文章目录
- 前言
- Redis集群原理
- 搭建Redis集群
- 集群拓展
- 后记
前言
前两期介绍和搭建了Redis的主从复制架构和哨兵模式,虽然哨兵模式能够实现自动故障转移主备切换,一定程度上提高了系统的容错性
但这两种架构模式都不能解决单节点的并发压力和物理上线的问题,单节点写的Redis始终无法应对大型项目中的高并发压力以及内存和磁盘的密集IO存取操作。
这种情况下就需要Redis的集群来解决以上的问题!
Redis集群原理
Redis3.0开始支持集群模式,实现了数据的分布式存储,对数据进行分片,将数据存储在不同的master节点上

Redis集群采用去中心化的思想,没有中心节点的说法,对于客户端来说,整个集群可以看成一个整体,可以连接任意一个节点进行操作,就像操作单一Redis实例一样,不需要任何代理中间件,当客户端操作的key没有分配到该node上时,Redis会返回转向指令,指向正确的node。

- 主节点负责读写请求和集群信息的维护,从节点只对主节点数据和状态信息的复制
- 称数据分片是Redis集群最核心的功能,集群将数据分散到多个master节点
- 集群同样支持主从复制和主节点的自动故障转移(与哨兵模式类似),当任意节点发生故障时,集群仍然可以正常对外提供服务
Redis集群采用的是
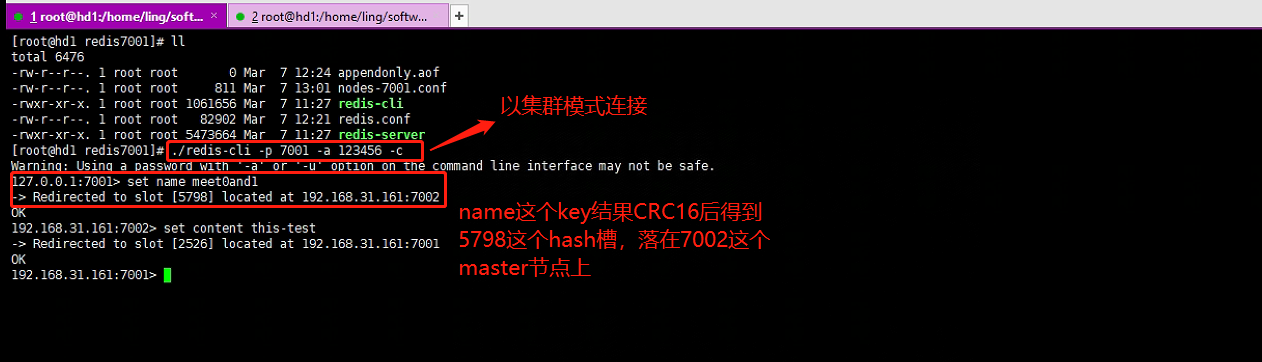
哈希槽分区算法。Redis集群中有16384个哈希槽(槽的范围是 0 -16383,哈希槽),将不同的哈希槽分布在不同的Redis节点上面进行管理,也就是说每个Redis节点只负责一部分的哈希槽。在对数据进行操作的时候,集群会对使用CRC16算法对key进行计算并对16384取模(slot = CRC16(key)%16383),得到的结果就是 Key-Value 所放入的槽,通过这个值,去找到对应的槽所对应的Redis节点,然后直接到这个对应的节点上进行存取操作。
摘自:https://blog.csdn.net/a745233700/article/details/112691126
搭建Redis集群
集群中的节点是否可用,是由集群中的所用master节点选举决定的,当半数以上的节点认为某个节点故障了,那么该节点就是挂掉了,所以搭建redis集群时建议master节点数最好为奇数,搭建Redis集群至少需要三个主节点,三个从节点。
**注意:**我这里用的是redis-6.0.4版本,redis-6版本之前还需要安装ruby脚本来构建redis集群,而redis-6版本之后直接使用redis-cli构建。
为方便演示,这里在一台主机上模拟redis集群的效果
1、准备6个redis服务节点
# (1)在redis根目录下创建6个目录作为6个节点
mkdir -p redis-cluster/redis700{1..6}
# (2)编写一个sh脚本将redis的配置文件redis.conf、redis-server和redis-cli复制一份到6个节点目录下(或者手动一个个复制)
#!/bin/bash
for i in {1..6}
do
cp /software/redis/redis.conf /software/redis/redis-cluster/redis700$i
cp /software/redis/bin/redis-cli /software/redis/bin/redis-server /software/redis/redis-cluster/redis700$i
done
2、配置6个服务节点
修改6个节点redis.conf配置文件中的以下内容,可以修改好一个后复制六份再修改port和集群节点配置文件名nodes-port.conf
bind 0.0.0.0 # 开启远程连接
port 7001 # 设置redis服务端口【需要修改6个】
daemonize yes # 开启以守护线程的(后台)方式启动
protected-mode no # 关闭保护模式
requirepass 123456 # 设置Redis服务访问密码
appendonly yes # 开启AOF持久化
cluster-enabled yes # 开启集群模式
cluster-config-file nodes-7001.conf # 集群节点配置文件nodes-port.conf【需要修改6个】
cluster-node-timeout 5000 # 集群节点超时时间(默认15000毫秒)
3、启动6个节点
在各自节点目录下,执行以下命令启动当前redis服务节点
./redis-server ./redis.conf
# 查看是否启动了六个Redis进程
ps -ef|grep redis


4、构建集群
在任意一个节点上执行创建命令构建redis集群:构建集群时,会根据创建命令节点顺序指定主从节点,会自动为master节点分配16384个hash槽
# 六个节点分为三组,每组又分为一主一从
# 这里会把前三个做为主节点,后三个做为从节点,--cluster-replicas 1表示指定每个主节点有一个从节点
./redis-cli --cluster create 192.168.31.161:7001 192.168.31.161:7002 192.168.31.161:7003 192.168.31.161:7004 192.168.31.161:7005 192.168.31.161:7006 --cluster-replicas 1 -a 123456
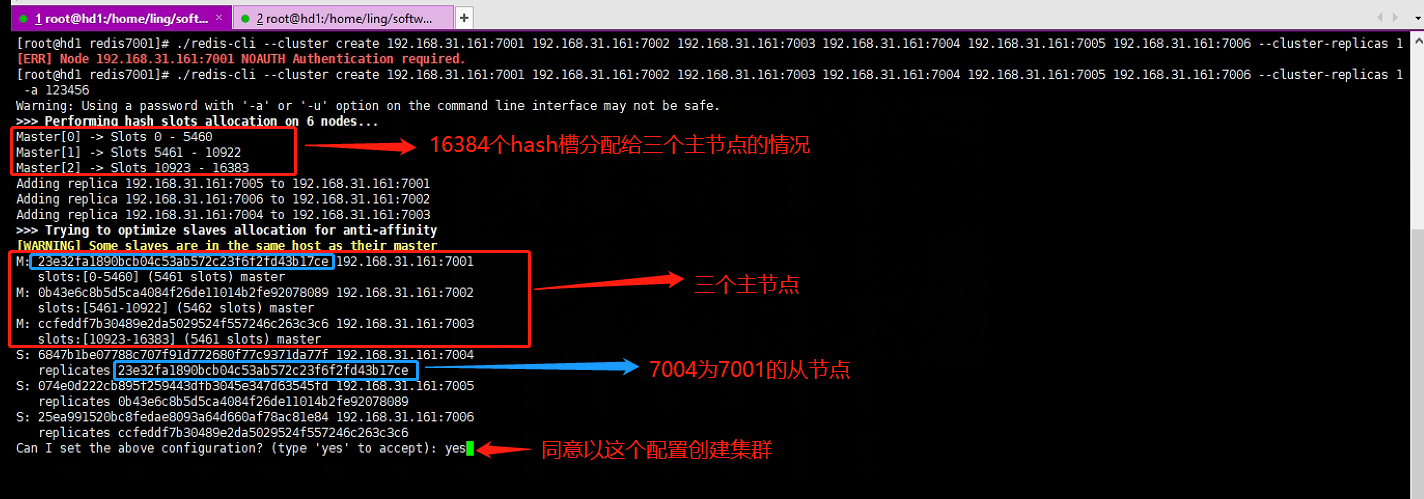
看到All nodes agree about slots configuration.和All 16384 slots covered即代表集群构建成功

集群拓展
# -c:以集群模式连接
./redis-cli -p 7001 -a 123456 -c
# redis-cli连接后,通过cluster nodes查看集群的节点信息
192.168.31.161:7001> cluster nodes
把7001这个master节点kill掉,查看它的从节点是否顶替上来作为新的master节点了
Spring Boot中操作Redis集群
<!--redis-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
# 书写集群中的所有节点IP:port,以逗号分隔
spring.redis.cluster.nodes=192.168.31.161:7001,192.168.31.161:7002,192.168.31.161:7003,192.168.31.161:7004,192.168.31.161:7005,192.168.31.161:7006
后记
redis主从复制、哨兵模式(sentinel)、redis集群(cluster)三种架构模式的演变,已经能应对当下市场上的项目对Redis缓存的需求
Redis缓存的存在主要是为了减轻数据库的并发压力(当然在分布式系统中,由于跨JVM导致synchronized失效,而常用Redis来实现分布式锁等,Redis的应用也非常广泛)
Redis缓存虽减轻了数据库的一部分并发压力,但要提高数据库自身的容错性,以及实现数据库服务在整个系统中的高可用才是根本!
后面将持续带来MySQL的主从复制,以及MySQL读写分离(集群)的介绍和搭建详情!