专栏:神经网络复现目录
本章介绍的是现代神经网络的结构和复现,包括深度卷积神经网络(AlexNet),VGG,NiN,GoogleNet,残差网络(ResNet),稠密连接网络(DenseNet)。
文章部分文字和代码来自《动手学深度学习》
文章目录
- 含并行连结的网络(GoogLeNet)
- Inception块
- 定义和结构
- 实现
- GoogLeNet模型
- 结构
- 实现
- 实战
- 导包
- 数据集
- 优化器,损失函数
- 训练和评估
含并行连结的网络(GoogLeNet)
GoogleNet,也叫Inception v1,是Google在2014年提出的深度卷积神经网络,它的主要特点是使用了Inception模块来替代原来的单一卷积层,以更好地提取特征。GoogleNet是在ImageNet数据集上训练出来的,它在当年的ImageNet比赛中获得了最好的结果。
GoogleNet的整体架构相对于之前的模型更为复杂,具有22层。其中,它的最大特点是使用了Inception模块,使得模型的参数量比之前的模型更小,但是精度更高。
Inception模块主要是将不同卷积核大小的卷积层和最大池化层进行组合,以获得不同大小的感受野,从而更好地提取特征。同时,Inception模块使用了1x1的卷积层进行通道数的调整,进一步减少了参数量。
除了Inception模块之外,GoogleNet还采用了全局平均池化层来代替全连接层,这也是后续很多模型都采用的做法,可以减少过拟合,同时减少参数量。
Inception块
定义和结构
Inception模块是GoogleNet中的一个核心组成部分,用于提取图像特征。该模块采用并行的多个卷积层和池化层来提取不同尺度的特征,然后将它们在通道维度上进行拼接,得到更丰富的特征表达。
一个基本的Inception模块包含了四个分支(Branch),每个分支都有不同的卷积核或者池化核,如下图所示:
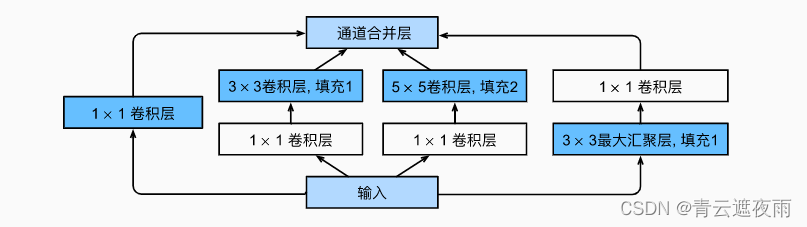
在这个模块中,我们可以看到分支1、2、3都是卷积层,分支4则是最大池化层,其目的是提取图像中不同大小的特征。通过这些分支的组合,Inception模块可以有效地提取图像的多尺度特征,且计算代价相对较小。
具体来说,假设输入的特征图的大小是 h × w × c h\times w\times c h×w×c,Inception模块将其输入到四个分支中,这四个分支分别是:
分支1:1×1卷积层,用于对通道数进行降维,可以看做是对输入的特征进行了线性变换,从而提取空间信息;
分支2:1×1卷积层后接3×3卷积层,先通过1×1卷积层将通道数降维,然后再通过3×3卷积层提取特征。在这个分支中,1×1卷积层可以用来降低计算量,3×3卷积层用于提取空间信息,组合起来可以在计算效率和特征表达能力之间取得平衡;
分支3:1×1卷积层后接5×5卷积层,和分支2类似,该分支也是先通过1×1卷积层将通道数降维,然后再通过5×5卷积层提取特征。与3×3卷积核相比,5×5卷积核可以捕捉更大的空间范围,从而更好地提取空间信息;
分支4:3×3最大池化层后接1×1卷积层,通过池化层可以提取图像中不同大小的特征,然后使用1×1卷积层进行通道数降维。
最后,将四个分支的输出在通道维度上进行拼接,得到的结果就是Inception模块的输出。
实现
import torch
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l
class Inception(nn.Module):
# c1--c4是每条路径的输出通道数
def __init__(self, in_channels, c1, c2, c3, c4, **kwargs):
super(Inception, self).__init__(**kwargs)
# 线路1,单1x1卷积层
self.p1_1 = nn.Conv2d(in_channels, c1, kernel_size=1)
# 线路2,1x1卷积层后接3x3卷积层
self.p2_1 = nn.Conv2d(in_channels, c2[0], kernel_size=1)
self.p2_2 = nn.Conv2d(c2[0], c2[1], kernel_size=3, padding=1)
# 线路3,1x1卷积层后接5x5卷积层
self.p3_1 = nn.Conv2d(in_channels, c3[0], kernel_size=1)
self.p3_2 = nn.Conv2d(c3[0], c3[1], kernel_size=5, padding=2)
# 线路4,3x3最大汇聚层后接1x1卷积层
self.p4_1 = nn.MaxPool2d(kernel_size=3, stride=1, padding=1)
self.p4_2 = nn.Conv2d(in_channels, c4, kernel_size=1)
def forward(self, x):
p1 = F.relu(self.p1_1(x))
p2 = F.relu(self.p2_2(F.relu(self.p2_1(x))))
p3 = F.relu(self.p3_2(F.relu(self.p3_1(x))))
p4 = F.relu(self.p4_2(self.p4_1(x)))
# 在通道维度上连结输出
return torch.cat((p1, p2, p3, p4), dim=1)
GoogLeNet模型
GoogLeNet一共使用9个Inception块和全局平均汇聚层的堆叠来生成其估计值。Inception块之间的最大汇聚层可降低维度。 第一个模块类似于AlexNet和LeNet,Inception块的组合从VGG继承,全局平均汇聚层避免了在最后使用全连接层。
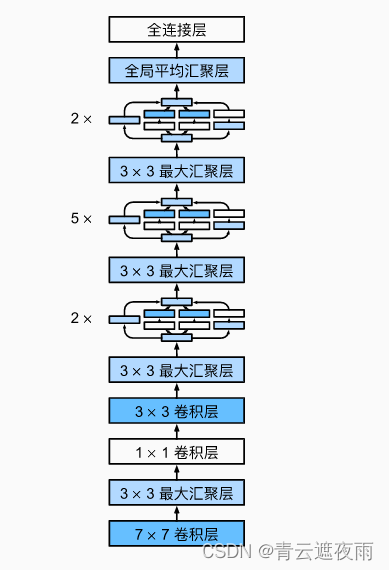
结构
- 卷积层,输入为 224 × 224 224\times224 224×224的彩色图像,使用 7 × 7 7\times7 7×7的卷积核,步幅为2,输出通道数为64,偏置和ReLU激活函数。
- 最大池化层,使用 3 × 3 3\times3 3×3的卷积核,步幅为2,输出尺寸为 112 × 112 112\times112 112×112。
- 卷积层,输入通道数为64,使用 1 × 1 1\times1 1×1的卷积核,输出通道数为64,偏置和ReLU激活函数。
- 卷积层,输入通道数为64,使用 3 × 3 3\times3 3×3的卷积核,输出通道数为192,步幅为1,偏置和ReLU激活函数。
- 最大池化层,使用 3 × 3 3\times3 3×3的卷积核,步幅为2,输出尺寸为 56 × 56 56\times56 56×56。
- 使用两个Inception模块,输出通道数为256和480,分别将它们堆叠在一起。
- 最大池化层,使用 3 × 3 3\times3 3×3的卷积核,步幅为2,输出尺寸为 28 × 28 28\times28 28×28。
- 使用五个Inception模块,输出通道数分别为 512 , 512 , 512 , 528 512, 512, 512, 528 512,512,512,528和 832 832 832,分别将它们堆叠在一起。
- 最大池化层,使用 3 × 3 3\times3 3×3的卷积核,步幅为2,输出尺寸为 14 × 14 14\times14 14×14。
- 使用两个Inception模块,输出通道数分别为 832 832 832和 1024 1024 1024,分别将它们堆叠在一起。
- 全局平均池化层,使用一个 7 × 7 7\times7 7×7的池化窗口,输出大小为 1 × 1 1\times1 1×1。
- Dropout层,随机将一定比例的元素归零,防止过拟合。
- 全连接层,输出为10,对应10个类别。
实现
class GoogLeNet(nn.Module):
def __init__(self, in_channels=3, num_classes=1000):
super(GoogLeNet, self).__init__()
# 第一阶段
self.stage1 = nn.Sequential(
nn.Conv2d(in_channels, 64, kernel_size=7, stride=2, padding=3),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
)
# 第二阶段
self.stage2 = nn.Sequential(
nn.Conv2d(64, 64, kernel_size=1),
nn.ReLU(inplace=True),
nn.Conv2d(64, 192, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
)
# 第三阶段
self.stage3 = nn.Sequential(
Inception(in_channels=192, c1=64, c2=(96, 128), c3=(16, 32), c4=32),#64+128+32+32=256
Inception(256, 128, (128, 192), (32, 96), 64),#128+192+96+64=480
nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
)
# 第四阶段
self.stage4 = nn.Sequential(
Inception(480, 192, (96, 208), (16, 48), 64),
Inception(512, 160, (112, 224), (24, 64), 64),
Inception(512, 128, (128, 256), (24, 64), 64),
Inception(512, 112, (144, 288), (32, 64), 64),
Inception(528, 256, (160, 320), (32, 128), 128),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
)
# 第五阶段
self.stage5 = nn.Sequential(
Inception(832, 256, (160, 320), (32, 128), 128),
Inception(832, 384, (192, 384), (48, 128), 128),
nn.AdaptiveAvgPool2d((1, 1)),
nn.Flatten()
)
# 全连接层
self.fc = nn.Linear(1024, num_classes)
def forward(self, x):
x = self.stage1(x)
x = self.stage2(x)
x = self.stage3(x)
x = self.stage4(x)
x = self.stage5(x)
x = self.fc(x)
return x
实战
导包
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
torch.manual_seed(1234)
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(device)
数据集
transform_train = transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
transform_test = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform_train)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=32,
shuffle=True, num_workers=2)
testset = torchvision.datasets.CIFAR10(root='./data', train=False,
download=True, transform=transform_test)
testloader = torch.utils.data.DataLoader(testset, batch_size=32,
shuffle=False, num_workers=2)
优化器,损失函数
net = GoogLeNet(num_classes=10).to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
训练和评估
import time
def evaluate_accuracy(data_iter, net, device):
net.eval() # 评估模式
acc_sum, n = 0.0, 0
with torch.no_grad():
for X, y in data_iter:
X, y = X.to(device), y.to(device)
acc_sum += (net(X).argmax(dim=1) == y).float().sum().cpu().item()
n += y.shape[0]
net.train() # 改回训练模式
return acc_sum / n
def train(net, train_iter, test_iter, loss, optimizer, device, epochs):
net = net.to(device)
print("training on ", device)
batch_count = 0
for epoch in range(epochs):
train_l_sum, train_acc_sum, n, start = 0.0, 0.0, 0, time.time()
for X, y in train_iter:
X, y = X.to(device), y.to(device)
y_hat = net(X)
l = loss(y_hat, y)
optimizer.zero_grad()
l.backward()
optimizer.step()
train_l_sum += l.cpu().item()
train_acc_sum += (y_hat.argmax(dim=1) == y).sum().cpu().item()
n += y.shape[0]
batch_count += 1
test_acc = evaluate_accuracy(test_iter, net, device)
print('epoch %d, loss %.4f, train acc %.3f, test acc %.3f, time %.1f sec' % (
epoch + 1, train_l_sum / batch_count, train_acc_sum / n, test_acc, time.time() - start))
train(net,trainloader,testloader,criterion,optimizer,device,10)