门的编号,再找出部门的名字
-- 你查找到的记录,多于 1 行了 Subquery returns more than 1 row
-- select name from department where id = (select depart_id from worker where money > 12000);
select name from department where id in (select depart_id from worker where money > 12000);
-- 查询行政财务和技术研发中的所有员工的信息
-- 1. 先根据名字来查找 id
select id from department where name in ('行政财务', '技术研发');
-- 2. 再去查询相关的员工
select * from worker where depart_id in (select id from department where name in ('行政财务', '技术研发'));
3)多行多列
当你的子查询只要是多列,那么它肯定在 from 后面是以一张表存在的。
select 字段 from (子查询) 表别名 where 条件;
子查询在这里要作为表,然后还要给一个别名,如果不这样处理的话,就没办法访问到表中的字段。
-- 从 2019 年后入职的员工和相关部门信息
-- 1. 2019-1-1 后的时间
select * from worker where inWork_date >= '2019-01-01';
-- 2. 当我们从上面查找到对应的员工,则可以通过员工的 depart_id 找到对应的部门信息
select * from department d, (select * from worker where inWork_date >=
'2019-01-01') w
where d.id = w.depart_id;
-- 将上面的例子,换成内连接实现
select * from worker inner join department on worker.depart_id = department.id where inWork_date >= '2019-01-01';
第三章 事务
3.1 事务原理
事务:要么成功,要么不成功。
转账,A - 500,B + 500。转账的过程中,有可能会有一些突发的情况,导致转账操作会出现一些意料不到的问题。所以,在这里,我们需要建立一个通道,在通道中完成的操作,要么成功,要么不成功的时候及时回滚数据,避免造成大面积的业务混乱。
-- 账户表
create table bankCount(
id int primary key auto_increment,
name varchar(50),
money double
);
-- 添加数据
insert into bankCount(name, money)
values ('cuihua', 1000), ('banban', 2000);
-- 翠花给班班转钱 500
update bankCount set money = money - 500 where name = 'cuihua';
update bankCount set money = money + 500 where name = 'banban';
-- 提供一个事务通道,让转账的操作稳妥一些,如果中途出现问题,及时回滚数据,不要造成数据丢失
事务的原理:
当我们在 MySQL 中,如果开启了事务,那么你所有的操作都会临时被保存在事务日志中,只有遇上commit(提交)命令的时候,才会同步到数据表中。如果遇上 rollback 和 断开连接,那么它都会去清空你的事务日志。

3.2 手动提交
1)核心 SQL 语句
开启事务:start transaction
提交事务:commit
回滚事务:rollback
2)实现过程
第一步:开启事务
第二步:执行你的 SQL 语句
第三步:提交事务
第四步:如果出现问题的话,则回滚事务(数据)
3)事务提交
第一步:开启事务
start transaction;
第二步:执行你的 SQL 语句
update bankCount set money = money - 500 where name = 'cuihua';
update bankCount set money = money + 500 where name = 'banban';
第三步:如果出现问题的话,则回滚事务(数据)
commit;
4)事务回滚
第一步:开启事务
start transaction;
第二步:执行你的 SQL 语句
update bankCount set money = money - 500 where name = 'cuihua';
update bankCount set money = money + 500 where name = 'banban';
第三步:提交事务
rollback;
3.3 自动提交
MySQL 默认情况下,每一条 DML 语句都是一个单独的事务,都会对应的开启一个事务,当你执行的时候,同时自动默认提交事务。
1)自动提交事务
-- 随便一个 DML 语句都是会自动提交事务的
update bankCount set money = money + 500 where name = 'banban';
2)取消自动提交
@@autocommit 原来是 1 的,如果你要取消的话,则设置为 0 即可(但不建议)
set @@autocommit = 0;
3.4 事务
1)事务的特性 ACID
a. 原子性:Atomicity 在每一个事务中,都可以看成是一个整体,不能将其再度分解,所有的操作,要么一起成功,要么一起失败。
b. 一致性:Consistency 在事务执行前数据的所有状态跟执行后的数据状态应该是一样的。比如,转账前两个账户的金额总和应该跟转账后两个账户的总金额都是一样的。
c. 隔离性:Isolation 多个事务之间不能相互影响,必须保证其操作的单独性,否则会出现一些串改的情况,执行的时候应该保持隔离的状态。
d. 持久性:Durability 如果我们的事务执行成功之后,它将把数据永久性存储到数据库中,哪怕设备关机之后,也是能够保存下来的。
2)隔离级别可能会出现的问题
a. 脏读:其中一个事务读取到了另外一个事务中的数据(尚未提交的数据)。
b. 不可重复读:一个事务中两次读取数据的时候,发现数据的内容不一样。要求,多次读取数据的时候,在一个事务中读出的都应该是一样的。一般是由于 update 操作引发,所以将来执行的时候要特别注意。
c. 幻读:一般都是 insert 或者 delete 操作的时候会出现这个问题。一个事务中,两次读取数据的时候,发现数据的数量不一样。要求,在一个事务中多次去读取数据的时候都应该是一样的。
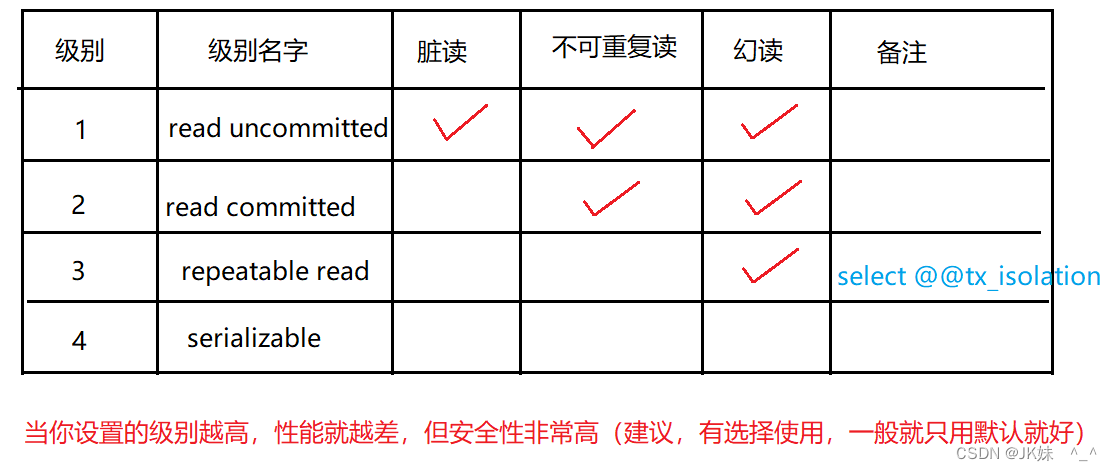
3)MySQL 的四种隔离级别
如果你将来使用 命令行 来设置隔离级别的时候,只有在当次会话中是有效的。只要你关掉了窗口,隔离级别会即时恢复到默认状况 — RR。
read uncommitted 读未提交
read committed 读已提交
repeatable read 可重复读(默认)
serializable 串行化
3.5 案例演示(了解)
1)脏读
先打开窗口,设置隔离级别:
set global transaction isolation level read uncommitted;
如果设置的级别是“读未提交”,其实会造成一个脏读的问题。脏读,会导致一个事务读取到了另外一个事务中的数据,其实非常危险。
解决方案:提升你的隔离级别。
set global transaction isolation level read committed;
当你设置成 read commintted 就不能读取到另外一个事务中的数据了。
只有当第一个事务提交了数据之后,第二个事务才能够去读取到数据。
read committed 可以避免数据的脏读。
2)不可重复读
如果将来,你写的 SQL 语句,发现第一次查询的时候,是一个结果,第二次查询的时候又是另外一个结果。一般都是最后一次查询的才是正确的,有时候第一次不正确的结果会被误用,就会给用户不好的体验。
订票:PC 端 — App 端 — 短信 如果说每次查询的结果不一样的话,则会导致推送用户信息的时候,呈现的数据不同步。
解决方案:将你的级别设置为 repeatable read 可重复读,也就是 mysql 默认的级别(不建议修改)。
3)幻读(课后自己演示)
set global transaction isolation level serializable ;
第四章 DCL
DDL create、alter、drop
DML insert、update、delete
DQL select、show
DCL grant、revoke
4.1 创建用户
如果将来创建一个新的用户,它并不会拥有与 root 用户一样的权限,root 是超级管理员,所有的权限它都有。
create user '用户名'@'主机名' identified by '密码';
CREATE USER '用户名'@'主机名' IDENTIFIED WITH mysql_native_password BY '密码';
create user 'cuihua'@'localhost' identified by '1234';
create user 'huahua'@'localhost' identified by '1234';
4.2 授权
如果想要使用这些新增的用户,则需要授予一定的权限。
grant 权限1, 权限2,..., 权限N on 数据库名.表名 to '用户'@'主机名'
-- cuihua 的权限
-- 如果希望在某个数据库下所有的表都能用的话,则建议写成 数据库名.*
grant create, alter, insert, update, select on hello.* to
'cuihua'@'localhost';
-- 简单的赋权限方法
grant all on *.* to 'huahua'@'localhost';
4.3 撤销授权
revoke all on hello.* from 'cuihua'@'localhost';
4.4 查看权限
-- 查看权限
show grants for '用户名'@'主机名';
4.5 删除用户
drop user '用户名'@'主机名';
4.6 修改用户的密码
ALTER USER '用户名'@'主机名' IDENTIFIED WITH mysql_native_password BY '新密码';




![[数据结构]:16-归并排序(顺序表指针实现形式)(C语言实现)](https://img-blog.csdnimg.cn/41c9940f80594b03be87a9bb81752916.png)





![[SQL Statements] 基本的SQL知识 之DDL针对表结构和表空间的基本操作](https://img-blog.csdnimg.cn/f6c55b60339549b9a29b96c42b31ec6b.png#pic_center)