一、influxdb的安装
InfluxDB简介
时序数据库InfluxDB版是一款专门处理高写入和查询负载的时序数据库,用于存储大规模的时序数据并进行实时分析,包括来自DevOps监控、应用指标和IoT传感器上的数据
主要特点:
专为时间序列数据量身订造高性能数据存储。TSM引擎提供数据高速读写和压缩等功能
简单高效的HTTP API写入和查询接口
针对时序数据,量身订造类似SQL的查询语言,轻松查询聚合数据
允许对tag建索引,实现快速有效的查询
数据保留策略(Retention policies)能够有效地使旧数据自动失效
————————————————
下载链接:
官网
https://portal.influxdata.com/downloads其他版本
#修改内核参数等切换其他版本
https://repos.influxdata.com/rhel/7/arm64/stable/2、linux版本的1.8.10版本具体参考链接:
#下载rpm包
wget https://dl.influxdata.com/influxdb/releases/influxdb-1.8.10.x86_64.rpm
#直接yum安装
sudo yum localinstall influxdb-1.8.10.x86_64.rpm3、安装后的相关配置或文件的路径:
/etc/influxdb/influxdb.conf 默认的配置文件
/var/log/influxdb/influxd.log 日志文件
/var/lib/influxdb/data 数据文件
/usr/lib/influxdb/scripts 初始化脚本文件夹4、启动influx数据库
# 1.正常后台启动
[root@aliyun ~]# systemctl start influxd 或者service influxdb restart(重启)
# 前台启动可以查看运行状态 也可以用 -config 指定启动时的配置文件
[root@aliyun ~]# /usr/bin/influxd
8888888 .d888 888 8888888b. 888888b.
888 d88P" 888 888 "Y88b 888 "88b
888 888 888 888 888 888 .88P
888 88888b. 888888 888 888 888 888 888 888 888 8888888K.
888 888 "88b 888 888 888 888 Y8bd8P' 888 888 888 "Y88b
888 888 888 888 888 888 888 X88K 888 888 888 888
888 888 888 888 888 Y88b 888 .d8""8b. 888 .d88P 888 d88P
8888888 888 888 888 888 "Y88888 888 888 8888888P" 8888888P"
5,进入命令行工具
进入命令行工具界面进行用户添加,如果修改了默认绑定的端口,需要添加-port参数指定端口(没改端口 可忽略):
[root@aliyun ~]# influx -port '8086'
Connected to http://localhost:18088 version 1.8.6
InfluxDB shell version: 1.7.6
Enter an InfluxQL query
# 创建管理员用户
> create user "admin" with password 'admin' with all privileges;
# 查看用户信息
> show users;
user admin
---- -----
admin true6,开启登录认证
# 修改配置
vim /etc/influxdb/influxdb.conf
# http相关参数 权限认证
[http]
# 开启 HTTP API
enabled = true
# bind-address = ":8086"
# 默认绑定端口为 8086可进行修改
bind-address = ":18088"
# auth-enabled = false
# 用户及密码验证默认关闭【注意】创建管理员用户后生产环境进行开启
auth-enabled = true
#改完重新启动
service influxdb restart(重启)7,数据保存地址配置
# 修改配置
vim /etc/influxdb/influxdb.conf
# 以下三个文件夹可根据需要进行修改
[meta]
dir = "/var/lib/influxdb/meta"
[data]
dir = "/var/lib/influxdb/data"
wal-dir = "/var/lib/influxdb/wal"7,重启服务后使用用户名及密码进行登录:
# 重启服务
systemctl restart influxd
# 如果不使用用户及密码登录操作时会报错
[root@aliyun ~]# influx -port '8086'
Connected to http://localhost:18088 version 1.7.6
InfluxDB shell version: 1.7.6
Enter an InfluxQL query
> show users;
ERR: unable to parse authentication credentials
Warning: It is possible this error is due to not setting a database.
Please set a database with the command "use <database>".
# 验证用户及密码
> auth
username: admin
password:
> show users;
user admin
---- -----
admin true
# 使用用户名及密码正确登录
[root@aliyun ~]# influx -port '18088' -username 'admin' -password 'admin'
Connected to http://localhost:18088 version 1.7.6
InfluxDB shell version: 1.7.6
Enter an InfluxQL query
> show users;
user admin
---- -----
admin true
7,数据保存地址配置
# 修改配置
vim /etc/influxdb/influxdb.conf
# 以下三个文件夹可根据需要进行修改
[meta]
dir = "/var/lib/influxdb/meta"
[data]
dir = "/var/lib/influxdb/data"
wal-dir = "/var/lib/influxdb/wal"二,常用操作
1. 官方文档
https://influxdb-v1-docs-cn.cnosdb.com/influxdb/v1.8/administration/authentication_and_authorization/2. influxdb基本操作
2.1. 数据库基本操作
# 创建数据库
> create database db01;
# 查看数据库
> show databases;
name: databases
name
----
_internal
mydb
db01
# 删除数据库
> drop database db01;
> show databases;
name: databases
name
----
_internal
mydb
# 使用数据库
> use mydb;
Using database mydb2.2. 表基本操作(measurement)
# 查看表
> show measurements;
name: measurements
name
----
meas01
meas02
mymeans
mymeas
# 新建表
# disk_free 就是表名,hostname是索引,value=xx是记录值,记录值可以有多个,最后是指定的时间
> insert disk_free,hostname=server01 value=442221834240i 1435362189575692182
> show measurements;
name: measurements
name
----
disk_free
meas01
meas02
mymeans
mymeas
# 查看表
> select * from disk_free;
name: disk_free
time hostname value
---- -------- -----
1435362189575692182 server01 442221834240
# 删除表
> drop measurement disk_free;
> show measurements;
name: measurements
name
----
meas01
meas02
mymeans
mymeas2.3. 系列基本操作(series)
> select * from disk_free;
name: disk_free
time hostname value
---- -------- -----
1435362189335692182 server01 442221834240
1435362189345692182 server01 442221834240
1435362189355692182 server01 442221834240
1435362189355692182 server02 442221834240
# series表示这个表里面的数据,可以在图表上画成几条线,series主要通过tags排列组合算出来。
> show series from disk_free;
key
---
disk_free,hostname=server01
disk_free,hostname=server022.4 存储策略操作(rentention policy)
# 注意:策略名称需要添加引号
# 新建策略
> create retention policy "role-02" on "mydb" duration 2h replication 1 default
# 查看策略
> show retention policies on mydb;
name duration shardGroupDuration replicaN default
---- -------- ------------------ -------- -------
autogen 0s 168h0m0s 1 false
2_hours 2h0m0s 1h0m0s 1 false
role-01 2h0m0s 1h0m0s 1 false
role-02 2h0m0s 1h0m0s 1 true
# name--名称,此示例名称为 default
# duration--持续时间,0代表无限制1h, 90m, 12h, 7d, 4w, INF 最小1h, 最大INF
# shardGroupDuration--shardGroup的存储时间,shardGroup是InfluxDB的一个基本储存结构,应该大于这个时间的数据在查询效率上应该有所降低。
# replicaN--全称是REPLICATION,副本个数
# default--是否是默认策略
# 修改策略
> alter retention policy "role-01" on mydb duration 3h default
> show retention policies on mydb;
name duration shardGroupDuration replicaN default
---- -------- ------------------ -------- -------
autogen 0s 168h0m0s 1 false
2_hours 2h0m0s 1h0m0s 1 false
role-01 3h0m0s 1h0m0s 1 true
role-02 2h0m0s 1h0m0s 1 false
# 删除策略
> drop retention policy "role-01" on mydb;
> show retention policies on mydb;
name duration shardGroupDuration replicaN default
---- -------- ------------------ -------- -------
autogen 0s 168h0m0s 1 false
2_hours 2h0m0s 1h0m0s 1 false
role-02 2h0m0s 1h0m0s 1 false2.5. 用户操作
# 查看用户
> show users;
user admin
---- -----
admin true
# 创建普通用户
> create user root with password '123456';
> show users;
user admin
---- -----
admin true
root false
# 创建具有admin权限的用户
> create user root with password '111111' with all privileges;
> show users;
user admin
---- -----
admin true
root true
# 授权root用户admin权限
> grant all privileges to root;
> show users;
user admin
---- -----
admin true
root true
# 删除用户
> drop user root;
> show users;
user admin
---- -----
admin true
# 修改用户密码
> set password for admin='111111';3.配置文件详解
# reporting-disabled = false # 该选项用于上报influxdb的使用信息给InfluxData公司,默认值为false
bind-address = "127.0.0.1:8085" # 备份恢复时使用,默认值为8088
### [meta]
[meta]
dir = "/data/influxdb/meta" # meta数据存放目录
# retention-autocreate = true # 用于控制默认存储策略,数据库创建时,会自动生成autogen的存储策略,默认值:true
# logging-enabled = true # 是否开启meta日志,默认值:true
### [data]
[data]
dir = "/data/influxdb/data" # 最终数据(TSM文件)存储目录
wal-dir = "/data/influxdb/wal" # 预写日志存储目录
# wal-fsync-delay = "0s" # 在同步写入之前等待的总时间,默认0s
# index-version = "inmem" # 用于新碎片的切分索引的类型。
# trace-logging-enabled = false # 跟踪日志记录在tsm引擎周围提供了更详细的输出
# query-log-enabled = true # 是否开启tsm引擎查询日志,默认值: true
# Valid size suffixes are k, m, or g (case insensitive, 1024 = 1k).
# cache-max-memory-size = "1g" # 用于限定shard最大值,大于该值时会拒绝写入,默认值:1000MB,单位:byte
# Valid size suffixes are k, m, or g (case insensitive, 1024 = 1k).
# cache-snapshot-memory-size = "25m" # 用于设置快照大小,大于该值时数据会刷新到tsm文件,默认值:25MB,单位:byte
# cache-snapshot-write-cold-duration = "10m" # tsm引擎 snapshot写盘延迟,默认值:10Minute
# compact-full-write-cold-duration = "4h" # tsm文件在压缩前可以存储的最大时间,默认值:4Hour
# max-concurrent-compactions = 0 # 压缩并发的最大数量,默认设置为0表示runtime.GOMAXPROCS(0)*50% ,否则以设置的非零值为准
# Valid size suffixes are k, m, or g (case insensitive, 1024 = 1k).
# max-index-log-file-size = "1m" # 限制索引日志文件大小
# max-series-per-database = 1000000 # 限制数据库的级数,该值为0时取消限制,默认值:1000000
# max-values-per-tag = 100000 # 一个tag最大的value数,0取消限制,默认值:100000
# tsm-use-madv-willneed = false # 如果为true,mmap的建议值MADV_WILLNEED会被提供给内核
### [coordinator]
[coordinator]
# write-timeout = "10s" # 写操作超时时间,默认值: 10s
# max-concurrent-queries = 0 # 最大并发查询数,0无限制,默认值: 0
# query-timeout = "0s" # 查询操作超时时间,0无限制,默认值:0s
# log-queries-after = "0s" # 慢查询超时时间,0无限制,默认值:0s
# max-select-point = 0 # SELECT语句可以处理的最大点数(points),0无限制,默认值:0
# max-select-series = 0 # SELECT语句可以处理的最大级数(series),0无限制,默认值:0
# max-select-buckets = 0 # SELECT语句可以处理的最大"GROUP BY time()"的时间周期,0无限制,默认值:0
### [retention]
[retention]
# enabled = true # 是否启用该模块,默认值 : true
# check-interval = "30m" # 检查时间间隔,默认值 :"30m"
### [shard-precreation]
[shard-precreation]
# enabled = true # 是否启用该模块,默认值 : true
# check-interval = "10m" # 检查时间间隔,默认值 :"10m"
# advance-period = "30m" # 预创建分区的最大提前时间,默认值 :"30m"
[monitor]
# store-enabled = true # 是否启用该模块,默认值 :true
# store-database = "_internal" # 默认数据库:"_internal"
# store-interval = "10s" # 统计间隔,默认值:"10s"
### [http]
[http]
# enabled = true # 是否启用该模块,默认值 :true
# bind-address = ":8086" # 绑定地址,默认值 :":8086"
# auth-enabled = false # 是否开启认证,默认值:false
# realm = "InfluxDB" # 配置JWT realm,默认值: "InfluxDB"
# log-enabled = true # 是否开启日志,默认值:true
# suppress-write-log = false # 在启用日志时是否抑制HTTP写请求日志
# access-log-path = "" # 当启用HTTP请求日志时,该选项指定了路径。如influxd不能访问指定的路径,它将记录一个错误并将请求日志写入stderr
# write-tracing = false # 是否开启写操作日志,如果置成true,每一次写操作都会打日志,默认值:false
# pprof-enabled = true # 是否开启pprof,默认值:true
# debug-pprof-enabled = false # 是否开启pprof,默认值:true
# https-enabled = false # 是否开启https ,默认值 :false
# https-certificate = "/etc/ssl/influxdb.pem" # 设置https证书路径,默认值:"/etc/ssl/influxdb.pem"
# https-private-key = "" # 设置https私钥,无默认值
# shared-secret = "" # 用于JWT签名的共享密钥,无默认值
# max-row-limit = 0 # 配置查询返回最大行数,0无限制,默认值:0
# max-connection-limit = 0 # 配置最大连接数,0无限制,默认值:0
# unix-socket-enabled = false # 是否使用unix-socket,默认值:false
# bind-socket = "/var/run/influxdb.sock" # unix-socket路径,默认值:"/var/run/influxdb.sock"
# max-body-size = 25000000 # 客户端请求主体的最大值,以字节为单位。0无限制,默认值0
# max-concurrent-write-limit = 0 # 并发处理的最大写入次数,0无限制,默认值0
# max-enqueued-write-limit = 0 # 排队等待处理的最大数量,0无限制,默认值0
# enqueued-write-timeout = 0 # 在队列中等待处理的最长时间,0或者setting max-concurrent-write-limit=0无限制,默认值0
### [ifql]
[ifql]
# enabled = true # 是否启用该模块,默认值 :true
# log-enabled = true # 是否开启日志,默认值:true
# bind-address = ":8082" # ifql RPC服务使用的绑定地址默认是8082
### [logging]
[logging]
# format = "auto" # 日志格式,默认是自动
# level = "info" # 日志级别默认info
# suppress-logo = false # 当程序启动时,会抑制打印出来的logo输出
### [subscriber]
[subscriber]
# enabled = true # 是否启用该模块,默认值 :true
# http-timeout = "30s" # http超时时间,默认值:"30s"
# insecure-skip-verify = false # 是否允许不安全的证书
# ca-certs = "" # 设置CA证书
# write-concurrency = 40 # 设置并发数目,默认值:40
# write-buffer-size = 1000 # 设置buffer大小,默认值:1000
### [[graphite]]
[[graphite]]
# enabled = false # 是否启用该模块,默认值 :false
# database = "graphite" # 数据库名称,默认值:"graphite"
# retention-policy = "" # 存储策略,无默认值
# bind-address = ":2003" # 绑定地址,默认值:":2003"
# protocol = "tcp" # 协议,默认值:"tcp"
# consistency-level = "one" # 一致性级别,默认值:"one
# batch-size = 5000 # 批量size,默认值:5000
# batch-pending = 10 # 配置在内存中等待的batch数,默认值:10
# batch-timeout = "1s" # 超时时间,默认值:"1s"
# udp-read-buffer = 0 # udp读取buffer的大小,0表示使用操作系统提供的值,如果超过操作系统的默认配置则会出错。 该配置的默认值:0
# separator = "." # 多个measurement间的连接符,默认值: "."
# tags = ["region=us-east", "zone=1c"] # 将被添加到所有指标的默认标签。这些可以在模板级别上覆盖或者从指标中提取的标签
# templates = [
# "*.app env.service.resource.measurement",
# # Default template
# "server.*",
# ]
### [collectd]
[[collectd]]
# enabled = false # 是否启用该模块,默认值 :false
# bind-address = ":25826" # 绑定地址,默认值: ":25826"
# database = "collectd" # 数据库名称,默认值:"collectd"
# retention-policy = "" # 存储策略,无默认值
# typesdb = "/usr/local/share/collectd" # 路径,默认值:"/usr/share/collectd/types.db"
# security-level = "none" # 安全级别
# auth-file = "/etc/collectd/auth_file"
# batch-size = 5000 # 从缓存中批量获取数据的量,默认值:5000
# batch-pending = 10 # 可能在内存中等待的批次的数量,默认值:10
# batch-timeout = "10s" # 即使没有达到缓冲区的限制,至少要刷新一下,默认值:"10s"
# read-buffer = 0 # udp读取buffer的大小,0表示使用操作系统提供的值,如果超过操作系统的默认配置则会出错。默认值:0
# parse-multivalue-plugin = "split" # 两种处理方式split和join,split会分到不同的表中,join会将记录作为一个单独的记录处理。默认是split
### [opentsdb]
[[opentsdb]]
# enabled = false # 是否启用该模块,默认值 :false
# bind-address = ":4242" # 绑定地址,默认值:":4242"
# database = "opentsdb" # 默认数据库:"opentsdb"
# retention-policy = "" # 存储策略,无默认值
# consistency-level = "one" # 一致性级别,默认值:"one"
# tls-enabled = false # 是否开启tls,默认值:false
# certificate= "/etc/ssl/influxdb.pem" # 证书路径,默认值:"/etc/ssl/influxdb.pem"
# log-point-errors = true # 出错时是否记录日志,默认值:true
# batch-size = 1000 # 从缓存中批量获取数据的量,默认值:1000
# batch-pending = 5 # 可能在内存中等待的批次的数量,默认值:5
# batch-timeout = "1s" # 即使没有达到缓冲区的限制,至少要刷新一下,默认值:"1s"
### [[udp]]
[[udp]]
# enabled = false # 是否启用该模块,默认值 :false
# bind-address = ":8089" # 绑定地址,默认值:":8089"
# database = "udp" # 数据库名称,默认值:"udp"
# retention-policy = "" # 存储策略,无默认值
# precision = "" # 接收点的时间点的精度("" or "n", "u", "ms", "s", "m", "h")
# batch-size = 5000 # 从缓存中批量获取数据的量,默认值:5000
# batch-pending = 10 # 可能在内存中等待的批次的数量,默认值:10
# batch-timeout = "1s" # 即使没有达到缓冲区的限制,至少要刷新一下,默认值:"1s"
# read-buffer = 0 # udp读取buffer的大小,0表示使用操作系统提供的值,如果超过操作系统的默认配置则会出错。 该配置的默认值:0
### [continuous_queries]
[continuous_queries]
# enabled = true # 是否启用该模块,默认值 :true
# log-enabled = true # 是否开启日志,默认值:true
# query-stats-enabled = false # 控制查询是否被记录到自我监控数据存储中
# run-interval = "1s" # 时间间隔,默认值:"1s"
### [tls]
[tls]
# ciphers = [
# "TLS_ECDHE_ECDSA_WITH_CHACHA20_POLY1305",
# "TLS_ECDHE_RSA_WITH_AES_128_GCM_SHA256",
# ]
# min-version = "tls1.2"
# max-version = "tls1.2"
4. 基本操作 postman
#移步大佬博客
https://blog.csdn.net/qq_40378034/article/details/111112737三:可视化工具InfluxDBStudio
软件虽然界面简陋,但是目前暂未发现另一款可以可视化操作InfluxDB的软件,
虽然简陋,但是还是很容易上手,简单介绍下如何使用
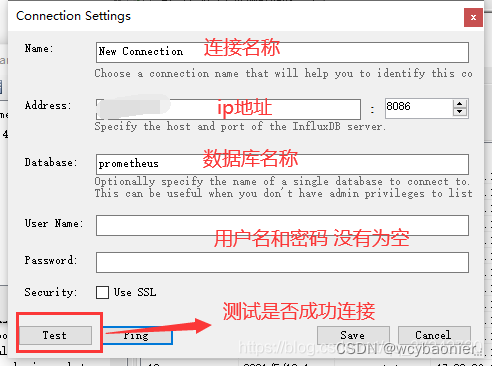
Name 名称 - 连接的名称。这是使用此连接时将看到的标签
Address 地址 - InfluxDB服务器的主机URI。排除协议信息。端口填写在右侧
Database 数据库 - 用于连接的数据库。将其留空以列出所有数据库(需要管理员权限)
UserName 用户名 - 用于连接的InfluxDB用户名
Password 密码 - 与连接一起使用的InfluxDB密码
Security - Use SSL 使用SSL - 连接到InfluxDB时是否使用SSL安全性(HTTPS)
https://github.com/CymaticLabs/InfluxDBStudio/releases/tag/v0.2.0-beta.11,使用方式

进去就不用多说了吧,低配版的SQLyog,哈哈哈